文章目录
- File文件操作
- FileInfo接口
- 权限
- 打开模式
- File操作
- 文件读取
- I/O操作
- io包
- 文件复制
- io包下的Read()和Write()
- io包下的Copy()
- ioutil包
- 总结
- 断点续传
- Seeker接口
- 断点续传
- bufio包
- bufio包原理
- Reader对象
- Writer对象
- bufio包
- bufio.Reader
- bufio.Writer
- ioutil包
- ioutil包的方法
- 示例代码
- 遍历文件夹
- 并发性Concurrency
- 多任务
- 什么是并发
- 进程、线程、协程
- 进程
- 线程
- 协程
- Go语言的协程——Goroutine
- Goroutine
- 什么是Goroutine
- 主goroutine
- 如何使用Goroutines
- 启动多个Goroutines
- Go语言的并发模型
- 线程模型
- 内核级线程模型
- 用户级线程模型
- 两级线程模型
- Go并发调度: G-P-M模型
- 调度器是如何工作的
- 线程阻塞
- runqueue执行完成
- 最后
- 示例
- runtime包
- 常用函数
- 示例代码
- 临界资源
- 临界资源安全问题
- 临界资源安全问题的解决
- 最后
- WaitGroup
- Add()方法
- Done()方法
- Wait()方法
- 示例代码
- 互斥锁
- Mutex(互斥锁)
- Lock()方法
- Unlock()方法
- 示例代码
- 读写锁
- RWMutex(读写锁)
- 常用方法
- RLock()方法
- RUnlock()方法
- Lock()方法
- Unlock()方法
- 示例代码
- channel通道
- 什么是通道
- 通道的概念
- 通道的声明
- channel的数据类型
- 通道的注意点
- 通道的使用语法
- 发送和接收
- 发送和接收默认是阻塞的
- 死锁
- 关闭通道
- 通道上的范围循环
- 缓冲通道
- 非缓冲通道
- 缓冲通道
- 示例代码
- 定向通道
- 双向通道
- 单向通道
- time包中的通道相关函数
- time.NewTimer()
- timer.Stop
- time.After()
- select语句
- 语法结构
- 示例代码
- Go语言的CSP模型
- CSP是什么
- Golang CSP
- Channel
- Goroutine
- Goroutine 调度器
- 最后
- 反射
- 引入
- 相关基础
- 反射的使用
- TypeOf和ValueOf
- 从relfect.Value中获取接口interface的信息
- 已知原有类型【进行“强制转换”】
- 未知原有类型【遍历探测其Filed】
- 通过reflect.ValueOf设置实际变量的值
- 通过reflect.ValueOf来进行方法的调用
- 通过反射,调用函数
- 结构体
- 匿名结构体
- 通过反射,修改结构体的数据
File文件操作
首先,file类是在os包中的,封装了底层的文件描述符和相关信息,同时封装了Read和Write的实现
FileInfo接口
FileInfo接口中定义了File信息相关的方法。
type FileInfo interface {
Name() string // base name of the file 文件名.扩展名 1.txt
Size() int64 // 文件大小,字节数 12540
Mode() FileMode // 文件权限 -rw-rw-rw-
ModTime() time.Time // 修改时间 2018-04-13 16:30:53 +0800 CST
IsDir() bool // 是否文件夹
Sys() interface{} // 基础数据源接口(can return nil)
}
示例代码:
package main
import (
"fmt"
"os"
)
func main() {
fileInfo, err := os.Stat("main/1.md")
if err != nil {
fmt.Println("err :", err)
return
}
fmt.Printf("%T\n", fileInfo)
//文件名
fmt.Println(fileInfo.Name())
//文件大小
fmt.Println(fileInfo.Size())
//是否是目录
fmt.Println(fileInfo.IsDir()) //IsDirectory
//修改时间
fmt.Println(fileInfo.ModTime())
//权限
fmt.Println(fileInfo.Mode()) //-rw-r--r--
}
输出结果:
*os.fileStat
1.md
47
false
2023-06-10 21:30:41.7576415 +0800 CST
-rw-rw-rw-
权限
至于操作权限perm,除非创建文件时才需要指定,不需要创建新文件时可以将其设定为0。虽然go语言给perm权限设定了很多的常量,但是习惯上也可以直接使用数字,如0666(具体含义和Unix系统的一致)。
权限控制:
linux 下有2种文件权限表示方式,即“符号表示”和“八进制表示”。
(1)符号表示方式:
- --- --- ---
type owner group others
文件的权限是这样子分配的 读 写 可执行 分别对应的是 r w x 如果没有那一个权限,用 - 代替
(-文件 d目录 |连接符号)
例如:-rwxr-xr-x
(2)八进制表示方式:
r ——> 004
w ——> 002
x ——> 001
- ——> 000
0755
0777(owner,group,others都是可读可写可执行)
0555
0444
0666
打开模式
文件打开模式:
const (
O_RDONLY int = syscall.O_RDONLY // 只读模式打开文件
O_WRONLY int = syscall.O_WRONLY // 只写模式打开文件
O_RDWR int = syscall.O_RDWR // 读写模式打开文件
O_APPEND int = syscall.O_APPEND // 写操作时将数据附加到文件尾部
O_CREATE int = syscall.O_CREAT // 如果不存在将创建一个新文件
O_EXCL int = syscall.O_EXCL // 和O_CREATE配合使用,文件必须不存在
O_SYNC int = syscall.O_SYNC // 打开文件用于同步I/O
O_TRUNC int = syscall.O_TRUNC // 如果可能,打开时清空文件
)
File操作
type File
//File代表一个打开的文件对象。
func Create(name string) (file *File, err error)
//Create采用模式0666(任何人都可读写,不可执行)创建一个名为name的文件,如果文件已存在会截断它(为空文件)。如果成功,返回的文件对象可用于I/O;对应的文件描述符具有O_RDWR模式。如果出错,错误底层类型是*PathError。
func Open(name string) (file *File, err error)
//Open打开一个文件用于读取。如果操作成功,返回的文件对象的方法可用于读取数据;对应的文件描述符具有O_RDONLY模式。如果出错,错误底层类型是*PathError。
func OpenFile(name string, flag int, perm FileMode) (file *File, err error)
//OpenFile是一个更一般性的文件打开函数,大多数调用者都应用Open或Create代替本函数。它会使用指定的选项(如O_RDONLY等)、指定的模式(如0666等)打开指定名称的文件。如果操作成功,返回的文件对象可用于I/O。如果出错,错误底层类型是*PathError。
func NewFile(fd uintptr, name string) *File
//NewFile使用给出的Unix文件描述符和名称创建一个文件。
func Pipe() (r *File, w *File, err error)
//Pipe返回一对关联的文件对象。从r的读取将返回写入w的数据。本函数会返回两个文件对象和可能的错误。
func (f *File) Name() string
//Name方法返回(提供给Open/Create等方法的)文件名称。
func (f *File) Stat() (fi FileInfo, err error)
//Stat返回描述文件f的FileInfo类型值。如果出错,错误底层类型是*PathError。
func (f *File) Fd() uintptr
//Fd返回与文件f对应的整数类型的Unix文件描述符。
func (f *File) Chdir() error
//Chdir将当前工作目录修改为f,f必须是一个目录。如果出错,错误底层类型是*PathError。
func (f *File) Chmod(mode FileMode) error
//Chmod修改文件的模式。如果出错,错误底层类型是*PathError。
func (f *File) Chown(uid, gid int) error
//Chown修改文件的用户ID和组ID。如果出错,错误底层类型是*PathError。
func (f *File) Close() error
//Close关闭文件f,使文件不能用于读写。它返回可能出现的错误。
示例代码:
package main
import (
"fmt"
"os"
"path/filepath"
)
func main() {
//1.路径
fileName1 := "C:\\GolandProjects\\GoProject1\\main\\1.md"
fileName2 := "main/1.md"
//判断是否是绝对路径
fmt.Println(filepath.IsAbs(fileName1)) //true
fmt.Println(filepath.IsAbs(fileName2)) //false
//转化为绝对路径
//fmt.Println(filepath.Abs(fileName1))
//fmt.Println(filepath.Abs(fileName2)) // C:\GolandProjects\GoProject1\main\1.md <nil>
//1.获取目录
//fmt.Println("获取父目录:", filepath.Join(fileName1, ".."))
//fmt.Println("获取父目录:", filepath.Dir(fileName1))
//fmt.Println("获取当前目录:", filepath.Join(fileName1, "."))
//2.创建目录
err := os.Mkdir("main/app", os.ModePerm) //权限0777
if err != nil {
fmt.Println("err:", err)
return
}
fmt.Println("文件夹创建成功。。")
//err := os.MkdirAll("main/a/b/c", os.ModePerm)
//if err != nil {
// fmt.Println("err:", err)
// return
//}
//fmt.Println("多层文件夹创建成功")
//3.创建文件:Create采用模式0666(任何人都可读写,不可执行)创建一个名为name的文件,如果文件已存在会截断它(为空文件)
//file1, err := os.Create(fileName1)
//if err != nil {
// fmt.Println("err:", err)
// return
//}
//fmt.Println(file1)
//file2, err := os.Create(fileName2) //创建相对路径的文件,是以当前工程为参照的
//if err != nil {
// fmt.Println("err :", err)
// return
//}
//fmt.Println(file2)
//4.打开文件:
//file3, err := os.Open(fileName1) //只读的
//if err != nil {
// fmt.Println("err:", err)
// return
//}
//fmt.Println(file3)
/*
第一个参数:文件名称
第二个参数:文件的打开方式
const (
// Exactly one of O_RDONLY, O_WRONLY, or O_RDWR must be specified.
O_RDONLY int = syscall.O_RDONLY // open the file read-only.
O_WRONLY int = syscall.O_WRONLY // open the file write-only.
O_RDWR int = syscall.O_RDWR // open the file read-write.
// The remaining values may be or'ed in to control behavior.
O_APPEND int = syscall.O_APPEND // append data to the file when writing.
O_CREATE int = syscall.O_CREAT // create a new file if none exists.
O_EXCL int = syscall.O_EXCL // used with O_CREATE, file must not exist.
O_SYNC int = syscall.O_SYNC // open for synchronous I/O.
O_TRUNC int = syscall.O_TRUNC // truncate regular writable file when opened.
