构建基于大模型的Autonomous Agents案例
1.1 Autonomous Agents原理机制
在本节中,我们将聚焦于LangChain上的自治代理(Autonomous Agents on LangChain)。自治代理是当前业界最热门的话题之一,特别是在企业级应用中。当然,自治代理也是核心研究的焦点之一。
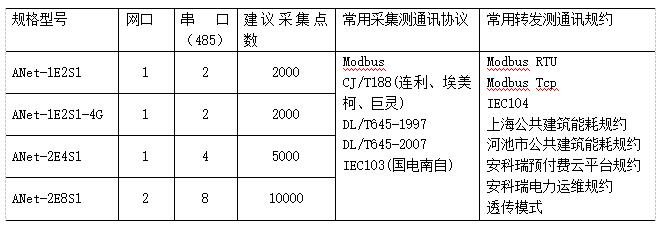
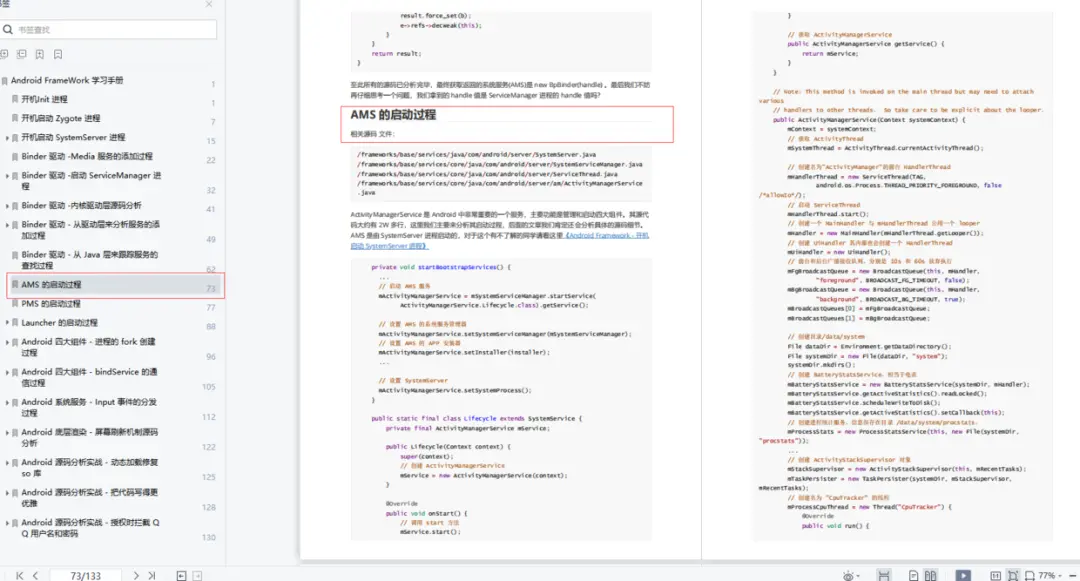
如图15-1所示,这是BabyAGI的一个基本流程图。
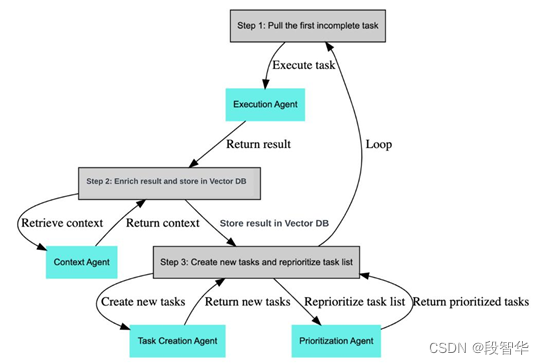
图15- 1 BabyAGI的一个基本流程图
在这个流程图中,我们可以看到它从具体的任务列表开始。
Gavin大咖微信:NLP_Matrix_Space
第一步:是获取第一个未完成的任务(pull the first Incomplete task)。显然,它是从任务列表中获取的。根据之前我们分享的内容,大家应该清楚任务列表是由我们的大型语言模型生成的,比如GPT-4,这是第一步,获取了未完成的任务后,接下来就是执行任务的过程(Execute task)。我们有一个具体的执行代理(Execution Agent),在这里可以进行各种操作,因为它是一个代理,可以与我们的模型进行交互。在这个执行过程中,核心是BabyAGI,最初的思想依赖于模型,但是作为一个代理,根据我们之前分享的内容,大家应该清楚它也可以与工具进行交互,会涉及模型、工具和数据访问,从而产生结果。在LangChain中,可以使用链式(chain)的方式,例如LLMChain,完成了许多工作。所产生的结果来源是语言模型提供的,提供的信息基于一些前提条件,比如任务的目标、过去的历史记录和系统设置等。当然,有时代理会调用第三方工具来生成结果,这些结果也会作为模型在生成结果之前的输入信息。这些内容对大家来说,不应该有任何理解上的难度,因为我们之前通过大量的案例和源码解析已经剖析了这些内容。例如,GPT-4基于这些因素生成了一个结果,把这个结果交给代理,转过来,作为下一步执行的前提或上下文。
第二步:丰富结果并存储在Vector DB中(Enrich result and store in Vector DB)。由于BabyAGI是一个面向任务的自动自治代理,因此它会有一些状态管理或保存。这里有一个非常有趣的词,叫做“Enrich”,这个词非常有意思。做大数据Flink开发的人员会明白,Flink在数据流动中的核心工作之一就是数据的丰富化操作。所谓数据丰富化操作,意思是基于某个事件,你可能在执行之前或之后都会产生一些新的信息,但是这些新的信息需要完成丰富化的过程,它会与其他信息进行关联,所以觉得在这里使用这个词非常恰当。“丰富结果并存储在Vector DB”,在这里,实际上它的核心是做什么呢?