什么是 HTTP 长轮询?
Web 应用程序最初是围绕客户端/服务器模型开发的,其中 Web 客户端始终是事务的发起者,向服务器请求数据。因此,没有任何机制可以让服务器在没有客户端先发出请求的情况下独立地向客户端发送或推送数据。
为了克服这个缺陷,Web 应用程序开发人员可以实施一种称为 HTTP长轮询的技术,其中客户端轮询服务器以请求新信息。服务器保持请求打开,直到有新数据可用。一旦可用,服务器就会响应并发送新信息。客户端收到新信息后,立即发送另一个请求,重复上述操作。
什么是 HTTP 长轮询?
那么,什么是长轮询?HTTP 长轮询是标准轮询的一种变体,它模拟服务器有效地将消息推送到客户端(或浏览器)。
长轮询是最早开发的允许服务器将数据“推送”到客户端的技术之一,并且由于其寿命长,它在所有浏览器和 Web 技术中几乎无处不在。即使在一个专门为持久双向通信设计的协议(例如 WebSockets)的时代,长轮询的能力仍然作为一种无处不在的回退机制占有一席之地。
HTTP 长轮询如何工作?
要了解长轮询,首先要考虑使用 HTTP 的标准轮询。
“标准”HTTP 轮询
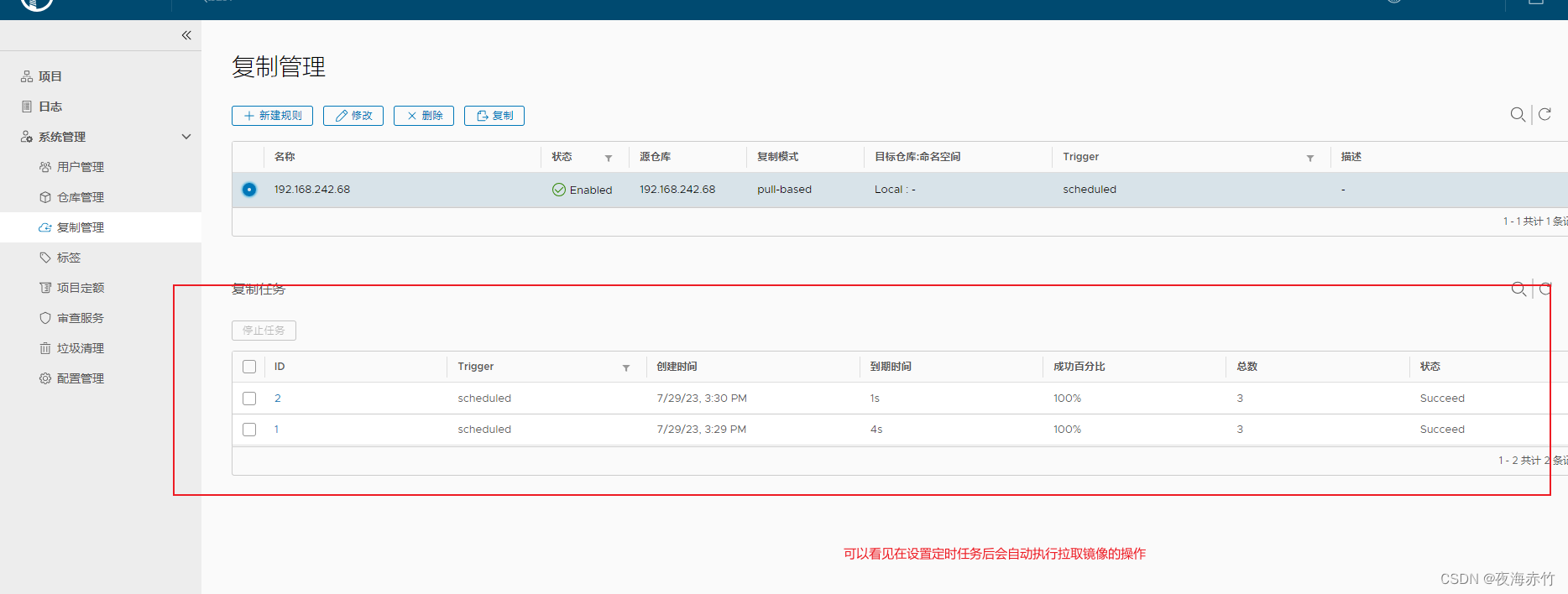
HTTP 轮询由客户端(例如 Web 浏览器)组成,不断向服务器请求更新。
一个用例是想要关注快速发展的新闻报道的用户。在用户的浏览器中,他们已经加载了网页,并希望该网页随着新闻报道的展开而更新。实现这一点的一种方法是浏览器反复询问新闻服务器“内容是否有任何更新”,然后服务器将以更新作为响应,或者如果没有更新则给出空响应。浏览器请求更新的速率决定了新闻页面更新的频率——更新之间的时间过长意味着重要的更新被延迟。更新之间的时间太短意味着会有很多“无更新”响应,从而导致资源浪费和效率低下。

