前言
当公司业务发展遇到瓶颈时,业务分析师以及决策者们总会希望通过交叉分析大量的业务数据和用户行为数据,以解答“为什么利润会下滑?”“为什么库存周转变慢了?”等问题,最终整点“干货”出来从而促进业务发展。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
数据库往往不擅长大量数据分析型的工作,所以出现了数据仓库。但数据仓库往往要求较高配置的底层基础设施,成本较高。企业为了控制成本,一般只会把建好模的、含金量较高的数据放在其中。但是,生产经营的很多数据企业难以短期判断有没有价值,丢弃了怕失去机会,保存在数仓里又会造成巨大成本,放在冷存储里,又不容易进行数据价值探索。
这个时候,数据湖应运而生。一方面它底层基于 Amazon Simple Storage Service (S3) 这样的对象存储,存储成本低;另外它与一系列数据处理工具打通,能够快速进行数据探索和数据挖掘,可以实现高效的”沙中淘金”。
传统数据湖虽然存储成本底,但是实效性也较低。传统的数据湖方案,常常基于 Apache Spark 进行T+1离线任务。公司的数据团队一般会定时在凌晨启动 Spark 进行 ETL 数据建模,这样业务在上班的时候就可以用截止到当天0点的数据。但是随着商业模式的演变,企业需要通过实时推荐、实时对账、实时预警等方式以占据竞争优势,而这些手段对数据的实时性都要求极高。笔者曾经听闻一则消息,某电商的运营人员,因为把小数点打错造成价格低于实际价格10倍,引起客户疯狂下单。第二天,公司分析师根据姗姗来迟的销量报告进行分析,花费数个小时才发现了这个问题。但这个时候造成的资产和信用的损失已经难以挽回。以笔者来看,如果采用实时数据技术,对实时数据流式应用机器学习或规则引擎技术,实时监控数据异常,该损失是很容易避免的,
本文将介绍一种实时数据湖方案,即能帮助企业低成本地使用海量数据,又能更快速地响应业务需求,同时借助亚马逊云科技的托管服务,能够快速实施和轻松运维。
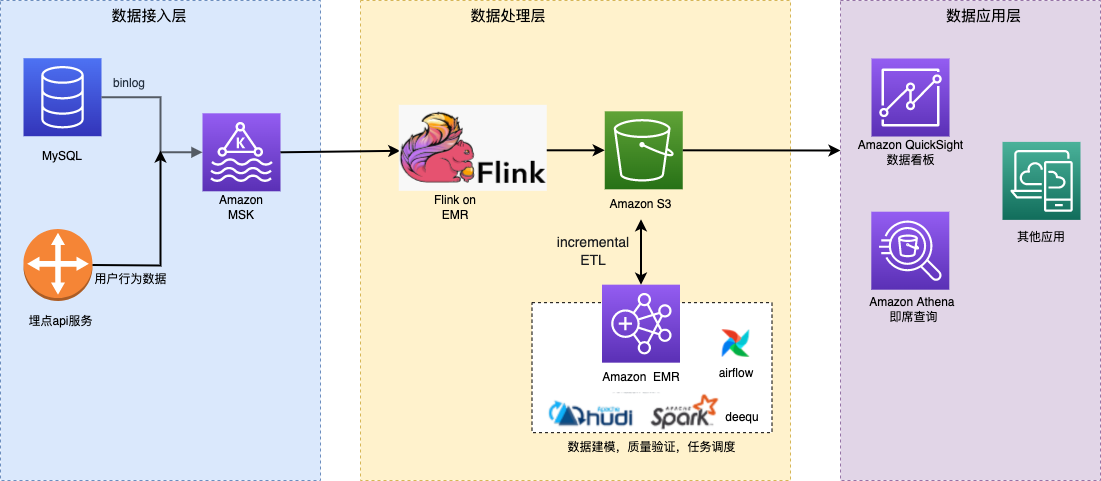
方案架构
整个架构为了保证数据的实效性,接入层使用 Apache Kafka 接入业务数据库的 binlog,而像用户行为这类数据,可以直接在埋点服务端调用 Kafka 的 producer api 将数据注入 Kafka。
在数据处理部分,我们使用 Apache Flink + Apache Hudi 进行增量消费,再使用 Apache Spark + Apache Hudi 的方式,实现增量ETL。整个架构能将数据延迟控制到秒级
借助亚马逊云科技托管的 Amazon Elastic MapReduce (EMR) 集群,你可以开箱即用 Flink, Spark 等服务。另外我们将使用 Amazon Managed Streaming for Apache Kafka (MSK) 托管 Kafka 消息队列,它能够让 Kafka 开箱即用,并且根据数据量动态扩缩容。
整个架构如下图:
关键服务介绍
整个架构中,我们使用了 Amazon EMR, Amazon MSK, Amazon S3, Apache Airflow,Apache Hudi 等服务或开源产品。下面笔者为大家简单进行介绍并说明使用它们为什么能让我们更轻松的搭建起整个实时数据湖
Amazon S3
Amazon S3 是专为从任意位置存储和检索任意数量的数据而构建的对象存储。Amazon S3 可以为不同用户、不同场景提供存储服务,比如数据湖、网站、移动应用、一般数据的备份恢复以及大数据分析等等。这是一种简单的存储服务,以极低的成本提供具备行业优势的耐久性、可用性、性能、安全性和几乎无限的可扩展性。使用 Amazon S3,您可以轻松构建使用原生云存储的应用程序。Amazon S3 具有高度可扩展性且按量计费,您可以从较小用量起步,之后根据需要扩展存储。
Amazon EMR
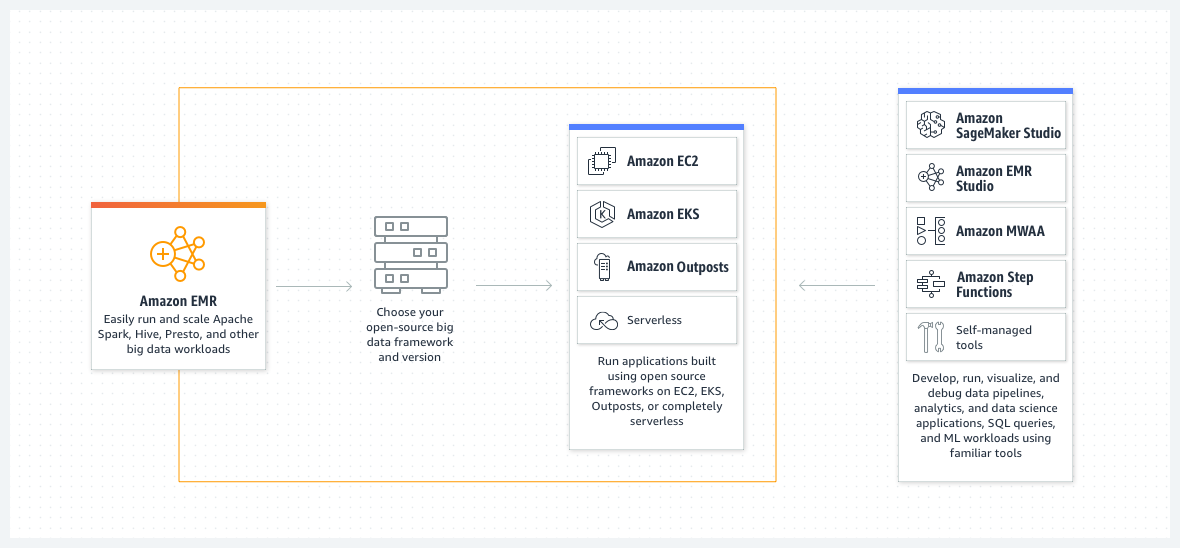