它的核心是将上下文、过去完成的任务、系统设置信息以及你的目标结合起来,完成整个丰富化的过程,并将结果存储在向量数据库中。在这一步中,涉及到上下文代理(Context Agent),其中,检索上下文(Retrieve context)与许多历史信息相关联。返回结果(Return result)是第一步中的结果,基于检索上下文以及返回结果,将结果存储在向量数据库中(Store result in Vector DB)中。
Gavin大咖微信:NLP_Matrix_Space
第三步:创建新任务并重新确定任务列表的优先级(Create new tasks and reprioritize task list)。在这一步中,我们可以创建新的任务,并重新确定任务列表的优先级。创建新任务和重新确定任务列表的优先级由谁来完成呢?当然是我们的语言模型,比如GPT-4。我们对大型语言模型应用程序开发特别感兴趣的原因之一是它的推理能力。创建新任务是一个动态的、不断发展的过程,这是使用语言模型的关键之一,在具体的实际场景中,这一点具有重要意义。例如,在教育领域,如果学习过程由大型语言模型驱动,教授或导师给学生分配任务,学生完成第一个任务后,语言模型会结合上下文信息和历史信息进行数据丰富(Data Enrich),“Enrich”这个词非常合适,“Enrich”的概念可以通过其他学术表现来进行丰富,不仅仅局限于本学期或本学年,还可以考虑过去1年甚至5年的表现。当将这些信息再次交给我们的语言模型进行处理时,它会动态生成新的任务。生成新任务后,语言模型还会进行另一个操作,即重新确定任务列表的优先级,以决定下一步最佳的执行顺序。因此,这个系统实现了自动化、个性化、更加高效和有针对性的教育场景。对于从事教育领域的人来说,这个过程应该是非常令人激动的,因为现在技术已经成为现实。
我们进行了优先级代理(Prioritization Agent)的操作,确定了下一步的执行操作,然后可能会再次重复(Loop)之前的过程,但是请注意,在这个重复的过程中,有一些东西是不变的,那就是用户的目标。以教育场景为例,你的导师可能要求你完成一个作业,这个作业的背景、条件和评估等信息,这些是不变的,这些信息会约束你的整个行为。但是,什么是在变化的呢?是你每次完成任务时的状态变化。在目标不变的情况下,你的状态不断变化,结合目标、状态和历史表现,语言模型会动态调整生成的学习任务,而且具有很强的针对性。例如,对于一般学生来说,完成一个任务可能需要执行30个步骤或者完成30个子任务。但对于那些非常优秀或对该领域特别感兴趣的学生来说,他们可能只需要一两个步骤就能完成。尤其是在数据丰富化(Data Enrichment)这一步骤中,没有必要一步一步进行。但如果你的基础不好,或者对该领域的兴趣不够强烈,那么给你提供更精细化的步骤就是必要的。
