项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实战掌握技能,助力用户更好利用 CSDN 平台,自主完成项目设计升级,提升自身的硬实力。

-
专栏订阅:项目大全提升自身的硬实力
-
[专栏详细介绍:项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域)
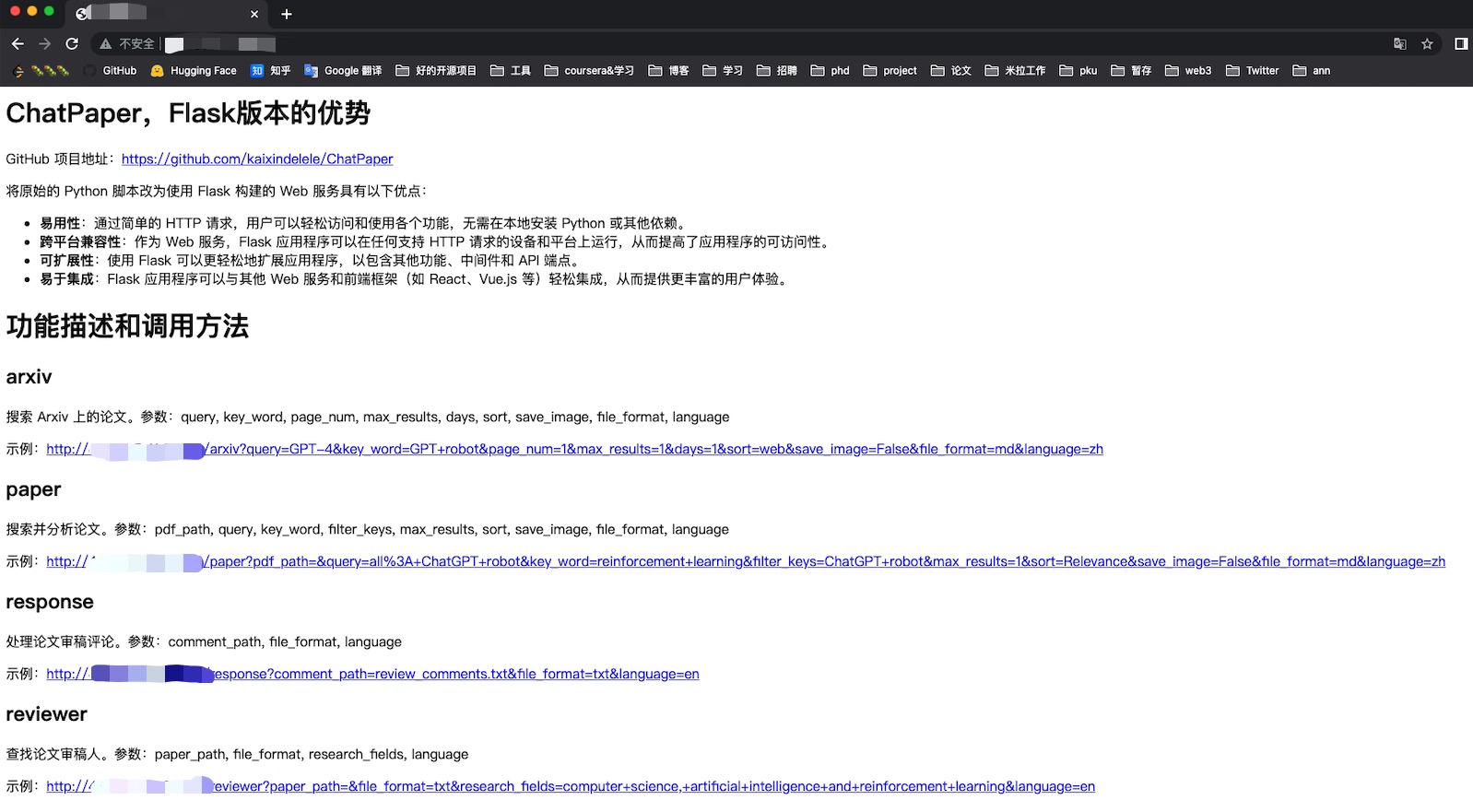
ChatPaper全流程加速科研:论文阅读+润色+优缺点分析与改进建议+审稿回复

| 工具名称 | 工具作用 | 是否在线? | 在线预览 | 备注 |
|---|---|---|---|---|
| ChatPaper | 通过ChatGPT实现对论文进行总结,帮助科研人进行论文初筛 | 访问wangrongsheng/ChatPaper 使用 | – | 原项目地址 |
