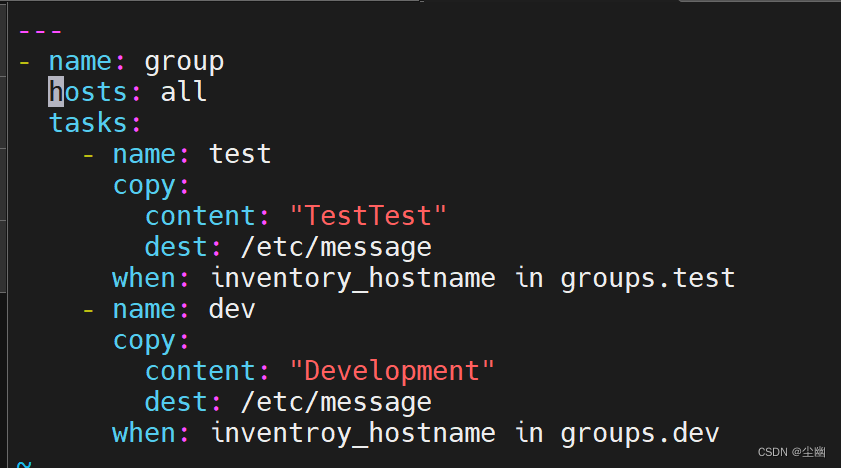
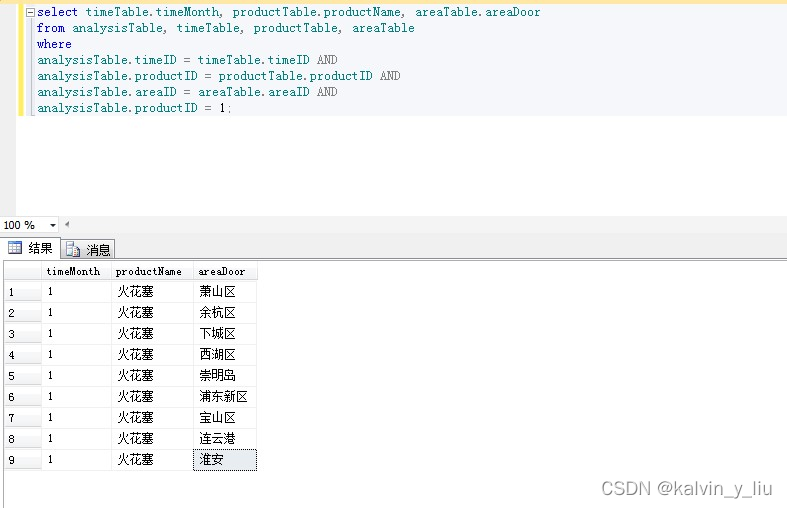
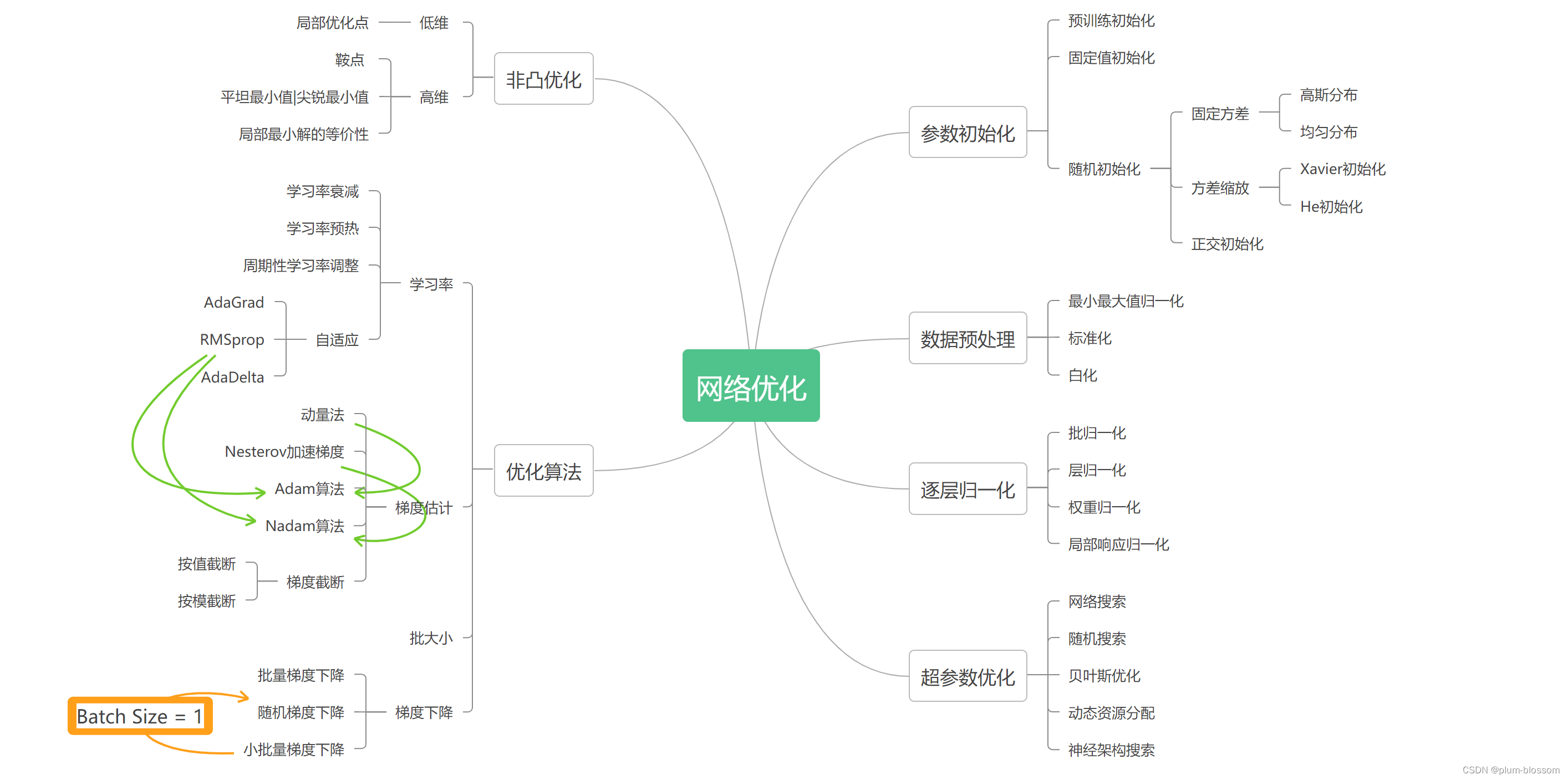
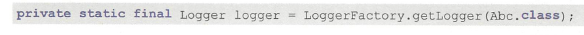一、EasyOCR + HanLp
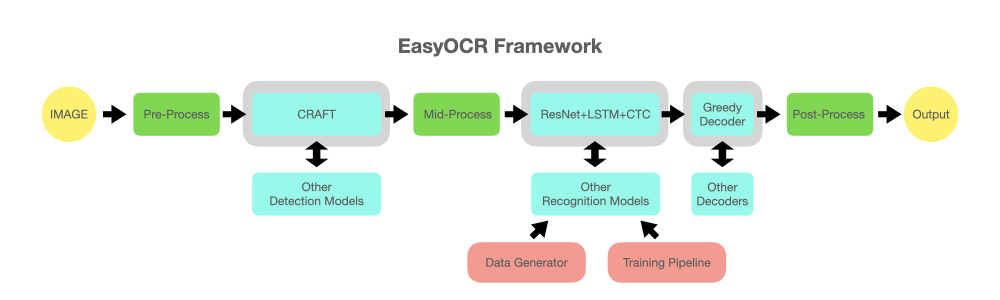
EasyOCR 是一个python版的文字识别工具。目前支持80中语言的识别。并且支持:图像预处理(去噪、色彩饱和度、尖锐处理)、CRAFT文字检测、中间处理(倾斜处理等)、文字识别、后续处理、输出结果。框架如下:
HanLP 是一系列模型与算法组成的NLP工具包,目标是普及自然语言处理在生产环境中的应用。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。内部算法经过工业界和学术界考验,配套书籍《自然语言处理入门》已经出版。目前,基于深度学习的HanLP 2.x已正式发布,次世代最先进的NLP技术,支持包括简繁中英日俄法德在内的104种语言上的联合任务。
下面采用 EasyOCR 提取出文本中的文字,利用 HanLP 分析出文本中的 中文姓名、机构名、地域名 等信息。