Amazon EMR 是行业先进的云计算大数据平台,适用于使用多种开源框架(例如 Apache Spark、Apache Hive、Presto)进行数据处理、交互分析和机器学习的场景。通过 Amazon EMR,您可以专注于数据转换和分析,而不必耗费时间精力用于管理计算能力或开源应用程序,此外还能节省资金成本。Amazon EMR采用存储和计算分离的架构,数据存储在 Amazon S3 上,计算资源来自 Amazon Elastic Compute Cloud (EC2) 实例。集群创建之后,MapReduce 通过 HDFS 代理调用 Amazon S3 接口,从 S3上读取和写入数据。Amazon EMR 为集群中的服务器定义了三种角色。
- 主节点——管理集群:协调将 MapReduce 可执行文件和原始数据子集分配到核心实例组和任务实例组。此外,它还会跟踪每个任务的执行状态,监控实例组的运行状况。一个集群中只有一个主节点。这与 Hadoop 主节点映射。
- 核心节点——使用 Hadoop 分布式文件系统(HDFS)运行任务和存储数据。这与 Hadoop 从属节点映射。
- 任务节点(可选)——运行任务:这与 Hadoop 从属节点映射。
Amazon MSK
Amazon MSK 是亚马逊云科技托管的高可用、强安全的 Kafka 服务,是数据分析领域负责消息传递的基础,也因此在流式数据入湖部分举足轻重。
Apache Airflow
Apache Airflow 是一项由 Airbnb 在 2014 年 推出的开源项目,其目的是为管理日益复杂的数据管理、脚本和分析工具,提供一个构建批处理工作流的方案。从功能来看,这是一种可扩展的分布式工作流调度系统,允许将工作流建模为有向无环图(DAGs),通过这种方式简化数据管道中各个处理步骤的创建、编排和监控。
Apache Hudi
Apache Hudi 是一个帮助企业构建流式数据湖的平台, Hudi 的含义是 Hadoop Upserts and Incrementals, 它的主要目的是高效减少摄取过程中的数据延迟, 由 Uber 开发并开源。它是一个表结构,提供了适用于Flink, Spark 的库,非常易于和现有大数据平台集成。
基础设施
该构建方案中使用到的基础设施除 Apache Airflow 外,均采用亚马逊云科技中国(宁夏)区域中的托管服务。Apache Airflow 采用 Docker 安装的方式,与其他组件在同一个 VPC 中。
构建方案
数据摄入
为了减少数据的延迟,我们在数据摄入过程中就采用流式数据。对于企业经营过程中的业务数据,一般存放在 MySQL 一类的关系型数据库,我们可以通过将 binlog接入 Kafka 完成,这个过程可以通过 Maxwell 一类的 binlog采集工具,也可以直接通过 Flink CDC。而对于用户行为数据的采集,各种埋点方案都可以直接把这些行为数据打入 Kafka。
使用 Apache Flink + Apache Hudi 构建 ODS 层表
数据接入 Kafka 以后,我们可以通过 Apache Flink + Apache Hudi 构建 ods 表。你可能会问这种方式构建的 ods 表和传统方式又和不同?
由于 Hudi 针对分布式数据存储提供了 插入更新(upsert)和增量消费两种原语,所以 Hudi 构建 raw table 天然能够同步原始数据的变更。
下面我将使用 Amazon EMR 6.4 版本来演示这个过程。启动 EMR 集群非常简单,我在这里不再赘述,您可以参考亚马逊云科技官方文档。
- 我们登陆 Amazon EMR 主节点,下载 hudi-flink-bundle 到 /usr/lib/flink/lib/ 目录中,即可使用 Hudi(你可以从 Central Repository: org/apache/hudi 下载合适你 Flink 版本的依赖包)
- 启动一个 Flink session
checkpoints=s3://xxxxxxxx/flink/checkpoints/
flink-yarn-session -jm 1024 -tm 4096 -s 2 \
-D state.backend=rocksdb \
