Neural Nets
神经网络
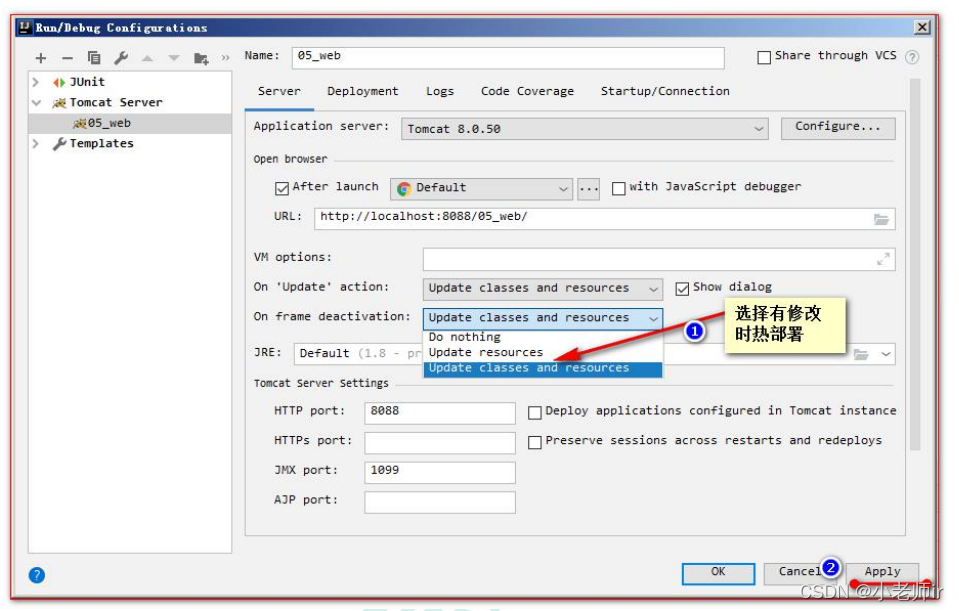
OK, so how do our typical models for tasks like image recognition actually work? The most popular—and successful—current approach uses neural nets. Invented—in a form remarkably close to their use today—in the 1940s, neural nets can be thought of as simple idealizations of how brains seem to work.
好的,那么我们对于图像识别等典型任务的模型实际上是如何工作的呢?目前最流行且最成功的方法是使用神经网络。神经网络在 20 世纪 40 年代发明,其形式与现在的使用非常接近,可以被看作是对大脑工作原理的简单理想化。
In human brains there are about 100 billion neurons (nerve cells), each capable of producing an electrical pulse up to perhaps a thousand times a second. The neurons are connected in a complicated net, with each neuron having tree-like branches allowing it to pass electrical signals to perhaps thousands of other neurons. And in a rough approximation, whether any given neuron produces an electrical pulse at a given moment depends on what pulses it’s received from other neurons—with different connections contributing with different “weights”.
人类大脑中有约 1000 亿个神经元(神经细胞),每个神经元每秒可以产生电脉冲多达数千次。神经元通过复杂的网络连接在一起,每个神经元都有类似树枝的分支,使其能够将电信号传递给数千个其他神经元。在粗略的近似下,任何给定神经元在给定时刻是否产生电脉冲取决于其从其他神经元接收到的脉冲,不同的连接以不同的“权重”进行贡献。
When we “see an image” what’s happening is that when photons of light from the image fall on (“photoreceptor”) cells at the back of our eyes they produce electrical signals in nerve cells. These nerve cells are connected to other nerve cells, and eventually the signals go through a whole sequence of layers of neurons. And it’s in this process that we “recognize” the image, eventually “forming the thought” that we’re “seeing a 2” (and maybe in the end doing something like saying the word “two” out loud).