二、环境准备
python环境:3.6
安装 EasyOCR :
pip install easyocr
安装好依赖,执行检测如果模型不存在会自动下载模型,不过下载时间很长容易失败,可以去官方网站中下载文本检测模型和文本分析模型:
https://www.jaided.ai/easyocr/modelhub/
下载文本识别模型:
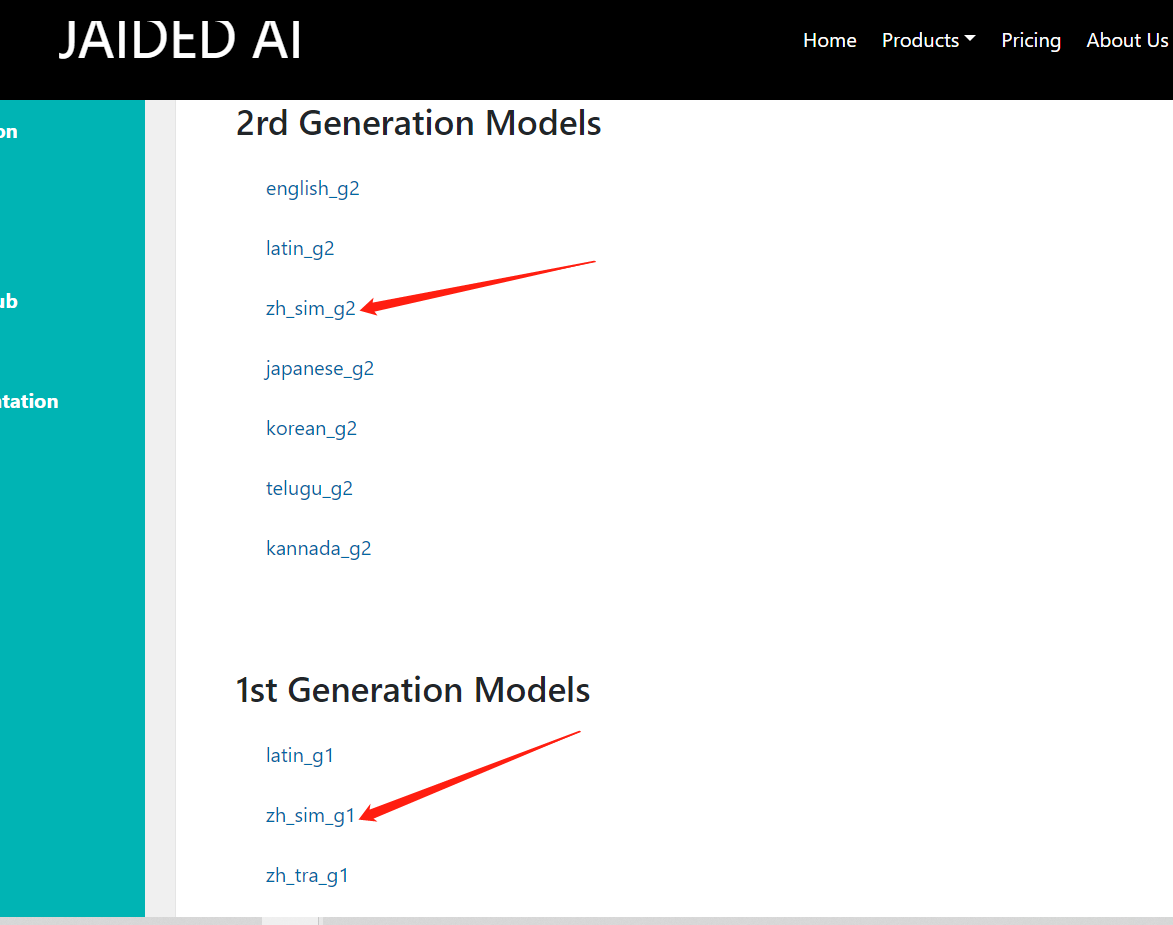
下载文本检测模型:

下载后解压放到项目的 model 目录下:
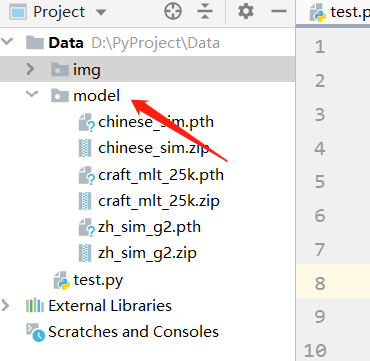
安装 HanLp
pip install pyhanlp
HanLp 的模型如果不存在也会自动下载,这个下载速度较快。
三、图片文字实体识别
下面是我准备的图片,其中姓名、机构名、地域名,还有一些干扰文字

编写识别程序:
import easyocr
from pyhanlp import HanLP
from PIL import Image, ImageDraw
def recognize():
# 加载 easyocr 模型,并制定语种
reader = easyocr.Reader(['ch_sim', 'en'], model_storage_directory='model')
