什么是事务
事务是由数据库中一系列的访问和更新组成的逻辑执行单元。
事务的逻辑单元中可以是一条SQL语句,也可以是一段SQL逻辑,这段逻辑要么全部执行成功,要么全部执行失败。
事务处理的基本原则是“原子性”、“一致性”、“隔离性”和“持久性”:
- 原子性:事务中的所有操作必须全部成功,或者全部失败。如果一个操作失败,那么事务将回滚,数据库将不会被更改
- 一致性:事务必须使数据库从一个一致状态转换到另一个一致状态。这意味着事务必须确保数据库中的数据始终处于正确的状态
- 隔离性:事务的执行不会被其他事务的执行干扰。这意味着在一个事务执行期间,其他事务无法看到该事务正在执行的更改
- 持久性:一旦事务提交,其更改将永久保存在数据库中。即使数据库发生故障,事务的更改也不会丢失
举个最常见的例子,你早上出去买早餐,支付宝扫码付款给早餐老板,这就是一个简单的转账过程,会包含两步:
- 从你的支付宝账户扣款10元
- 早餐老板的账户增加10元
这两步其中任何一部出现问题,都会导致整个账务出现问题:
- 假如你的支付宝账户扣款10元失败,早餐老板的账户增加成功,那你就Happy了,相当于马云请你吃早餐了
- 假如你的支付宝账户扣款10元成功,早餐老板的账户增加失败,那你就悲剧了,早餐老板不会放过你,会让你重新付款,相当于你请马云吃早餐了
事务就是用来保证一系列操作的原子性,上述两步操作,要么全部执行成功,要么全部执行失败。
实现
数据库为了保证事务的原子性和持久性,引入了redo log和undo log。
redo log
redo log是重做日志,通常是物理日志,记录的是物理数据页的修改,它用来恢复提交后的物理数据页。
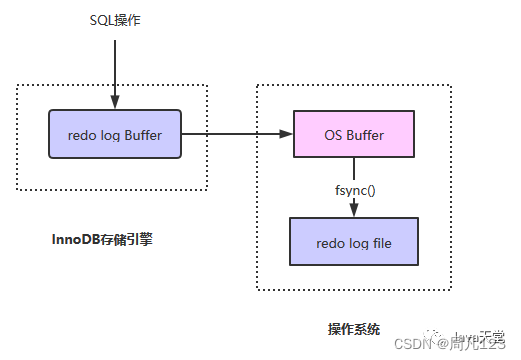
如上图所示,redo log分为两部分:
- 内存中的redo log Buffer是日志缓冲区,这部分数据是容易丢失的
- 磁盘上的redo log file是日志文件,这部分数据已经持久化到磁盘,不容易丢失
SQL操作数据库之前,会先记录重做日志,为了保证效率会先写到日志缓冲区中(redo log Buffer),再通过缓冲区写到磁盘文件中进行持久化,既然有缓冲区说明数据不是实时写到redo log file中的,那么假如redo log写到缓冲区后,此时服务器断电了,那redo log岂不是会丢失?
在MySQL中可以自已控制log buffer刷新到log file中的频率,通过innodb_flush_log_at_trx_commit参数可以设置事务提交时log buffer如何保存到log file中,innodb_flush_log_at_trx_commit参数有3个值(0、1、2),表示三种不同的方式:
- 为1表示事务每次提交都会将log buffer写入到os buffer,并调用操作系统的fsync()方法将日志写入log file,这种方式的好处是就算MySQL崩溃也不会丢数据,redo log file保存了所有已提交事务的日志,MySQL重新启动后会通过redo log file进行恢复。但这种方式每次提交事务都会写入磁盘,IO性能较差
- 为0表示事务提交时不会将log buffer写入到os buffer中,而是每秒写入os buffer然后调用fsync()方法将日志写入log file,这种方式在MySQL系统崩溃时会丢失大约1秒钟的数据
- 为2表示事务每次提交仅将log buffer写入到os buffer中,然后每秒调用fsync()方法将日志写入log file,这种方式在MySQL崩溃时也会丢失大约1秒钟的数据
undo log
undo log是回滚日志,用来回滚行记录到某个版本,undo log一般是逻辑日志,根据行的数据变化进行记录。
undo log跟redo log一样也是在SQL操作数据之前记录的,也就是SQL操作先记录日志,再进行操作数据。
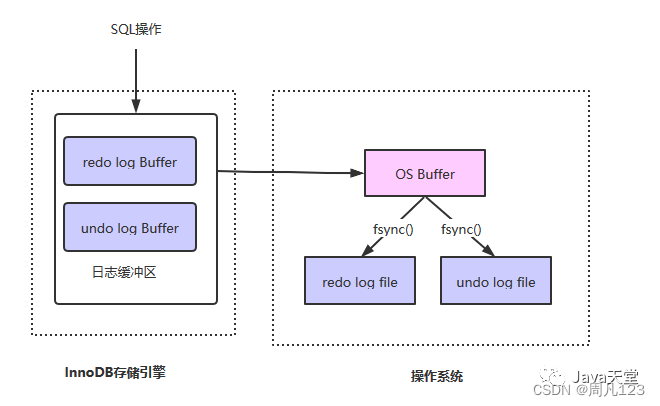
如上图所示,SQL操作之前会先记录redo log、undo log到日志缓冲区,日志缓冲区的数据会记录到os buffer中,再通过调用fsync()方法将日志记录到log file中。
undo log记录的是逻辑日志,可以简单的理解为:当insert一条记录时,undo log会记录一条对应的delete语句;当update一条语句时,undo log记录的是一条与之操作相反的语句。
当事务需要回滚时,可以从undo log中找到相应的内容进行回滚操作,回滚后数据恢复到操作之前的状态。
undo日志还有一个用途就是用来控制数据的多版本(MVCC)。
undo log是采用段(segment)的方式来记录的,每个undo操作在记录的时候占用一个undo log segment。
另外,undo log也会产生redo log,因为undo log也要实现持久性保护。
总结
MySQL中是如何实现事务提交和回滚的?