上图:Web 浏览器和服务器之间的 HTTP 轮询。服务器向立即响应的服务器发出重复请求。
这种“标准”HTTP 轮询有缺点:
- 更新请求之间没有完美的时间间隔。请求总是要么太频繁(效率低下)要么太慢(更新时间比要求的要长)。
- 随着规模的扩大和客户端数量的增加,对服务器的请求数量也会增加。由于资源被无目的使用,这可能会变得低效和浪费。
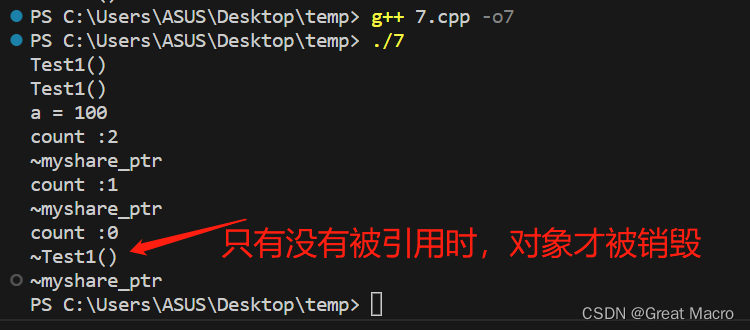
HTTP 长轮询解决了使用 HTTP 进行轮询的缺点
- 请求从浏览器发送到服务器,就像以前一样
- 服务器不会关闭连接,而是保持连接打开,直到有数据供服务器发送
- 客户端等待服务器的响应。
- 当数据可用时,服务器将其发送给客户端
- 客户端立即向服务器发出另一个 HTTP 长轮询请求

上图:客户端和服务器之间的 HTTP 长轮询。请注意,请求和响应之间有很长的时间,因为服务器会等待直到有数据要发送。
这比常规轮询更有效率。
- 浏览器将始终在可用时接收最新更新
- 服务器不会被永远无法满足的请求所搞垮。
长轮询有多长时间?
在现实世界中,任何与服务器的客户端连接最终都会超时。服务器在响应之前保持连接打开的时间取决于几个因素:服务器协议实现、服务器体系结构、客户端标头和实现(特别是 HTTP Keep-Alive 标头)以及用于启动的任何库并保持连接。
当然,许多外部因素也会影响连接,例如,移动浏览器在 WiFi 和蜂窝连接之间切换时更有可能暂时断开连接。
通常,除非您可以控制整个架构堆栈,否则没有单一的轮询持续时间。
使用长轮询时的注意事项
在您的应用程序中使用 HTTP 长轮询构建实时交互时,需要考虑几件事情,无论是在开发方面还是在操作/扩展方面。
- 随着使用量的增长,您将如何编排实时后端?
- 当移动设备在WiFi和蜂窝网络之间快速切换或失去连接,IP地址发生变化时,长轮询会自动重新建立连接吗?
- 通过长轮询,您能否管理消息队列并如何处理丢失的消息?
- 长轮询是否提供跨多个服务器的负载平衡或故障转移支持?
在为服务器推送构建具有 HTTP 长轮询的实时应用程序时,您必须开发自己的通信管理系统。这意味着您将负责更新、维护和扩展您的后端基础设施。
服务器性能和扩展
使用您的解决方案的每个客户端将至少每 5 分钟启动一次与您的服务器的连接,并且您的服务器将需要分配资源来管理该连接,直到它准备好满足客户端的请求。一旦完成,客户端将立即重新启动连接,这意味着实际上,服务器将需要能够永久分配其资源的一部分来为该客户端提供服务。当您的解决方案超出单个服务器的能力并且引入负载平衡时,您需要考虑会话状态——如何在服务器之间共享客户端状态?您如何应对连接不同 IP 地址的移动客户端?您如何处理潜在的拒绝服务攻击?
这些扩展挑战都不是 HTTP 长轮询独有的,但协议的设计可能会加剧这些挑战——例如,您如何区分多个客户端发出多个真正的连续请求和拒绝服务攻击?
消息排序和排队
在服务器向客户端发送数据和客户端发起轮询请求之间总会有一小段时间,数据可能会丢失。
服务器在此期间要发送给客户端的任何数据都需要缓存起来,并在下一次请求时传递给客户端。

然后出现几个明显的问题:
- 服务器应该将数据缓存或排队多长时间?
- 应该如何处理失败的客户端连接?
- 服务器如何知道同一个客户端正在重新连接,而不是新客户端?
- 如果重新连接花费了很长时间,客户端如何请求落在缓存窗口之外的数据?
所有这些问题都需要 HTTP 长轮询解决方案来回答。
设备和网络支持
如前所述,由于 HTTP 长轮询已经存在了很长时间,它在浏览器、服务器和其他网络基础设施(交换机、路由器、代理、防火墙)中几乎得到了无处不在的支持。这种级别的支持意味着长轮询是一种很好的后备机制,即使对于依赖更现代协议(如 WebSockets )的解决方案也是如此。
众所周知,WebSocket 实现,尤其是早期实现,在双重 NAT 和某些 HTTP 长轮询运行良好的代理环境中挣扎。