一、分布式锁的模型
(一)悲观锁: 认为线程安全问题一定会发生,因此在操作数据之前先获取锁,确保线程串行执行。例如Synchronized、Lock都属于悲观锁。
- 优点: 简单粗暴
- 缺点: 性能略低
(二)乐观锁: 认为线程安全问题不一定会发生,因此不加锁,只有在更新数据时判断有没有其他线程对数据做了修改,如果没有修改则认为是安全的,自己才能更新数据;如果已经被其它线程修改,说明发生了安全问题,此时可以重试或异常。
- 优点: 性能好
- 缺点: 存在成功率低的问题
(三)常见的实现方式:
- 版本号法: 通过 id-stock-version结构,通过查询的version与本次是否相同来判断是否被修改。
- CAS法: 是版本号法的改良版,是用 old-query-new的结构,通过第一次query出来的stock,与第二次提交的stock是否一致,若一致则 old = new;
二、Redis的分布式锁
(一)分布式锁的作用: 作为公用JVM锁监视器,集群中的每台JVM都能获取锁监视器监测的线程,多个JVM内部同步了线程执行。
(二)分布式锁的需求: 多进程可见、互斥、高可用、 高性能、安全性…
(三)常见分布式锁的差异:
| MySQL | Redis | Zookeeper | |
|---|---|---|---|
| 互斥 | 利用mysql本身的互斥锁机制 | 利用setnx这样的互斥命令 | 利用节点的唯一性和有序性实现互斥 |
| 高可用 | 好 | 好 | 好 |
| 高性能 | 一般 | 好 | 一般 |
| 安全性 | 断开连接,自动释放锁 | 利用锁超时时间,到期释放 | 临时节点,断开连接自动释放 |
(四)Redis实现分布式锁
1、获取锁:
- 互斥: 确保只有一个线程获取锁。
SETNX lock thread1
2、释放锁
- 手动释放:
DEL lock - 过期释放:
EXPIRE lock 5
(1)通过 SET 操作 实现原子性操作: SET lock thread1 EX 10 NX,意思是创建一个lock缓存,值为thread1,保持10s时间,NX为互斥操作
(2)当锁获取失败时的方法:
- 阻塞式获取锁: 一直等待到有线程释放锁。(对CPU资源消耗高)
- 非阻塞式获取锁: 失败就不再尝试获取锁。
3、代码实现分布式锁
(1)需求: 定义一个类,实现Redis分布式锁功能。
public class SimpleRedisLock implements ILockService {
private static final String LOCK = "lock:";
private String threadName;
private StringRedisTemplate redisTemplate;
public SimpleRedisLock() {
}
public SimpleRedisLock(String threadName, StringRedisTemplate redisTemplate) {
this.threadName = threadName;
this.redisTemplate = redisTemplate;
}
@Override
public boolean tryLock(long timeoutSec) {
//1、获取锁
Boolean absent = redisTemplate.opsForValue().setIfAbsent(LOCK + threadName, String.valueOf(Thread.currentThread().getId()), timeoutSec, TimeUnit.SECONDS);
return Boolean.TRUE.equals(absent);
}
@Override
public void unlock() {
//2、解锁
redisTemplate.delete(LOCK + threadName);
}
}
四、基于Redis的分布式锁优化——Redisson对象
(一)基于setnx实现的分布式锁存在的问题
- 不可重入: 同一个线程无法多次获得同一把锁
- 不可重试: 获取锁只尝试一次就返回false,没有重试机制
- 超时释放锁: 锁超时释放,虽然可以避免死锁,但在业务耗时过长,也会导致锁释放,存在安全隐患。
- 主从一致性: 如果Redis提供了主从集群,主从同步存在延迟,当主宕机时,如果从同步主中的所数据,则会出现锁实现。
(二)实现分布式锁的常用对象——Redisson
1、概念: Redisson是一个Redis的基础上实现的Java驻内存数据网络(In-Memory Data Grid)。提供了一系列分布式的Jav常用对象,还提供了许多分布式服务,其中包含了各种分布式锁的实现。
2、分布式锁的种类 官网地址: https://redisson.org
- 分布式锁(Lock)和同步器(Synchronizer)
- 可重入锁(Reentrant Lock)
- 公平锁(Fair Lock)
- 联锁(Multi Lock)
- 红锁(Red Lock)
- 读写锁(ReadWrite Lock)
- 信号量(Semaphore)
- 可过期性信号量(PermitExpirableSemaphore)
- 闭锁(CountDownLatch)
3、Redisson的基本使用
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.6</version>
</dependency>
@Configuration
public class RedisConfig {
@Bean
public RedissonClient redissonClient() {
//配置类
Config config = new Config();
//连接redis
config.useSingleServer().setAddress("redis://192.168.92.131:6379").setPassword("123321");
//创建客户端
return Redisson.create(config);
}
}
@Resource
private RedissonClient redissonClient;
@Test
void testRedisson() throws InterruptedException {
// 获取锁(可重入),指定锁名称
RLock lock = redissonClient.getLock("anyLock");
// 尝试获取锁,参数分别是: 获取锁的最大等待时间(期间会重试),锁自动释放时间,时间单位
boolean isLock = lock.tryLock(1, 10, TimeUnit.SECONDS);
// 判断释放获取成功
if(isLock){
try{
System.out.println("执行业务");
}finally{
//释放锁
lock.unlock();
}
}
}
4、Redisson可重入锁原理
(1)可重入锁是什么?