当我们“看到一张图像”时,光子从图像上落在我们眼睛背后的“光感受器”细胞上,它们会在神经元中产生电信号。这些神经元与其他神经元相连,信号经过一系列层的神经元。在这个过程中,我们“识别”图像,最终“形成思维”,认为我们“看到了一个 2”(最后可能会做出说出“2”这样的动作)。
The “black-box” function from the previous section is a “mathematicized” version of such a neural net. It happens to have 11 layers (though only 4 “core layers”):
前面部分的“黑盒子”函数是这样一个“数学化”的神经网络版本。它有 11 层(但只有 4 个“核心层”):

There’s nothing particularly “theoretically derived” about this neural net; it’s just something that—back in 1998—was constructed as a piece of engineering, and found to work. (Of course, that’s not much different from how we might describe our brains as having been produced through the process of biological evolution.)
这个神经网络并没有什么特别“理论上的推导”;它只是在 1998 年构建为一项工程,并被发现有效。(当然,这与我们可能描述人类大脑是如何通过生物进化过程产生的方式并没有太大区别。)
OK, but how does a neural net like this “recognize things”? The key is the notion of attractors. Imagine we’ve got handwritten images of 1’s and 2’s:
那么,像这样的神经网络是如何“识别事物”的呢?关键在于吸引子的概念。假设我们有手写的 1 和 2 的图像:

We somehow want all the 1’s to “be attracted to one place”, and all the 2’s to “be attracted to another place”. Or, put a different way, if an image is somehow “closer to being a 1” than to being a 2, we want it to end up in the “1 place” and vice versa.
我们希望所有的 1 都能“被吸引到一个地方”,而所有的 2 都能“被吸引到另一个地方”。换句话说,如果一个图像在某种程度上“更接近 1”而不是 2,我们希望它最终位于“1 的地方”,反之亦然。
As a straightforward analogy, let’s say we have certain positions in the plane, indicated by dots (in a real-life setting they might be positions of coffee shops). Then we might imagine that starting from any point on the plane we’d always want to end up at the closest dot (i.e. we’d always go to the closest coffee shop). We can represent this by dividing the plane into regions (“attractor basins”) separated by idealized “watersheds”:
作为一个直观的类比,我们假设平面上有一些位置,由点(在现实生活中它们可能是咖啡店的位置)表示。然后我们可以想象,从平面上的任意一点出发,我们总是希望最终到达最近的点(也就是我们总是去最近的咖啡店)。我们可以通过将平面划分为由理想化的“分水岭”分隔的区域(“吸引子盆地”)来表示这一点:

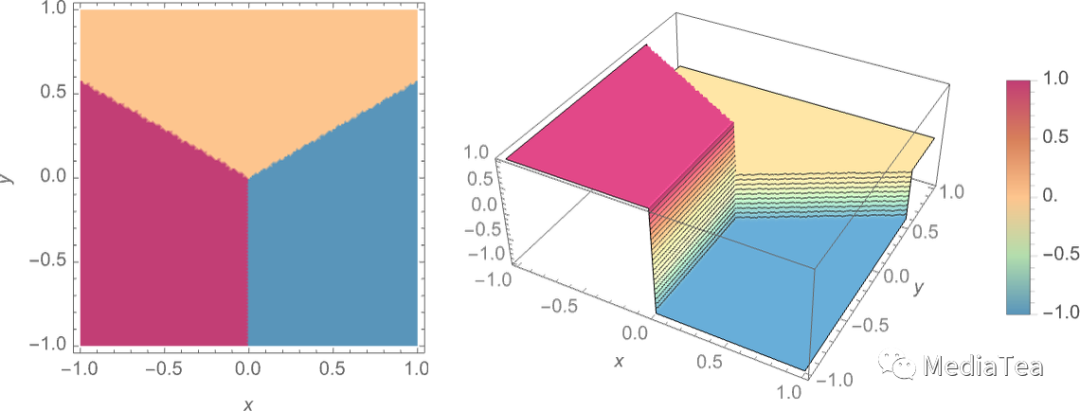
We can think of this as implementing a kind of “recognition task” in which we’re not doing something like identifying what digit a given image “looks most like”—but rather we’re just, quite directly, seeing what dot a given point is closest to. (The “Voronoi diagram” setup we’re showing here separates points in 2D Euclidean space; the digit recognition task can be thought of as doing something very similar—but in a 784-dimensional space formed from the gray levels of all the pixels in each image.)