因此,BabyAGI在业界产生了相当大的影响,尤其是它的思想揭示了语言模型的潜力和能力,以及它对教育行业和其他相关行业的实际价值。这也是为什么我们专门花一节内容来讨论基于LangChain的自主代理(autonomous agent on langchain)的原因之一。我们也专门讨论了另一个自主代理,是AutoGPT,揭示其背后的原理以及案例的源代码。
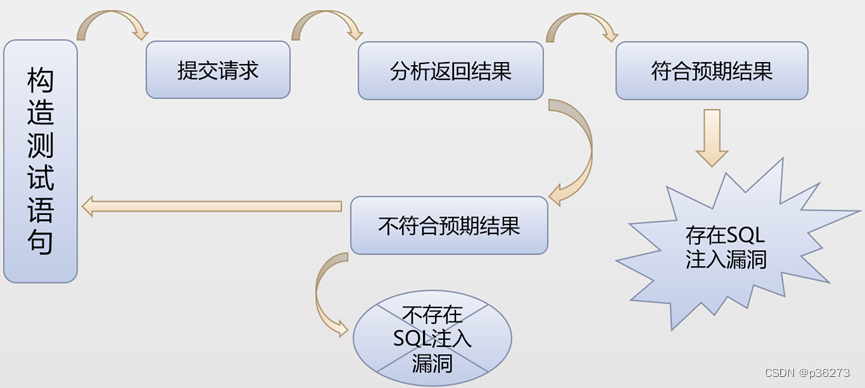
如图15-2所示,是LangChain的自治代理的代码目录,在目录(autonomous_agents)下面有两个目录,一个是AutoGPT,另外一个是BabyAGI。

图15- 2 LangChain的自治代理代码目录
AutoGPT和BabyAGI是两个典型的代理,但我们并不是直接使用它们,而是它们揭示了自然语言处理模型的巨大推理能力,并将其变成了现实。它们展示了这一点,并对各个领域产生了重大的理论影响。AutoGPT自动地将一个高层任务分解为具体步骤,并自动进行反思的自我调整。这在通用人工智能或自动化领域中提供了许多令人想象的空间。
我们初步讨论了这个基本流程。在代理的视角下,我们考虑了三个核心代理。第一个是执行代理(Execute Agent),它背后调用GPT-4或其他大型语言模型。第二个是任务创建代理(Task Creation Agent),它根据你的目标进行任务创建。在教育场景中,例如导师给出一个作业,这对所有学生来说是相同的,只是具体的学习过程不同。任务创建代理会考虑你之前的执行情况,并考虑你的背景、最近和长期的学习记录。这也涉及到上下文代理(Context Agent)的内容,将所有的状态数据存储在一个地方,并随时可以访问。当然,我们使用基于向量数据库的方式,例如,你可以使用Facebook的Faiss。第三个核心是优先级代理(Prioritization Agent),它涉及到确定下一步最重要的任务是什么。这是非常关键的,特别是在动态环境下。作为一个代理,设定优先级非常重要。回到之前提到的教育场景的例子,优先级代理可以确定哪些任务是重要且紧急的,这样可以让学生在最合适的时候学习最重要的内容或获得及时的帮助。然而,设置优先级时需要考虑许多因素,而这些因素的考虑是由模型驱动的。我们也强调了另一个非常重要的点,你可以使用专家模型来影响决策过程,包括影响优先级的排序或管理决策过程。无论是通过论文,还是源代码的角度,我们前面都非常清楚地向大家解释了,当你的大型语言模型考虑不同领域专家的观点,尤其是那些相对较小的模型时,可以显著提升性能。
Gavin大咖微信:NLP_Matrix_Space
回到我们的案例,具体看看它是如何实施的,以及案例的运行过程。在这个基础上,我们将深入探讨框架的内部实现。无论是案例,还是框架,我们都基于LangChain进行开发。LangChain已经成为开源界和工业界公认的标准大型模型应用开发框架,它提供了许多实用的工具,能够节省大量时间。我们具体看一下代码部分,这是基于官方文档中的“BabyAGI with Tools”实现的,这个名称本身就让人兴奋,因为它基于代理思想与工具进行交互,工具是LangChain提供的一个非常核心的功能。