可重入锁是指一个线程可以多次获取一把锁的锁获取机制。
(2)ReentrantLock可重入原理
当线程获取锁时,如果有线程占用锁,就检查该线程是否是自己本身,若是自己则再一次尝试获取锁,每执行一次尝试获取锁,就会有个重入计数器记录线程重入的次数,在本次方法执行结束后释放锁,重入计数器相应减一,直到整个方法执行完,才能完整的将锁释放掉。
(3)基于Redis的可重入锁的实现方式
流程: 判断锁是否存在(若不存在,则获取锁并添加线程标识,设置锁有效期,执行业务,执行完毕后依旧需要判断锁的归属以及锁计数状态) 》判断锁标识是否是自己(若是,则锁计数+1) 》 若不是,获取锁失败 》
lua脚本
local key = KEYS[1];
local threadId = ARGV[1];
local releaseTime = ARGV[2];
--1、判断当前锁是否是自己
if (redis.call("HEXISTS", key, threadId) == 0) then
-- 不是,则直接返回
return nil;
end
-- 如果是,则计数器-1
local count = redis.call("HINCRBY", key, threadId, -1);
--2、判断统计数是否为0
if (count > 0) then
-- 统计数不为零,则重置计时器
redis.call("expire", key, releaseTime);
else
--统计数为零,则释放锁
redis.call("del", key);
return nil;
end
5、multiLock,主从一致性
(1)产生原因: 多台Redis,主节点主要存储最新的数据,从节点需要同步数据,在数据同步过程中,会产生延时,因为某些异常导致了主节点宕机了,从节点的数据就不一致并且因为锁对象锁定的redis宕机了,所以锁就失效了,产生了之前所提到的所有分布式安全问题。
(2)解决方法: 联锁机制。
(3)联锁机制的主从一致性的解决方式: 通过获取Redis集群的所有锁,只有获取了Redis集群的所有锁才能进行数据更新。
(4)Redssion的联锁: MultiLock
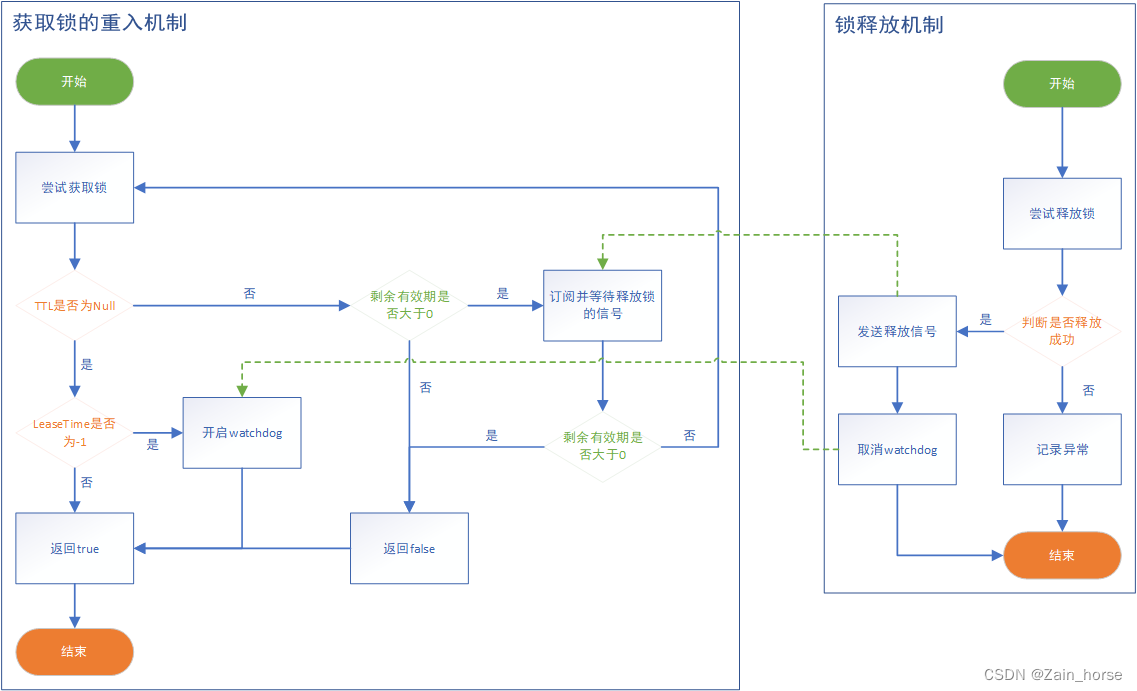
6、Redisson的锁重试以及WatchDog机制
(1)Redisson的锁重试机制的基本流程: 可自行查看RedissonLock类的重试锁机制和释放锁机制
- 将等待时间,释放时间,统一转换为毫秒级
- 第一次尝试获取锁(若返回的TTL为null,说明获取到了)
- 判断是否获取锁(阻塞等待结果返回)
- 判断锁释放时间是否为默认(传参了-1,表示默认),若为默认则使用WatchDog监控时间(30s),否则以传入的参数为准
- 使用异步释放函数,函数里包含了可重入锁实现的脚本(结果返回到一个Future类)
