搜索引擎日志分析

要求:
读取文件转换成RDD,并完成:
- 打印输出:热门搜索时间段(小时精度)Top3
- 打印输出:热门搜索词Top3
- 打印输出:统计黑马程序员关键字在哪个时段被搜索最多
- 将数据转换为JSON格式,写出为文件
代码:
"""
综合案例
要求:
读取文件转换成RDD,并完成:
打印输出:热门搜索时间段(小时精度)Top3
打印输出:热门搜索词Top3
打印输出:统计黑马程序员关键字在哪个时段被搜索最多
将数据转换为JSON格式,写出为文件
"""
# 构建执行环境入口对象
import json
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/Python/Python311/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
conf.set('spark.default.parallelism', '1')
sc = SparkContext(conf=conf)
# 读取文件转换成RDD,并完成:
rdd = sc.textFile("E:/百度网盘/1、Python快速入门(8天零基础入门到精通)/资料/第15章资料/资料/search_log.txt")
# print(rdd.collect())
# TOOP 需求1:热门搜索时间段(小时精度)Top3
# 1.1 取出全部的时间并转换为小时
# 1.2 转换为(小时,1)的二元元组
# 1.3 Key分组聚合Value
# 1.4 排序(降序)
# 1.5 取前三
# result1 = rdd.map(lambda x: x.split("\t")).\
# map(lambda x: x[0][:2]).\
# map(lambda x: (x, 1)).\
# reduceByKey(lambda a, b: a + b).\
# sortBy(lambda x: x[1], ascending=False, numPartitions=1).\
# take(3)
# print("需求1的结果:", result1)
result1 = rdd.map(lambda x: (x.split("\t")[0][:2], 1)). \
reduceByKey(lambda a, b: a + b). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1). \
take(3)
print("需求1的结果:", result1)
# TOOP 需求2:热门搜索词Top3
# 2.1 取出全部的搜索词
# 2.2 (词,1)二元元组
# 2.3 分组聚合
# 2.4 排序
# 2.5 Top3
result2 = rdd.map(lambda x: (x.split("\t")[2], 1)). \
reduceByKey(lambda a, b: a + b). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1). \
take(3)
print("需求2的结果:", result2)
# TOOP 需求3:统计黑马程序员关键字在哪个时段被搜索最多
# 3.1 过滤内容,只保留黑马程序员关键字
# 3.2 转换为(小时,1)的二元元组
# 3.3 Key分组聚合Value
# 3.4 排序(降序)
# 3.5 取前1
result3 = rdd.map(lambda x: x.split("\t")).\
filter(lambda x: x[2] == '黑马程序员').\
map(lambda x: (x[0][:2], 1)).\
reduceByKey(lambda a, b: a + b).\
sortBy(lambda x: x[1], ascending=False, numPartitions=1).\
take(1)
print("需求3的结果:", result3)
# TOOP 需求4:将数据转换为JSON格式,写出为文件
# 4.1 转换为JSON格式的RDD
# 4.2 写出为文件
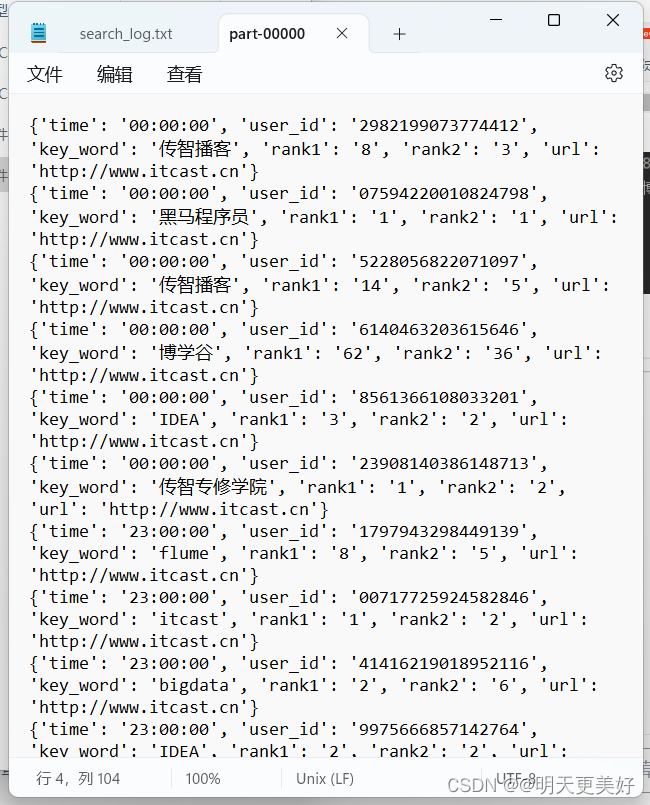
rdd.map(lambda x: x.split("\t")).\
map(lambda x: {'time': x[0], 'user_id': x[1], 'key_word': x[2], 'rank1': x[3], 'rank2': x[4], 'url': x[5]}).\
saveAsTextFile("D:/output_json")