论文来源:ACL 2021 Finding
论文链接:https://aclanthology.org/2021.findings-acl.161.pdf
论文代码:GitHub - Nealcly/templateNER: Source code for template-based NER
笔记仅供参考,撰写不易,请勿恶意转载抄袭!
Abstract
与资源丰富的源域相比,低资源的目标域具有不同的标签集(也就是说低资源的训练集与测试集的标签不交叉,测试集中的标签属于新的标签集合)。现有的方法使用基于相似性的度量,但是它们不能充分利用NER模型参数中的知识转移。为了解决这一问题,本文提出一种基于模板的NER方法,将NER视为sequence-to-sequence框架下的语言模型排序问题,将由候选命名实体span填充的原始句子和模板分别视为源sequence和目标sequence。进行推理时,模型需要根据相应的模板分数对每个候选span进行分类。本文分别在富资源任务和低资源任务进行了实验。
Introduction
命名实体识别是自然语言处理中的一个基本任务,是根据预先定义的实体类别识别文本输入中提及的span,如“location”、“person”和“ganization”等,主流方法如BiLSTM等如图Figure 2(a)所示。
基于距离的方法在很大程度上降低了域适应成本,尤其适用于目标域数量较多的场景,然而在标准域设置下的性能相对较弱。此外,它们在域适应能力受到两个方面的限制:① 目标域中标记的实例用于启发式最近邻搜索的最佳参数,而不是用于更新NER模型的网络参数,不能改善跨域实例的神经表示;② 这些方法依赖于源域和目标域之间相似的文本模式,当目标域的本文风格不同于源域时,可能会影响模型的性能。
为了解决上述问题,本文研究了一种基于模板的方法,利用生成式预训练语言模型的小样本学习潜力进行序列标注。具体来说,如Figure 2所示,BART使用由相应的标记实体填充的预定义模板进行微调。例如,定义这样的模板:“<condidate_span> is a <entity_type> entity”,其中<entity_type>可以是“person”或“location”等,给定句子“ACL will be held in Bangkok”,其中“Bangkok”的标签是“location”,我们可以使用一个填充模板“Bangkok is a location entity”作为输入句子的编码器输出来训练BART。对于非实体span,使用模板“<condidate_span> is not a named entity”,这样可以对负输出序列进行采样。在推理过程中,将输入句子中所有可能的文本span枚举为候选命名实体,并根据模板上的BART分数将其分类为实体或非实体。
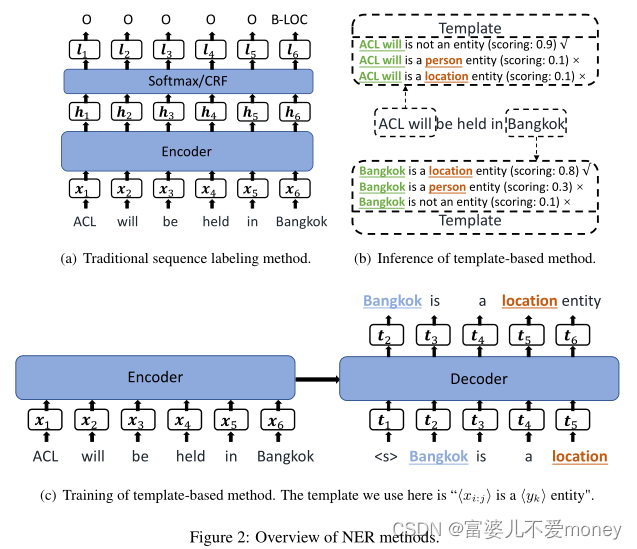
本文所提方法的三个优点:
- 由于预训练模型具有良好的泛化能力,可以有效的利用新领域中的标记实例进行调优;
- 即使目标域和源域在文本风格上存在较大的差距,本文所提方法也更具有鲁棒性;
- 与传统方法相比,本文所提方法可以应用于命名实体的任意新类别,无需改变输出层参数,允许持续学习。
Template-Based Method
本文将NER视为sequence-to-sequence框架下的语言模型排序问题。模型的源序列是一个输入文本,目标序列
是由候选文本span
和实体类型
填充的模板。
Template Creation
本文手工创建模板,其中一个槽用于candidate_span,另一个槽用于entity_type标签,并设置了一个一对一的映射函数来传递标签集L到一个单词集合Y,其中 ,如
,
,如
,并使用单词集合中的单词来定义模板
(例如<candidate_span> is a location entity),此外,还为非命名实体构造了一个非实体模板(例如,<candidate_span> is not a named entity)。这样可以得到一个模板列表
。如Figure 2(c),模板
为
is a
,
为
is not a named entity,其中
是一个候选文本跨度。
Inference
本文首先枚举一个句子中所有可能的span,并用准备好的模板进行填充。为了提高效率,本文将一个span的n-grams数量限制在1~8个,因此为每个句子创建8个模板。然后使用微调的生成式预训练语言模型为每个模板
分配一个分数,表示为:

