目录
- 前言
- 一、认识虚拟DOM
- 用 JS 对象模拟 DOM 结构
- 用JS对象模拟DOM节点的好处
- 为什么要使用虚拟 DOM 呢?
- 虚拟Dom 和 diff算法的关系
- 二、认识diff算法
- diff算法的优化
- key的作用
- diff算法 在什么时候执行?
- 三、深入diff算法源码
- patch 函数
- sameVnode 函数
- patchVnode 函数
- updateChildren 函数
- 为什么会有头对尾,尾对头的操作?
- 总结
- 1. 虚拟DOM的解析过程
- 2. diff 算法的原理
前言
这是一个系列学习源码的文章,感兴趣的可以继续阅读其他文章
Vue源码学习 - new Vue初始化都做了什么?
Vue源码学习 - 数据响应式原理
Vue源码学习 - 异步更新队列 和 nextTick原理
因为 Diff 算法,计算的就是虚拟 DOM 的差异,所以先铺垫一点点虚拟 DOM,了解一下其结构,再去看Diff 算法原理,循循渐进会更好些。
渲染真实的 DOM 时,并不是暴力覆盖原有的 DOM ,而是比对新旧两个vnode(虚拟节点),如果不是同一个节点,删除老的,替换成新的;如果是同一个节点,就复用老节点,增加新节点的属性。
一、认识虚拟DOM
虚拟 DOM 简单说就是 用JS对象来模拟 DOM 结构。
用 JS 对象模拟 DOM 结构
用 JS 对象模拟 DOM 结构的例子:
<template>
<div id="app" class="container">
<h1>铁锤妹妹</h1>
</div>
</template>
上面的模板转成 JS对象 就是下面这样。
这样的 DOM 结构就称之为 虚拟 DOM (Virtual Node),简称 vnode。
{
tag:'div',
props:{ id:'app', class:'container' },
children: [
{ tag: 'h1', children:'铁锤妹妹' }
]
}
它的表达方式就是把每一个标签都转为一个对象,这个对象可以有三个属性:tag、props、children。
- tag:必选。就是标签也可以是组件或者函数。
- props:非必选。就是这个标签上的属性和方法。
- children:非必选。就是这个标签的内容或者子节点,如果是文本节点就是字符串,如果有子节点就是数组。换句话说 如果判断 children 是字符串的话,就表示一定是文本节点,这个节点肯定没有子元素
用JS对象模拟DOM节点的好处
假设在一次操作中有1000个节点 需要更新,那么 虚拟DOM 不会立即去操作Dom,而将这1000次更新的 diff 内容保存到本地的一个JS对象上,之后将这个 JS 对象一次性 attach 到 DOM 树上,最后再进行后续的操作,这样子就避免了大量没必要的计算。
所以,用JS对象模拟DOM节点的好处就是:先将页面的更新全部反映到 虚拟DOM 上,这样子就 先操作内存中的JS对象。值得注意的是,操作内存中的 JS对象 速度是相当快的。然后等到全部DOM节点更新完成后,再将最后的 JS对象 映射到 真实DOM 上,交给 浏览器 去绘制。
这样就解决了 真实DOM 渲染速度慢,性能消耗大 的问题。
为什么要使用虚拟 DOM 呢?