-D state.checkpoint-storage=filesystem \
-D state.checkpoints.dir=${checkpoints} \
-D execution.checkpointing.interval=60000 \
-D state.checkpoints.num-retained=5 \
-D execution.checkpointing.mode=EXACTLY_ONCE \
-D execution.checkpointing.externalized-checkpoint-retention=RETAIN_ON_CANCELLATION \
-D state.backend.incremental=true \
-D execution.checkpointing.max-concurrent-checkpoints=1 \
-D rest.flamegraph.enabled=true \
-d \
-t /etc/hive/conf/hive-site.xml- 启动 Flink SQL。其中 application id 是 Flink session 的 application id
/usr/lib/flink/bin/sql-client.sh -s {application id}- 在启动好的 Flink SQL 客户端的中,创建一个 Kafka 流表。这里举个订单的例子
CREATE TABLE kafka_order (
order_id BIGINT,
user_mail STRING,
status STRING,
good_count BIGINT,
city STRING,
amount DECIMAL(10, 2),
create_time STRING,
update_time STRING
) WITH (
'connector' = 'kafka',
'topic' = 'order_table',
'properties.bootstrap.servers' = 'xxxxxxx.cn-northwest-1.amazonaws.com.cn:9092',
'properties.group.id' = 'testGroup1',
'format' = 'maxwell-json'
);注意,上面代码 connector 设置为 Kafka,所以你需要下载 Flink Kafka connector 到 /usr/lib/flink/lib/ 目录中
- 使用 Hudi connector 创建一张Hudi 表。
CREATE TABLE flink_hudi_order_ods(
order_id BIGINT,
user_mail STRING,
status STRING,
good_count BIGINT,
city STRING,
amount DECIMAL(10, 2),
create_time STRING,
update_time STRING,
ts TIMESTAMP(3),
logday VARCHAR(255),
hh VARCHAR(255)
)PARTITIONED BY (`logday`,`hh`)
WITH (
'connector' = 'hudi',
'path' = 's3://xxxxx/flink/flink_hudi_order_ods/',
'table.type' = 'COPY_ON_WRITE',
'write.precombine.field' = 'ts',
'write.operation' = 'upsert',
'hoodie.datasource.write.recordkey.field' = 'order_id',
'hive_sync.enable' = 'true',
'hive_sync.table' = 'flink_hudi_order_ods',
'hive_sync.mode' = 'HMS',
'hive_sync.use_jdbc' = 'false',
'hive_sync.username' = 'hadoop',