- 判断是否获取锁(阻塞等待结果返回)
- 若未获取到锁,则将等待时间减去获取锁的那段时间,并且加以判断等待时间是否不足(若不足,则放弃重试返回错误信息)
- 订阅当前尝试获取锁的线程标识(阻塞等待剩余等待时间,若还是没有释放锁的信号,则取消订阅并返回错误信息),当释放锁脚本中
publish命令执行后,开始进行锁获取 - 订阅到锁信号
- 判断等待时间是否充足(等待时间先被减去等待信号的时间,计算结果若小于零,则返回错误信息)
- 若充足,则循环尝试获取锁,直至锁成功获取,或等待时间不足返回错误(循环尝试并不是一直循环,只有在获取到锁信号的时候才会尝试获取)
三、分布式锁使用过程中的相关问题
(一)数据超量修改
1、产生原因: 由于多线程的参与,功能模块的方法之间执行顺序就会有差异,那么当多个线程由于操作顺序不同可能都查询到了库存还有剩余,都会去执行扣减库存的操作,这样原本库存数 < 请求线程数,就造成了库存直接变负的情况。
2、解决方案: 加锁,保持用户访问时持有锁才能修改操作。
3、加乐观锁和加悲观锁对问题解决效果
(1)加乐观锁: 由于是通过对更新前后数据变化进行判断是否能够更新数据,同时访问的线程,在线程 a 访问更新后,线程 b 由于更新前后访问的数据不一致,导致线程更新失败,同时在同一时期访问的线程全部失败,所以它的效率会极差,但依旧可以完成业务。
(2)加悲观锁: 由于线程 a 获得了锁,进入了访问更新阶段,但线程 b 并未获取锁而阻塞,若因为没有锁重试机制,可能会导致大量线程失败,相较于乐观锁的方式,成功率显然有所提升,并且其安全性也获得了提升,不会因为同一个用户的多次相同请求而多次更新。
(二)集群状态下,锁功能失效
1、产生原因: JVM内部维护了一个锁监视器,在同一个userid下,认为这个线程是同一个线程,但是当有两个或更多的JVM集群出来,而锁监视器并没有锁定同一个线程,所以才会有并发安全问题。
2、解决方案: 采用分布式锁
(三)业务阻塞导致锁超时释放
1、原因: 线程被阻塞,分布式锁超时被释放,导致线程运行混乱。
2、解决方法: 在业务完成后,先检查锁的标识是否一致,再判断是否释放锁。
(四)超时释放锁
1、产生原因: 由于JVM的垃圾回收机制,线程在释放锁之前可能会遭遇阻塞,造成超时释放锁
2、解决方法: 将判断表示与释放锁形成原子性。
3、实现方法: 使用Lua脚本,编写多条Redis,保证Redis命令的原子性。
3、Lua脚本的使用方法: Redis提供了一个回调函数,可以调用脚本。
EVAL "return redis.call('set', KEYS[1], ARGV[1])" 1 name Rose
4、释放锁的业务流程
- 获取锁中的线程标识
- 判断是否与指定标识(当前线程标识)一致
- 如果一致则释放锁(删除)
- 如果不一致则什么都不做