| ChatReviewer | 利用ChatGPT对论文进行优缺点分析,提出改进建议 | 访问ShiwenNi/ChatReviewer 使用 | – | 原项目地址 |
| ChatImprovement | 利用ChatGPT对论文初稿进行润色、翻译等 | 访问qingxu98/gpt-academic 使用 | – | 原项目地址 |
| ChatResponse | 利用ChatGPT对审稿人的提问进行回复 | 访问ShiwenNi/ChatResponse 使用 | – | 原项目地址 |
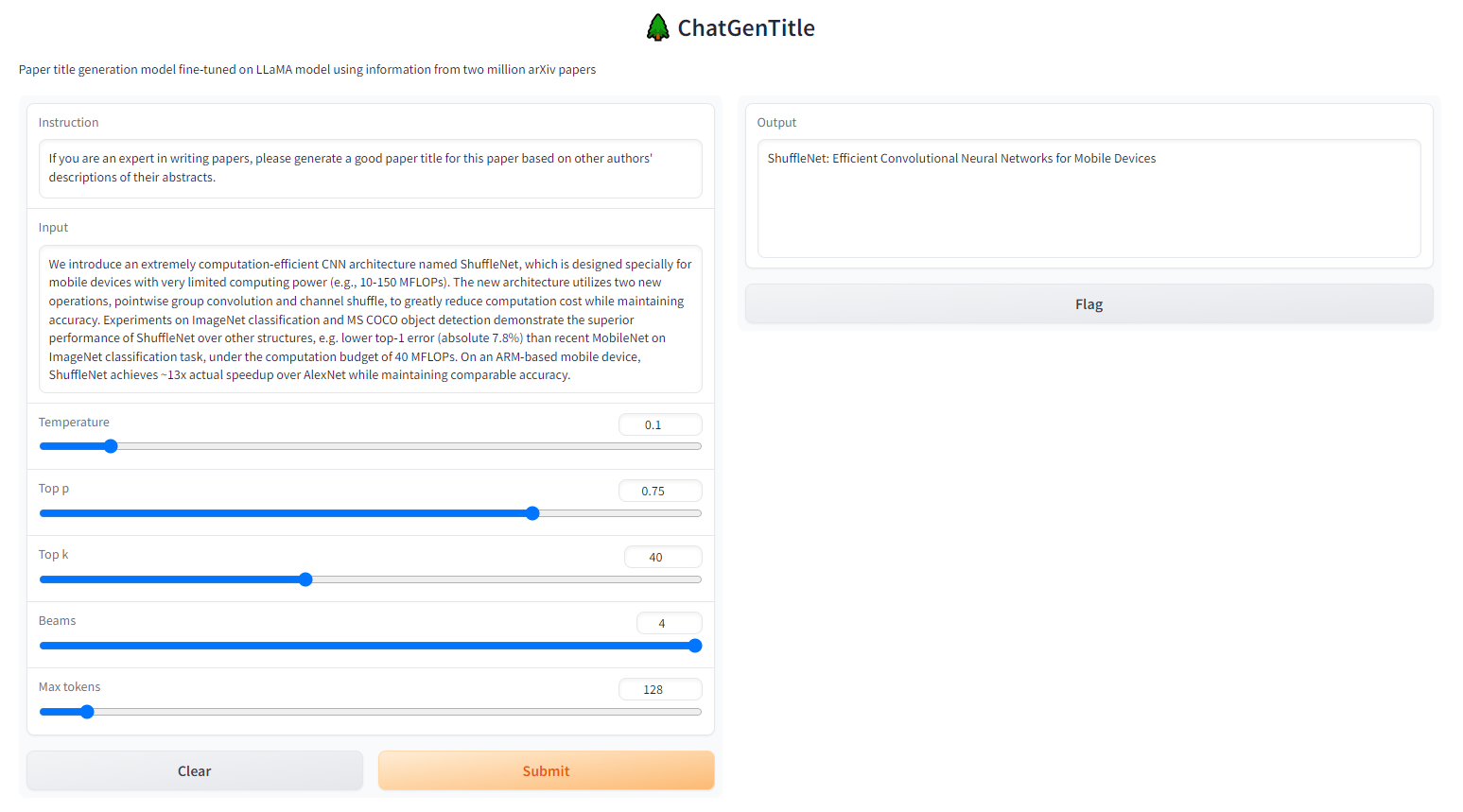
| ChatGenTitle | 利用百万arXiv论文元信息训练出来的论文题目生成模型,根据论文摘要生成合适题目 | – | – | 原项目地址 |
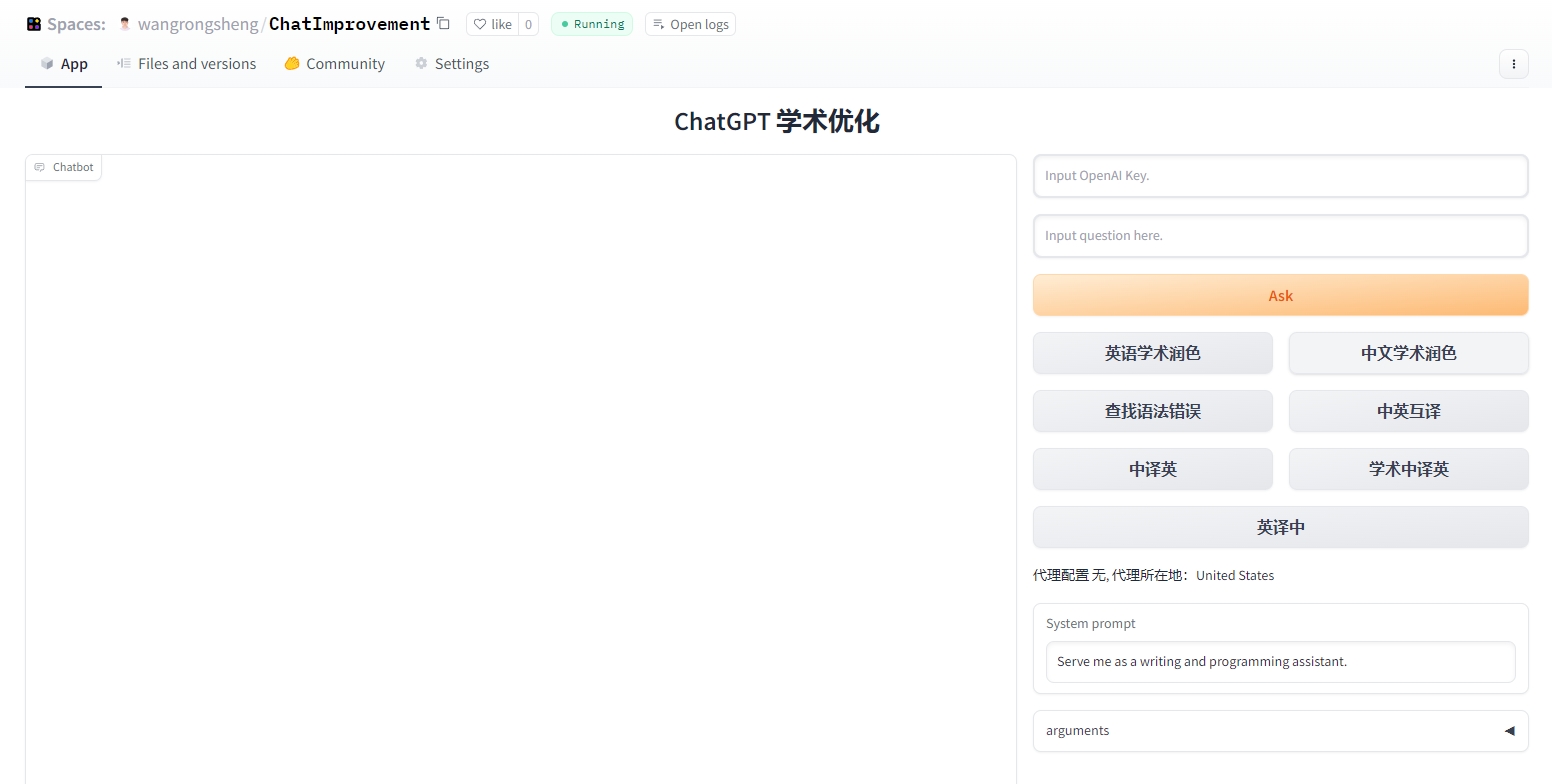