第一步,我们需要安装一些库,例如LangChain、OpenAI、tiktoken等。我们使用的是faiss-cpu,这不仅是一个CPU版本,而且你不需要依赖其他工具,因为它可以在本地模式下运行。此外,我们还使用了google-search-results等库。
!pip install langchain openai tiktoken faiss-cpu google-search-results -q
我们在本地使用的是faiss的cpu版本,因为有faiss的本地模式。在当前进行大模型应用开发时,实际上进行向量操作的时候,并不需要太多的计算资源。这是一个经常被读者问到的问题,是否需要一台专门的GPU服务器,从开发或学习的角度来看,实际上是不需要的。即使在某些情况下确实需要GPU,最简单且最高效的方法是使用Google Colab,它是最简单且最广泛使用的方式,因为全世界有那么多人在使用Google Colab,它已经经过了充分的测试和优化,经历了千锤百炼,而且它不仅提供GPU,还提供TPU,所以你根本不用担心硬件的许多问题。对于开发大型模型应用程序,对机器的特殊要求并不是必须的,并没有对机器提出特别的要求。
导入必要的库,并设置环境变量,导入LLMChain、OpenAI等。代码中还包括了一些向量存储的导入,以及一些基本的配置。在导入库和设置环境变量后,代码使用了dotenv库加载环境变量文件,并将SERPAPI_API_KEY和OPENAI_API_KEY设置为相应的值。
1. import os
2. from collections import deque
3. from typing import Dict, List, Optional, Any
4.
5. from langchain import LLMChain, OpenAI, PromptTemplate
6. from langchain.embeddings import OpenAIEmbeddings
7. from langchain.llms import BaseLLM
8. from langchain.vectorstores.base import VectorStore
9. from pydantic import BaseModel, Field
10. from langchain.chains.base import Chain
11.
12. import os
13.
14. from dotenv import load_dotenv, find_dotenv
15. _ = load_dotenv(find_dotenv())
16.