我们可以将此视为实现“识别任务”的一种方式,我们并不是在做类似于确定给定图像“看起来最像哪个数字”的事情,而是直接看给定点最接近的是哪个点。(我们在这里展示的“沃罗诺伊图”设置将 2D 欧氏空间中的点分隔开;数字识别任务可以认为是在 784 维空间中进行,该空间由每个图像中所有像素的灰度级组成。)
So how do we make a neural net “do a recognition task”? Let’s consider this very simple case:
那么,我们如何使神经网络“执行识别任务”呢?让我们考虑这个非常简单的例子:
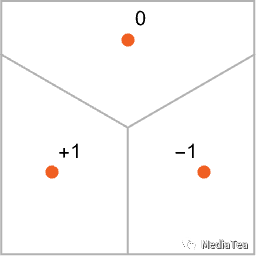
Our goal is to take an “input” corresponding to a position {x,y}—and then to “recognize” it as whichever of the three points it’s closest to. Or, in other words, we want the neural net to compute a function of {x,y} like:
我们的目标是将“输入”转换为对应于位置{x,y}的点,并将其“识别”为最接近的三个点之一。换句话说,我们希望神经网络计算关于{x,y}的函数,如下所示:
So how do we do this with a neural net? Ultimately a neural net is a connected collection of idealized “neurons”—usually arranged in layers—with a simple example being:
那么我们如何用神经网络实现这个呢?从根本上讲,神经网络是由一系列理想化的“神经元”相互连接而成的,通常按层排列,一个简单的例子是:
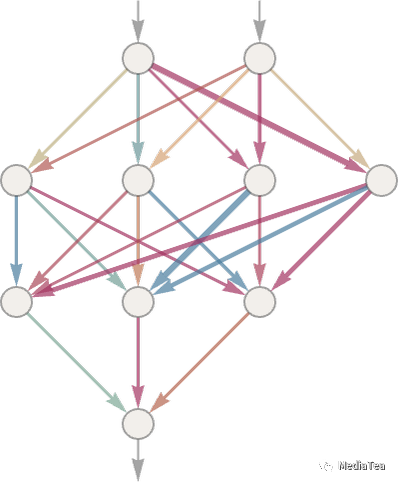
Each “neuron” is effectively set up to evaluate a simple numerical function. And to “use” the network, we simply feed numbers (like our coordinates x and y) in at the top, then have neurons on each layer “evaluate their functions” and feed the results forward through the network—eventually producing the final result at the bottom:
每个“神经元”实际上被设置为评估一个简单的数值函数。为了“使用”网络,我们只需在顶部输入数字(例如我们的坐标 x 和 y),然后在每个层上的神经元“评估它们的函数”并将结果通过网络向前传递——最终在底部产生最终结果:
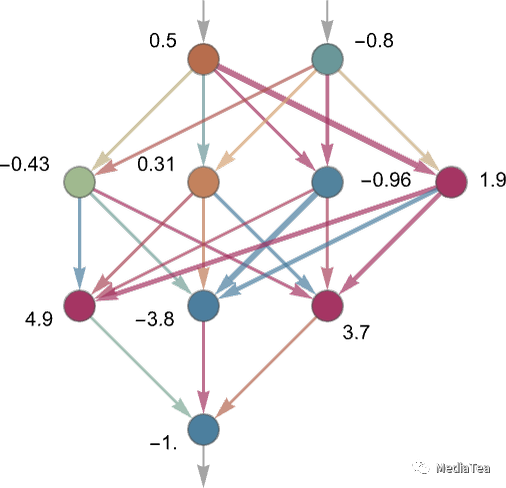
In the traditional (biologically inspired) setup each neuron effectively has a certain set of “incoming connections” from the neurons on the previous layer, with each connection being assigned a certain “weight” (which can be a positive or negative number). The value of a given neuron is determined by multiplying the values of “previous neurons” by their corresponding weights, then adding these up and adding a constant—and finally applying a “thresholding” (or “activation”) function. In mathematical terms, if a neuron has inputs x = {x1, x2 …} then we compute f[w . x + b], where the weights w and constant b are generally chosen differently for each neuron in the network; the function f is usually the same.