本文通过使用任意的生成式预训练语言模型为每个模板打分来计算每个实体类型的分数和非实体类型分数
,然后将得分最高的实体类型分配给文本span
。本文使用的生成式预训练语言模型BART。
如果两个span存在文本重叠,并且在推理中分配了不同的标签,本文会选择得分较高的span作为最终的决策,以避免可能出现的预测冲突。例如“ACL will be held in Bangkok”,通过使用局部得分函数可以将“in Bangkok”和“Bangkok”分别标记为“ORG”和“LOC”,此时会比较二者分数的大小,并选择得分较大的标签进行全局决策。
Training
标记实体用于在训练期间创建模板,假设的实体类型为
,则将文本span
和实体类型
填充到
,以创建目标句子
,并以相同方式来获取目标句子
。本文使用标记实体构建
对,并随机采样非实体文本span来构建负样本
。负样本对是正样本对的1.5倍。
给定一个序列对,将X输入到BART的编码器,然后获得句子的隐藏表示:

单词的条件概率定义为:

其中,,
,V为BART的词汇表大小。以编码器输出与原始模板之间的交叉熵作为损失函数。

Transfer Learning
给定一个具有少量实例的新域,标签集
可以与用于训练NER模型的标签集不同。因此,本文用新域的标签集来填充模板用于训练和测试,而模型和算法的其余部分保持不变。即给定少量的
,使用上述方法为低资源创建序列对,并微调在富资源域上的NER模型。
此过程成本低,但能有效地传递标签知识。由于本文的方法输出的是一个自然句,而不是特定的标签,富资源和低资源的标签词都是预训练语言模型词汇的子集,这使得我们的方法可以利用“person”和“character”、“location”和“city”等标签相关性来增强跨域迁移学习的效果。
Experiments
不同的模板对实验结果的影响:

标准NER设置下的模型性能:

域内小样本设置:
本文在CoNLL03上构建了一个小样本学习场景,其中,某些特定类别的训练实例数量受到下采样的限制。特别地,将“MISC”和“ORG”设置为资源丰富的实体,将“LOC”和“PER”设置为资源贫乏的实体。我们对CoNLL03训练集进行下采样,产生3,806个训练实例,其中包括3,925个ORG”,1,423个“MISRC”,50个“LOC”和50个“PER”。由于文本样式在富资源和低资源实体类别中是一致的,因此我们将域中的场景称为少样本NER。结果如下:

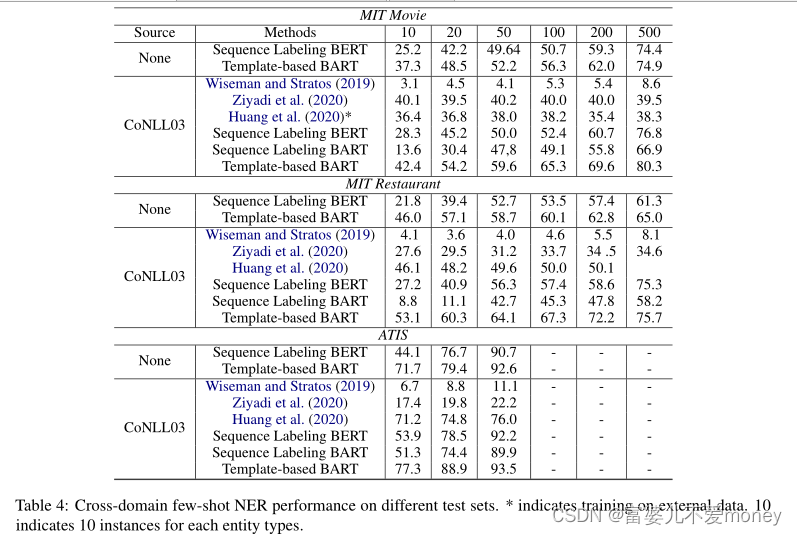
跨域小样本NER结果:
![[附源码]Python计算机毕业设计大学生扶贫创业平台Django(程序+LW)](https://img-blog.csdnimg.cn/3824cbbf49bc4c878ded7203d86025ba.png)
![[附源码]Python计算机毕业设计SSM基于的企业人事管理系统(程序+LW)](https://img-blog.csdnimg.cn/ae096b8702784b6f8ec7092508d5078c.png)


![[附源码]Node.js计算机毕业设计大学生心理健康管理系统Express](https://img-blog.csdnimg.cn/c2e3f6b2435840678cedbe2adc03ccb6.png)