)
第三个参数:文件的权限:文件不存在创建文件,需要指定权限
*/
//file4, err := os.OpenFile(fileName1, os.O_RDONLY|os.O_WRONLY, os.ModePerm)
//if err != nil {
// fmt.Println("err:", err)
// return
//}
//fmt.Println(file4)
//5关闭文件,
//err := file4.Close()
//if err != nil {
// return
//}
//6.删除文件或文件夹:
//删除文件(该方法也可以删除空目录)
//err := os.Remove("main/1.md")
//if err != nil {
// fmt.Println("err:", err)
// return
//}
//fmt.Println("删除文件成功。。")
//删除目录
//err := os.RemoveAll("main/a/b/c")
//if err != nil {
// fmt.Println("err:", err)
// return
//}
//fmt.Println("删除目录成功。。
文件读取
文件的操作函数和方法的介绍:
func (f *File) Readdir(n int) (fi []FileInfo, err error)
//Readdir读取目录f的内容,返回一个有n个成员的[]FileInfo,这些FileInfo是被Lstat返回的,采用目录顺序。对本函数的下一次调用会返回上一次调用剩余未读取的内容的信息。如果n>0,Readdir函数会返回一个最多n个成员的切片。这时,如果Readdir返回一个空切片,它会返回一个非nil的错误说明原因。如果到达了目录f的结尾,返回值err会是io.EOF。如果n<=0,Readdir函数返回目录中剩余所有文件对象的FileInfo构成的切片。此时,如果Readdir调用成功(读取所有内容直到结尾),它会返回该切片和nil的错误值。如果在到达结尾前遇到错误,会返回之前成功读取的FileInfo构成的切片和该错误。
func (f *File) Readdirnames(n int) (names []string, err error)
//Readdir读取目录f的内容,返回一个有n个成员的[]string,切片成员为目录中文件对象的名字,采用目录顺序。对本函数的下一次调用会返回上一次调用剩余未读取的内容的信息。如果n>0,Readdir函数会返回一个最多n个成员的切片。这时,如果Readdir返回一个空切片,它会返回一个非nil的错误说明原因。如果到达了目录f的结尾,返回值err会是io.EOF。如果n<=0,Readdir函数返回目录中剩余所有文件对象的名字构成的切片。此时,如果Readdir调用成功(读取所有内容直到结尾),它会返回该切片和nil的错误值。如果在到达结尾前遇到错误,会返回之前成功读取的名字构成的切片和该错误。
func (f *File) Truncate(size int64) error
//Truncate改变文件的大小,它不会改变I/O的当前位置。 如果截断文件,多出的部分就会被丢弃。如果出错,错误底层类型是*PathError。
func (f *File) Read(b []byte) (n int, err error)
//Read方法从f中读取最多len(b)字节数据并写入b。它返回读取的字节数和可能遇到的任何错误。文件终止标志是读取0个字节且返回值err为io.EOF。
func (f *File) ReadAt(b []byte, off int64) (n int, err error)
//ReadAt从指定的位置(相对于文件开始位置)读取len(b)字节数据并写入b。它返回读取的字节数和可能遇到的任何错误。当n<len(b)时,本方法总是会返回错误;如果是因为到达文件结尾,返回值err会是io.EOF。
func (f *File) Write(b []byte) (n int, err error)
//Write向文件中写入len(b)字节数据。它返回写入的字节数和可能遇到的任何错误。如果返回值n!=len(b),本方法会返回一个非nil的错误。
func (f *File) WriteString(s string) (ret int, err error)
//WriteString类似Write,但接受一个字符串参数。
func (f *File) WriteAt(b []byte, off int64) (n int, err error)
//WriteAt在指定的位置(相对于文件开始位置)写入len(b)字节数据。它返回写入的字节数和可能遇到的任何错误。如果返回值n!=len(b),本方法会返回一个非nil的错误。
func (f *File) Seek(offset int64, whence int) (ret int64, err error)
//Seek设置下一次读/写的位置。offset为相对偏移量,而whence决定相对位置:0为相对文件开头,1为相对当前位置,2为相对文件结尾。它返回新的偏移量(相对开头)和可能的错误。
func (f *File) Sync() (err error)
//Sync递交文件的当前内容进行稳定的存储。一般来说,这表示将文件系统的最近写入的数据在内存中的拷贝刷新到硬盘中稳定保存。
I/O操作
I/O操作也叫输入输出操作。其中I是指Input,O是指Output,用于读或者写数据的,有些语言中也叫流操作,是指数据通信的通道。
Golang 标准库对 IO 的抽象非常精巧,各个组件可以随意组合,可以作为接口设计的典范。
io包
io包中提供I/O原始操作的一系列接口。它主要包装了一些已有的实现,如 os 包中的那些,并将这些抽象成为实用性的功能和一些其他相关的接口。
由于这些接口和原始的操作以不同的实现包装了低级操作,客户不应假定它们对于并行执行是安全的。
在io包中最重要的是两个接口:Reader和Writer接口,首先来介绍这两个接口。
Reader接口的定义,Read()方法用于读取数据。
type Reader interface {
Read(p []byte) (n int, err error)
}
Read 将 len§ 个字节读取到 p 中。它返回读取的字节数 n(0 <= n <= len§)以及任何遇到的错误。即使 Read 返回的 n < len§,它也会在调用过程中使用 p的全部作为暂存空间。若一些数据可用但不到 len§ 个字节,Read 会照例返回可用的东西,而不是等待更多。
当 Read 在成功读取 n > 0 个字节后遇到一个错误或 EOF 情况,它就会返回读取的字节数。它会从相同的调用中返回(非nil的)错误或从随后的调用中返回错误(和 n == 0)。这种一般情况的一个例子就是 Reader 在输入流结束时会返回一个非零的字节数,可能的返回不是 err == EOF 就是 err == nil。无论如何,下一个 Read 都应当返回 0, EOF。
调用者应当总在考虑到错误 err 前处理 n > 0 的字节。这样做可以在读取一些字节,以及允许的 EOF 行为后正确地处理I/O错误。
Read 的实现会阻止返回零字节的计数和一个 nil 错误,调用者应将这种情况视作空操作。
示例代码:
package main
import (
"fmt"
"io"
"os"
)
func main() {
/*
读取数据:
Reader接口:
Read(p []byte)(n int, error)
*/
//读取本地1.txt文件中的数据
//step1:打开文件
fileName := "main/1.txt"
file, err := os.Open(fileName)
if err != nil {
fmt.Println("err:", err)
return
}
//step3:关闭文件
defer func(file *os.File) {
err := file.Close()
if err != nil {
}
}(file)
//step2:读取数据
bs := make([]byte, 4, 4)
/*
//第一次读取
n, err := file.Read(bs)
fmt.Println(err) //<nil>
fmt.Println(n) //4
fmt.Println(bs) //[97 98 99 100]
fmt.Println(string(bs)) //abcd
//第二次读取
n, err = file.Read(bs)
fmt.Println(err) //<nil>
fmt.Println(n) //4
fmt.Println(bs) //[101 102 103 104]
fmt.Println(string(bs)) //efgh
//第三次读取
n, err = file.Read(bs)
fmt.Println(err) //<nil>
fmt.Println(n) //2
fmt.Println(bs) //[105 106 103 104]
fmt.Println(string(bs)) //ijgh
//第四次读取
n, err = file.Read(bs)
fmt.Println(err) //EOF,文件的末尾
fmt.Println(n) //0
*/
n := -1
for {
n, err = file.Read(bs)
if n == 0 || err == io.EOF {
fmt.Println("读取到了文件的末尾,结束读取操作。。")
break
}
fmt.Println(n)
fmt.Println(string(bs[:n]))
}
/*
abcd
efgh
ij
读取到了文件的末尾,结束读取操作。。
*/
}
Writer接口的定义,Write()方法用于写出数据。
type Writer interface {
Write(p []byte) (n int, err error)
}
Write 将 len§ 个字节从 p 中写入到基本数据流中。它返回从 p 中被写入的字节数n(0 <= n <= len§)以及任何遇到的引起写入提前停止的错误。若 Write 返回的n < len§,它就必须返回一个非nil的错误。Write 不能修改此切片的数据,即便它是临时的。
示例代码:
package main
import (
"fmt"
"log"
"os"
)
func main() {
fileName := "main/1.txt"
//step1:打开文件
//step2:写出数据
//step3:关闭文件
//file, err := os.Open(fileName)
file, err := os.OpenFile(fileName, os.O_CREATE|os.O_WRONLY|os.O_APPEND, os.ModePerm)
if err != nil {
fmt.Println(err)
return
}
defer file.Close()
//写出数据
//bs := []byte{65, 66, 67, 68, 69, 70} //A,B,C,D,E,F
//bs := []byte{97, 98, 99, 100} //a,b,c,d
//n,err := file.Write(bs)
//n, err := file.Write(bs[:2])
//fmt.Println(n)
//HandleErr(err)
//file.WriteString("\n")
//
//直接写出字符串
//n, err := file.WriteString("HelloWorld")
//fmt.Println(n)
//HandleErr(err)
file.WriteString("\n")
n, err := file.Write([]byte("today"))
fmt.Println(n)
HandleErr(err)
}
func HandleErr(err error) {
if err != nil {
log.Fatal(err)
}
}
Seeker接口的定义,封装了基本的 Seek 方法。
type Seeker interface {
Seek(offset int64, whence int) (int64, error)
}
Seeker 用来移动数据的读写指针
Seek 设置下一次读写操作的指针位置,每次的读写操作都是从指针位置开始的
whence 的含义:
如果 whence 为 0:表示从数据的开头开始移动指针
如果 whence 为 1:表示从数据的当前指针位置开始移动指针
如果 whence 为 2:表示从数据的尾部开始移动指针
offset 是指针移动的偏移量
返回移动后的指针位置和移动过程中遇到的任何错误
ReaderFrom接口的定义,封装了基本的 ReadFrom 方法。
type ReaderFrom interface {
ReadFrom(r Reader) (n int64, err error)
}
ReadFrom 从 r 中读取数据到对象的数据流中
直到 r 返回 EOF 或 r 出现读取错误为止
返回值 n 是读取的字节数
返回值 err 就是 r 的返回值 err
WriterTo接口的定义,封装了基本的 WriteTo 方法。
type WriterTo interface {
WriteTo(w Writer) (n int64, err error)
}
WriterTo 将对象的数据流写入到 w 中
直到对象的数据流全部写入完毕或遇到写入错误为止
返回值 n 是写入的字节数
返回值 err 就是 w 的返回值 err
定义ReaderAt接口,ReaderAt 接口封装了基本的 ReadAt 方法
type ReaderAt interface {
ReadAt(p []byte, off int64) (n int, err error)
}
ReadAt 从对象数据流的 off 处读出数据到 p 中
忽略数据的读写指针,从数据的起始位置偏移 off 处开始读取
如果对象的数据流只有部分可用,不足以填满 p
则 ReadAt 将等待所有数据可用之后,继续向 p 中写入
直到将 p 填满后再返回
在这点上 ReadAt 要比 Read 更严格
返回读取的字节数 n 和读取时遇到的错误
如果 n < len§,则需要返回一个 err 值来说明
为什么没有将 p 填满(比如 EOF)
如果 n = len§,而且对象的数据没有全部读完,则
err 将返回 nil
如果 n = len§,而且对象的数据刚好全部读完,则
err 将返回 EOF 或者 nil(不确定)
定义WriterAt接口,WriterAt 接口封装了基本的 WriteAt 方法
type WriterAt interface {
WriteAt(p []byte, off int64) (n int, err error)
}
WriteAt 将 p 中的数据写入到对象数据流的 off 处
忽略数据的读写指针,从数据的起始位置偏移 off 处开始写入
返回写入的字节数和写入时遇到的错误
如果 n < len§,则必须返回一个 err 值来说明
为什么没有将 p 完全写入
文件复制
在io包中主要是操作流的一些方法,今天主要学习一下copy。就是把一个文件复制到另一个目录下。
它的原理就是通过程序,从源文件读取文件中的数据,在写出到目标文件里。
io包下的Read()和Write()
我们可以通过io包下的Read()和Write()方法,边读边写,就能够实现文件的复制。这个方法是按块读取文件,块的大小也会影响到程序的性能。
package main
import (
"fmt"
"io"
"os"
)
func main() {
srcFile := "main/1.txt"
destFile := "main/2.txt"
total, err := copyFile1(srcFile, destFile)
fmt.Println(total, err)
}
/*
该函数的功能:实现文件的拷贝,返回值是拷贝的总数量(字节),错误
*/
func copyFile1(srcFile, destFile string) (int, error) {
file1, err := os.Open(srcFile)
if err != nil {
return 0, err
}
file2, err := os.OpenFile(destFile, os.O_WRONLY|os.O_CREATE, os.ModePerm)
if err != nil {
return 0, err
}
defer file1.Close()
defer file2.Close()
// 拷贝数据
bs := make([]byte, 1024, 1024)
n := -1 //读取的数据量
total := 0
for {
n, err = file1.Read(bs)
if err == io.EOF || n == 0 {
fmt.Println("拷贝完毕。。")
break
} else if err != nil {
fmt.Println("报错了。。。")
return total, err
}
total += n
file2.Write(bs[:n])
}
return total, nil
}
io包下的Copy()
我们也可以直接使用io包下的Copy()方法。
示例代码如下:
package main
import (
"fmt"
"io"
"os"
)
func main() {
srcFile := "main/1.txt"
destFile := "main/2.txt"
total, err := copyFile2(srcFile, destFile)
fmt.Println(total, err)
}
func copyFile2(srcFile, destFile string) (int64, error) {
file1, err := os.Open(srcFile)
if err != nil {
return 0, err
}
file2, err := os.OpenFile(destFile, os.O_WRONLY|os.O_CREATE, os.ModePerm)
if err != nil {
return 0, err
}
defer file1.Close()
defer file2.Close()
return io.Copy(file2, file1)
}
在io包中,不止提供了Copy()方法,还有另外2个公开的copy方法:CopyN(),CopyBuffer()。
Copy(dst,src) //为复制src 全部到 dst 中。
CopyN(dst,src,n) //为复制src 中 n 个字节到 dst。
CopyBuffer(dst,src,buf)//为指定一个buf缓存区,以这个大小完全复制。
无论是哪个copy方法最终都是由copyBuffer()这个私有方法实现的。
func copyBuffer(dst Writer, src Reader, buf []byte) (written int64, err error) {
// If the reader has a WriteTo method, use it to do the copy.