在传统的(生物启发式的)设置中,每个神经元实际上都有来自上一层神经元的一组“输入连接”,每个连接都被赋予某个“权重”(可以是正数或负数)。给定神经元的值是通过将“上一层神经元”的值与它们对应的权重相乘,然后相加并加上一个常数——最后应用一个“阈值”(或“激活”)函数来确定的。在数学上,如果一个神经元具有输入 x = {x1,x2...},那么我们计算 f[w·x + b],其中权重 w 和常数 b 通常对于网络中的每个神经元选择不同;函数 f 通常是相同的。
Computing w . x + b is just a matter of matrix multiplication and addition. The “activation function” f introduces nonlinearity (and ultimately is what leads to nontrivial behavior). Various activation functions commonly get used; here we’ll just use Ramp (or ReLU):
计算 w·x + b 只是矩阵乘法和加法的问题。激活函数 f 引入了非线性(最终导致不平凡的行为)。通常会使用不同的激活函数;在这里,我们使用了 Ramp(或 ReLU):

For each task we want the neural net to perform (or, equivalently, for each overall function we want it to evaluate) we’ll have different choices of weights. (And—as we’ll discuss later—these weights are normally determined by “training” the neural net using machine learning from examples of the outputs we want.)
对于我们希望神经网络执行的每个任务(或等效地,我们希望它评估的每个整体函数),我们都有不同的权重选择。(我们稍后将讨论这些权重通常是通过使用机器学习来从我们希望的输出的示例中“训练”神经网络得到的。)
Ultimately, every neural net just corresponds to some overall mathematical function—though it may be messy to write out. For the example above, it would be:
归根结底,每个神经网络只对应于某个整体数学函数——尽管可能很难写出。对于上面的例子,它将是:
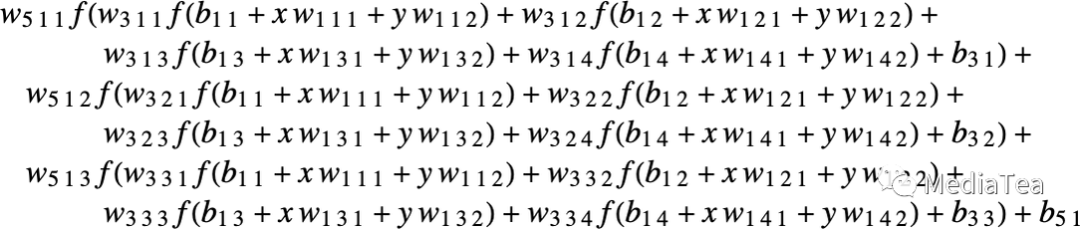
The neural net of ChatGPT also just corresponds to a mathematical function like this—but effectively with billions of terms.