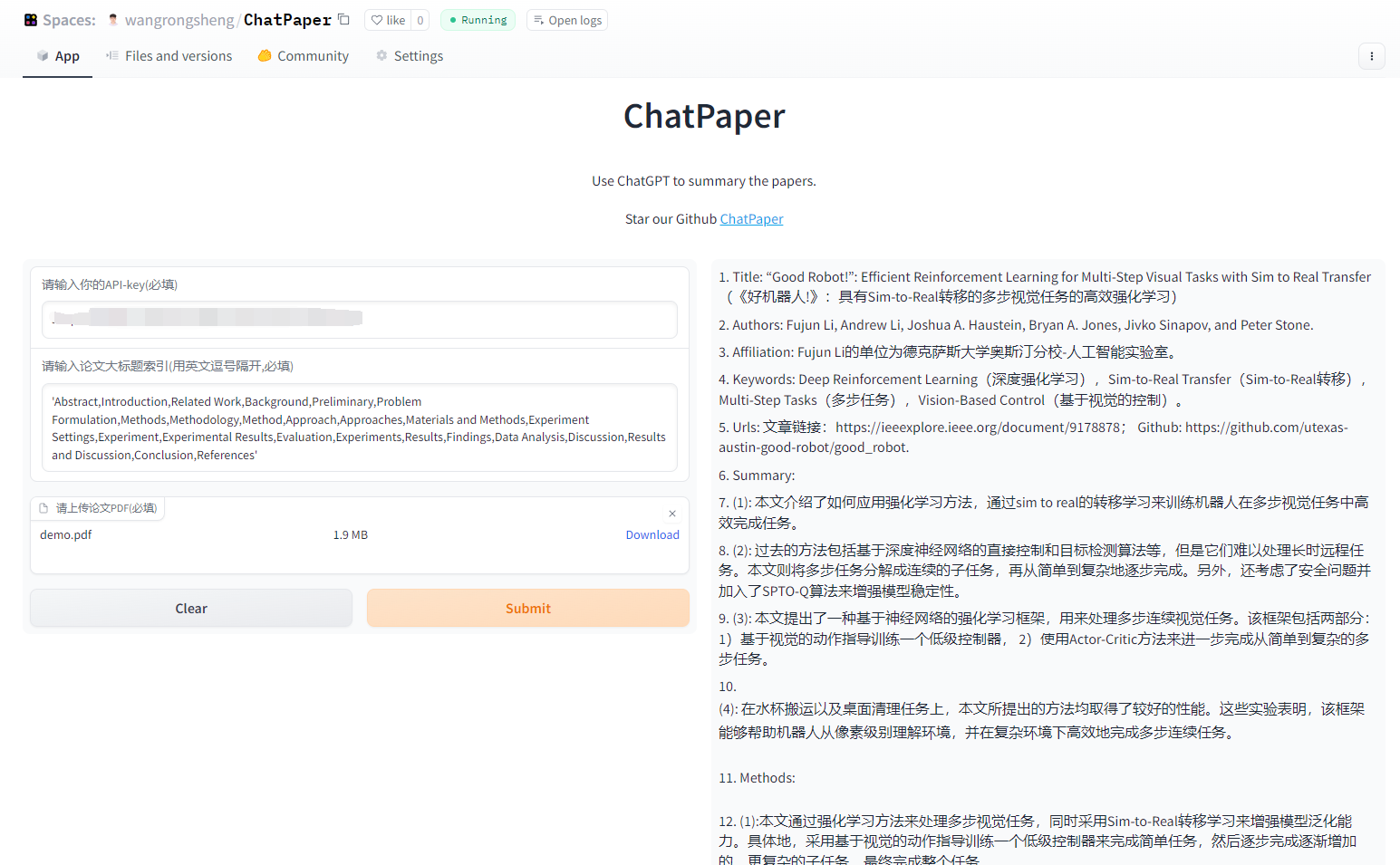
1.解决问题
面对每天海量的arxiv论文,以及AI极速的进化,我们人类必须也要一起进化才能不被淘汰。ChatPaper是一款论文总结工具。AI用一分钟总结论文,用户用一分钟阅读AI总结的论文。
它可以根据用户输入的关键词,自动在arxiv上下载最新的论文,再利用ChatGPT3.5的API接口强大的总结能力,将论文总结为固定的格式,以最少的文本,最低的阅读门槛,为大家提供最大信息量,以决定该精读哪些文章。也可以提供本地的PDF文档地址,直接处理。一般一个晚上就可以速通一个小领域的最新文章。我自己测试了两天了。这段代码虽然不多,但整个流程走通也花了我近一周的时间,今天分享给大家。
2.技术原理:
论文总结遵循下面四个问题:
-
研究背景
-
过去的方案是什么?他们有什么问题?
-
本文方案是什么?具体步骤是什么?
-
本文在哪些任务中,取得了什么效果?