// Avoids an allocation and a copy.
if wt, ok := src.(WriterTo); ok {
return wt.WriteTo(dst)
}
// Similarly, if the writer has a ReadFrom method, use it to do the copy.
if rt, ok := dst.(ReaderFrom); ok {
return rt.ReadFrom(src)
}
if buf == nil {
size := 32 * 1024
if l, ok := src.(*LimitedReader); ok && int64(size) > l.N {
if l.N < 1 {
size = 1
} else {
size = int(l.N)
}
}
buf = make([]byte, size)
}
for {
nr, er := src.Read(buf)
if nr > 0 {
nw, ew := dst.Write(buf[0:nr])
if nw > 0 {
written += int64(nw)
}
if ew != nil {
err = ew
break
}
if nr != nw {
err = ErrShortWrite
break
}
}
if er != nil {
if er != EOF {
err = er
}
break
}
}
return written, err
}
从这部分代码可以看出,复制主要分为3种。
1.如果被复制的Reader(src)会尝试能否断言成writerTo,如果可以则直接调用下面的writerTo方法
2.如果 Writer(dst) 会尝试能否断言成ReadFrom ,如果可以则直接调用下面的readfrom方法
3.如果都木有实现,则调用底层read实现复制。
其中,有这么一段代码:
if buf == nil {
size := 32 * 1024
if l, ok := src.(*LimitedReader); ok && int64(size) > l.N {
if l.N < 1 {
size = 1
} else {
size = int(l.N)
}
}
buf = make([]byte, size)
}
这部分主要是实现了对Copy和CopyN的处理。通过上面的调用关系图,我们看出CopyN在调用后,会把Reader转成LimiteReader。
区别是如果Copy,直接建立一个缓存区默认大小为 32* 1024 的buf,如果是CopyN 会先判断 要复制的字节数,如果小于默认大小,会创建一个等于要复制字节数的buf。
ioutil包
第三种方法是使用ioutil包中的 ioutil.WriteFile()和ioutil.ReadFile(),但由于使用一次性读取文件,再一次性写入文件的方式,所以该方法不适用于大文件,容易内存溢出。
示例代码:
package main
import (
"fmt"
"io/ioutil"
)
func main() {
srcFile := "main/1.txt"
destFile := "main/2.txt"
total, err := copyFile3(srcFile, destFile)
fmt.Println(total, err)
}
func copyFile3(srcFile, destFile string) (int, error) {
input, err := ioutil.ReadFile(srcFile)
if err != nil {
fmt.Println(err)
return 0, err
}
err = ioutil.WriteFile(destFile, input, 0644)
if err != nil {
fmt.Println("操作失败:", destFile)
fmt.Println(err)
return 0, err
}
return len(input), nil
}
目前ReadFile和WriteFile已弃用。
总结
最后,我们来测试一下这3种拷贝需要花费时间,拷贝的文件都是一样的一个mp4文件(400M)。
第一种:io包下Read()和Write()直接读写:我们自己创建读取数据的切片的大小,直接影响性能。
拷贝完毕。。
<nil>
401386819
real 0m7.911s
user 0m2.900s
sys 0m7.661s
第二种:io包下Copy()方法:
<nil>
401386819
real 0m1.594s
user 0m0.533s
sys 0m1.136s
第三种:ioutil包
<nil>
401386819
real 0m1.515s
user 0m0.339s
sys 0m0.625s
这3种方式,在性能上,不管是还是io.Copy()还是ioutil包,性能都是还不错的。
断点续传
Seeker接口
Seeker是包装基本Seek方法的接口。
type Seeker interface {
Seek(offset int64, whence int) (int64, error)
}
seek(offset,whence),设置指针光标的位置,随机读写文件:
第一个参数:偏移量
第二个参数:如何设置
0:seekStart表示相对于文件开始,
1:seekCurrent表示相对于当前偏移量,
2:seek end表示相对于结束。
1.txt内容
ABCDEFababHelloWorldHelloWorld
示例代码:
package main
import (
"fmt"
"io"
"log"
"os"
)
func main() {
fileName := "main/1.txt"
file, err := os.OpenFile(fileName, os.O_RDWR, os.ModePerm)
if err != nil {
log.Fatal(err)
}
defer file.Close()
//读写
bs := []byte{0}
file.Read(bs)
fmt.Println(string(bs))
file.Seek(4, io.SeekStart)
file.Read(bs)
fmt.Println(string(bs))
file.Seek(2, 0) //SeekStart
file.Read(bs)
fmt.Println(string(bs))
file.Seek(3, io.SeekCurrent)
file.Read(bs)
fmt.Println(string(bs))
file.Seek(0, io.SeekEnd)
file.WriteString("ABC")
}
运行结果:
A
E
C
a
断点续传
首先思考几个问题
Q1:如果你要传的文件,比较大,那么是否有方法可以缩短耗时?
Q2:如果在文件传递过程中,程序因各种原因被迫中断了,那么下次再重启时,文件是否还需要重头开始?
Q3:传递文件的时候,支持暂停和恢复么?即使这两个操作分布在程序进程被杀前后。
通过断点续传可以实现,不同的语言有不同的实现方式。我们看看Go语言中,通过Seek()方法如何实现:
先说一下思路:想实现断点续传,主要就是记住上一次已经传递了多少数据,那我们可以创建一个临时文件,记录已经传递的数据量,当恢复传递的时候,先从临时文件中读取上次已经传递的数据量,然后通过Seek()方法,设置到该读和该写的位置,再继续传递数据。
示例代码:
package main
import (
"fmt"
"io"
"log"
"os"
"strconv"
"strings"
)
func main() {
srcFile := "main/1.txt"
destFile := srcFile[strings.LastIndex(srcFile, "/")+1:]
tempFile := destFile + "temp.txt"
file1, err := os.Open(srcFile)
file2, err := os.OpenFile(destFile, os.O_CREATE|os.O_WRONLY, os.ModePerm)
file3, err := os.OpenFile(tempFile, os.O_CREATE|os.O_RDWR, os.ModePerm)
defer file1.Close()
defer file2.Close()
//step1:先读取临时文件中的数据,再seek
file3.Seek(0, io.SeekStart)
bs := make([]byte, 100, 100)
n1, err := file3.Read(bs)
countStr := string(bs[:n1])
count, err := strconv.ParseInt(countStr, 10, 64)
//step2:设置读,写的位置:
file1.Seek(count, io.SeekStart)
file2.Seek(count, io.SeekStart)
data := make([]byte, 1024, 1024)
n2 := -1 //读取的数据量
n3 := -1 //写出的数据量
total := int(count) //读取的总量
//
//step3:复制文件
for {
n2, err = file1.Read(data)
if err == io.EOF || n2 == 0 {
fmt.Println("文件复制完毕。。")
file3.Close()
os.Remove(tempFile)
break
}
n3, err = file2.Write(data[:n2])
total += n3
//将复制的总量,存储到临时文件中
file3.Seek(0, io.SeekStart)
file3.WriteString(strconv.Itoa(total))
fmt.Printf("total:%d\n", total)
//假装断电
//if total > 8000{
// panic("假装断电了。。。")
//}
}
}
func HandleErr(err error) {
if err != nil {
log.Fatal(err)
}
}
bufio包
bufio包原理
bufio 是通过缓冲来提高效率。
io操作本身的效率并不低,低的是频繁的访问本地磁盘的文件。所以bufio就提供了缓冲区(分配一块内存),读和写都先在缓冲区中,最后再读写文件,来降低访问本地磁盘的次数,从而提高效率。
简单的说就是,把文件读取进缓冲(内存)之后再读取的时候就可以避免文件系统的io 从而提高速度。同理,在进行写操作时,先把文件写入缓冲(内存),然后由缓冲写入文件系统。看完以上解释有人可能会表示困惑了,直接把 内容->文件 和 内容->缓冲->文件相比, 缓冲区好像没有起到作用嘛。其实缓冲区的设计是为了存储多次的写入,最后一口气把缓冲区内容写入文件。
bufio 封装了io.Reader或io.Writer接口对象,并创建另一个也实现了该接口的对象。
io.Reader或io.Writer 接口实现read() 和 write() 方法,对于实现这个接口的对象都是可以使用这两个方法的。
Reader对象
bufio.Reader 是bufio中对io.Reader 的封装
// Reader implements buffering for an io.Reader object.
type Reader struct {
buf []byte
rd io.Reader // reader provided by the client
r, w int // buf read and write positions
err error
lastByte int // last byte read for UnreadByte; -1 means invalid
lastRuneSize int // size of last rune read for UnreadRune; -1 means invalid
}
bufio.Read(p []byte) 相当于读取大小len§的内容,思路如下:
- 当缓存区有内容的时,将缓存区内容全部填入p并清空缓存区
- 当缓存区没有内容的时候且len§>len(buf),即要读取的内容比缓存区还要大,直接去文件读取即可
- 当缓存区没有内容的时候且len§<len(buf),即要读取的内容比缓存区小,缓存区从文件读取内容充满缓存区,并将p填满(此时缓存区有剩余内容)
- 以后再次读取时缓存区有内容,将缓存区内容全部填入p并清空缓存区(此时和情况1一样)
示例代码:
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
fileName := "main/1.txt"
file, err := os.Open(fileName)
if err != nil {
fmt.Println(err)
return
}
defer func(file *os.File) {
err := file.Close()
if err != nil {
}
}(file)
//创建Reader对象
//b1 := bufio.NewReader(file)
//1.Read(),高效读取
//p := make([]byte, 1024)
//n1, err := b1.Read(p)
//fmt.Println(n1)
//fmt.Println(string(p[:n1]))
//2.ReadLine()
//data, flag, err := b1.ReadLine()
//fmt.Println(flag)
//fmt.Println(err)
//fmt.Println(data)
//fmt.Println(string(data))
//3.ReadString()
//s1, err := b1.ReadString('\n')
//fmt.Println(err)
//fmt.Println(s1)
//s1, err = b1.ReadString('\n')
//fmt.Println(err)
//fmt.Println(s1)
//s1, err = b1.ReadString('\n')
//fmt.Println(err)
//fmt.Println(s1)
//
//for {
// s1, err := b1.ReadString('\n')
// if err == io.EOF {
// fmt.Println("读取完毕。。")
// break
// }
// fmt.Println(s1)
//}
//4.ReadBytes()
//data, err := b1.ReadBytes('\n')
//fmt.Println(err)
//fmt.Println(string(data))
//Scanner,输入的内容如果有空格,只能接收到空格前面的数据
//s2 := ""
//fmt.Scanln(&s2)
//fmt.Println(s2)
//可以接收到空格后面的数据
b2 := bufio.NewReader(os.Stdin)
s2, _ := b2.ReadString('\n')
fmt.Println(s2)
}
Writer对象
bufio.Writer 是bufio中对io.Writer 的封装
// Writer implements buffering for an io.Writer object.
// If an error occurs writing to a Writer, no more data will be
// accepted and all subsequent writes, and Flush, will return the error.