17. os.environ['SERPAPI_API_KEY'] = os.getenv('SERPAPI_API_KEY')
18. os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY')
以上代码中,我们使用了collections库中的一个重要数据结构deque,它作为一种数据结构,deque可以从左侧或右侧进行操作,也可以从前端或后端进行操作,而且非常高效。作者之前给一家跨国公司讲解高级Python开发时,其中有五个核心的高级数据结构,而deque是其中一个非常重要的结构,之所以重要,是因为它提供了许多有用的数据结构操作,值得大家花时间去学习。
接下来我们导入了LLMChain,在之前的源码和运行过程中,我们一直使用LLMChain。导入PromptTemplate和OpenAIEmbeddings,因为它们对于管理提示(Prompt)和将文本转换为向量非常有效。尤其是OpenAIEmbeddings的表现还不错,它可以将输入的信息或文本转换为向量表示。BaseLLM作为类似于包装器(wrapper)的方式,可以将它视为类似于一个接口。VectorStore用于数据存储,BaseModel、Field和Chain是一些基本的对象。
我们回到官方文档,LangChain为我们提供了一些模块,包括模型输入输出(Model I/O)、数据连接(Data connection)、链(Chains)、内存(Memory)、代理(Agent)、回调(Callbacks)等。LangChain提供了这些模块,使得开发变得更容易。它提供了许多LangChain本身没有实现的功能,特别是当你想复现最新的研究论文,或展示一个在网络上找不到参考的产品演示时,LangChain的模块可以极大地方便你的开发,提高开发质量并节省时间。
由于我们需要进行网络操作,使用了Python封装的Google服务,并且有对应的SERPAPI_API_KEY。此外,我们还需要OPENAI_API_KEY。
以下代码中,首先,导入InMemoryDocstore和FAISS模块。InMemoryDocstore用于在内存中存储文档数据,而FAISS是一个用于向量存储和相似性搜索的模块。接下来,定义了一个嵌入式向量模型embeddings_model,使用的是OpenAIEmbeddings,一般是1536维,每个维度代表一个特征,这个嵌入式向量模型可以将文本转换为向量表示。这里使用了FAISS模块,检索模型是IndexFlatL2,Faiss会有很多其他的检索算法,将嵌入查询函数embeddings_model.embed_query、索引和文档存储对象传递给FAISS的构造函数。InMemoryDocstore({})表示使用内存中的文档存储。
1. from langchain.docstore import InMemoryDocstore
2. from langchain.vectorstores.faiss import FAISS
3.
4. # 定义嵌入模型
5. embeddings_model = OpenAIEmbeddings()
6. # 将vectorstore初始化为空
7. import faiss
8. embedding_size = 1536
9. index = faiss.IndexFlatL2(embedding_size)
10. vectorstore = FAISS(embeddings_model.embed_query, index, InMemoryDocstore({}), {})
接下来,定义一些链(Chains),BabyAGI依赖于三个LLM链:
任务创建链:以选择要添加到列表中的新任务
任务优先级链:以重新确定任务的优先级
执行链:执行任务
TaskCreationChain类是LLMChain的子类,关键在于TaskCreationChain类,它在创建任务时提供了帮助。TaskCreationChain类提供了一个from_llm的类方法,用于从基本LLM(Language Model)对象创建LLMChain对象。这个方法接受一个llm参数和一个verbose参数,并返回一个LLMChain对象。在from_llm方法中,定义了一个task_creation_template的任务创建模板。该模板描述了任务创建AI的功能和使用的输入变量,包括目标(objective)、结果(result)、任务描述(task_description)和未完成任务(incomplete_tasks)等。
任务创建模板的内容为:
你是一个任务创建AI,它使用执行代理的结果来创建具有以下目标的新任务:{objective},最后完成的任务具有结果:{result}。此结果基于任务描述:{task_description}。这些是未完成的任务:{incomplete_tasks}。根据结果,创建AI系统需要完成的新任务,且不与未完成的任务重叠。以数组形式返回任务。
通过使用PromptTemplate,将任务创建模板和输入变量传递给LLMChain的构造函数,创建了一个具有任务创建功能的LLMChain对象,并将其作为结果返回。
1. class TaskCreationChain(LLMChain):
2. """生成任务的链."""
3.
4. @classmethod
5. def from_llm(cls, llm: BaseLLM, verbose: bool = True) -> LLMChain:
6. """获取响应解析器."""
7. task_creation_template = (
8. "You are an task creation AI that uses the result of an execution agent"
9. " to create new tasks with the following objective: {objective},"
10. " The last completed task has the result: {result}."