ChatGPT 的神经网络也只是对应于这样一个数学函数——但是有效地有数十亿个项。
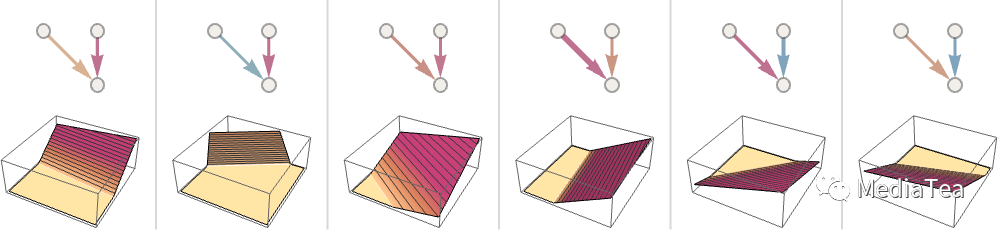
But let’s go back to individual neurons. Here are some examples of the functions a neuron with two inputs (representing coordinates x and y) can compute with various choices of weights and constants (and Ramp as activation function):
不过让我们回到单个神经元。以下是一个具有两个输入(表示坐标 x 和 y)的神经元根据不同的权重和常数(以及 Ramp 作为激活函数)所计算的一些函数示例:
But what about the larger network from above? Well, here’s what it computes:
那么上面的较大网络呢?好吧,它计算的是这个:
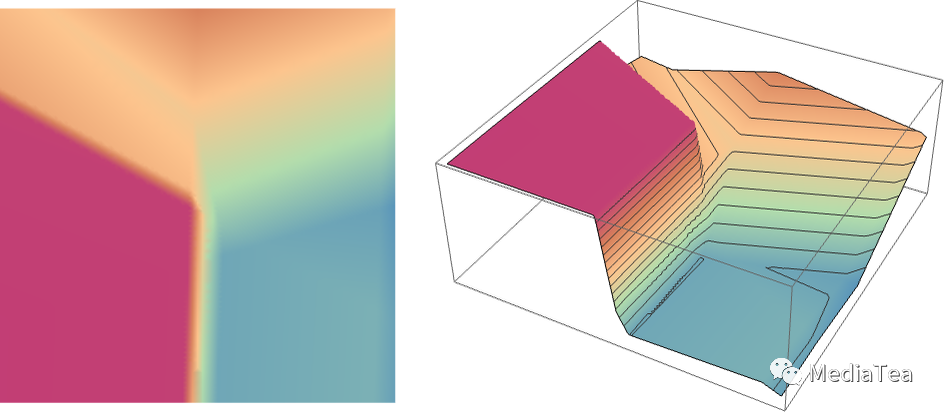
It’s not quite “right”, but it’s close to the “nearest point” function we showed above.
这并不完全“正确”,但它接近我们之前展示的“最近点”函数。
Let’s see what happens with some other neural nets. In each case, as we’ll explain later, we’re using machine learning to find the best choice of weights. Then we’re showing here what the neural net with those weights computes:
让我们看看其他神经网络发生了什么。在每种情况下,正如我们稍后将解释的,我们都在使用机器学习来找到最佳的权重选择。然后我们在这里展示这些权重的神经网络计算的结果:
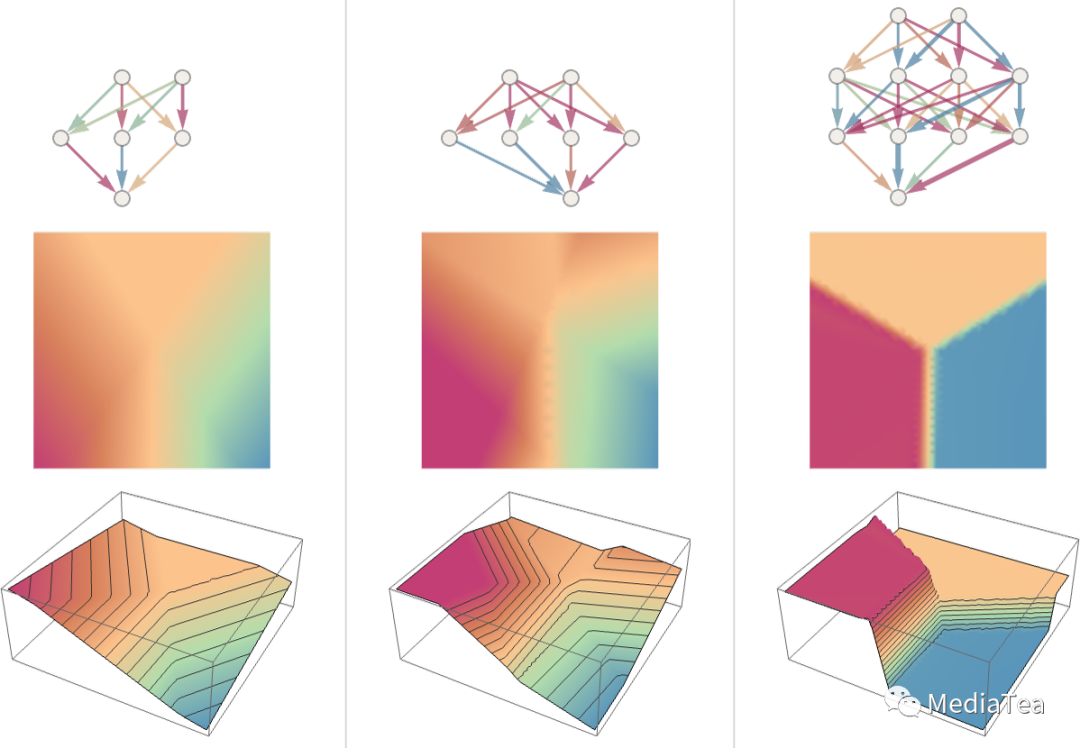
Bigger networks generally do better at approximating the function we’re aiming for. And in the “middle of each attractor basin” we typically get exactly the answer we want. But at the boundaries—where the neural net “has a hard time making up its mind”—things can be messier.