// After all data has been written, the client should call the
// Flush method to guarantee all data has been forwarded to
// the underlying io.Writer.
type Writer struct {
err error
buf []byte
n int
wr io.Writer
}
bufio.Write(p []byte) 的思路如下
- 判断buf中可用容量是否可以放下 p
- 如果能放下,直接把p拼接到buf后面,即把内容放到缓冲区
- 如果缓冲区的可用容量不足以放下,且此时缓冲区是空的,直接把p写入文件即可
- 如果缓冲区的可用容量不足以放下,且此时缓冲区有内容,则用p把缓冲区填满,把缓冲区所有内容写入文件,并清空缓冲区
- 判断p的剩余内容大小能否放到缓冲区,如果能放下(此时和步骤1情况一样)则把内容放到缓冲区
- 如果p的剩余内容依旧大于缓冲区,(注意此时缓冲区是空的,情况和步骤3一样)则把p的剩余内容直接写入文件
示例代码:
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
fileName := "main/2.txt"
file, err := os.OpenFile(fileName, os.O_CREATE|os.O_WRONLY, os.ModePerm)
if err != nil {
fmt.Println(err)
return
}
defer func(file *os.File) {
err := file.Close()
if err != nil {
}
}(file)
w1 := bufio.NewWriter(file)
//n, err := w1.WriteString("helloworld")
//fmt.Println(err)
//fmt.Println(n)
//err = w1.Flush()
//if err != nil {
// return
//} //刷新缓冲区
for i := 1; i <= 1000; i++ {
_, err2 := w1.WriteString(fmt.Sprintf("%d:hello", i))
if err2 != nil {
return
}
}
err = w1.Flush()
if err != nil {
return
}
}
bufio包
bufio包实现了有缓冲的I/O。它包装一个io.Reader或io.Writer接口对象,创建另一个也实现了该接口,且同时还提供了缓冲和一些文本I/O的帮助函数的对象。
bufio.Reader
bufio.Reader 实现了如下接口:
io.Reader
io.WriterTo
io.ByteScanner
io.RuneScanner
// NewReaderSize 将 rd 封装成一个带缓存的 bufio.Reader 对象,
// 缓存大小由 size 指定(如果小于 16 则会被设置为 16)。
// 如果 rd 的基类型就是有足够缓存的 bufio.Reader 类型,则直接将
// rd 转换为基类型返回。
func NewReaderSize(rd io.Reader, size int) *Reader
// NewReader 相当于 NewReaderSize(rd, 4096)
func NewReader(rd io.Reader) *Reader
// Peek 返回缓存的一个切片,该切片引用缓存中前 n 个字节的数据,
// 该操作不会将数据读出,只是引用,引用的数据在下一次读取操作之
// 前是有效的。如果切片长度小于 n,则返回一个错误信息说明原因。
// 如果 n 大于缓存的总大小,则返回 ErrBufferFull。
func (b *Reader) Peek(n int) ([]byte, error)
// Read 从 b 中读出数据到 p 中,返回读出的字节数和遇到的错误。
// 如果缓存不为空,则只能读出缓存中的数据,不会从底层 io.Reader
// 中提取数据,如果缓存为空,则:
// 1、len(p) >= 缓存大小,则跳过缓存,直接从底层 io.Reader 中读
// 出到 p 中。
// 2、len(p) < 缓存大小,则先将数据从底层 io.Reader 中读取到缓存
// 中,再从缓存读取到 p 中。
func (b *Reader) Read(p []byte) (n int, err error)
// Buffered 返回缓存中未读取的数据的长度。
func (b *Reader) Buffered() int
// ReadBytes 功能同 ReadSlice,只不过返回的是缓存的拷贝。
func (b *Reader) ReadBytes(delim byte) (line []byte, err error)
// ReadString 功能同 ReadBytes,只不过返回的是字符串。
func (b *Reader) ReadString(delim byte) (line string, err error)
bufio.Writer
bufio.Writer 实现了如下接口:
io.Writer
io.ReaderFrom
io.ByteWriter
// NewWriterSize 将 wr 封装成一个带缓存的 bufio.Writer 对象,
// 缓存大小由 size 指定(如果小于 4096 则会被设置为 4096)。
// 如果 wr 的基类型就是有足够缓存的 bufio.Writer 类型,则直接将
// wr 转换为基类型返回。
func NewWriterSize(wr io.Writer, size int) *Writer
// NewWriter 相当于 NewWriterSize(wr, 4096)
func NewWriter(wr io.Writer) *Writer
// WriteString 功能同 Write,只不过写入的是字符串
func (b *Writer) WriteString(s string) (int, error)
// WriteRune 向 b 写入 r 的 UTF-8 编码,返回 r 的编码长度。
func (b *Writer) WriteRune(r rune) (size int, err error)
// Flush 将缓存中的数据提交到底层的 io.Writer 中
func (b *Writer) Flush() error
// Available 返回缓存中未使用的空间的长度
func (b *Writer) Available() int
// Buffered 返回缓存中未提交的数据的长度
func (b *Writer) Buffered() int
// Reset 将 b 的底层 Writer 重新指定为 w,同时丢弃缓存中的所有数据,复位
// 所有标记和错误信息。相当于创建了一个新的 bufio.Writer。
func (b *Writer) Reset(w io.Writer)
ioutil包
除了io包可以读写数据,Go语言中还提供了一个辅助的工具包就是ioutil,里面的方法虽然不多,但是都还蛮好用的。
import "io/ioutil"
该包的介绍只有一句话:Package ioutil implements some I/O utility functions。
ioutil包的方法
下面我们来看一下里面的方法:
// Discard 是一个 io.Writer 接口,调用它的 Write 方法将不做任何事情
// 并且始终成功返回。
var Discard io.Writer = devNull(0)
// ReadAll 读取 r 中的所有数据,返回读取的数据和遇到的错误。
// 如果读取成功,则 err 返回 nil,而不是 EOF,因为 ReadAll 定义为读取
// 所有数据,所以不会把 EOF 当做错误处理。
func ReadAll(r io.Reader) ([]byte, error)
// ReadFile 读取文件中的所有数据,返回读取的数据和遇到的错误。
// 如果读取成功,则 err 返回 nil,而不是 EOF
func ReadFile(filename string) ([]byte, error)
// WriteFile 向文件中写入数据,写入前会清空文件。
// 如果文件不存在,则会以指定的权限创建该文件。
// 返回遇到的错误。
func WriteFile(filename string, data []byte, perm os.FileMode) error
// ReadDir 读取指定目录中的所有目录和文件(不包括子目录)。
// 返回读取到的文件信息列表和遇到的错误,列表是经过排序的。
func ReadDir(dirname string) ([]os.FileInfo, error)
// NopCloser 将 r 包装为一个 ReadCloser 类型,但 Close 方法不做任何事情。
func NopCloser(r io.Reader) io.ReadCloser
// TempFile 在 dir 目录中创建一个以 prefix 为前缀的临时文件,并将其以读
// 写模式打开。返回创建的文件对象和遇到的错误。
// 如果 dir 为空,则在默认的临时目录中创建文件(参见 os.TempDir),多次
// 调用会创建不同的临时文件,调用者可以通过 f.Name() 获取文件的完整路径。
// 调用本函数所创建的临时文件,应该由调用者自己删除。
func TempFile(dir, prefix string) (f *os.File, err error)
// TempDir 功能同 TempFile,只不过创建的是目录,返回目录的完整路径。
func TempDir(dir, prefix string) (name string, err error)
示例代码
package main
import (
"fmt"
"io/ioutil"
"os"
)
func main() {
/*
ioutil包:
ReadFile()
WriteFile()
ReadDir()
..
*/
//1.读取文件中的所有的数据
//fileName := "main/1.txt"
//data, err := ioutil.ReadFile(fileName)
fmt.Println(err)
fmt.Println(data)
//fmt.Println(string(data))
//2.写出数据(覆盖写)
//fileName := "main/1.txt"
//s1 := "床前明月光,地上鞋三双"
//err := ioutil.WriteFile(fileName, []byte(s1), os.ModePerm)
//fmt.Println(err)
//3.ReadAll()
//s2 := "王二狗和李小花是两个好朋友,Ruby就是我,也是他们的朋友"
//r1 := strings.NewReader(s2)
//data, err := ioutil.ReadAll(r1)
//fmt.Println(err)
//fmt.Println(data)
//fmt.Println(string(data))
//4.ReadDir(),读取一个目录下的子内容:子文件和子目录,但是只能读取一层
//dirName := "main"
//fileInfos, err := ioutil.ReadDir(dirName)
//if err != nil {
// fmt.Println(err)
// return
//}
//fmt.Println(len(fileInfos))
//for i := 0; i < len(fileInfos); i++ {
// //fmt.Printf("%T\n", fileInfos[i])
// fmt.Printf("第 %d 个:名称:%s,是否是目录:%t\n", i, fileInfos[i].Name(), fileInfos[i].IsDir())
//}
//5.临时目录和临时文件
dir, err := ioutil.TempDir("./", "Test")
if err != nil {
fmt.Println(err)
return
}
defer os.Remove(dir)
fmt.Println(dir)
file, err := ioutil.TempFile(dir, "Test")
if err != nil {
fmt.Println(err)
return
}
defer os.Remove(file.Name())
fmt.Println(file.Name())
}
遍历文件夹
因为文件夹下还有子文件夹,而ioutil包的ReadDir()只能获取一层目录,所以我们需要自己去设计算法来实现,最容易实现的思路就是使用递归。
示例代码:
package main
import (
"fmt"
"io/ioutil"
)
func main() {
dirName := "C:\\Users\\19393\\Desktop\\操作系统"
readDir(dirName)
}
func readDir(dirName string) {
fileInfos, err := ioutil.ReadDir(dirName)
if err != nil {
return
}
for i := 0; i < len(fileInfos); i++ {
if fileInfos[i].IsDir() {
dirName = dirName + "\\" + fileInfos[i].Name()
readDir(dirName)
} else {
fmt.Printf("文件名:%s\n", fileInfos[i].Name())
}
}
}
该包目前已弃用
并发性Concurrency
多任务
什么叫“多任务”呢?简单地说,就是操作系统可以同时运行多个任务。打个比方,你一边在用浏览器上网,一边在听MP3,一边在用Word赶作业,这就是多任务,至少同时有3个任务正在运行。还有很多任务悄悄地在后台同时运行着,只是桌面上没有显示而已。
CPU的速度太快啦。。。
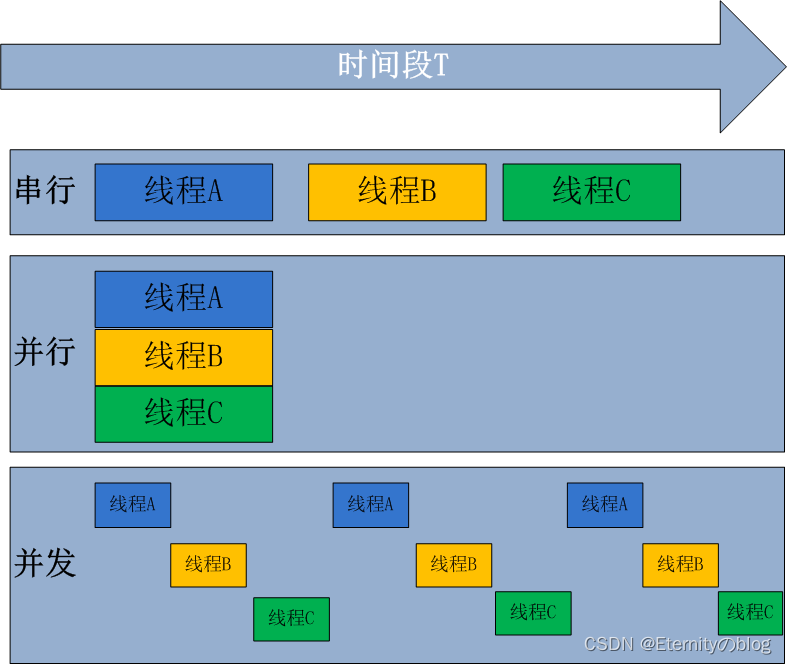
什么是并发
Go是并发语言,而不是并行语言。在讨论如何在Go中进行并发处理之前,我们首先必须了解什么是并发,以及它与并行性有什么不同。(Go is a concurrent language and not a parallel one. )
并发性Concurrency是同时处理许多事情的能力。
举个例子,假设一个人在晨跑。在晨跑时,他的鞋带松了。现在这个人停止跑步,系鞋带,然后又开始跑步。这是一个典型的并发性示例。这个人能够同时处理跑步和系鞋带,这是一个人能够同时处理很多事情。
什么是并行性parallelism,它与并发concurrency有什么不同?