'hive_sync.partition_fields' = 'logday,hh',
'hive_sync.partition_extractor_class' = 'org.apache.hudi.hive.MultiPartKeysValueExtractor'
);- 将流式数据插入刚才创建的 Hudi 表
insert into flink_hudi_order_ods select * ,
CURRENT_TIMESTAMP as ts,
DATE_FORMAT(CURRENT_TIMESTAMP, 'yyyy-MM-dd') as logday,
DATE_FORMAT(CURRENT_TIMESTAMP, 'hh') as hh
from kafka_order;- 验证。一两分钟后,你应该可以通过 hive 或 glue catalog 查看到 flink_hudi_order 表,你可使用 hIve 或 Amazon Athena 查询这张表的数据。同时你也可以验证一下数据更新,在原始数据的 mysql 中更新某条记录,十多秒后再尝试在 hive 查询数据湖中的 flink_hudi_order_ods 表,应该发现刚才的更新已经同步到了数据湖中。
使用 Apache Spark + Apache Hudi 进行增量数据 ETL
接下来我们使用演示一下如何通过 Apache Spark + Apache Hudi 进行增量数据的 ETL
-
首先,你需要根据你的 Spark 版本下在 Amazon EMR master 节点下载hudi-spark-bundle 包
-
在编写 ETL 任务时,你需要把输出格式改为 hudi
df.write
.format("hudi")
.options(getQuickstartWriteConfigs)
.option(PRECOMBINE_FIELD.key(), "logday")
.option(RECORDKEY_FIELD.key(), "logday")
.option(PARTITIONPATH_FIELD.key(), "logday")
.option(OPERATION.key(), "upsert")
.option("hoodie.table.name", targetTbName)
.option("hoodie.datasource.hive_sync.enable", "true")
.option("hoodie.datasource.hive_sync.database", "default")
.option("hoodie.datasource.hive_sync.table", targetTbName)
.option("hoodie.datasource.hive_sync.mode", "HMS")
.option("hoodie.datasource.hive_sync.use_jdbc", "false")
.option("hoodie.datasource.hive_sync.username", "hadoop")
.option("hoodie.datasource.hive_sync.partition_fields", "logday")
.option(
"hoodie.datasource.hive_sync.partition_extractor_class", "org.apache.hudi.hive.MultiPartKeysValueExtractor" )
.mode(SaveMode.Append)
.save(basePath)- 由于我们要通过 Airflow 调度任务,所以在你的 Airflow DAG 文件应该如下方式启动你的任务
spark-submit \
--deploy-mode cluster \
--master yarn \
--class com.xxxx.xxxx.Demo \
--jars {app_dir}/hudi-spark3.1.2-bundle_2.12-0.10.1.jar,{app_dir}/spark-avro_2.12-3.1.2.jar \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.dynamicAllocation.enabled=false' \