更大的网络通常在逼近我们目标函数方面做得更好。在各个“吸引子盆地”的中部,我们通常可以得到我们想要的确切答案。但在边界处——神经网络“很难做出决定”的地方——事情可能会更混乱。
With this simple mathematical-style “recognition task” it’s clear what the “right answer” is. But in the problem of recognizing handwritten digits, it’s not so clear. What if someone wrote a “2” so badly it looked like a “7”, etc.? Still, we can ask how a neural net distinguishes digits—and this gives an indication:
在这个简单的数学风格的“识别任务”中,很明显是什么是“正确答案”。但在识别手写数字的问题中,情况并不那么明确。如果有人把“2”写得很糟糕,看起来像“7”之类的数字,怎么办?尽管如此,我们可以问神经网络如何区分数字,这会给出一个指示:

Can we say “mathematically” how the network makes its distinctions? Not really. It’s just “doing what the neural net does”. But it turns out that that normally seems to agree fairly well with the distinctions we humans make.
我们能否以“数学”的方式描述神经网络是如何进行区分的呢?其实不能。它只是在“做神经网络该做的事”。但结果表明,这通常与我们人类所做的区分相当一致。
Let’s take a more elaborate example. Let’s say we have images of cats and dogs. And we have a neural net that’s been trained to distinguish them. Here’s what it might do on some examples:
让我们看一个更复杂的例子。假设我们有猫和狗的图片,还有一个经过训练的神经网络,用于区分它们。在一些例子中,它可能会这么做:

Now it’s even less clear what the “right answer” is. What about a dog dressed in a cat suit? Etc. Whatever input it’s given the neural net will generate an answer, and in a way reasonably consistent with how humans might. As I’ve said above, that’s not a fact we can “derive from first principles”. It’s just something that’s empirically been found to be true, at least in certain domains. But it’s a key reason why neural nets are useful: that they somehow capture a “human-like” way of doing things.
现在“正确答案”变得更加不清楚。如果有一只穿着猫装的狗呢?等等。无论输入是什么,神经网络都会生成一个答案,并以与人类相当一致的方式。就像我前面所说的,这并不是一个我们可以“从第一原则推导出来”的事实。这只是一些经验性的发现,至少在某些领域是成立的。但这是为什么神经网络是有用的关键原因:它们以某种方式捕捉了“类似于人类”的处理方式。
Show yourself a picture of a cat, and ask “Why is that a cat?”. Maybe you’d start saying “Well, I see its pointy ears, etc.” But it’s not very easy to explain how you recognized the image as a cat. It’s just that somehow your brain figured that out. But for a brain there’s no way (at least yet) to “go inside” and see how it figured it out. What about for an (artificial) neural net? Well, it’s straightforward to see what each “neuron” does when you show a picture of a cat. But even to get a basic visualization is usually very difficult.