并行就是同时做很多事情。这听起来可能与并发类似,但实际上是不同的。
让我们用同样的慢跑例子更好地理解它。在这种情况下,我们假设这个人正在慢跑,并且使用它的手机听音乐。在这种情况下,一个人一边慢跑一边听音乐,那就是他同时在做很多事情。这就是所谓的并行性(parallelism)。
并发性和并行性——一种技术上的观点。
假设我们正在编写一个web浏览器。web浏览器有各种组件。其中两个是web页面呈现区域和下载文件从internet下载的下载器。假设我们以这样的方式构建了浏览器的代码,这样每个组件都可以独立地执行。当这个浏览器运行在单个核处理器中时,处理器将在浏览器的两个组件之间进行上下文切换。它可能会下载一个文件一段时间,然后它可能会切换到呈现用户请求的网页的html。这就是所谓的并发性。并发进程从不同的时间点开始,它们的执行周期重叠。在这种情况下,下载和呈现从不同的时间点开始,它们的执行重叠。
假设同一浏览器运行在多核处理器上。在这种情况下,文件下载组件和HTML呈现组件可能同时在不同的内核中运行。这就是所谓的并行性。
并行性Parallelism不会总是导致更快的执行时间。这是因为并行运行的组件可能需要相互通信。例如,在我们的浏览器中,当文件下载完成时,应该将其传递给用户,比如使用弹出窗口。这种通信发生在负责下载的组件和负责呈现用户界面的组件之间。这种通信开销在并发concurrent 系统中很低。当组件在多个内核中并行concurrent 运行时,这种通信开销很高。因此,并行程序并不总是导致更快的执行时间!
进程、线程、协程
进程
进程是一个程序在一个数据集中的一次动态执行过程,可以简单理解为“正在执行的程序”,它是CPU资源分配和调度的独立单位。
进程一般由程序、数据集、进程控制块三部分组成。我们编写的程序用来描述进程要完成哪些功能以及如何完成;数据集则是程序在执行过程中所需要使用的资源;进程控制块用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志。 进程的局限是创建、撤销和切换的开销比较大。
线程
线程是在进程之后发展出来的概念。 线程也叫轻量级进程,它是一个基本的CPU执行单元,也是程序执行过程中的最小单元,由线程ID、程序计数器、寄存器集合和堆栈共同组成。一个进程可以包含多个线程。
线程的优点是减小了程序并发执行时的开销,提高了操作系统的并发性能,缺点是线程没有自己的系统资源,只拥有在运行时必不可少的资源,但同一进程的各线程可以共享进程所拥有的系统资源,如果把进程比作一个车间,那么线程就好比是车间里面的工人。不过对于某些独占性资源存在锁机制,处理不当可能会产生“死锁”。
协程
协程是一种用户态的轻量级线程,又称微线程,英文名Coroutine,协程的调度完全由用户控制。人们通常将协程和子程序(函数)比较着理解。
子程序调用总是一个入口,一次返回,一旦退出即完成了子程序的执行。
与传统的系统级线程和进程相比,协程的最大优势在于其"轻量级",可以轻松创建上百万个而不会导致系统资源衰竭,而线程和进程通常最多也不能超过1万的。这也是协程也叫轻量级线程的原因。
协程与多线程相比,其优势体现在:协程的执行效率极高。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
Go语言对于并发的实现是靠协程,Goroutine
Go语言的协程——Goroutine
进程(Process),线程(Thread),协程(Coroutine,也叫轻量级线程)
-
进程
进程是一个程序在一个数据集中的一次动态执行过程,可以简单理解为“正在执行的程序”,它是CPU资源分配和调度的独立单位。
进程一般由程序、数据集、进程控制块三部分组成。我们编写的程序用来描述进程要完成哪些功能以及如何完成;数据集则是程序在执行过程中所需要使用的资源;进程控制块用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志。 进程的局限是创建、撤销和切换的开销比较大。 -
线程
线程是在进程之后发展出来的概念。 线程也叫轻量级进程,它是一个基本的CPU执行单元,也是程序执行过程中的最小单元,由线程ID、程序计数器、寄存器集合和堆栈共同组成。一个进程可以包含多个线程。
线程的优点是减小了程序并发执行时的开销,提高了操作系统的并发性能,缺点是线程没有自己的系统资源,只拥有在运行时必不可少的资源,但同一进程的各线程可以共享进程所拥有的系统资源,如果把进程比作一个车间,那么线程就好比是车间里面的工人。不过对于某些独占性资源存在锁机制,处理不当可能会产生“死锁”。 -
协程
协程是一种用户态的轻量级线程,又称微线程,英文名Coroutine,协程的调度完全由用户控制。人们通常将协程和子程序(函数)比较着理解。 子程序调用总是一个入口,一次返回,一旦退出即完成了子程序的执行。
与传统的系统级线程和进程相比,协程的最大优势在于其"轻量级",可以轻松创建上百万个而不会导致系统资源衰竭,而线程和进程通常最多也不能超过1万的。这也是协程也叫轻量级线程的原因。
协程的特点在于是一个线程执行,与多线程相比,其优势体现在:协程的执行效率极高。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
Goroutine
什么是Goroutine
go中使用Goroutine来实现并发concurrently。
Goroutine是Go语言特有的名词。区别于进程Process,线程Thread,协程Coroutine,因为Go语言的创造者们觉得和他们是有所区别的,所以专门创造了Goroutine。
Goroutine是与其他函数或方法同时运行的函数或方法。Goroutines可以被认为是轻量级的线程。与线程相比,创建Goroutine的成本很小,它就是一段代码,一个函数入口。以及在堆上为其分配的一个堆栈(初始大小为4K,会随着程序的执行自动增长删除)。因此它非常廉价,Go应用程序可以并发运行数千个Goroutines。
Goroutines在线程上的优势。
- 与线程相比,Goroutines非常便宜。它们只是堆栈大小的几个kb,堆栈可以根据应用程序的需要增长和收缩,而在线程的情况下,堆栈大小必须指定并且是固定的
- Goroutines被多路复用到较少的OS线程。在一个程序中可能只有一个线程与数千个Goroutines。如果线程中的任何Goroutine都表示等待用户输入,则会创建另一个OS线程,剩下的Goroutines被转移到新的OS线程。所有这些都由运行时进行处理,我们作为程序员从这些复杂的细节中抽象出来,并得到了一个与并发工作相关的干净的API。
- 当使用Goroutines访问共享内存时,通过设计的通道可以防止竞态条件发生。通道可以被认为是Goroutines通信的管道。
主goroutine
封装main函数的goroutine称为主goroutine。
主goroutine所做的事情并不是执行main函数那么简单。它首先要做的是:设定每一个goroutine所能申请的栈空间的最大尺寸。在32位的计算机系统中此最大尺寸为250MB,而在64位的计算机系统中此尺寸为1GB。如果有某个goroutine的栈空间尺寸大于这个限制,那么运行时系统就会引发一个栈溢出(stack overflow)的运行时恐慌。随后,这个go程序的运行也会终止。
此后,主goroutine会进行一系列的初始化工作,涉及的工作内容大致如下:
-
创建一个特殊的defer语句,用于在主goroutine退出时做必要的善后处理。因为主goroutine也可能非正常的结束
-
启动专用于在后台清扫内存垃圾的goroutine,并设置GC可用的标识
-
执行mian包中的init函数
-
执行main函数
执行完main函数后,它还会检查主goroutine是否引发了运行时恐慌,并进行必要的处理。最后主goroutine会结束自己以及当前进程的运行。
如何使用Goroutines
在函数或方法调用前面加上关键字go,您将会同时运行一个新的Goroutine。
实例代码:
package main
import (
"fmt"
)
func hello() {
fmt.Println("Hello world goroutine")
}
func main() {
go hello()
fmt.Println("main function")
}
运行结果:可能会值输出main function。
由于主线程和新的goroutine是并发执行的,它们在时间上是相互独立的,因此主线程在打印"main function"之后,很可能立即结束,而新的goroutine可能没有足够的时间来执行fmt.Println("Hello world goroutine")语句,从而导致该语句没有被执行和打印。
我们开始的Goroutine怎么样了?我们需要了解Goroutine的规则
- 当新的Goroutine开始时,Goroutine调用立即返回。与函数不同,go不等待Goroutine执行结束。当Goroutine调用,并且Goroutine的任何返回值被忽略之后,go立即执行到下一行代码。
- main的Goroutine应该为其他的Goroutines执行。如果main的Goroutine终止了,程序将被终止,而其他Goroutine将不会运行。
修改以上代码:
package main
import (
"fmt"
"time"
)
func hello() {
fmt.Println("Hello world goroutine")
}
func main() {
go hello()
time.Sleep(1 * time.Second)
fmt.Println("main function")
}
在上面的程序中,我们已经调用了时间包的Sleep方法,它会在执行过程中睡觉。在这种情况下,main的goroutine被用来睡觉1秒。现在调用go hello()有足够的时间在main Goroutine终止之前执行。这个程序首先打印Hello world goroutine,等待1秒,然后打印main function。
启动多个Goroutines
示例代码:
package main
import (
"fmt"
"time"
)
func numbers() {
for i := 1; i <= 5; i++ {
time.Sleep(250 * time.Millisecond)
fmt.Printf("%d ", i)
}
}
func alphabets() {
for i := 'a'; i <= 'e'; i++ {
time.Sleep(400 * time.Millisecond)
fmt.Printf("%c ", i)
}
}
func main() {
go numbers()
go alphabets()
time.Sleep(3000 * time.Millisecond)
fmt.Println("main terminated")
}
运行结果:
1 a 2 3 b 4 c 5 d e main terminated
时间轴分析:

Go语言的并发模型
Go 语言相比Java等一个很大的优势就是可以方便地编写并发程序。Go 语言内置了 goroutine 机制,使用goroutine可以快速地开发并发程序, 更好的利用多核处理器资源。接下来我们来了解一下Go语言的并发原理。
线程模型
在现代操作系统中,线程是处理器调度和分配的基本单位,进程则作为资源拥有的基本单位。每个进程是由私有的虚拟地址空间、代码、数据和其它各种系统资源组成。线程是进程内部的一个执行单元。 每一个进程至少有一个主执行线程,它无需由用户去主动创建,是由系统自动创建的。 用户根据需要在应用程序中创建其它线程,多个线程并发地运行于同一个进程中。
我们先从线程讲起,无论语言层面何种并发模型,到了操作系统层面,一定是以线程的形态存在的。而操作系统根据资源访问权限的不同,体系架构可分为用户空间和内核空间;内核空间主要操作访问CPU资源、I/O资源、内存资源等硬件资源,为上层应用程序提供最基本的基础资源,用户空间呢就是上层应用程序的固定活动空间,用户空间不可以直接访问资源,必须通过“系统调用”、“库函数”或“Shell脚本”来调用内核空间提供的资源。