我们先创建一个空div,打印看看上面自带的所有属性和事件。
let div = document.createElement('div')
let props = ''
for (let key in div) {
props += key + ' '
}
console.log(props)
打印结果:

如图可以看出原生 DOM 有非常多的属性和事件,就算是创建一个空div也要付出不小的代价。而使用虚拟 DOM 来提升性能的点在于 DOM 发生变化的时候,通过 diff 算法和数据改变前的 DOM 对比,计算出需要更改的 DOM,然后只对变化的 DOM 进行操作,而不是更新整个视图。
虚拟Dom 和 diff算法的关系
其实,vdom 是一个大的概念,而 diff算法 是 vdom 中的一部分。vdom 的核心价值在于最大程度上减少 真实DOM 的频繁更新。
vdom 通过把 DOM 用 JS的方式 进行模拟,通过比较新旧虚拟DOM,只更新差异部分,然后批量操作真实DOM,减少了对真实DOM 的频繁操作,提高了性能。那么这个对比的过程就是diff算法。也就是说两者是包含关系,如下图所示:

二、认识diff算法
diff算法的优化
假如有1000个节点,就需要计算 1000³ 次,也就是10亿次,这样是无法接受的,所以 Vue 里使用 Diff 算法的时候都遵循深度优先,同层比较的策略做了一些优化,来计算出最小变化。
1)只比较同一层级,不跨级比较
Diff 过程只会把同颜色框起来的同一层级的 DOM 进行比较,这样来简化比较次数。
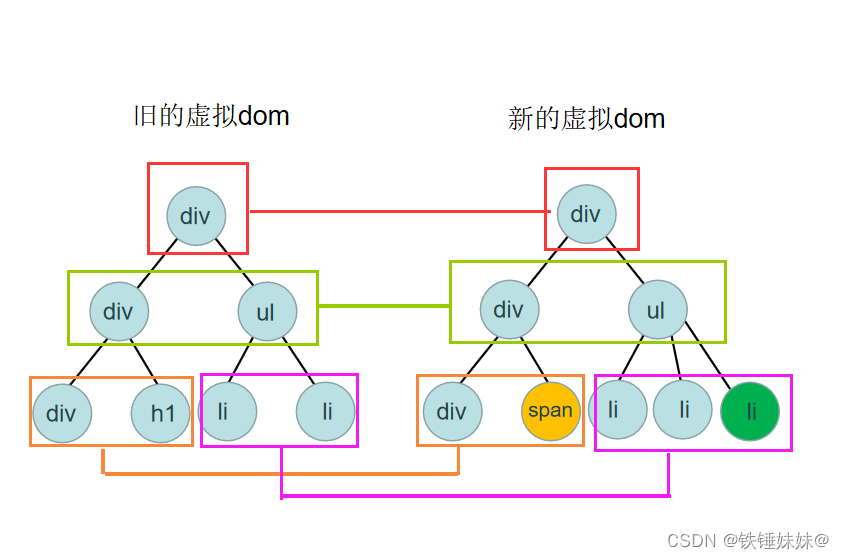
2) 比较tag标签名
如果同一层级的标签名不同,就直接删掉旧的虚拟 DOM 重建,不继续做深度比较。
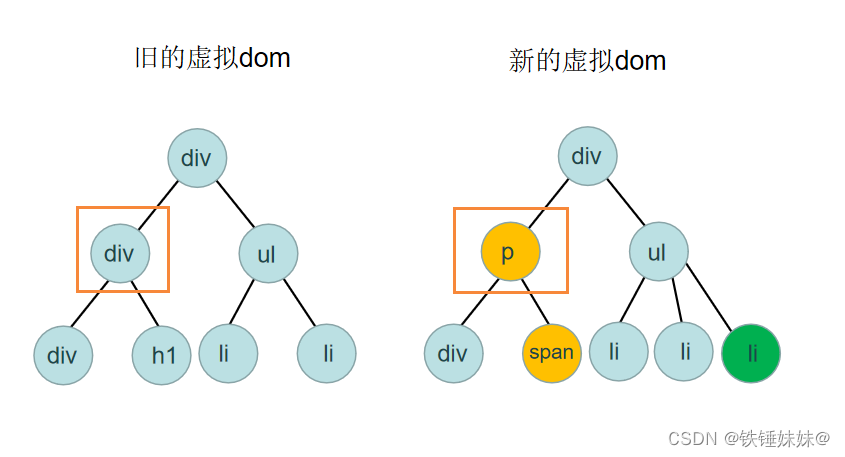
3)比较 key
如果标签名相同,key 也相同,就会认为是相同节点,不继续做深度比较。
比如我们写 v-for 的时候会比较 key,不写 key 就会报错,这也就是因为 Diff 算法需要比较 key。
key的作用
通过图形例子会更好理解些:
比如有一个列表,需要在 列表中间 插入一个元素,会发生什么变化呢?先看个图

如图的 li1 和 li2 不会重新渲染,而 li3、li4、li5 都会重新渲染。
因为在不使用 key 或者列表的 index 作为 key 的时候,每个元素对应的位置关系都是索引 index,上图中的结果直接导致我们插入的元素到后面的全部元素,对应的位置关系都发生了变更,所以全部都会执行更新操作,这不是我们想要的,我们希望的是只渲染添加的那一个元素 li5,其他四个元素不做任何变更,就地复用就好,不要重新渲染。
而在使用唯一 key 的情况下,每个元素对应的位置关系就是 key,看一下使用唯一 key 值的情况下:

这样如图中的 li3 和 li4 就不会重新渲染,因为元素内容没发生改变,对应的位置关系也没有发生改变。
这也是为什么 v-for 必须要写 key,而且不建议开发中使用数组的 index 作为 key 的原因。
总结一下:
- key 的作用主要是为了更高效的更新虚拟 DOM,因为它可以非常精确的找到相同节点,diff 操作可以更高效。
如果数据项的顺序发生了改变,Vue 不会移动 DOM 元素来匹配数据项的顺序,而是简单“就地复用”此处的每个元素。
diff算法 在什么时候执行?
1. 页面
首次渲染的时候,会调用一次 patch 并创建新的 vnode,不会进行更深层次的比较。
2. 然后就是在组件中的数据发生变化的时候,会触发setter,然后通过notify()通知watcher,对应的watcher会通知更新,并执行更新函数,它会执行render函数获取新的虚拟 DOM,然后执行patch对比旧的虚拟 DOM,并计算出最小变化,然后再去根据这个最小变化去更新真实的DOM,也就是视图更新。
三、深入diff算法源码
patch 函数
用于比较新旧 VNode,并进行 DOM 更新的核心函数。
需要注意的是,patch 函数在进行 DOM 更新时会尽可能地复用已有的 DOM 元素和节点,从而提高性能。它会通过对比新旧 VNode 的差异,只对真正发生变化的部分进行更新,而不会重新创建整个 DOM 结构。
主要流程是这样的:
-
vnode 不存在,oldVnode 存在,就删掉 oldVnode。(vnode 不存在表示组件被移除或不在需要渲染,为保持视图与数据的同步,所以删掉 oldVnode)
-
vnode 存在,oldVnode 不存在,就创建 vnode。