基本上是大家做论文汇报的主要内容了。
实现细节:
-
提取摘要和introduction的内容,因为abstract很少会告诉你过去的方案是什么,存在什么问题。
-
然后提取method章节,总结方法的具体步骤
-
最后提取conclusion章节,总结全文。
分三次总结和喂入,如果每个部分超过了长度,则截断(目前这个方案太粗暴了,但也没有更好的更优雅的方案)
3.使用步骤
3.1以脚本方式运行
Windows, Mac和Linux系统应该都可以
python版本最好是3.9,其他版本应该也没啥问题
- 在apikey.ini中填入你的openai key。
小白用户比较多,我直接给截图示意下可能会更好:

- 使用过程要保证全局代理!
如果客户端时clash的话,可以参考这个进行配置:
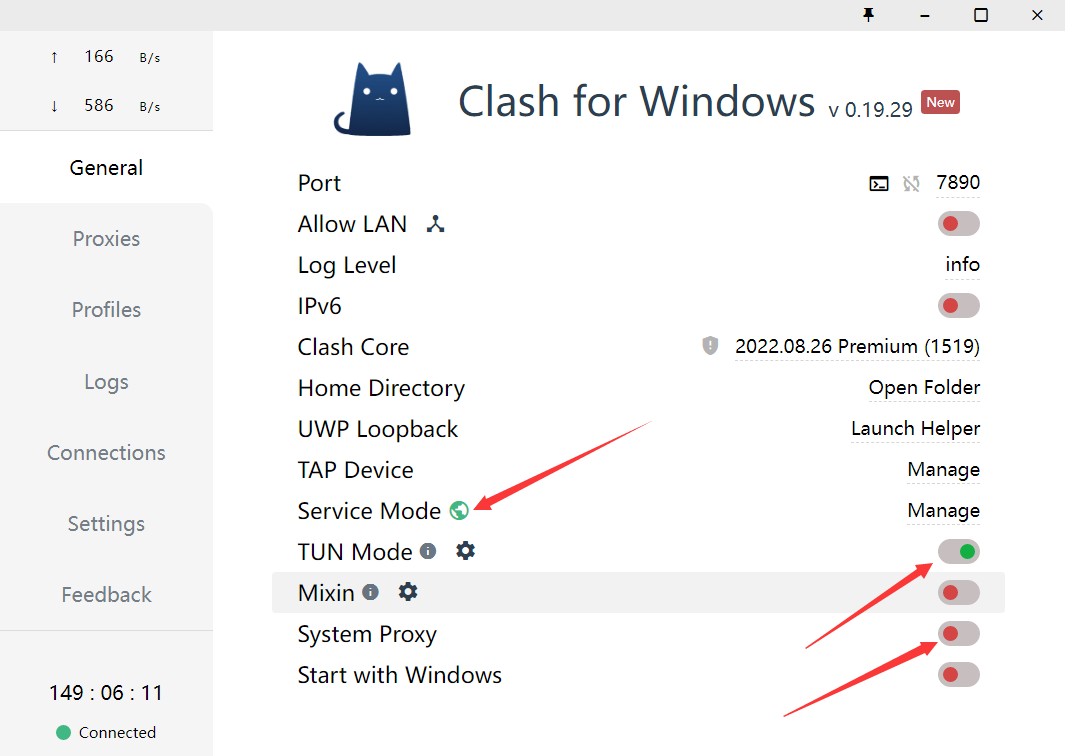
- 安装依赖:最好翻墙,或者用国内源。
pip install -r requirements.txt
4.1. Arxiv在线批量搜索+下载+总结: 运行chat_paper.py, 比如:
python chat_paper.py --query "chatgpt robot" --filter_keys "chatgpt robot" --max_results 3
更准确的脚本是chat_arxiv.py,使用方案,命令行更加简洁:
python chat_arxiv.py --query "chatgpt robot" --page_num 2 --max_results 3 --days 10
其中query仍然是关键词,page_num是搜索的页面,每页和官网一样,最大是50篇,max_results是最终总结前N篇的文章,days是选最近几天的论文,严格筛选!
注意:搜索词无法识别-,只能识别空格!所以原标题的连字符最好不要用! 感谢网友提供的信息
4.2. Arxiv在线批量搜索+下载+总结+高级搜索: 运行chat_paper.py, 比如:
python chat_paper.py --query "all: reinforcement learning robot 2023" --filter_keys "reinforcement robot" --max_results 3
4.3. Arxiv在线批量搜索+下载+总结+高级搜索+指定作者: 运行chat_paper.py, 比如:
python chat_paper.py --query "au: Sergey Levine" --filter_keys "reinforcement robot" --max_results 3
4.4. 本地pdf总结: 运行chat_paper.py, 比如:
python chat_paper.py --pdf_path "demo.pdf"
4.5. 本地文件夹批量总结: 运行chat_paper.py, 比如:
python chat_paper.py --pdf_path "your_absolute_path"
4.6. 谷歌学术论文整理: 运行google_scholar_spider.py, 比如:
python google_scholar_spider.py --kw "deep learning" --nresults 30 --csvpath "./data" --sortby "cit/year" --plotresults 1
此命令在Google Scholar上搜索与“deep learning”相关的文章,检索30个结果,将结果保存到“./data”文件夹中的CSV文件中,按每年引用次数排序数据,并绘制结果。
具体使用和参数请参考https://github.com/JessyTsu1/google_scholar_spider
另外注意,目前这个不支持综述类文章。
注意:key_word不重要,但是filter_keys非常重要!
一定要修改成你的关键词。
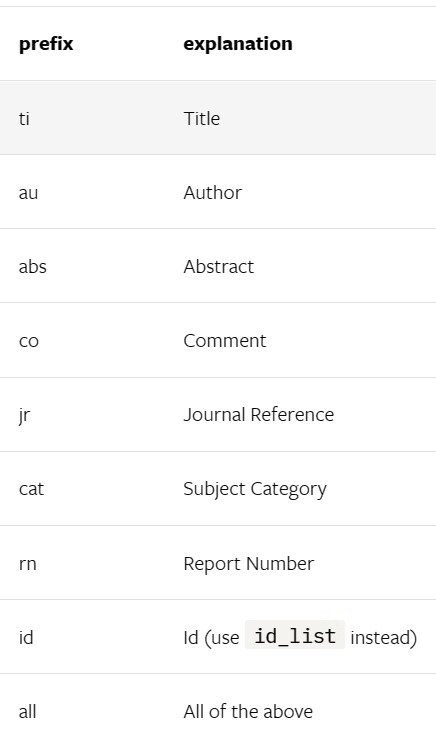
另外关于arxiv的搜索关键词可以参考下图:
- 参数介绍:
[--pdf_path 是否直接读取本地的pdf文档?如果不设置的话,直接从arxiv上搜索并且下载]
[--query 向arxiv网站搜索的关键词,有一些缩写示范:all, ti(title), au(author),一个query示例:all: ChatGPT robot]
[--key_word 你感兴趣领域的关键词,重要性不高]
[--filter_keys 你需要在摘要文本中搜索的关键词,必须保证每个词都出现,才算是你的目标论文]
[--max_results 每次搜索的最大文章数,经过上面的筛选,才是你的目标论文数,chat只总结筛选后的论文]
[--sort arxiv的排序方式,默认是相关性,也可以是时间,arxiv.SortCriterion.LastUpdatedDate 或者 arxiv.SortCriterion.Relevance, 别加引号]
[--save_image 是否存图片,如果你没注册gitee的图床的话,默认为false]
[--file_format 文件保存格式,默认是markdown的md格式,也可以是txt]
parser.add_argument("--pdf_path", type=str, default='', help="if none, the bot will download from arxiv with query")
parser.add_argument("--query", type=str, default='all: ChatGPT robot', help="the query string, ti: xx, au: xx, all: xx,")
parser.add_argument("--key_word", type=str, default='reinforcement learning', help="the key word of user research fields")
parser.add_argument("--filter_keys", type=str, default='ChatGPT robot', help="the filter key words, 摘要中每个单词都得有,才会被筛选为目标论文")
parser.add_argument("--max_results", type=int, default=1, help="the maximum number of results")
parser.add_argument("--sort", default=arxiv.SortCriterion.Relevance, help="another is arxiv.SortCriterion.LastUpdatedDate")
parser.add_argument("--save_image", default=False, help="save image? It takes a minute or two to save a picture! But pretty")
parser.add_argument("--file_format", type=str, default='md', help="导出的文件格式,如果存图片的话,最好是md,如果不是的话,txt的不会乱")
3.2 以Flask服务运行
- 下载项目并进入项目目录
git clone https://github.com/kaixindelele/ChatPaper.git
cd ChatPaper
- 在项目根目录下的
apikey.ini文件中填入您的 OpenAI 密钥。 - 配置虚拟环境并下载依赖
pip install virtualenv
安装虚拟环境工具
virtualenv venv
新建一个名为venv的虚拟环境
Linux/Mac下:
source venv/bin/activate
Windows下:
.\venv\Scripts\activate.bat
pip install -r requirements.txt
- 启动服务
python3 app.py
#启动 Flask 服务。运行此命令后,Flask 服务将在本地的 5000 端口上启动并等待用户请求。在浏览器中访问以下地址之一以访问 Flask 服务的主页:
#http://127.0.0.1:5000/
#或
#http://127.0.0.1:5000/index
访问 http://127.0.0.1:5000/ 后,您将看到主页。在主页上,您可以点击不同的链接来调用各种服务。您可以通过修改链接中的参数值来实现不同的效果。有关参数详细信息,请参阅上一步骤中的详细介绍
-
特别的,这四个接口实际是封装了根目录下四个脚本的 web 界面。参数可以通过链接来修改。例如要运行“arxiv?query=GPT-4&key_word=GPT+robot&page_num=1&max_results=1&days=1&sort=web&save_image=False&file_format=md&language=zh”的话,相当于在根目录下调用 chat_arxiv.py 并返回结果。这个显示的结果和在命令行中调用的结果是一样的(即:python chat_arxiv.py --query “GPT-4” --key_word “GPT robot” --page_num 1 --max_results 1 --days 1 --sort “web” --save_image False --file_format “md” --language “zh”)。您可以通过修改参数来获得其他搜索结果。
如果以这种方式部署的话,结果会保存在同级目录下新生成的export、pdf_files 和response_file三个文件夹里
3.3 以docker形式运行
-
安装docker和docker-compose,可以参考以下链接
https://yeasy.gitbook.io/docker_practice/install
https://yeasy.gitbook.io/docker_practice/compose/install
-
找地方放项目根目录下的“docker-compose.yaml”文件,将21行的
YOUR_KEY_HERE替换为自己的openai_key -
在同级目录下在命令行运行
docker-compose up -d -
这样的界面代表一些正常,随后访问https://127.0.0.1:28460/ 就可以从网页上打开了! !

-
特别的,如果有改进项目的想法,您可以查看 build.sh、dev.sh、tagpush.sh这三个脚本以及根目录docker目录下文件的作用,相信它们会对你容器化封装项目的思想有进一步提升
-
所有的运行结果都被保存在 Docker 的 volumes 中,如果想以服务的形式长期部署,您可以将这些目录映射出来。默认情况下,它们位于 /var/lib/docker/volumes/ 下。您可以进入该目录并查看 chatpaper_log、chatpaper_export、chatpaper_pdf_files 和 chatpaper_response_file 四个相关文件夹中的结果。有关 Docker volumes 的详细解释,请参考此链接:http://docker.baoshu.red/data_management/volume.html。
4.在线部署
- 在Hugging Face 创建自己的个人账号并登录;
- 进入ChatPaper主仓库:https://huggingface.co/spaces/wangrongsheng/ChatPaper ,您可以在Files and Version 看到所有的最新部署代码;
- [可选]私有化部署使用:点击Duplicate this space ,在弹出的页面中将
Visibility选择为Private,最后点击Duplicate Space,Space的代码就会部署到你自己的Space中,为了方便自己每次调用可以不用填写API-key,您可以将app.py#L845 修改为您的密钥:default="sk-abcdxxxxxxxx",点击保存文件就会立即重新部署了; - [可选]公有化部署使用:点击Duplicate this space ,在弹出的页面中将
Visibility选择为Public,最后点击Duplicate Space,Space的代码就会部署到你自己的Space中,这样就可以完成一个公有化的部署。
注:公有化部署和私有化部署根据你的需求二选一即可!
5. 使用技巧
快速刷特定关键词的论文,不插图的话,每张篇文章需要花一分钟,阅读时间差不多一分钟。
本项目可以用于跟踪领域最新论文,或者关注其他领域的论文,可以批量生成总结,最大可生成1000(如果你能等得及的话)。
虽然Chat可能有瞎编的成分,但是在我的规范化提问的框架下,它的主要信息是保熟的。
数字部分需要大家重新去原文检查!
找到好的文章之后,可以精读这篇文章。
推荐另外两个精读论文的AI辅助网站:https://typeset.io/ 和chatpdf。
和上面这两个工具的主要优势在于,ChatPaper可以批量自动总结最新论文,可以极大的降低阅读门槛,尤其是我们国人。
缺点也很明显,ChatPaper没有交互功能,不能连续提问,但我觉得这个重要性不大~
6.常见报错
- pip 安装错误:
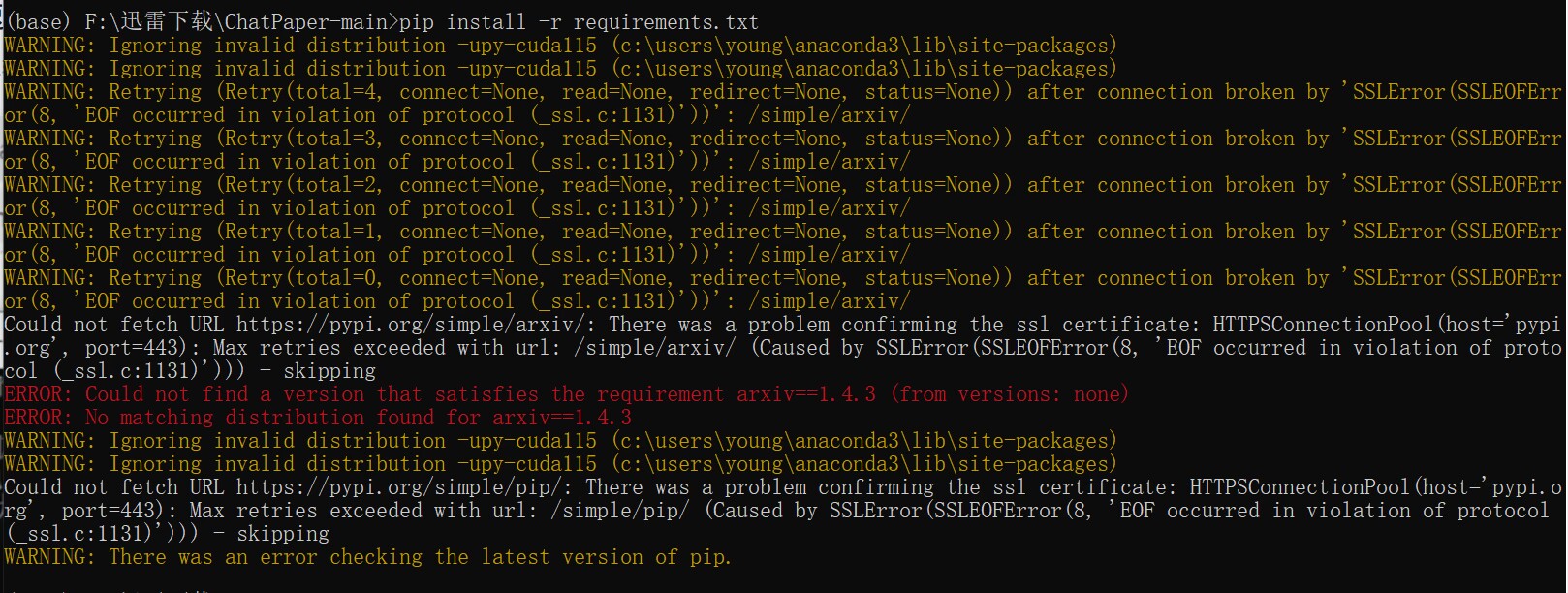
推荐关掉梯子,使用国内源下载:
pip install -r requirements.txt -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
- 调用openai的chatgpt api时出现APIConnectionError, 如何解决?
参考知乎回答:
https://www.zhihu.com/question/587322263/answer/2919916984
直接在chat_paper.py里加上
os.environ[“http_proxy”] = “http://<代理ip>:<代理端口>”
os.environ[“https_proxy”] = “http://<代理ip>:<代理端口>”
代理ip和端口需要你在Windows系统里面查找。
- API被OpenAI禁了的报错:

这种情况只能用新号了。另外一定要注意一个号尽量不要多刷,节点一定要靠谱,千万不能用大陆和香港的节点,用了就寄。
- Https通信错误:
这个报错大概率是节点不够干净。如果有大佬知道具体原因,欢迎挂issues
issue174提供的方案是:
pip install urllib3==1.25.11
7.chatgpt 分析报告
[0/13] 程序概述: get_paper.py
该文件是一个Python脚本,文件名为 get_paper.py,属于 ChatPaper 工程中的一个组成部分。它实现了一个 Paper 类和一个 main 函数。Paper 类代表了一篇论文,它可以从 PDF 文件中解析出论文的元信息和内容,并提供了一些函数用于获取论文信息,如获取文章标题,获取章节名称及内容等。主函数 main() 演示了如何使用 Paper 类处理 PDF 文件,根据 PDF 文件路径初始化 Paper 对象,并调用 parse_pdf() 函数解析 PDF 文件并获取相应的信息。
[1/13] 程序概述: chat_arxiv_maomao.py
该程序文件名为 chat_arxiv_maomao.py,猫娘版chat_arxiv.py,其功能为使用 OpenAI API 进行聊天和从 arxiv 搜索引擎中查询论文信息,并将相应的论文保存为PDF格式和部分信息保存为图片格式。程序文件使用了许多 Python 的第三方库,如 arxiv、numpy、openai、fitz 等。程序中定义了 ArxivParams 以及 Paper、Reader 三个类,其中 ArxivParams 定义了从 arxiv 搜索论文时需要的各种参数;Paper 类用于解析 PDF 文件,提取论文信息并保存为本地 PDF 文件及多个图片文件,其中包括论文标题、pdf 路径、每个章节标题对应的 pdf 页码、每个章节的正文内容、摘要信息,以及保存为图片文件的论文第一页;Reader 类主要用于在 arxiv 搜索引擎中查询论文信息,根据查询信息和关键词得到论文列表,再根据列表中的论文信息获取论文 pdf 文件并保存。
核心区别在于猫娘限定款,但目前的主要语句没有猫娘的韵味,希望大家一起帮忙调试出一个有灵魂的猫娘AI论文秘书!给你留一个pull的位置!
[2/13] 程序概述: chat_paper.py
该程序文件名为chat_paper.py,包含一个Reader类和PaperParams元组。该程序功能为根据读者输入的搜索查询和感兴趣的关键词,从Arxiv数据库中获取文章,并对文章进行摘要和总结。程序使用了OpenAI的GPT-3模型生成文本摘要,使用了arxiv包获取Arxiv数据库中的文章。程序会将摘要和总结以markdown文件的形式保存下来。
Reader类包含了下载文章、筛选文章以及使用GPT-3生成文本摘要和总结的方法。主要方法有:
- get_arxiv(): 使用Arxiv的API获取搜索结果。
- filter_arxiv(): 筛选文章,并返回筛选后的结果。
- download_pdf(): 从Arxiv下载筛选后的文章。
- summary_with_chat(): 对每一篇下载下来的文章进行文本摘要和总结,并将结果以markdown文件的形式保存。
PaperParams元组包含了程序运行所需要的参数,如下载文件保存路径、搜索查询、关键词、排序方式、筛选关键词等。程序中使用了多次retry来保证程序的稳定性。
[3/13] 程序概述: get_paper_from_pdf.py
本程序文件为Python脚本文件,文件名为get_paper_from_pdf.py,主要是通过调用fitz库和PIL库的方法,从PDF文件中解析出文章的各个部分的文本内容,包括标题、摘要、章节标题和正文等,并且对PDF文件中的图片进行提取和保存,并返回图片的路径和扩展名。
具体实现是定义了一个Paper类,通过传入PDF文件的路径初始化Paper对象,然后封装了一系列方法,如解析PDF文件的方法parse_pdf(),获取所有章节名称的方法get_chapter_names(),获取文章中的图片路径的方法get_image_path()等。最后在main()函数中调用了Paper类的parse_pdf()方法,并将解析出的各个部分的文本内容和图片路径打印输出。
[4/13] 程序概述: app.py
该程序文件为一个基于 Flask 框架实现的 Web 应用程序,提供了四个功能模块:arxiv、 paper、 response 和 reviewer,分别对应搜索 Arxiv 上的论文、搜索并分析论文、处理论文审稿评论和查找论文审稿人四个功能。其中,每个功能模块定义了相应的路由函数,并使用 process_request 函数处理请求参数,并将请求参数作为参数调用相应的功能主函数,输出结果。此外,home 函数为应用的首页,提供了应用简介、各功能模块的描述以及该应用的 GitHub 项目地址等信息。最后,在程序结尾,代码根据命令行参数来启动应用程序。
[5/13] 程序概述: chat_arxiv.py
这个程序的文件名是chat_arxiv.py。这个程序实现了一个论文下载器。在论文知识库 arXiv 上搜索论文,并下载相应的 PDF 文件。程序将会接收用户的查询字符串、关键词、搜索页数、文件格式等参数,为这些参数构建一个名为 ArxivParams 的元组。接着,程序使用提供的参数调用 arXiv API,获取查询到的论文列表。程序遍历每篇论文,并下载它们的 PDF 文件。程序接收到 PDF 后,使用 fitz 库打开它,提取出目录,正文和元数据等信息。在 PDF 中查找到第一张图片,并将它保存成 PNG 格式的文件。程序遍历文本,找到所有的章节名称和图片,并将它们保存成字典,并存储在 Paper 对象里。最后调用 Gitee API 将文件上传到 Gitee 仓库里。
[6/13] 程序概述: chat_response.py
该程序文件是一个Python脚本,文件名为"chat_response.py",主要功能是根据输入的评论文件路径,使用OpenAI的Chat API生成对应的回复文本,并将回复输出到指定格式的文件中。
具体包括以下功能:
-
定义了一个Response类,包括了一些属性和方法,用于初始化和生成回复文本。
-
定义了一个chat_response_main函数,用于启动Response类生成回复文本。
-
通过导入argparse、configparser、datetime、json、os、re、time等模块,实现了参数解析、文件读写、时间处理、字符串匹配等操作。
-
使用了numpy、openai、tenacity、tiktok等第三方库,实现了文本编码、OpenAI Chat API调用、重试机制、加密解密等功能。
-
使用了正则表达式对文本进行匹配处理,提取关键信息后进行逻辑处理和字符串拼接,形成回复文本。
-
实现输出格式为txt、markdown等格式的回复文件。
总之,该程序用于将审稿意见进行回复,实现了自动化生成回复文本的功能,从而提高了工作效率。
[7/13] 程序概述: chat_reviewer.py
该程序文件是一个基于OpenAI Chat API的文献审稿系统,可以通过输入论文的标题、摘要、和各章节内容,生成相应的评审意见。主要包括以下内容:
1.导入所需要的模块和包
2.自定义namedtuple类ReviewerParams,包括4个属性:paper_path(论文路径),file_format(生成文件格式),research_fields(研究领域),language(输出语言)
3.自定义类Reviewer,包括以下方法:
init: 初始化方法,用于设置属性
validateTitle:用于校验论文的路径
review_by_chatgpt:根据传入的论文列表,获取关键部分,发送至OpenAI Chat API,生成评审意见
stage_1:审稿的第一阶段,根据传入的论文,提供标题、摘要、可提取的章节等信息并将其发送至OpenAI Chat API,以获取用户选择的章节
chat_review:审稿的第二阶段,将用户选定的章节和关键部分发送至OpenAI Chat API,以生成审稿意见
export_to_markdown:将审稿意见保存为markdown格式的文件
4.chat_reviewer_main:用于初始化程序,读取命令行参数后初始化Reviewer类,通过传入的论文路径或文件名,调用Reviewer类的review_by_chatgpt方法生成评审意见
该程序通过OpenAI Chat API调用人工智能模型,为用户提供便利的文献评审服务,同时又充分考虑到了对用户信息的保护,具有一定的可靠性和安全性。
[8/13] 程序概述: google_scholar_spider.py
这个程序文件是一个可从 Google Scholar 网站上获取特定关键字相关论文信息的爬虫,主要用于研究学术领域的热点话题。该爬虫的主要功能包括:
- 从命令行参数中获取关键字、结果数、CSV 文件路径、排序方式等信息;
- 根据关键字和年份(可选)构建 Google Scholar 查询链接;
- 使用 requests 库向链接发送请求,并对结果进行处理,包括获取标题、作者、被引用次数等;
- 按照排序方式对结果进行排序,将结果保存为 CSV 文件,并可选择在结果中生成柱状图。
[9/13] 程序概述: deploy/Public/app.py
该程序文件是一个Python脚本,文件名为app.py。该脚本包含了多个模块的导入和多个类和函数的定义。其中,一些重要的模块包括numpy、os、re、datetime、arxiv、openai、base64、requests、argparse、configparser、fitz、io、PIL、gradio、markdown、json、tiktoken、concurrent。主要的类包括Paper和Reader,辅助函数包括parse_text、api_key_check、valid_apikey、get_chapter_names、get_title、get_paper_info、get_image_path等。该程序还涉及到一些第三方API的调用,例如Arxiv、OpenAI等。该程序实现了一些功能,例如解析PDF文件,提取文本内容并按照章节组织成字典,获取PDF中每个页面的文本信息,根据字体大小识别每个章节名称等。该程序还可以检查有效的API密钥,生成一份有效的API密钥列表。
[10/13] 程序概述: deploy/Public/optimizeOpenAI.py
该程序文件名为optimizeOpenAI.py,是一个官方ChatGPT API的简单包装器,主要实现了和ChatGPT模型的交互功能,包括对话、重置对话、获取对话摘要等,以及对于API调用时间、API key的管理和流程控制。其中提供了两个主要的方法:ask()用于获取model的回答信息,conversation_summary()用于获取对话的摘要信息。
[11/13] 程序概述: deploy/Private/app.py
该程序实现了一个名为chatPaper的应用,用户可以通过输入特定的关键词,将获取的论文进行自动摘要和筛选,并使用OpenAI进行QA问答,由机器智能生成答案。其中,程序分为若干个子功能,包括:将PDF中的第一张图另存为图片,获取PDF文件中每个页面的文本信息并将其按章节组织成字典返回,获取PDF文件的标题,获取PDF文件中的章节。程序引入了numpy、os、re、datetime、arxiv、tenacity、base64、requests、argparse、configparser、PIL、gradio、fitz、io和optimizeOpenAI等库函数。主入口为app.py。
[12/13] 程序概述: deploy/Private/optimizeOpenAI.py
这是一个名为optimizeOpenAI.py的程序文件,是一个对官方ChatGPT API的简单包装器。该文件定义了一个名为chatPaper的类,该类包含了用于与ChatGPT交互的各种方法。它使用OpenAI API完成交互,并在输入和输出之间维护存储对话的本地转换。它使用一个优先队列来存储API密钥,以确保API请求不会超过每个密钥的最大使用限制。在一个对话中,用户可以不断地提出问题并回答ChatGPT提供的管道中的问题。此外,该文件还包含用于重置对话、截断对话、计算并返回每个对话的当前令牌成本的函数,以及用于获取已注册的API密钥、检查API的可用性以及生成会话摘要的函数。
- 对程序的整体功能和构架做出概括。然后用一张markdown表格整理每个文件的功能(包括get_paper.py, chat_arxiv_maomao.py, chat_paper.py, get_paper_from_pdf.py, app.py, chat_arxiv.py, chat_response.py, chat_reviewer.py, google_scholar_spider.py, deploy/Public/app.py, deploy/Public/optimizeOpenAI.py, deploy/Private/app.py, deploy/Private/optimizeOpenAI.py)。
整体功能和构架概括:
ChatPaper是一个文献管理工具,主要针对学术论文的查询、下载、管理和评审等方面进行了自动化处理和优化,主要功能包括:
- 论文的搜索和下载
- 论文的摘要和评审自动生成
- 论文的PDF文件解析和信息提取
- 学术文献信息的爬取和整合
- 学术论文开源代码的维护和管理
文件与功能对应表:
| 文件名 | 主要功能 |
|---|---|
| get_paper.py | 解析PDF文件的主要信息:标题,作者,章节 |
| chat_arxiv_maomao.py | 在arxiv中搜索最新论文,并总结,猫娘款 |
| chat_paper.py | 搜索,下载,管理学术论文 |
| get_paper_from_pdf.py | 解析PDF文件 |
| app.py | 论文文献和爬虫 |
| chat_arxiv.py | 在arxiv中搜索最新论文,并总结 |
| chat_response.py | 使用OpenAI API自动生成文献回复 |
| chat_reviewer.py | 使用OpenAI API自动生成评审建议 |
| google_scholar_spider.py | 从谷歌学术爬取论文摘要信息和引用数 |
| Public/app.py | 提取PDF信息 |
| Public/optimizeOpenAI.py | 自然语言处理概述 |
| Private/app.py | 学术论文查询和管理 |
| Private/optimizeOpenAI.py | OpenAI API请求处理 |
项目码源见文章顶部or文末
https://download.csdn.net/download/sinat_39620217/88009540