我们现在的计算机语言,可以狭义的认为是一种“软件”,它们中所谓的“线程”,往往是用户态的线程,和操作系统本身内核态的线程(简称KSE),还是有区别的。
Go并发编程模型在底层是由操作系统所提供的线程库支撑的,因此还是得从线程实现模型说起。
线程可以视为进程中的控制流。一个进程至少会包含一个线程,因为其中至少会有一个控制流持续运行。因而,一个进程的第一个线程会随着这个进程的启动而创建,这个线程称为该进程的主线程。当然,一个进程也可以包含多个线程。这些线程都是由当前进程中已存在的线程创建出来的,创建的方法就是调用系统调用,更确切地说是调用
pthread create函数。拥有多个线程的进程可以并发执行多个任务,并且即使某个或某些任务被阻塞,也不会影响其他任务正常执行,这可以大大改善程序的响应时间和吞吐量。另一方面,线程不可能独立于进程存在。它的生命周期不可能逾越其所属进程的生命周期。
线程的实现模型主要有3个,分别是:用户级线程模型、内核级线程模型和两级线程模型。它们之间最大的差异就在于线程与内核调度实体( Kernel Scheduling Entity,简称KSE)之间的对应关系上。顾名思义,内核调度实体就是可以被内核的调度器调度的对象。在很多文献和书中,它也称为内核级线程,是操作系统内核的最小调度单元。
内核级线程模型
用户线程与KSE是1对1关系(1:1)。大部分编程语言的线程库(如linux的pthread,Java的java.lang.Thread,C++11的std::thread等等)都是对操作系统的线程(内核级线程)的一层封装,创建出来的每个线程与一个不同的KSE静态关联,因此其调度完全由OS调度器来做。这种方式实现简单,直接借助OS提供的线程能力,并且不同用户线程之间一般也不会相互影响。但其创建,销毁以及多个线程之间的上下文切换等操作都是直接由OS层面亲自来做,在需要使用大量线程的场景下对OS的性能影响会很大。每个线程由内核调度器独立的调度,所以如果一个线程阻塞则不影响其他的线程。
优点:在多核处理器的硬件的支持下,内核空间线程模型支持了真正的并行,当一个线程被阻塞后,允许另一个线程继续执行,所以并发能力较强。
缺点:每创建一个用户级线程都需要创建一个内核级线程与其对应,这样创建线程的开销比较大,会影响到应用程序的性能。
用户级线程模型
用户线程与KSE是多对1关系(M:1),这种线程的创建,销毁以及多个线程之间的协调等操作都是由用户自己实现的线程库来负责,对OS内核透明,一个进程中所有创建的线程都与同一个KSE在运行时动态关联。现在有许多语言实现的 协程 基本上都属于这种方式。这种实现方式相比内核级线程可以做的很轻量级,对系统资源的消耗会小很多,因此可以创建的数量与上下文切换所花费的代价也会小得多。但该模型有个致命的缺点,如果我们在某个用户线程上调用阻塞式系统调用(如用阻塞方式read网络IO),那么一旦KSE因阻塞被内核调度出CPU的话,剩下的所有对应的用户线程全都会变为阻塞状态(整个进程挂起)。
所以这些语言的协程库会把自己一些阻塞的操作重新封装为完全的非阻塞形式,然后在以前要阻塞的点上,主动让出自己,并通过某种方式通知或唤醒其他待执行的用户线程在该KSE上运行,从而避免了内核调度器由于KSE阻塞而做上下文切换,这样整个进程也不会被阻塞了。
优点: 这种模型的好处是线程上下文切换都发生在用户空间,避免的模态切换(mode switch),从而对于性能有积极的影响。
缺点:所有的线程基于一个内核调度实体即内核线程,这意味着只有一个处理器可以被利用,在多处理器环境下这是不能够被接受的,本质上,用户线程只解决了并发问题,但是没有解决并行问题。如果线程因为 I/O 操作陷入了内核态,内核态线程阻塞等待 I/O 数据,则所有的线程都将会被阻塞,用户空间也可以使用非阻塞而 I/O,但是不能避免性能及复杂度问题。
两级线程模型
用户线程与KSE是多对多关系(M:N),这种实现综合了前两种模型的优点,为一个进程中创建多个KSE,并且线程可以与不同的KSE在运行时进行动态关联,当某个KSE由于其上工作的线程的阻塞操作被内核调度出CPU时,当前与其关联的其余用户线程可以重新与其他KSE建立关联关系。当然这种动态关联机制的实现很复杂,也需要用户自己去实现,这算是它的一个缺点吧。Go语言中的并发就是使用的这种实现方式,Go为了实现该模型自己实现了一个运行时调度器来负责Go中的"线程"与KSE的动态关联。此模型有时也被称为 混合型线程模型,即用户调度器实现用户线程到KSE的“调度”,内核调度器实现KSE到CPU上的调度。
Go并发调度: G-P-M模型
在操作系统提供的内核线程之上,Go搭建了一个特有的两级线程模型。goroutine机制实现了M : N的线程模型,goroutine机制是协程(coroutine)的一种实现,golang内置的调度器,可以让多核CPU中每个CPU执行一个协程。
调度器是如何工作的
有了上面的认识,我们可以开始真正的介绍Go的并发机制了,先用一段代码展示一下在Go语言中新建一个“线程”(Go语言中称为Goroutine)的样子:
// 用go关键字加上一个函数(这里用了匿名函数)
// 调用就做到了在一个新的“线程”并发执行任务
go func() {
// do something in one new goroutine
}()
理解goroutine机制的原理,关键是理解Go语言scheduler的实现。
Go语言中支撑整个scheduler实现的主要有4个重要结构,分别是M、G、P、Sched, 前三个定义在runtime.h中,Sched定义在proc.c中。
- Sched结构就是调度器,它维护有存储M和G的队列以及调度器的一些状态信息等。
- M结构是Machine,系统线程,它由操作系统管理的,goroutine就是跑在M之上的;M是一个很大的结构,里面维护小对象内存cache(mcache)、当前执行的goroutine、随机数发生器等等非常多的信息。
- P结构是Processor,处理器,它的主要用途就是用来执行goroutine的,它维护了一个goroutine队列,即runqueue。Processor是让我们从N:1调度到M:N调度的重要部分。
- G是goroutine实现的核心结构,它包含了栈,指令指针,以及其他对调度goroutine很重要的信息,例如其阻塞的channel。
Processor的数量是在启动时被设置为环境变量GOMAXPROCS的值,或者通过运行时调用函数GOMAXPROCS()进行设置。Processor数量固定意味着任意时刻只有GOMAXPROCS个线程在运行go代码。
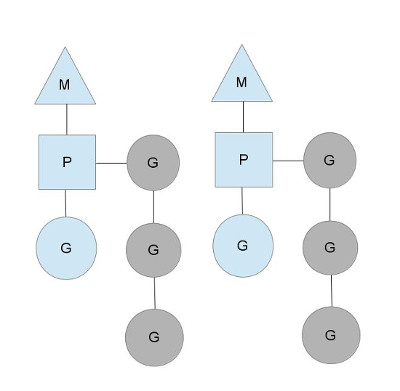
我们分别用三角形,矩形和圆形表示Machine Processor和Goroutine。
在单核处理器的场景下,所有goroutine运行在同一个M系统线程中,每一个M系统线程维护一个Processor,任何时刻,一个Processor中只有一个goroutine,其他goroutine在runqueue中等待。一个goroutine运行完自己的时间片后,让出上下文,回到runqueue中。 多核处理器的场景下,为了运行goroutines,每个M系统线程会持有一个Processor。
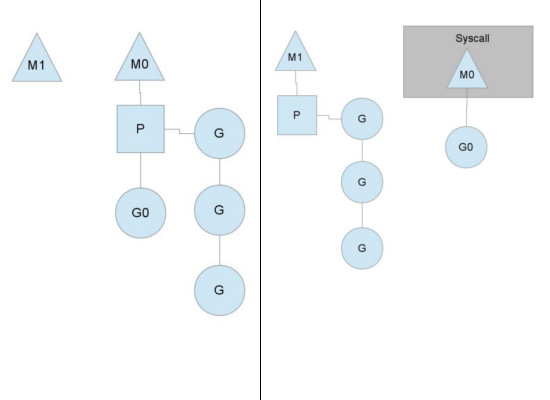
在正常情况下,scheduler会按照上面的流程进行调度,但是线程会发生阻塞等情况,看一下goroutine对线程阻塞等的处理。
线程阻塞
当正在运行的goroutine阻塞的时候,例如进行系统调用,会再创建一个系统线程(M1),当前的M线程放弃了它的Processor,P转到新的线程中去运行。
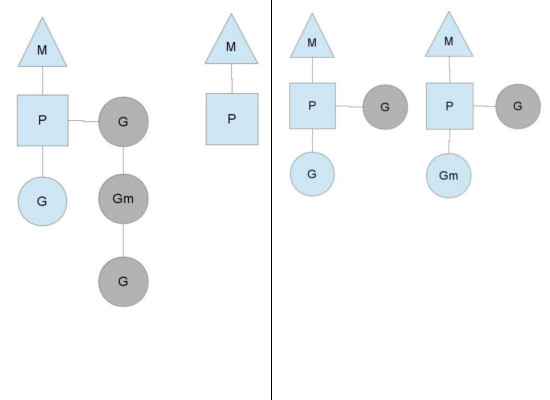
runqueue执行完成
当其中一个Processor的runqueue为空,没有goroutine可以调度。它会从另外一个上下文偷取一半的goroutine。
其图中的G,P和M都是Go语言运行时系统(其中包括内存分配器,并发调度器,垃圾收集器等组件,可以想象为Java中的JVM)抽象出来概念和数据结构对象:
G:Goroutine的简称,上面用go关键字加函数调用的代码就是创建了一个G对象,是对一个要并发执行的任务的封装,也可以称作用户态线程。属于用户级资源,对OS透明,具备轻量级,可以大量创建,上下文切换成本低等特点。
M:Machine的简称,在linux平台上是用clone系统调用创建的,其与用linux pthread库创建出来的线程本质上是一样的,都是利用系统调用创建出来的OS线程实体。M的作用就是执行G中包装的并发任务。Go运行时系统中的调度器的主要职责就是将G公平合理的安排到多个M上去执行。其属于OS资源,可创建的数量上也受限了OS,通常情况下G的数量都多于活跃的M的。
P:Processor的简称,逻辑处理器,主要作用是管理G对象(每个P都有一个G队列),并为G在M上的运行提供本地化资源。
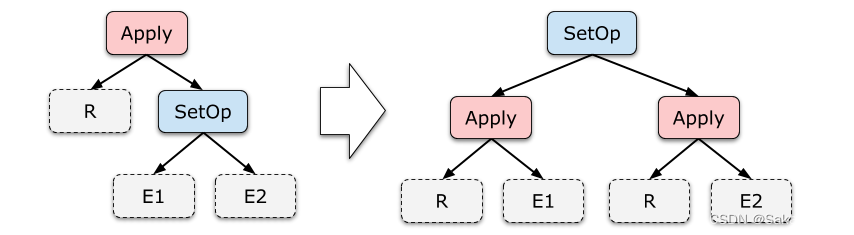
从两级线程模型来看,似乎并不需要P的参与,有G和M就可以了,那为什么要加入P这个东东呢?
其实Go语言运行时系统早期(Go1.0)的实现中并没有P的概念,Go中的调度器直接将G分配到合适的M上运行。但这样带来了很多问题,例如,不同的G在不同的M上并发运行时可能都需向系统申请资源(如堆内存),由于资源是全局的,将会由于资源竞争造成很多系统性能损耗,为了解决类似的问题,后面的Go(Go1.1)运行时系统加入了P,让P去管理G对象,M要想运行G必须先与一个P绑定,然后才能运行该P管理的G。这样带来的好处是,我们可以在P对象中预先申请一些系统资源(本地资源),G需要的时候先向自己的本地P申请(无需锁保护),如果不够用或没有再向全局申请,而且从全局拿的时候会多拿一部分,以供后面高效的使用。就像现在我们去政府办事情一样,先去本地政府看能搞定不,如果搞不定再去中央,从而提供办事效率。
而且由于P解耦了G和M对象,这样即使M由于被其上正在运行的G阻塞住,其余与该M关联的G也可以随着P一起迁移到别的活跃的M上继续运行,从而让G总能及时找到M并运行自己,从而提高系统的并发能力。
Go运行时系统通过构造G-P-M对象模型实现了一套用户态的并发调度系统,可以自己管理和调度自己的并发任务,所以可以说Go语言原生支持并发。自己实现的调度器负责将并发任务分配到不同的内核线程上运行,然后内核调度器接管内核线程在CPU上的执行与调度。
最后
Go运行时完整的调度系统是很复杂,很难用一篇文章描述的清楚,这里只能从宏观上介绍一下,让大家有个整体的认识。
// Goroutine1
func task1() {
go task2()
go task3()
}
假如我们有一个G(Goroutine1)已经通过P被安排到了一个M上正在执行,在Goroutine1执行的过程中我们又创建两个G,这两个G会被马上放入与Goroutine1相同的P的本地G任务队列中,排队等待与该P绑定的M的执行,这是最基本的结构,很好理解。 关键问题是:
a.如何在一个多核心系统上尽量合理分配G到多个M上运行,充分利用多核,提高并发能力呢?
如果我们在一个Goroutine中通过go关键字创建了大量G,这些G虽然暂时会被放在同一个队列, 但如果这时还有空闲P(系统内P的数量默认等于系统cpu核心数),Go运行时系统始终能保证至少有一个(通常也只有一个)活跃的M与空闲P绑定去各种G队列去寻找可运行的G任务,该种M称为自旋的M。一般寻找顺序为:自己绑定的P的队列,全局队列,然后其他P队列。如果自己P队列找到就拿出来开始运行,否则去全局队列看看,由于全局队列需要锁保护,如果里面有很多任务,会转移一批到本地P队列中,避免每次都去竞争锁。如果全局队列还是没有,就要开始玩狠的了,直接从其他P队列偷任务了(偷一半任务回来)。这样就保证了在还有可运行的G任务的情况下,总有与CPU核心数相等的M+P组合 在执行G任务或在执行G的路上(寻找G任务)。
b. 如果某个M在执行G的过程中被G中的系统调用阻塞了,怎么办?