-
两个都存在的话,通过
sameVnode()比较两者是否是同一节点。1)如果是同一节点的话,通过
patchVnode()函数进行后续对比节点文本变化或者子节点变化。
2)如果不是同一节点,则删除该节点重新创建新节点进行替换(对于组件节点,Vue 将尽可能地复用已有的组件实例,而不是销毁和重新创建组件)
// src/core/vdom/patch.ts
// 两个判断函数
export function isUndef(v: any): v is undefined | null {
return v === undefined || v === null
}
export function isDef<T>(v: T): v is NonNullable<T> {
return v !== undefined && v !== null
}
return function patch(oldVnode, vnode, hydrating, removeOnly) {
// 当新的 VNode 不存在时,如果旧的 VNode 存在,则调用旧的 VNode 的销毁钩子函数,以确保在组件更新过程中正确地执行销毁逻辑。
// 如果新的 VNode 不存在,通常表示组件 被移除 或者 不再需要渲染。
// 如果旧的 VNode 仍然存在,它对应的 DOM 元素需要被删除,以保持视图与数据的同步。确保不留下无用的 DOM 节点,避免内存泄漏和不必要的性能开销。
if (isUndef(vnode)) {
if (isDef(oldVnode)) invokeDestroyHook(oldVnode)
return
}
let isInitialPatch = false
const insertedVnodeQueue: any[] = []
// 如果 oldVnode 不存在的话,新的 vnode 是肯定存在的,比如首次渲染的时候
if (isUndef(oldVnode)) {
isInitialPatch = true
// 就创建新的 vnode
createElm(vnode, insertedVnodeQueue)
} else {
// 剩下的都是新的 vnode 和 oldVnode 都存在的话
// 旧的 VNode是不是元素节点
const isRealElement = isDef(oldVnode.nodeType)
// 如果旧的 VNode 是真实的 DOM 元素节点 && 与新的 VNode 是同一个节点
if (!isRealElement && sameVnode(oldVnode, vnode)) {
// 如果是,就用 patchVnode 对现有的根节点进行更新操作,而不是重新创建整个组件树。
patchVnode(oldVnode, vnode, insertedVnodeQueue, null, null, removeOnly)
} else {
// 如果不是同一元素节点的话
if (isRealElement) {
// const SSR_ATTR = 'data-server-rendered'
// 如果是元素节点 并且有 'data-server-rendered' 这个属性
if (oldVnode.nodeType === 1 && oldVnode.hasAttribute(SSR_ATTR)) {
// 就是服务端渲染,删掉这个属性
oldVnode.removeAttribute(SSR_ATTR)
hydrating = true
}
// 就是服务端渲染的,删掉这个属性
if (isTrue(hydrating)) {
if (hydrate(oldVnode, vnode, insertedVnodeQueue)) {
invokeInsertHook(vnode, insertedVnodeQueue, true)
return oldVnode
} else if (__DEV__) {
warn('一段很长的警告信息')
}
}
// 如果不是服务端渲染的,或者混合失败,就创建一个空的注释节点替换 oldVnode
oldVnode = emptyNodeAt(oldVnode)
}
// 拿到 oldVnode 的父节点
const oldElm = oldVnode.elm
const parentElm = nodeOps.parentNode(oldElm)
// 根据新的 vnode 创建一个 DOM 节点,挂载到父节点上
createElm(
vnode,
insertedVnodeQueue,