{app_dir}/spark-scala-examples-1.0-SNAPSHOT.jar- 你也可以直接使用 spark-shell 直接查询 Hudi 表,如下演示如何将 Hudi 和 spark-shell 集成
spark-shell --jars ./hudi-spark3.1.2-bundle_2.12-0.10.1.jar,spark-avro_2.12-3.1.2.jar --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' --conf 'spark.dynamicAllocation.enabled=false'部署 Apache Airflow 并对 Spark 任务进行任务调度
在跟 Amazon EMR 同样的VPC中启动一台 Amazon EC2,操作系统可以选择 Amazon Linux 或者 CentOS。然后根据以下步骤安装 Apache Arflow。
-
安装 docker
-
安装 docker compose
-
使用 git clone GitHub - tuanavu/airflow-tutorial: Apache Airflow tutorial
-
cd 到airflow-tutorial目录
-
运行
docker-compose up -d 命令
执行完第五步的命令,Apache Airflow 相关软件将被下载和安装,安装完成之后,我们可以通过编写 DAG 来对 Spark 进行任务调度。
如何调度 Amazon EMR 上的 Spark 任务呢?我们建议使用 Airflow ssh hook,这种方式配置简单,并且容许你的 Airflow 单独部署。我们需要保证 Airflow 集群能够访问你的 Amazon EMR 集群,所以如果你的 Airflow 是单独部署,没有部署在 Amazon EMR 集群中,你需要保证二者的网络互通,另外 Airflow 可以通过 ssh 访问你的 Amazon EMR master 节点。具体配置方式是在 Airflow 配置 ssh 的默认信息的地方,配置好 Amazon EMR master 节点的信息,用户账号,以及 Amazon EMR master 节点 ssh 私钥地址。这里有个需要注意的问题,由于我们使用的是 docker 启动 Airflow,所以您的 ssh 私钥要保证 docker 内部可访问。
总结
本文在 Amazon EMR 集群上,演示了如何通过使用Flink, Spark 等服务与Hudi 集成,配合 Airflow, Amazon MSK 等服务实现了一个流式数据湖,从而有效的减少了数据从产生到消费的数据延迟。
借助 Amazon EMR 和 Amazon MSK, 消除了 Flink /Spark/Kafka 等基础服务运营开销,让这些服务开箱即用,从而使我们只要关心数据湖的构建以及湖上的数据处理。
本篇作者

许庭新
西云数据解决方案架构师,10+年产品研发和解决方案咨询经验,在电商,互联网金融,智能汽车领域有丰富的实战经验,擅长利用云计算、大数据,AI等技术挖掘用户底层需求,实现精准运营。

蔡如海
西云数据解决方案架构师,10+年开发和架构经验,曾就职于知名外企,在媒体、金融等业务领域有丰富的工作经验,擅长云计算、机器学习等技术,并且有丰富的项目管理经验。
文章来源:https://dev.amazoncloud.cn/column/article/6309c8990c9a20404da7914f?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN
![一、Postfix[安装与配置、smtp认证、Python发送邮件以及防垃圾邮件方法、使用腾讯云邮件服务]](https://img-blog.csdnimg.cn/08eeaeb3b7074842bda39e804be2d01e.png)