11. " This result was based on this task description: {task_description}."
12. " These are incomplete tasks: {incomplete_tasks}."
13. " Based on the result, create new tasks to be completed"
14. " by the AI system that do not overlap with incomplete tasks."
15. " Return the tasks as an array."
16. )
17. prompt = PromptTemplate(
18. template=task_creation_template,
19. input_variables=["result", "task_description", "incomplete_tasks", "objective"],
20. )
21. return cls(prompt=prompt, llm=llm, verbose=verbose)
这里使用的from_llm方法是基于大语言模型的,我们在这里明确指出,任务的创建是由任务创建代理(Task Creation Agent)使用大语言模型,根据提示(Prompts)来创建的。我们来看一下模板(templates),在这里使用的是 PromptTemplate。在这个模板中,我们描述了一个任务创建的AI,它利用执行代理(Execution Agent)的结果来创建任务。那么我们的执行代理在哪里呢?如图15-3所示,虚框标识的是执行代理。第一步是获取要执行的任务,并由执行代理完成任务。执行代理的结果经过丰富化的过程,结合上下文,然后传递给我们的任务创建代理。
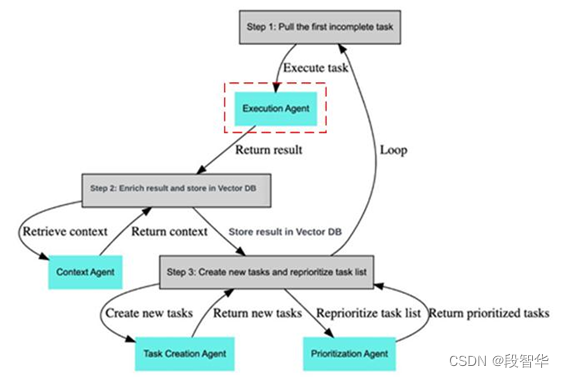
图15- 3 执行代理
创建具有以下目标的新任务:{objective}。显然,这个目标是你输入的一个目标,用户告诉你要做什么。最后完成的任务的结果是:{result},这是你的输出结果。如果目标是用户的输入,那么结果就是输出。这样说也不完全准确,因为我们讨论的是最后一个任务的输出结果。从大语言模型的角度来看,当它生成一个类似于报告的最终结果时,最后一个任务肯定是一个核心内容,但它还包含历史信息和其他的一些信息。这个结果是基于以下任务描述{task_description}的内容,接下来是未完成的任务:{incomplete_tasks}。根据这个结果,创建新的将要去完成的任务。这是它的指令,要求你创建新的任务,AI系统根据指令创建的任务不应与未完成的任务重叠。这是一个非常高质量的提示,因为它清晰地说明了在创建新任务时,不应与已存在的未完成任务有重叠,否则会有太多的重复信息。然后,将任务作为一个数组返回,我们将在其中将提示(Prompt)放入我们的 PromptTemplate,并设置 input_variables为[“result”,“task_description”,“incomplete_tasks”,“objective”]。这个目标(objective)显然是最终的目标。有时候我们开玩笑地说,开放式的目标是什么?目标就像一个婴儿,而这个婴儿是个老板。婴儿看起来好像发出了一个指令或者需求,就像一个婴儿有各种各样的需求一样。无论是人,还是物,我们都围绕着这个婴儿转,这就是你所处的环境。因此,当我们谈到目标时,我们经常说“婴儿是老板”。一方面,这是为了强调目标的重要性,另一方面,在团队协作和交流时,大家都明白这句话的含义,即一切都应与目标保持一致。 确实,在整个自主(Autonomous)模型的运行过程中,它会在每一步考虑你的目标,只有这样它才能以自主的方式执行任务。因此,这种自主方式实际上是有具体目标的,而这个目标是由用户输入的,只是用户输入了目标后,自动帮助他去完成。实际上,它是由用户控制的,因为用户给出了任务,它是面向任务的自主代理(Autonomous Agent)。
以上代码第21行,这里是创建LLMChain类的实例,我们返回的是一个LLMChain对象。该对象包含了我们的模型、提示(prompts)以及verbose状态。通常,大家会将verbose设置为True,因为这样可以看到更多的内部状态。这个对象是我们的任务创建代理(Task Creation Agent)。
接下来,另外一个代理是优先级排序代理(Prioritization Agent),它以一个链(Chain)的方式帮我们进行封装,这是确定任务优先级的链。
task_prioritization.py的代码实现:
1. class TaskPrioritizationChain(LLMChain):
2. """确定任务优先级的链."""