oldElm._leaveCb ? null : parentElm,
nodeOps.nextSibling(oldElm)
)
// 如果新的 vnode 的根节点存在,就是说根节点被修改了,就需要遍历更新父节点
if (isDef(vnode.parent)) {
let ancestor = vnode.parent
const patchable = isPatchable(vnode)
// 递归更新父节点下的元素
while (ancestor) {
// 卸载老根节点下的全部组件
for (let i = 0; i < cbs.destroy.length; ++i) {
cbs.destroy[i](ancestor)
}
// 替换现有元素
ancestor.elm = vnode.elm
if (patchable) {
for (let i = 0; i < cbs.create.length; ++i) {
cbs.create[i](emptyNode, ancestor)
}
const insert = ancestor.data.hook.insert
if (insert.merged) {
for (let i = 1; i < insert.fns.length; i++) {
insert.fns[i]()
}
}
} else {
registerRef(ancestor)
}
// 更新父节点
ancestor = ancestor.parent
}
}
// 如果旧节点还存在,就删掉旧节点
if (isDef(parentElm)) {
removeVnodes([oldVnode], 0, 0)
// 否则直接卸载 oldVnode
} else if (isDef(oldVnode.tag)) {
invokeDestroyHook(oldVnode)
}
}
}
// 返回更新后的节点
invokeInsertHook(vnode, insertedVnodeQueue, isInitialPatch)
return vnode.elm
}
}
sameVnode 函数
这个是用来判断 新旧Vnode 是不是 同一节点 的函数。
function sameVnode(a, b) {
return (
a.key === b.key && // key 是不是一样
a.asyncFactory === b.asyncFactory && // 是不是异步组件
((a.tag === b.tag && // 标签是不是一样
a.isComment === b.isComment && // 是不是注释节点
isDef(a.data) === isDef(b.data) && // 内容数据是不是一样
sameInputType(a, b)) || // 判断 input 的 type 是不是一样
(isTrue(a.isAsyncPlaceholder) && isUndef(b.asyncFactory.error))) // 判断区分异步组件的占位符否存在
)
}
patchVnode 函数
这个是在新的 vnode 和 oldVnode 是同一节点的情况下,才会执行的函数,主要是对比 节点文本变化 或 子节点变化。
主要流程是这样的:
-
如果 oldVnode 和 vnode 的引用地址是一样的,就表示节点没有变化,直接返回。
-
如果 oldVnode 的 isAsyncPlaceholder 存在,就跳过异步组件的检查,直接返回。
-
如果 oldVnode 和 vnode 都是静态节点 && 有相同的key && vnode是克隆节点 || v-once 指令控制的节点时,把 oldVnode.elm 和 oldVnode.child 都复制到 vnode 上,然后返回。
-
如果 vnode 不是文本节点 也不是注释的情况下
1)如果 oldVnode 和 vnode 都有子节点,并且
子节点不一样的时候,调用updateChildren()函数 更新子节点。
2)如果只有vnode有子节点,就调用addVnodes()创建子节点。
3)如果只有oldVnode有子节点,就调用removeVnodes()删除该子节点。
4)如果oldVnode是文本节点,就清空。 -
如果 vnode 是文本节点但是和 oldVnode 文本内容不一样,就更新文本
function patchVnode(
oldVnode, // 旧的虚拟 DOM 节点
vnode, // 新的虚拟 DOM 节点
insertedVnodeQueue,
ownerArray,
index,