# 图片位置
imgPath = 'img/1.jpeg'
# 识别图片中的文字
result = reader.readtext(imgPath, detail=1)
# 使用 PIL 读取图片,画出识别框
image = Image.open(imgPath)
# 对图片绘图
draw = ImageDraw.Draw(image)
# 存放识别出所有文字,进行NLP解析
text = ''
for item in result:
text += item[1]+' '
# 画矩形框
draw.rectangle((tuple(item[0][0]), tuple(item[0][2])), fill=None, outline=(255, 0, 0), width=2)
print("提取到文字块:",item)
print("==================================================")
print("识别文字文本: ",text)
# 创建分词器
segment = HanLP.newSegment().enableNameRecognize(True).enableOrganizationRecognize(True).enablePlaceRecognize(True)
# 提取实体
cut_word = segment.seg(text)
print(cut_word)
# 存放人名
name = []
organization = []
place = []
for item in cut_word:
word = item.word
nature = item.nature.toString()
if nature == 'nr':
name.append(word)
elif nature == 'ns':
place.append(word)
elif nature == 'nt':
organization.append(word)
print("识别中文姓名:",name)
print("识别机构名:",organization)
print("识别地域名:",place)
image.show()
if __name__ == '__main__':
recognize()
运行程序,如果没有 HanLP ,则自动下载:

识别文字情况:

可以看到文字都被捕捉到了,下面看词语分析效果:
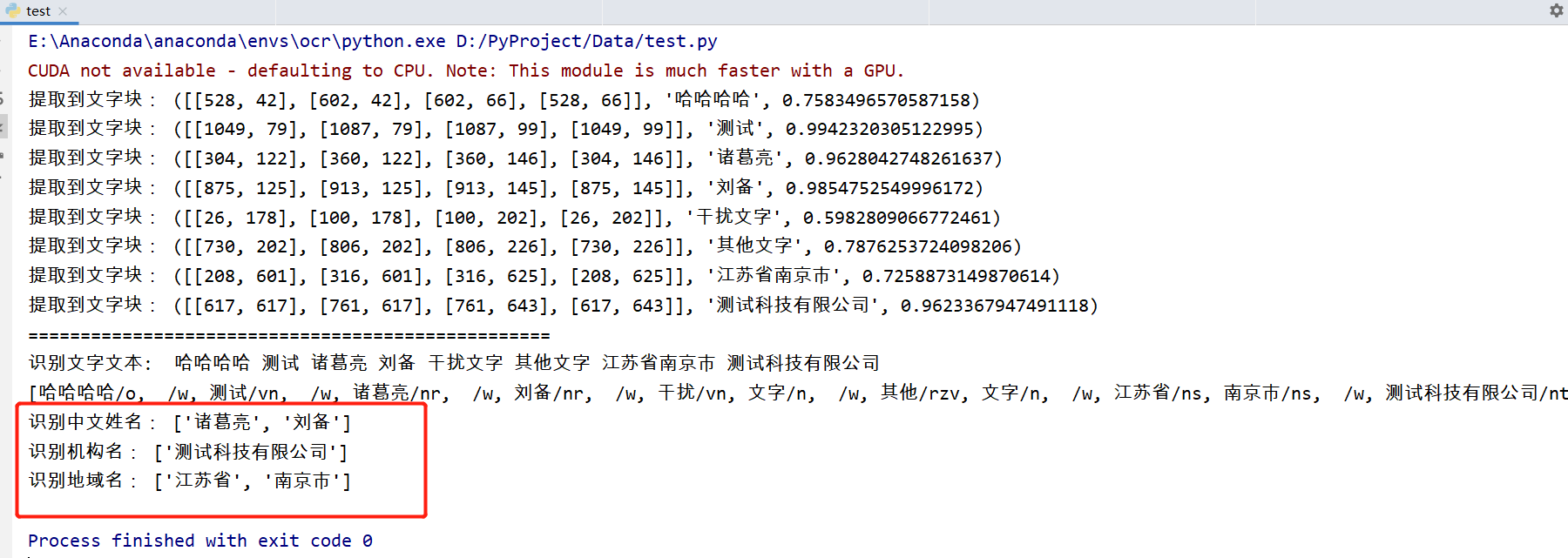
已成功提取相关实体信息。