3.
4. @classmethod
5. def from_llm(cls, llm: BaseLLM, verbose: bool = True) -> LLMChain:
6. """获取响应解析器."""
7. task_prioritization_template = (
8. "You are an task prioritization AI tasked with cleaning the formatting of and reprioritizing"
9. " the following tasks: {task_names}."
10. " Consider the ultimate objective of your team: {objective}."
11. " Do not remove any tasks. Return the result as a numbered list, like:"
12. " #. First task"
13. " #. Second task"
14. " Start the task list with number {next_task_id}."
15. )
16. prompt = PromptTemplate(
17. template=task_prioritization_template,
18. input_variables=["task_names", "next_task_id", "objective"],
19. )
20. return cls(prompt=prompt, llm=llm, verbose=verbose)
TaskPrioritizationChain类继承至LLMChain类,是一个确定任务优先级的链。实现了一个from_llm类方法,接收llm和verbose两个参数,返回一个LLMChain对象。该方法的作用是获取响应解析器。其中,定义一个task_prioritization_template的字符串变量,包含任务名称和目标信息,并使用一些占位符,如{task_names}、{objective}和{next_task_id},用于在代码中进行动态替换。
任务优先级模板的内容为:
你是一个任务优先级AI,负责清理以下任务的格式,并重新排定优先级:{task_names}。考虑你团队的最终目标:{objective},不要删除任何任务,以编号列表的形式返回结果,如:#.第一个任务 #.第二个任务 启动编号为{next_task_id}的任务列表
接下来,使用PromptTemplate创建了一个prompt的实例,该实例的作用是将上述占位符替换为实际的信息。然后,返回一个TaskPrioritizationChain的实例对象,该对象包含了prompt、llm和verbose等属性。
TaskPrioritizationChain类的from_llm方法返回的是一个LLMChain对象,这一点是显而易见的。在这个方法中,我们可以看到一些重要的指令。注意,我们之前已经明确说明了,这个模型是GPT-4的服务,用于管理任务的优先级。因此,在指令中,你需要明确地告诉GPT-4要做什么,“你是一个任务优先级AI,负责清理格式,并重新排定以下任务的优先级:{task_names}。”这句话,告诉了模型它需要清理和重新排序任务。这里面的一些符号,如“cleaning the formatting”、 “reprioritizing”都是动名词的形式,语言模型会根据符号之间的关系,去获取相应的信息。这种观点在我们之前的论文中已经非常清楚地被阐述过,即模型本身并不会思考,它只是将文本基于符号构建的模式隐式提取出来。由于有这些模式,它会涉及到一些步骤。其中,{task_names}是具体任务的列表。同时,你需要明确告诉模型,你的团队的终极目标{objective}是什么。注意,一定不要删除任何任务,因为它们都是核心信息。如果模型将它们删除了,将会产生非常大的影响。但如果从应用的角度来看,你可能希望它移除一些任务,以更好地适应特定个体的需求。返回结果是一个编号列表,例如:“#. 第一个任务,#.第二个任务”,并从数字{next_task_id}开始计任务列表,这里的列表可以看作是计算机中的堆栈,模板的输入变量是[“task_names”, “next_task_id”, “objective”],返回一个LLMChain实例。