removeOnly?: any
) {
// 新老节点引用地址是一样的,return 返回
// 比如 props 没有改变的时候,子组件就不做渲染,直接复用
if (oldVnode === vnode) {
return
}
if (isDef(vnode.elm) && isDef(ownerArray)) {
vnode = ownerArray[index] = cloneVNode(vnode)
}
const elm = (vnode.elm = oldVnode.elm)
// 如果当前节点是注释或 v-if 的,或者是异步函数,就跳过检查异步组件
if (isTrue(oldVnode.isAsyncPlaceholder)) {
if (isDef(vnode.asyncFactory.resolved)) {
hydrate(oldVnode.elm, vnode, insertedVnodeQueue)
} else {
vnode.isAsyncPlaceholder = true
}
return
}
// 当前节点是静态节点的时候,key 也一样,并且vnode 是克隆节点,或者有 v-once 的时候,就直接赋值返回
if (
isTrue(vnode.isStatic) &&
isTrue(oldVnode.isStatic) &&
vnode.key === oldVnode.key &&
(isTrue(vnode.isCloned) || isTrue(vnode.isOnce))
) {
vnode.componentInstance = oldVnode.componentInstance
return
}
let i
const data = vnode.data
if (isDef(data) && isDef((i = data.hook)) && isDef((i = i.prepatch))) {
i(oldVnode, vnode)
}
// 获取子元素列表
const oldCh = oldVnode.children
const ch = vnode.children
if (isDef(data) && isPatchable(vnode)) {
for (i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode)
if (isDef((i = data.hook)) && isDef((i = i.update))) i(oldVnode, vnode)
}
// 如果新节点不是文本节点,也就是说有子节点
if (isUndef(vnode.text)) {
// 如果新旧节点都有子节点
if (isDef(oldCh) && isDef(ch)) {
// 但是子节点不一样,就调用 updateChildren 函数,对比子节点
if (oldCh !== ch)
updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly)
} else if (isDef(ch)) {
// 如果只有新节点有子节点的话,新增子节点
// 如果 旧节点 是文本节点,表示它没有子节点,就清空
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '')
// 新增 子节点
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
} else if (isDef(oldCh)) {
// 如果只有 旧节点 有子节点,就删除
removeVnodes(oldCh, 0, oldCh.length - 1)
} else if (isDef(oldVnode.text)) {
// 如果旧节点是文本节点,就清空
nodeOps.setTextContent(elm, '')
}
// 新老节点都是文本节点,且文本不一样,就更新文本
} else if (oldVnode.text !== vnode.text) {
nodeOps.setTextContent(elm, vnode.text)
}
if (isDef(data)) {
if (isDef((i = data.hook)) && isDef((i = i.postpatch))) i(oldVnode, vnode)
}
}
updateChildren 函数
这个是新的 vnode 和 oldVnode 都有子节点,且 子节点不一样 的时候进行对比子节点的函数。
这个函数 很关键,很关键!