向自己展示一张猫的图片,然后问:“为什么这是一只猫?”或许你会开始说:“嗯,我看到它尖尖的耳朵等等。”但解释你如何识别出这是一张猫的图片并不容易。只是不知怎么的,你的大脑就搞定了。但对于大脑来说,目前(至少)没有办法“进入”并看看它是如何弄清楚的。那么对于(人造的)神经网络呢?嗯,很难将其可视化。
In the final net that we used for the “nearest point” problem above there are 17 neurons. In the net for recognizing handwritten digits there are 2190. And in the net we’re using to recognize cats and dogs there are 60,650. Normally it would be pretty difficult to visualize what amounts to 60,650-dimensional space. But because this is a network set up to deal with images, many of its layers of neurons are organized into arrays, like the arrays of pixels it’s looking at.
在我们上面使用的最终网络中,有 17 个神经元。在用于识别手写数字的网络中,有 2190 个神经元。在我们用于识别猫和狗的网络中,有 60650 个神经元。通常,对于一个拥有 60650 维度的空间,将其可视化是非常困难的。但由于这是一个处理图像的网络,它的许多神经元层都组织成类似于它正在查看的像素阵列。
And if we take a typical cat image,
如果我们拿一个典型的猫的图片

then we can represent the states of neurons at the first layer by a collection of derived images—many of which we can readily interpret as being things like “the cat without its background”, or “the outline of the cat”:
然后我们可以通过一系列衍生图片来表示第一层的神经元的状态,其中很多图片我们可以轻松解释为“没有背景的猫”,或者“猫的轮廓”等:

By the 10th layer it’s harder to interpret what’s going on:
到第 10 层,很难解释正在发生什么:

But in general we might say that the neural net is “picking out certain features” (maybe pointy ears are among them), and using these to determine what the image is of. But are those features ones for which we have names—like “pointy ears”? Mostly not.
但总的来说,我们可以说神经网络“挑选出某些特征”,然后使用这些特征来确定图像所代表的是什么。但这些特征是否与我们有名称的特征相似,比如“尖尖的耳朵”?大多数并不是。
Are our brains using similar features? Mostly we don’t know. But it’s notable that the first few layers of a neural net like the one we’re showing here seem to pick out aspects of images (like edges of objects) that seem to be similar to ones we know are picked out by the first level of visual processing in brains.
我们的大脑是否使用类似的特征?我们大多数情况下并不知道。但值得注意的是,我们在这里展示的网络的前几层似乎会提取出与大脑中视觉处理的第一层所提取的相似的图像特征(如物体边缘)。
But let’s say we want a “theory of cat recognition” in neural nets. We can say: “Look, this particular net does it”—and immediately that gives us some sense of “how hard a problem” it is (and, for example, how many neurons or layers might be needed). But at least as of now we don’t have a way to “give a narrative description” of what the network is doing. And maybe that’s because it truly is computationally irreducible, and there’s no general way to find what it does except by explicitly tracing each step. Or maybe it’s just that we haven’t “figured out the science”, and identified the “natural laws” that allow us to summarize what’s going on.
但是,假设我们想要一个神经网络中的“猫识别理论”。我们可以说:“看,这个特定的网络能做到这一点”——这立刻让我们对“问题有多难”有了一定的了解(例如,可能需要多少神经元或层数)。但至少到目前为止,我们还没有办法“用叙述性的方式描述”网络在做什么。也许这是因为它在计算上是不可化简的,除非我们显式地追踪每一步。或者也许是因为我们还没有“解释这个科学”,找到了允许我们总结发生的事情的“自然法则”。
We’ll encounter the same kinds of issues when we talk about generating language with ChatGPT. And again it’s not clear whether there are ways to “summarize what it’s doing”. But the richness and detail of language (and our experience with it) may allow us to get further than with images.
当我们讨论使用 ChatGPT 生成语言时,我们将遇到相同类型的问题。同样,目前还不清楚是否有办法“总结它在做什么”。但是语言的丰富性和细节(以及我们对它的经验)可能使我们在这方面取得更大的进展。

“点赞有美意,赞赏是鼓励”