- 为了保证数据的持久性,数据库在执行SQL操作数据之前会先记录redo log和undo log
- redo log是重做日志,通常是物理日志,记录的是物理数据页的修改,它用来恢复提交后的物理数据页
- undo log是回滚日志,用来回滚行记录到某个版本,undo log一般是逻辑日志,根据行的数据变化进行记录
- redo/undo log都是写先写到日志缓冲区,再通过缓冲区写到磁盘日志文件中进行持久化保存
- undo日志还有一个用途就是用来控制数据的多版本(MVCC)
简单理解就是:
- redo log是用来恢复数据的,用于保障已提交事务的持久性
- undo log是用来回滚事务的,用于保障未提交事务的原子性
实践
创建事务
在MySQL中,可以使用BEGIN语句开始一个事务,例如:
BEGIN;
-- 这里添加事务处理语句,如INSERT、UPDATE、DELETE等
COMMIT;
事务操作
在事务中,可以使用以下操作方法来处理数据:
- 插入:使用INSERT语句插入新记录
- 更新:使用UPDATE语句修改现有记录
- 删除:使用DELETE语句删除记录
- 条件查询:使用SELECT语句查询符合条件的记录
例如,以下是一个插入、更新和删除操作的示例:
BEGIN;
INSERT INTO table_name (column1, column2) VALUES ('value1', 'value2');
UPDATE table_name SET column1 = 'new_value' WHERE id = 1;
DELETE FROM table_name WHERE id = 1;
COMMIT;
事务管理
在MySQL中,可以使用以下语句来管理事务:
- COMMIT:提交事务,将事务中的所有操作永久保存到数据库
- ROLLBACK:回滚事务,撤销所有未提交的更改,并将数据库恢复到事务开始之前的状态
- SAVEPOINT:在事务中设置保存点,以便在需要时回滚部分事务
- SET TRANSACTION:设置事务的隔离级别、并发模式等属性
事务处理流程
MySQL事务处理流程一般包括以下步骤:
- 开始事务
- 执行一系列数据库操作
- 评估事务是否成功,如果成功,则提交事务;否则,回滚事务
在MySQL中,可以使用COMMIT语句提交事务,或使用ROLLBACK语句回滚事务。例如:
BEGIN;
-- 这里添加事务处理语句
COMMIT; -- 提交事务
ROLLBACK; -- 回滚事务
实战演练
下面通过一个实际的案例来说明如何使用MySQL事务处理来处理大量数据。假设我们有一个表格,用于记录学生的成绩信息,我们需要在一个事务中插入多个学生的成绩数据,以确保数据的一致性和完整性。
CREATE TABLE student_scores (
id INT AUTO_increment PRIMARY key,
student_id INT,
course_id INT,
score FLOAT
);
现在,我们需要在同一个事务中插入多个学生的成绩数据。示例代码如下:
BEGIN; -- 开始事务
INSERT INTO student_scores (student_id, course_id, score) VALUES (1, 1, 85);
INSERT INTO student_scores (student_id, course_id, score) VALUES (2, 1, 90);
INSERT INTO student_scores (student_id, course_id, score) VALUES (3, 1, 80);
-- 这里添加更多插入语句或更新、删除语句
COMMIT; -- 提交事务
如果插入过程中发生错误,所有插入的数据都将被回滚,以确保数据的一致性和完整性。
在MySQL中,可以使用以下语句来查看当前事务的状态:
SELECT * FROM INFORMATION_SCHEMA.INNODB_trx;
该语句将返回当前正在运行的所有事务的信息,包括事务的ID、状态、持有锁等等。
最佳实践
以下是一些MySQL事务处理的最佳实践:
- 使用事务处理语句:BEGIN和COMMIT/ROLLBACK是MySQL事务处理的核心语句,必须使用它们来确保事务的一致性和完整性
- 确保事务的原子性:事务处理应该是一个原子操作,要么全部执行成功,要么全部回滚。在事务中,如果发生错误或异常,应该立即执行ROLLBACK语句,以确保数据的一致性
- 设置合适的隔离级别:在事务中,应该设置合适的隔离级别来确保数据的一致性和完整性。一般来说,较高的隔离级别可以提高数据的一致性,但也会影响性能
- 使用锁:在事务中,应该使用锁来保护数据,避免并发访问导致的数据冲突和脏读等问题
- 设计合适的数据结构:在事务中,应该确保数据结构的正确性和一致性,避免数据异常和数据丢失等问题
- 分阶段提交:在大型事务中,应该将事务分为多个阶段,并逐个提交每个阶段,以避免长时间阻塞和死锁问题