比如现在有两个子节点列表对比,对比主要流程如下:
循环遍历两个列表,循环停止条件是:其中一个列表的开始指针 startIdx 和 结束指针 endIdx 重合。
循环内容是:
- 新的头 和 老的头 对比
- 新的尾 和 老的尾 对比
- 新的尾 和 老的头 对比
- 新的头 和 老的尾 对比
以上四种只要有一种判断相等,就调用 patchVnode() 对比节点文本变化 或 子节点变化,然后移动对比的下标,继续下一轮循环对比。
如果以上 四种情况 都没有命中,就要用 循环 来寻找了,不断拿新的节点的 key 去老的 children 里找。
-
如果 没找到,就创建一个新的节点。
-
如果 找到了,再对比标签是不是同一节点。
1)如果是同一个节点,调用
pathVnode()进行后续对比,然后把这个节点插入到老的开始前面,并且移动新的开始下标,继续下一轮循环对比。
2)如果不是相同节点,就创建一个新的节点。 -
如果老的 vnode 先遍历完,就添加 新的vnode 没有遍历的节点。
-
如果新的 vnode 先遍历完,说明老节点中还有剩余节点,就删除 老的vnode 没有遍历的节点。
为什么会有头对尾,尾对头的操作?
- 头对尾 和 尾对头是 Diff 算法的一种优化策略,目的是尽可能地
复用已存在的 DOM 节点来减少重新渲染的成本。- 头对尾的操作指的是比较新旧节点列表中开头和结尾位置的节点对,然后逐步向内部移动比较。这样做的原因是在许多情况下,节点的变更主要发生在列表的首尾位置,而中间的节点相对稳定。通过首尾节点的对比,可以避免不必要的节点移动和更新,只需对新增或删除的节点进行插入或删除操作。
- 尾对头的操作与头对尾类似。
function updateChildren(
parentElm,
oldCh,
newCh,
insertedVnodeQueue,
removeOnly
) {
let oldStartIdx = 0 // 老 vnode 遍历的开始下标
let newStartIdx = 0 // 新 vnode 遍历的开始下标
let oldEndIdx = oldCh.length - 1 // 老 vnode 遍历的结束下标
let oldStartVnode = oldCh[0] // 老 vnode 列表第一个子元素
let oldEndVnode = oldCh[oldEndIdx] // 老 vnode 列表最后一个子元素
let newEndIdx = newCh.length - 1 // 新 vnode 遍历的结束下标
let newStartVnode = newCh[0] // 新 vnode 列表第一个子元素
let newEndVnode = newCh[newEndIdx] // 老 vnode 列表最后一个子元素
let oldKeyToIdx, idxInOld, vnodeToMove, refElm
const canMove = !removeOnly
if (__DEV__) {
checkDuplicateKeys(newCh)
}
// 循环,规则是开始指针向右移动,结束指针向左移动
// 当开始 和 结束的 指针重合 的时候就结束循环
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx] // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
// 老的头和新的头对比
} else if (sameVnode(oldStartVnode, newStartVnode)) {
// 是同一节点 递归调用 继续对比这两个节点的内容和子节点
patchVnode(
oldStartVnode,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
)
// 然后把指针后移一位,从前往后依次对比
// 比如第一次对比两个列表[0],然后对比[1]...,后面同理
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
// 老结束和新结束对比
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(
oldEndVnode,
newEndVnode,
insertedVnodeQueue,
newCh,
newEndIdx
)
// 然后把指针前移一位,从后往前依次对比
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
// 老开始和新结束对比
} else if (sameVnode(oldStartVnode, newEndVnode)) {
patchVnode(
oldStartVnode,
newEndVnode,
insertedVnodeQueue,
newCh,
newEndIdx
)
canMove && nodeOps.insertBefore(parentElm,oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm))
// 老的列表从前往后取值,新的列表从后往前取值,然后对比