在这种情况下,这个M将会被内核调度器调度出CPU并处于阻塞状态,与该M关联的其他G就没有办法继续执行了,但Go运行时系统的一个监控线程(sysmon线程)能探测到这样的M,并把与该M绑定的P剥离,寻找其他空闲或新建M接管该P,然后继续运行其中的G,大致过程如下图所示。然后等到该M从阻塞状态恢复,需要重新找一个空闲P来继续执行原来的G,如果这时系统正好没有空闲的P,就把原来的G放到全局队列当中,等待其他M+P组合发掘并执行。
c. 如果某一个G在M运行时间过长,有没有办法做抢占式调度,让该M上的其他G获得一定的运行时间,以保证调度系统的公平性?
我们知道linux的内核调度器主要是基于时间片和优先级做调度的。对于相同优先级的线程,内核调度器会尽量保证每个线程都能获得一定的执行时间。为了防止有些线程"饿死"的情况,内核调度器会发起抢占式调度将长期运行的线程中断并让出CPU资源,让其他线程获得执行机会。当然在Go的运行时调度器中也有类似的抢占机制,但并不能保证抢占能成功,因为Go运行时系统并没有内核调度器的中断能力,它只能通过向运行时间过长的G中设置抢占flag的方法温柔的让运行的G自己主动让出M的执行权。
说到这里就不得不提一下Goroutine在运行过程中可以动态扩展自己线程栈的能力,可以从初始的2KB大小扩展到最大1G(64bit系统上),因此在每次调用函数之前需要先计算该函数调用需要的栈空间大小,然后按需扩展(超过最大值将导致运行时异常)。Go抢占式调度的机制就是利用在判断要不要扩栈的时候顺便查看以下自己的抢占flag,决定是否继续执行,还是让出自己。
运行时系统的监控线程会计时并设置抢占flag到运行时间过长的G,然后G在有函数调用的时候会检查该抢占flag,如果已设置就将自己放入全局队列,这样该M上关联的其他G就有机会执行了。但如果正在执行的G是个很耗时的操作且没有任何函数调用(如只是for循环中的计算操作),即使抢占flag已经被设置,该G还是将一直霸占着当前M直到执行完自己的任务。
示例
package main
import (
"fmt"
"time"
)
func main() {
/*
一个goroutine打印数字,另外一个goroutine打印字母,观察运行结果。。
并发的程序的运行结果,每次都不一定相同。
不同计算机设备执行,效果也不相同。
go语言的并发:go关键字
系统自动创建并启动主goroutine,执行对应的main()
用于自己创建并启动子goroutine,执行对应的函数
go 函数()//go关键创建并启动goroutine,然后执行对应的函数(),该函数执行结束,子goroutine也随之结束。
子goroutine中执行的函数,往往没有返回值。
如果有也会被舍弃。
*/
//1.先创建并启动子goroutine,执行printNum()
go printNum()
//2.main中打印字母
for i := 1; i <= 10; i++ {
fmt.Printf("\t主goroutine中打印字母:A %d\n", i)
}
time.Sleep(1 * time.Second)
fmt.Println("main...over...")
}
func printNum() {
for i := 1; i <= 10; i++ {
fmt.Printf("子goroutine中打印数字:%d\n", i)
}
}
运行结果:
主goroutine中打印字母:A 1
子goroutine中打印数字:1
子goroutine中打印数字:2
子goroutine中打印数字:3
子goroutine中打印数字:4
子goroutine中打印数字:5
子goroutine中打印数字:6
子goroutine中打印数字:7
主goroutine中打印字母:A 2
主goroutine中打印字母:A 3
主goroutine中打印字母:A 4
主goroutine中打印字母:A 5
主goroutine中打印字母:A 6
主goroutine中打印字母:A 7
主goroutine中打印字母:A 8
子goroutine中打印数字:8
子goroutine中打印数字:9
主goroutine中打印字母:A 9
子goroutine中打印数字:10
主goroutine中打印字母:A 10
main...over...
runtime包
尽管 Go 编译器产生的是本地可执行代码,这些代码仍旧运行在 Go 的 runtime(这部分的代码可以在 runtime 包中找到)当中。这个 runtime 类似 Java 和 .NET 语言所用到的虚拟机,它负责管理包括内存分配、垃圾回收、栈处理、goroutine、channel、切片(slice)、map 和反射(reflection)等等。
常用函数
runtime 调度器是个非常有用的东西,关于 runtime 包几个方法:
-
NumCPU:返回当前系统的
CPU核数量 -
GOMAXPROCS:设置最大的可同时使用的
CPU核数通过runtime.GOMAXPROCS函数,应用程序何以在运行期间设置运行时系统中得P最大数量。但这会引起“Stop the World”。所以,应在应用程序最早的调用。并且最好是在运行Go程序之前设置好操作程序的环境变量GOMAXPROCS,而不是在程序中调用runtime.GOMAXPROCS函数。
无论我们传递给函数的整数值是什么值,运行时系统的P最大值总会在1~256之间。
go1.8后,默认让程序运行在多个核上,可以不用设置了
go1.8前,还是要设置一下,可以更高效的利益cpu
-
Gosched:让当前线程让出
cpu以让其它线程运行,它不会挂起当前线程,因此当前线程未来会继续执行这个函数的作用是让当前
goroutine让出CPU,当一个goroutine发生阻塞,Go会自动地把与该goroutine处于同一系统线程的其他goroutine转移到另一个系统线程上去,以使这些goroutine不阻塞。 -
Goexit:退出当前
goroutine(但是defer语句会照常执行) -
NumGoroutine:返回正在执行和排队的任务总数
runtime.NumGoroutine函数在被调用后,会返回系统中的处于特定状态的Goroutine的数量。这里的特指是指Grunnable\Gruning\Gsyscall\Gwaition。处于这些状态的Groutine即被看做是活跃的或者说正在被调度。
注意:垃圾回收所在Groutine的状态也处于这个范围内的话,也会被纳入该计数器。
-
GOOS:目标操作系统
-
runtime.GC:会让运行时系统进行一次强制性的垃圾收集
- 强制的垃圾回收:不管怎样,都要进行的垃圾回收。
- 非强制的垃圾回收:只会在一定条件下进行的垃圾回收(即运行时,系统自上次垃圾回收之后新申请的堆内存的单元(也成为单元增量)达到指定的数值)。
-
GOROOT :获取goroot目录
-
GOOS : 查看目标操作系统
很多时候,我们会根据平台的不同实现不同的操作,就而已用GOOS了:
示例代码
- 获取goroot和os:
//获取goroot目录:
fmt.Println("GOROOT-->",runtime.GOROOT())
//获取操作系统
fmt.Println("os/platform-->",runtime.GOOS)
GOROOT--> C:\Users\19393\sdk\go1.20.4
os/platform--> windows
- 获取CPU数量,和设置CPU数量:
func init(){
//1.获取逻辑cpu的数量
fmt.Println("逻辑CPU的核数:",runtime.NumCPU()) //16
//2.设置go程序执行的最大的:[1,256]
n := runtime.GOMAXPROCS(runtime.NumCPU())
fmt.Println(n) //16
}
- Gosched():
func main() {
go func() {
for i := 0; i < 5; i++ {
fmt.Println("goroutine")
}
}()
for i := 0; i < 4; i++ {
//让出时间片,先让别的协议执行,它执行完,再回来执行此协程
runtime.Gosched()
fmt.Println("main")
}
}
goroutine
goroutine
goroutine
goroutine
goroutine
main
main
main
main
- Goexit的使用(终止协程)
package main
import (
"fmt"
"runtime"
"time"
)
func main() {
//创建新建的协程
go func() {
fmt.Println("goroutine开始")
//调用了别的函数
fun()
fmt.Println("goroutine结束")
}() //别忘了()
//睡一会儿,不让主协程结束
time.Sleep(3 * time.Second)
}
func fun() {
defer fmt.Println("defer")
//return //终止此函数
runtime.Goexit() //终止所在的协程
fmt.Println("fun函数")
}
goroutine开始
defer
临界资源
临界资源: 指并发环境中多个进程/线程/协程共享的资源。
但是在并发编程中对临界资源的处理不当, 往往会导致数据不一致的问题。
示例代码:
package main
import (
"fmt"
"time"
)
func main() {
a := 1
go func() {
a = 2
fmt.Println("子goroutine",a)
}()
a = 3
time.Sleep(1)
fmt.Println("main goroutine",a)
}
子goroutine 2
main goroutine 2
能够发现一处被多个goroutine共享的数据a。
临界资源安全问题
并发本身并不复杂,但是因为有了资源竞争的问题,就使得我们开发出好的并发程序变得复杂起来,因为会引起很多莫名其妙的问题。
如果多个goroutine在访问同一个数据资源的时候,其中一个线程修改了数据,那么这个数值就被修改了,对于其他的goroutine来讲,这个数值可能是不对的。
举个例子,我们通过并发来实现火车站售票这个程序。一共有10张票,4个售票口同时出售。
我们先来看一下示例代码:
package main
import (
"fmt"
"math/rand"
"time"
)
// 全局变量
var ticket = 10 //
func main() {
/*
4个goroutine,模拟4个售票口,4个子程序操作同一个共享数据。
*/
go saleTickets("售票口1") // g1,10
go saleTickets("售票口2") // g2,10
go saleTickets("售票口3") //g3,10
go saleTickets("售票口4") //g4,10
time.Sleep(5 * time.Second)
}
func saleTickets(name string) {
rand.Seed(time.Now().UnixNano())
for { //ticket=1
if ticket > 0 { //g1,g3,g2,g4
//睡眠
time.Sleep(time.Duration(rand.Intn(1000)) * time.Millisecond)
// g1 ,g3, g2,g4
fmt.Println(name, "售出:", ticket)
ticket--
} else {
fmt.Println(name, "售罄,没有票了。。")
break
}
}
}
运行结果:
售票口4 售出: 10
售票口1 售出: 10
售票口3 售出: 10
售票口2 售出: 10
售票口1 售出: 6
售票口1 售出: 5
售票口2 售出: 4
售票口4 售出: 3
售票口4 售出: 2
售票口1 售出: 1
售票口1 售罄,没有票了。。
售票口3 售出: 0
售票口3 售罄,没有票了。。
售票口4 售出: -1
售票口4 售罄,没有票了。。
售票口2 售出: -2
售票口2 售罄,没有票了。。
我们为了更好的观察临界资源问题,每个goroutine先睡眠一个随机数,然后再售票,我们发现程序的运行结果,还可以卖出编号为负数的票。
分析:
我们的卖票逻辑是先判断票数的编号是否为负数,如果大于0,然后我们就进行卖票,只不过在卖票钱先睡眠,然后再卖,假如说此时已经卖票到只剩最后1张了,某一个goroutine持有了CPU的时间片,那么它再片段是否有票的时候,条件是成立的,所以它可以卖票编号为1的最后一张票。但是因为它在卖之前,先睡眠了,那么其他的goroutine就会持有CPU的时间片,而此时这张票还没有被卖出,那么第二个goroutine再判断是否有票的时候,条件也是成立的,那么它可以卖出这张票,然而它也进入了睡眠。其他的第三个第四个goroutine都是这样的逻辑,当某个goroutine醒来的时候,不会再判断是否有票,而是直接售出,这样就卖出最后一张票了,然而其他的goroutine醒来的时候,就会陆续卖出了第0张,-1张,-2张。
这就是临界资源的不安全问题。某一个goroutine在访问某个数据资源的时候,按照数值,已经判断好了条件,然后又被其他的goroutine抢占了资源,并修改了数值,等这个goroutine再继续访问这个数据的时候,数值已经不对了。
临界资源安全问题的解决
要想解决临界资源安全的问题,很多编程语言的解决方案都是同步。通过上锁的方式,某一时间段,只能允许一个goroutine来访问这个共享数据,当前goroutine访问完毕,解锁后,其他的goroutine才能来访问。
我们可以借助于sync包下的锁操作。
示例代码:
package main
import (
"fmt"
"math/rand"
"time"
