目的:可以解决在本地实现根据图片查找相似图片的功能
背景:由于需要查找别人代码保存的图像的命名,但由于数据集是cifa10图像又小又多,所以直接找很费眼睛,所以实现用该代码根据图像查找图像,从而得到保存图像的命名。
方法:
1、将需要查找的图像(查询图像, queryImg)放入queryImgs文件夹,以及一个存放数据库图像的文件夹datasetImgs
2、批量读取查询图像
3、根据MSE(均方误差)和SSIM(结构相似性指数)计算权重,来比较两张图像的相似程度。
其中:
MSE(均方误差):计算两张图片的每个像素值之间的平均差值,结果越小表示两张图片越相似。
SSIM(结构相似性指数):比较两张图片的结构、亮度和对比度等方面的相似程度,结果介于-1到1之间,越接近1表示两张图片越相似。
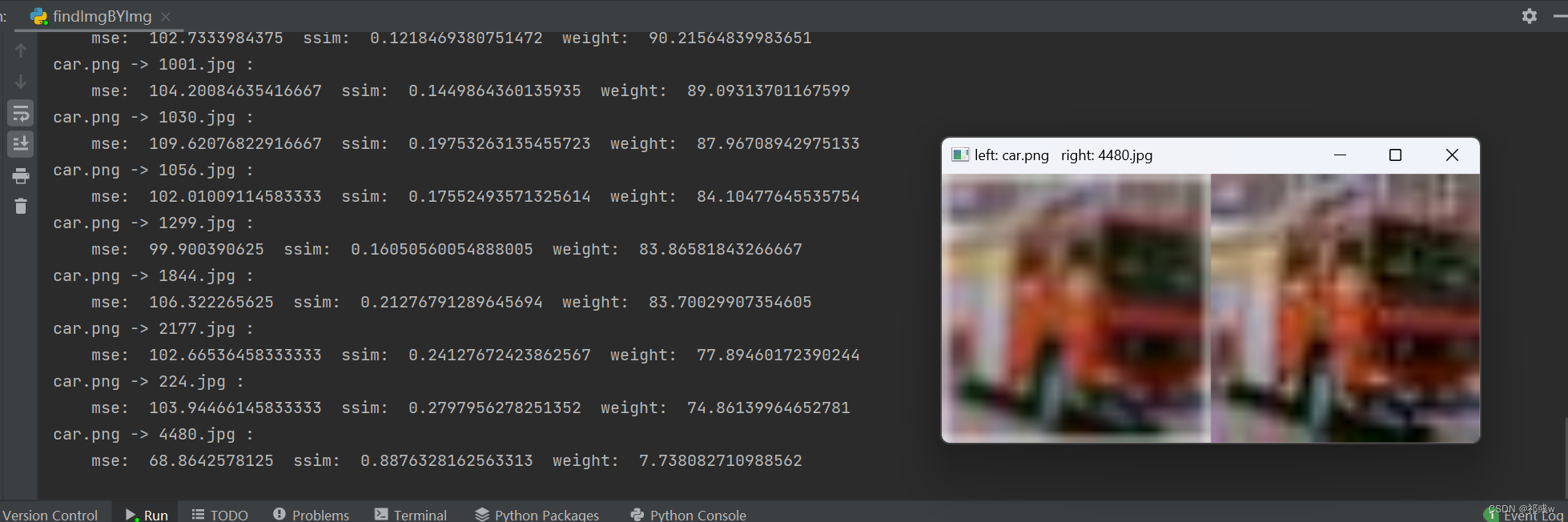
4、以224×224的大小显示当前queryImg和bestImg(数据库图像中相似度最高的图像),title为queryImg和bestImg的文件名。
5、将bestImg移动到命名为“dstImgs”的文件夹,并保留源文件名称。
运行速度:
在1万张32×32图像中,平均检索速度:34.64s左右(不包括对数据库图像使用transform统一大小),可以为权重设置阈值提前结束检索(建议阈值为小于10)。
限制:
1、需要明确查询图像和数据库图像的大小,并手动更改对应注释的代码。
2、检索结果唯一,不能检索到多个结果(由于我知道我的datasets里只有唯一对应的图像,所以代码逻辑是只保存最相似的图像,或第一个相似度权重小于10的图像),不过可以自行修改代码实现检索多个结果。
代码:
import os
import shutil
import time
from skimage.metrics import structural_similarity as compare_ssim
from torchvision.transforms import transforms
from PIL import Image
import cv2
import numpy as np
data_transform = transforms.Resize((32, 32)) # 数据库图像和查询图像统一大小,大小为32×32
show_transform = transforms.Resize((224, 224)) # 显示图像大小为224×224
def transformImg(img, transform):
img = transform(Image.fromarray(img))
img = np.array(img)
return img
root_path = "./queryImgs" # 查询图像所在的文件夹
dataset_path = "./datasetImgs" # 数据库图像所在的文件夹
for query_img in os.listdir(root_path):
query_img_path = os.path.join(root_path, query_img)
query_img_obj = cv2.imread(query_img_path)
query_img_obj = transformImg(query_img_obj, data_transform)
best_mse = np.Inf
best_ssim = np.Inf
best_weight = np.Inf
best_img_name = ""
best_img_path = ""
best_img_obj = None
print("Start search Img: ", query_img)
start_time = time.time()
for dataset_img in os.listdir(dataset_path):
dataset_img_path = os.path.join(dataset_path, dataset_img)
dataset_img_obj = cv2.imread(dataset_img_path)
# # 统一数据库图像大小, 若数据库图像大小一致则可以只调整查询图像大小。
# dataset_img_obj = transformImg(dataset_img_obj, data_transform)
mse = ((query_img_obj - dataset_img_obj) ** 2).mean()
ssim = compare_ssim(query_img_obj, dataset_img_obj, channel_axis=query_img_obj.shape[2] - 1)
weight = mse * (1 - ssim)
if weight < best_weight:
best_mse = mse
best_ssim = ssim
best_weight = weight
best_img_path = dataset_img_path
best_img_obj = dataset_img_obj
best_img_name = dataset_img
print(query_img, "->", dataset_img, ": ")
print("\tmse: ", best_mse, " ssim: ", ssim, " weight: ", weight)
# 权重小于10提前结束检索
if best_weight < 10:
break
elapsed_time = time.time() - start_time
best_img = np.hstack([transformImg(query_img_obj, show_transform), transformImg(best_img_obj, show_transform)])
cv2.imshow("left: {} right: {}".format(query_img, best_img_name), best_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
if not os.path.exists("./dstImgs"): os.mkdir("./dstImgs")
shutil.copy(best_img_path, './dstImgs/' + best_img_name)
print("save as: ", './dstImgs/' + best_img_name, " time elapsed: ", elapsed_time, "\n")
结果: