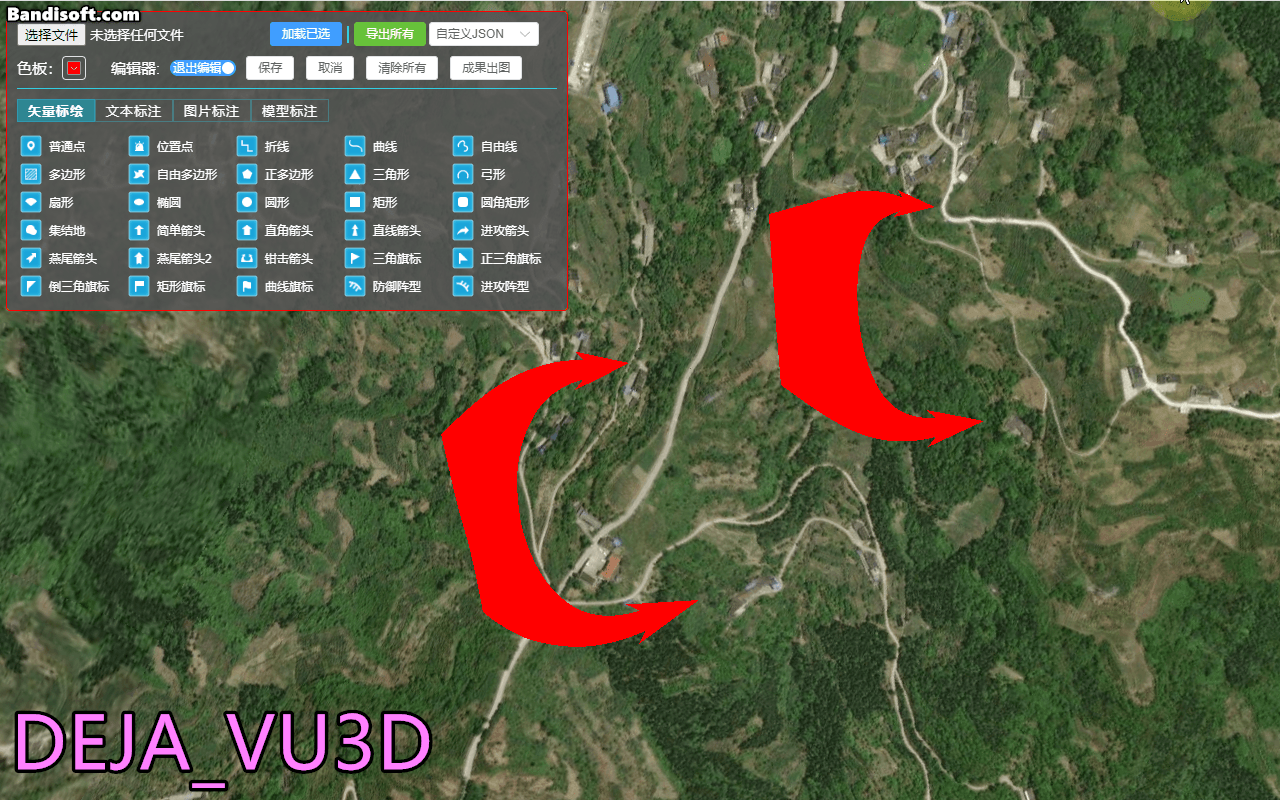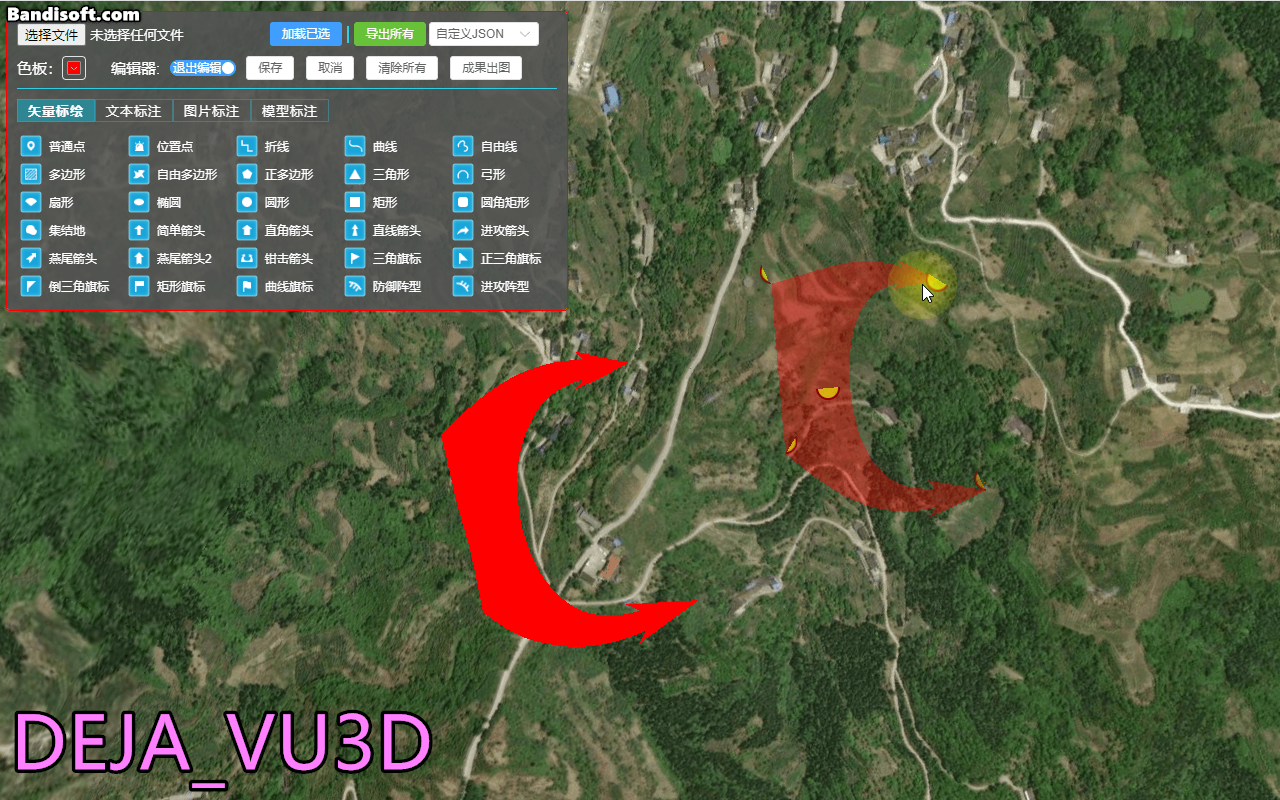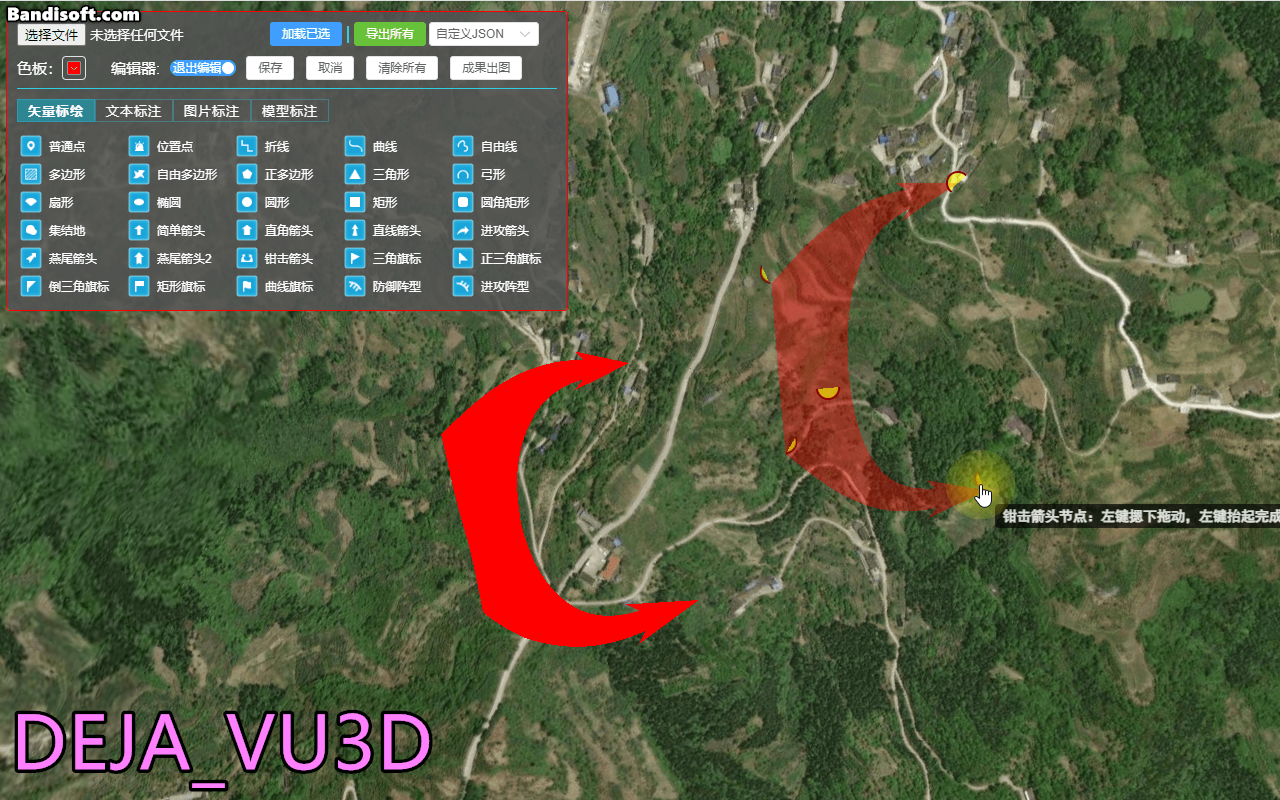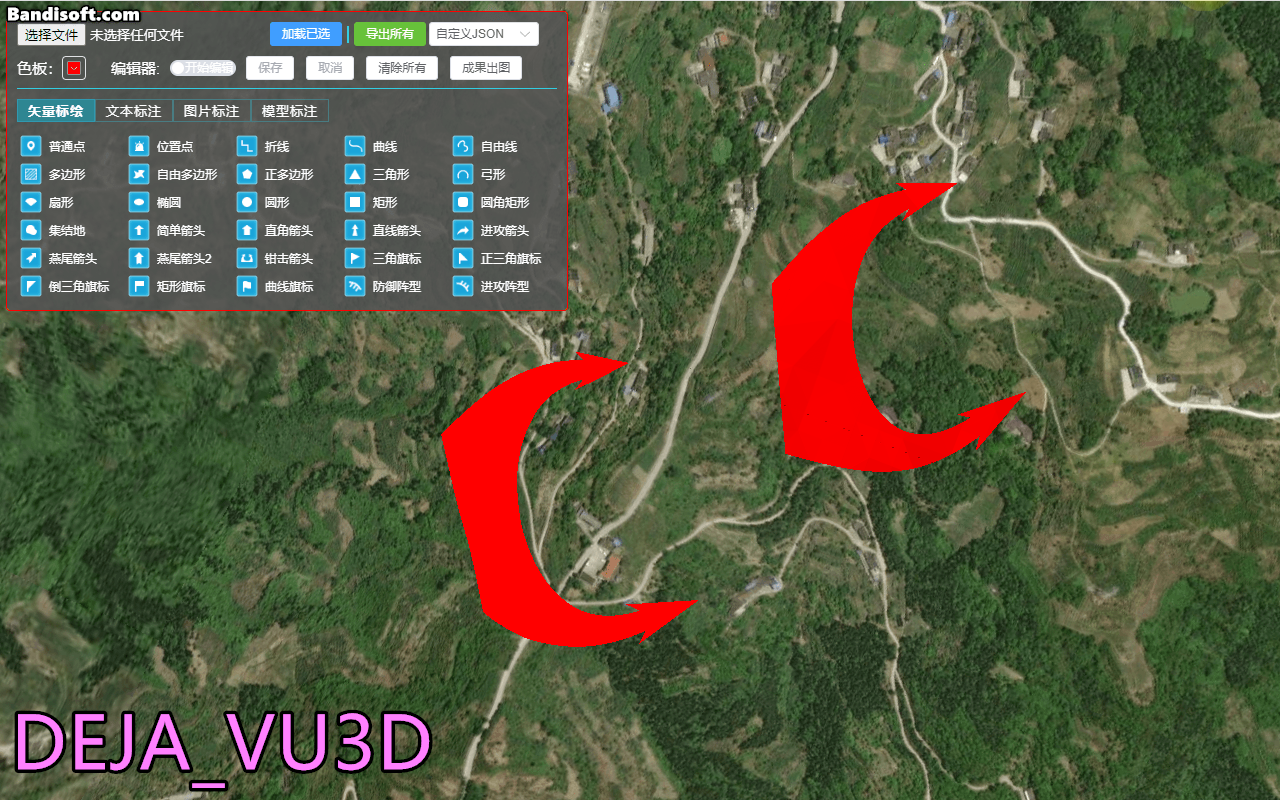
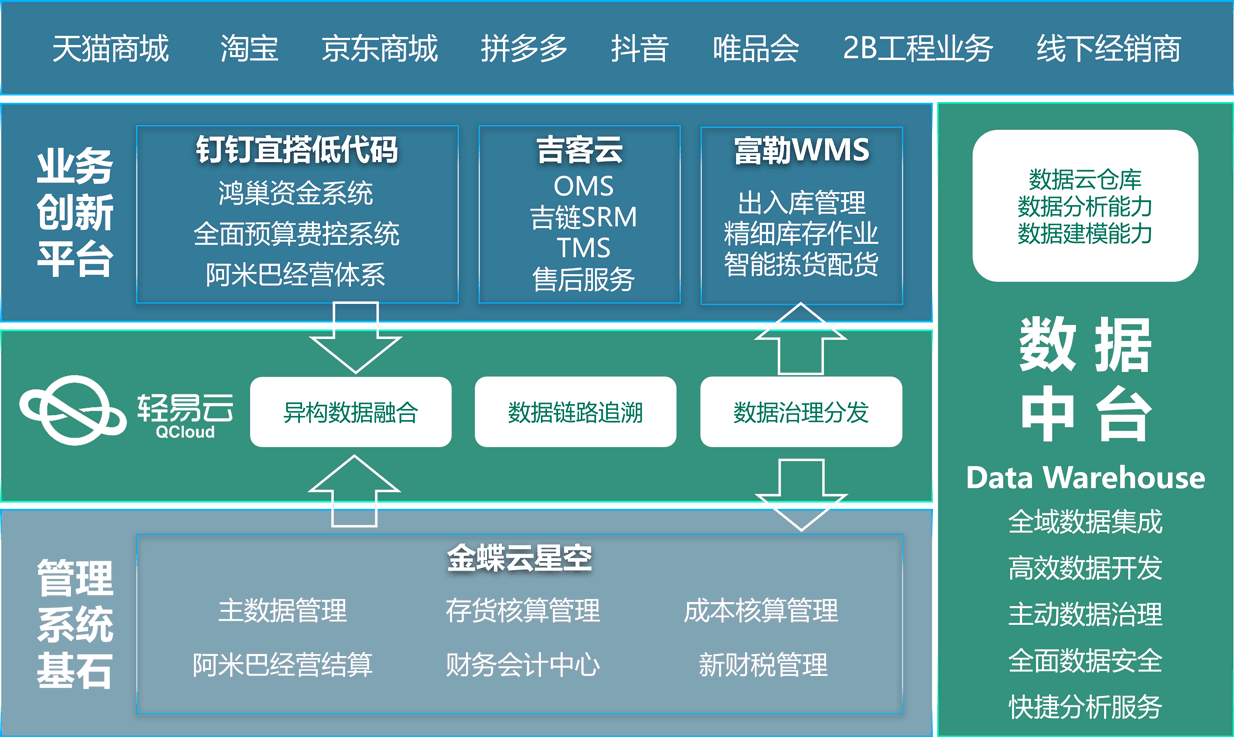
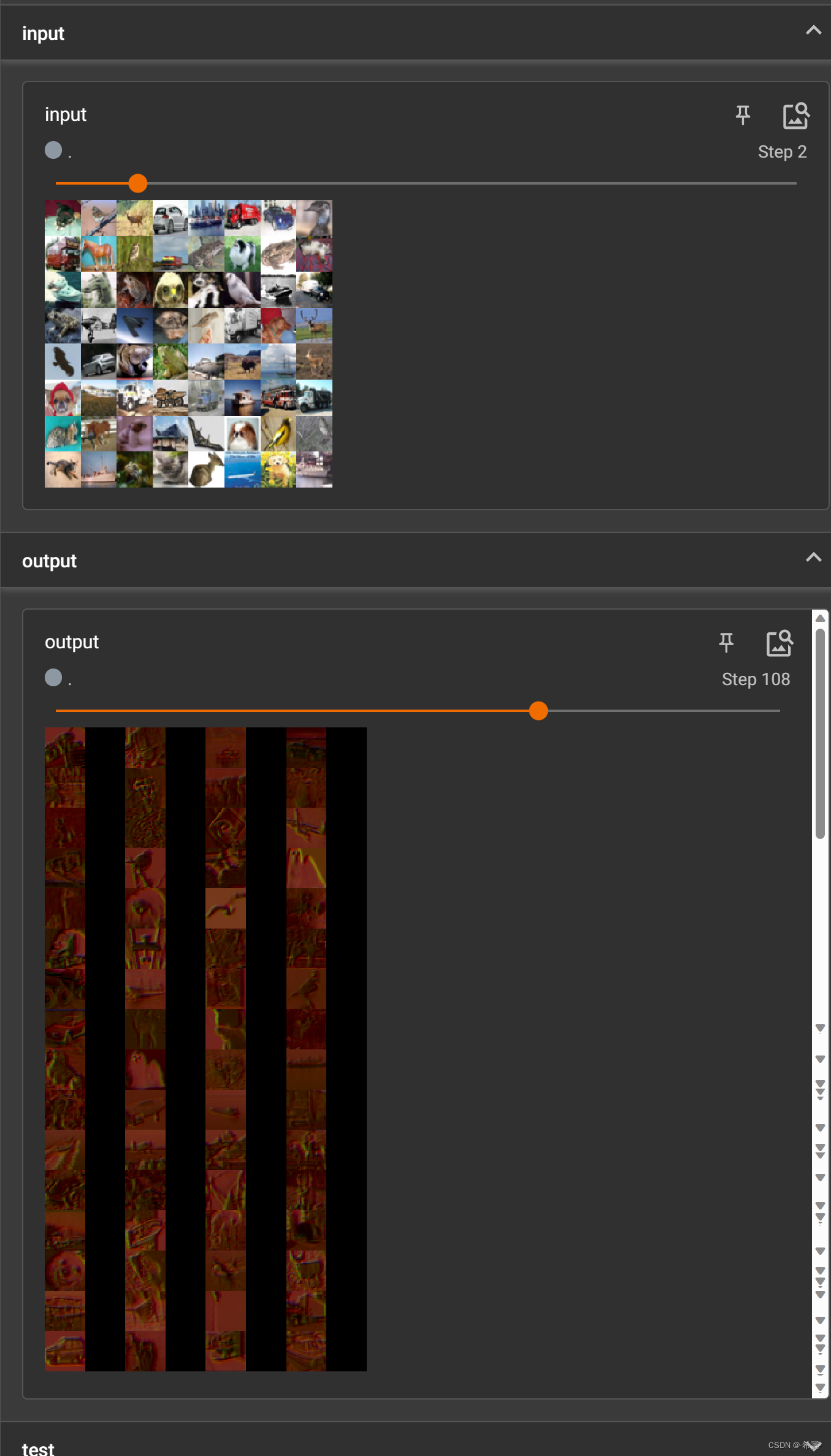
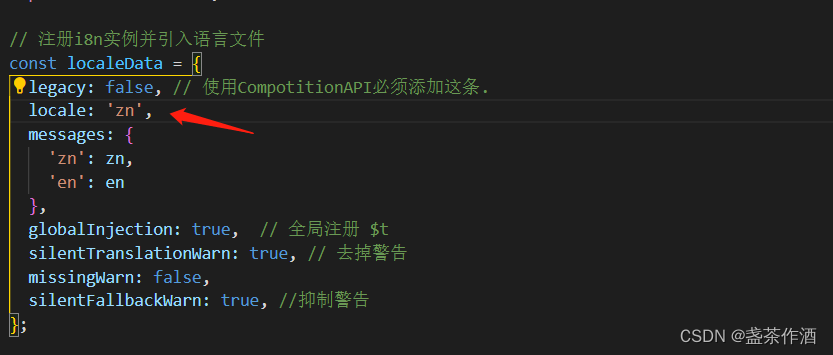
使用zlib对数据进行压缩
现实世界中,大量存在着对数据压缩的需求。为此,python内置了zlib压缩库,可以方便的对任意对象进行压缩。
下述代码演示了对字符串进行压缩:
import zlib
# 压缩一段中文
originstr = '神龟虽寿,犹有竟时;腾蛇乘雾,终为土灰。老骥伏枥,志在千里;烈士暮年,壮心不已。盈缩之期,不但在天;养怡之福,可得永年。幸甚至哉,歌以咏志。'
print(len(originstr))
str_compression = zlib.compress(originstr.encode('utf-8'), level=8)
print(len(str_compression))
print(str_compression)
decompress_str = zlib.decompress(str_compression)
print(decompress_str)
print(decompress_str.decode('utf-8'))
# 压缩一段英文
originstr = 'The World Health Organization officially declared on Saturday that the current multi-country monkeypox outbreak outside of the traditional endemic areas in Africa has already turned into a public health emergency of international concern (PHEIC).'
print(len(originstr))
str_compression = zlib.compress(originstr.encode('utf-8'), level=8)
print(len(str_compression))
print(str_compression)
decompress_str = zlib.decompress(str_compression)
print(decompress_str)
print(decompress_str.decode('utf-8'))运行上述代码后,会发现压缩并不一定会减少字节数,压缩的效率取决于压缩内容中的冗余程度。对于第一句的中文压缩后反而增加了字节数。但第二段英文则有明显的压缩比(246/180)。此外,在压缩时不指定level则使用缺省的压缩级别(大约是6),是一个在速度与压缩比间的平衡值。
level的设定如下:
-
level=0,效果是不压缩。
-
level=1,速度最快
-
level=9,速度最慢,压缩比最高
-
level=-1,缺省值
压缩一个文件的操作类似,示例代码如下:
import zlib
def compress(inputfile,outputfile):
with open(inputfile,'rb') as input:
with open(outputfile,'wb') as output:
data = input.read()
compressdata = zlib.compress(data)
output.write(compressdata)
def decompress(inputfile,outputfile):
with open(inputfile,'rb') as input:
with open(outputfile,'wb') as output:
data = input.read()
compressdata = zlib.decompress(data)
output.write(compressdata)
compress(r'd:\dev\sensor.dat',r'd:\dev\sensor.zlib')
decompress(r'd:\dev\sensor.zlib',r'd:\dev\sensor_d.dat')使用vscode的hex editor可以打开三个文件如下图所示:
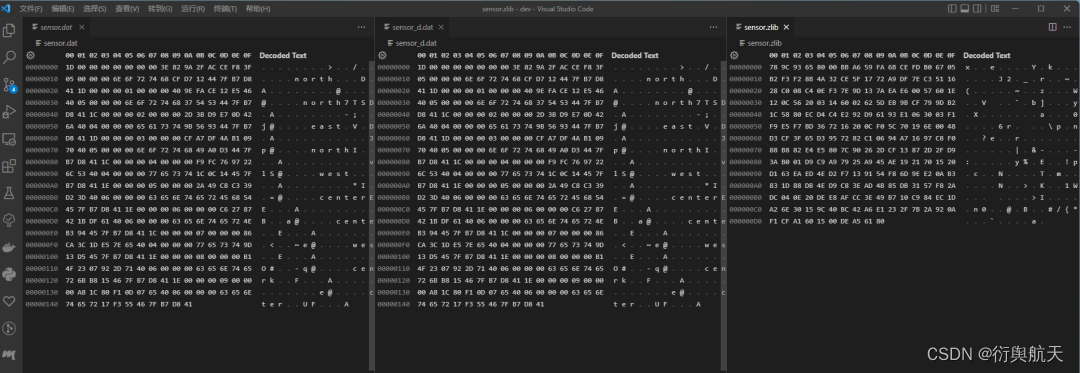
首先源文件与压缩解压后的文件完全一样。其次,压缩后的文件确实小多了。最后可以看出,从某种意义上来说,压缩也相当于加密。