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
// 老结束和新开始对比
} else if (sameVnode(oldEndVnode, newStartVnode)) {
patchVnode(
oldEndVnode,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
)
canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
// 老的列表从后往前取值,新的列表从前往后取值,然后对比
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
// 以上四种情况都没有命中的情况
} else {
if (isUndef(oldKeyToIdx))
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
// 拿到新开始的 key,在老的 children 里去找有没有某个节点有这个 key
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
// 新的 children 里有,可是没有在老的 children 里找到对应的元素
if (isUndef(idxInOld)) {
// 创建新的元素
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
)
} else {
// 在老的 children 里找到了对应的元素
vnodeToMove = oldCh[idxInOld]
// 判断是否是同一个元素
if (sameVnode(vnodeToMove, newStartVnode)) {
// 是同一节点 递归调用 继续对比这两个节点的内容和子节点
patchVnode(
vnodeToMove,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
)
oldCh[idxInOld] = undefined
canMove &&
nodeOps.insertBefore(
parentElm,
vnodeToMove.elm,
oldStartVnode.elm
)
} else {
// 不同的话,就创建新元素
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
)
}
}
newStartVnode = newCh[++newStartIdx]
}
}
// 说明老的 vnode 先遍历完
if (oldStartIdx > oldEndIdx) {
// 就添加从 newStartIdx 到 newEndIdx 之间的节点
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm
addVnodes(
parentElm,
refElm,
newCh,
newStartIdx,
newEndIdx,
insertedVnodeQueue
)
// 否则就说明新的 vnode 先遍历完
} else if (newStartIdx > newEndIdx) {
// 就删除老的 vnode 里没有遍历的结点
removeVnodes(oldCh, oldStartIdx, oldEndIdx)
}
}
总结
1. 虚拟DOM的解析过程
首先对将要插入到文档中的DOM树结构进行分析,使用 js对象 将其表示出来,比如一个元素对象,包含 TagName 、props 和 Children 这些属性。然后将这个 js对象树 给保存下来,最后再将DOM片段插入到文档中。
当页面的状态发生改变,需要对页面的DOM的结构进行调整的时候,首先根据变更的状态,重新构建起一棵对象树,然后将这棵 新的对象树 和 旧的对象树 进行 比较,记录下两棵树的的差异。
最后将记录的有差异的地方应用到 真正的DOM树 中去,这样视图就更新了。
2. diff 算法的原理
在新老虚拟dom对比时:
首先,对比节点本身,通过 sameVnode() 判断是否是同一节点。
- 如果不为相同节点,则 删除 该节点重新创建新节点进行替换。
- 如果为相同节点,进行
patchVnode(),判断如何对该节点的子节点进行处理。
先判断一方有子节点一方没有子节点的情况。
1)如果新的children 有子节点,就调用 addVnodes() 创建新子节点。
2)如果新的children 没有子节点, 就调用 removeVnodes() 删除旧子节点。
如果都有子节点,但是子节点不一样时候,则进行 updateChildren(),判断如何对这些新老节点的子节点进行操作(diff 核心)。
匹配时,找到相同的子节点,递归调用 patchVnode() 函数来进一步比较和更新这些子节点。
在 diff 中,只对同层的子节点进行比较,放弃跨级的节点比较,使得时间复杂从 O(n3)降低值 O(n),也就是说,只有当新旧 children都为多个子节点时才需要用核心的 Diff 算法进行同层级比较。
可参考:
面试中的网红虚拟DOM,你知多少呢?深入解读diff算法
深入浅出虚拟 DOM 和 Diff 算法,及 Vue2 与 Vue3 中的区别