"sync"
)
//全局变量
var ticket = 10 // 10张票
var wg sync.WaitGroup
var matex sync.Mutex // 创建锁头
func main() {
/*
4个goroutine,模拟4个售票口,4个子程序操作同一个共享数据。
*/
wg.Add(4)
go saleTickets("售票口1") // g1,100
go saleTickets("售票口2") // g2,100
go saleTickets("售票口3") //g3,100
go saleTickets("售票口4") //g4,100
wg.Wait() // main要等待。。。
//time.Sleep(5*time.Second)
}
func saleTickets(name string) {
rand.Seed(time.Now().UnixNano())
defer wg.Done()
//for i:=1;i<=100;i++{
// fmt.Println(name,"售出:",i)
//}
for { //ticket=1
matex.Lock()
if ticket > 0 { //g1,g3,g2,g4
//睡眠
time.Sleep(time.Duration(rand.Intn(1000)) * time.Millisecond)
// g1 ,g3, g2,g4
fmt.Println(name, "售出:", ticket) // 1 , 0, -1 , -2
ticket-- //0 , -1 ,-2 , -3
} else {
matex.Unlock() //解锁
fmt.Println(name, "售罄,没有票了。。")
break
}
matex.Unlock() //解锁
}
}
运行结果:
售票口1 售出: 10
售票口1 售出: 9
售票口4 售出: 8
售票口3 售出: 7
售票口2 售出: 6
售票口1 售出: 5
售票口4 售出: 4
售票口3 售出: 3
售票口2 售出: 2
售票口1 售出: 1
售票口4 售罄,没有票了。。
售票口1 售罄,没有票了。。
售票口3 售罄,没有票了。。
售票口2 售罄,没有票了。。
最后
在Go的并发编程中有一句很经典的话:不要以共享内存的方式去通信,而要以通信的方式去共享内存。
在Go语言中并不鼓励用锁保护共享状态的方式在不同的Goroutine中分享信息(以共享内存的方式去通信)。而是鼓励通过channel将共享状态或共享状态的变化在各个Goroutine之间传递(以通信的方式去共享内存),这样同样能像用锁一样保证在同一的时间只有一个Goroutine访问共享状态。
当然,在主流的编程语言中为了保证多线程之间共享数据安全性和一致性,都会提供一套基本的同步工具集,如锁,条件变量,原子操作等等。Go语言标准库也毫不意外的提供了这些同步机制,使用方式也和其他语言也差不多。
WaitGroup
sync是synchronization同步这个词的缩写,所以也会叫做同步包。这里提供了基本同步的操作,比如互斥锁等等。这里除了Once和WaitGroup类型之外,大多数类型都是供低级库例程使用的。更高级别的同步最好通过channel通道和communication通信来完成。
WaitGroup,同步等待组。
在类型上,它是一个结构体。一个WaitGroup的用途是等待一个goroutine的集合执行完成。主goroutine调用了Add()方法来设置要等待的goroutine的数量。然后,每个goroutine都会执行并且执行完成后调用Done()这个方法。与此同时,可以使用Wait()方法来阻塞,直到所有的goroutine都执行完成。
Add()方法
Add这个方法,用来设置到WaitGroup的计数器的值。我们可以理解为每个waitgroup中都有一个计数器
用来表示这个同步等待组中要执行的goroutin的数量。
如果计数器的数值变为0,那么就表示等待时被阻塞的goroutine都被释放,如果计数器的数值为负数,那么就会引发恐慌,程序就报错了。
Done()方法
Done()方法,就是当WaitGroup同步等待组中的某个goroutine执行完毕后,设置这个WaitGroup的counter数值减1。
其实Done()的底层代码就是调用了Add()方法:
// Done decrements the WaitGroup counter by one.
func (wg *WaitGroup) Done() {
wg.Add(-1)
}
Wait()方法
Wait()方法,表示让当前的goroutine等待,进入阻塞状态。一直到WaitGroup的计数器为零。才能解除阻塞,
这个goroutine才能继续执行。
示例代码
我们创建并启动两个goroutine,来打印数字和字母,并在main goroutine中,将这两个子goroutine加入到一个WaitGroup中,同时让main goroutine进入Wait(),让两个子goroutine先执行。当每个子goroutine执行完毕后,调用Done()方法,设置WaitGroup的counter减1。当两条子goroutine都执行完毕后,WaitGroup中的counter的数值为零,解除main goroutine的阻塞。
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup // 创建同步等待组对象
func main() {
/*
WaitGroup:同步等待组
可以使用Add(),设置等待组中要 执行的子goroutine的数量,
在main 函数中,使用wait(),让主程序处于等待状态。直到等待组中子程序执行完毕。解除阻塞
子gorotuine对应的函数中。wg.Done(),用于让等待组中的子程序的数量减1
*/
//设置等待组中,要执行的goroutine的数量
wg.Add(2)
go fun1()
go fun2()
fmt.Println("main进入阻塞状态。。。等待wg中的子goroutine结束。。")
wg.Wait() //表示main goroutine进入等待,意味着阻塞
fmt.Println("main,解除阻塞。。")
}
func fun1() {
for i := 1; i <= 10; i++ {
fmt.Println("fun1.。。i:", i)
}
wg.Done() //给wg等待中的执行的goroutine数量减1.同Add(-1)
}
func fun2() {
defer wg.Done()
for j := 1; j <= 10; j++ {
fmt.Println("\tfun2..j,", j)
}
}
运行结果:
main进入阻塞状态。。。等待wg中的子goroutine结束。。
fun2..j, 1
fun2..j, 2
fun2..j, 3
fun2..j, 4
fun2..j, 5
fun2..j, 6
fun2..j, 7
fun2..j, 8
fun2..j, 9
fun2..j, 10
fun1.。。i: 1
fun1.。。i: 2
fun1.。。i: 3
fun1.。。i: 4
fun1.。。i: 5
fun1.。。i: 6
fun1.。。i: 7
fun1.。。i: 8
fun1.。。i: 9
fun1.。。i: 10
main,解除阻塞。。
互斥锁
Mutex(互斥锁)
在并发程序中,会存在临界资源问题。就是当多个协程来访问共享的数据资源,那么这个共享资源是不安全的。为了解决协程同步的问题我们使用了channel,但是Go语言也提供了传统的同步工具。
什么是锁呢?就是某个协程(线程)在访问某个资源时先锁住,防止其它协程的访问,等访问完毕解锁后其他协程再来加锁进行访问。一般用于处理并发中的临界资源问题。
Go语言包中的 sync 包提供了两种锁类型:sync.Mutex 和 sync.RWMutex。
Mutex 是最简单的一种锁类型,互斥锁,同时也比较暴力,当一个 goroutine 获得了 Mutex 后,其他 goroutine 就只能乖乖等到这个 goroutine 释放该 Mutex。
每个资源都对应于一个可称为 “互斥锁” 的标记,这个标记用来保证在任意时刻,只能有一个协程(线程)访问该资源。其它的协程只能等待。
互斥锁是传统并发编程对共享资源进行访问控制的主要手段,它由标准库sync中的Mutex结构体类型表示。sync.Mutex类型只有两个公开的指针方法,Lock和Unlock。Lock锁定当前的共享资源,Unlock进行解锁。
在使用互斥锁时,一定要注意:对资源操作完成后,一定要解锁,否则会出现流程执行异常,死锁等问题。通常借助defer。锁定后,立即使用defer语句保证互斥锁及时解锁。
Lock()方法
Lock()这个方法,锁定m。如果该锁已在使用中,则调用goroutine将阻塞,直到互斥体可用。
Unlock()方法
Unlock()方法,解锁m。如果m未在要解锁的条目上锁定,则为运行时错误。
锁定的互斥体不与特定的goroutine关联。允许一个goroutine锁定互斥体,然后安排另一个goroutine解锁互斥体。
示例代码
使用goroutine,模拟4个售票口出售火车票的案例。4个售票口同时卖票,会发生临界资源数据安全问题。我们使用互斥锁解决一下。(Go语言推崇的是使用Channel来实现数据共享,但是也还是提供了传统的同步处理方式)
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
// 全局变量,表示票
var ticket = 10 //10张票
var mutex sync.Mutex //创建锁头
var wg sync.WaitGroup //同步等待组对象
func main() {
wg.Add(4)
go saleTickets("售票口1")
go saleTickets("售票口2")
go saleTickets("售票口3")
go saleTickets("售票口4")
wg.Wait() //main要等待
fmt.Println("程序结束了。。。")
}
func saleTickets(name string) {
rand.Seed(time.Now().UnixNano())
defer wg.Done()
for {
//上锁
mutex.Lock() //g2
if ticket > 0 { //ticket 1 g1
time.Sleep(time.Duration(rand.Intn(1000)) * time.Millisecond)
fmt.Println(name, "售出:", ticket) // 1
ticket-- // 0
} else {
mutex.Unlock() //条件不满足,也要解锁
fmt.Println(name, "售罄,没有票了。。")
break
}
mutex.Unlock() //解锁
}
}
运行结果:
售票口1 售出: 10
售票口1 售出: 9
售票口2 售出: 8
售票口4 售出: 7
售票口3 售出: 6
售票口1 售出: 5
售票口2 售出: 4
售票口4 售出: 3
售票口3 售出: 2
售票口1 售出: 1
售票口3 售罄,没有票了。。
售票口2 售罄,没有票了。。
售票口4 售罄,没有票了。。
售票口1 售罄,没有票了。。
程序结束了。。。
读写锁
RWMutex(读写锁)
通过对互斥锁的学习,我们已经知道了锁的概念以及用途。主要是用于处理并发中的临界资源问题。
Go语言包中的 sync 包提供了两种锁类型:sync.Mutex 和 sync.RWMutex。其中RWMutex是基于Mutex实现的,只读锁的实现使用类似引用计数器的功能。
RWMutex是读/写互斥锁。锁可以由任意数量的读取器或单个编写器持有。RWMutex的零值是未锁定的mutex。
如果一个goroutine持有一个rRWMutex进行读取,而另一个goroutine可能调用lock,那么在释放初始读取锁之前,任何goroutine都不应该期望能够获取读取锁。特别是,这禁止递归读取锁定。这是为了确保锁最终可用;被阻止的锁调用会将新的读卡器排除在获取锁之外。
我们怎么理解读写锁呢?当有一个 goroutine 获得写锁定,其它无论是读锁定还是写锁定都将阻塞直到写解锁;当有一个 goroutine 获得读锁定,其它读锁定仍然可以继续;当有一个或任意多个读锁定,写锁定将等待所有读锁定解锁之后才能够进行写锁定。所以说这里的读锁定(RLock)目的其实是告诉写锁定:有很多人正在读取数据,你给我站一边去,等它们读(读解锁)完你再来写(写锁定)。我们可以将其总结为如下三条:
- 同时只能有一个 goroutine 能够获得写锁定。
- 同时可以有任意多个 gorouinte 获得读锁定。
- 同时只能存在写锁定或读锁定(读和写互斥)。
所以,RWMutex这个读写锁,该锁可以加多个读锁或者一个写锁,其经常用于读次数远远多于写次数的场景。
读写锁的写锁只能锁定一次,解锁前不能多次锁定,读锁可以多次,但读解锁次数最多只能比读锁次数多一次,一般情况下我们不建议读解锁次数多余读锁次数。
基本遵循两大原则:
1、可以随便读,多个goroutine同时读。
2、写的时候,啥也不能干。不能读也不能写。
读写锁即是针对于读写操作的互斥锁。它与普通的互斥锁最大的不同就是,它可以分别针对读操作和写操作进行锁定和解锁操作。读写锁遵循的访问控制规则与互斥锁有所不同。在读写锁管辖的范围内,它允许任意个读操作的同时进行。但是在同一时刻,它只允许有一个写操作在进行。
并且在某一个写操作被进行的过程中,读操作的进行也是不被允许的。也就是说读写锁控制下的多个写操作之间都是互斥的,并且写操作与读操作之间也都是互斥的。但是,多个读操作之间却不存在互斥关系。
常用方法
RLock()方法
func (rw *RWMutex) RLock()
读锁,当有写锁时,无法加载读锁,当只有读锁或者没有锁时,可以加载读锁,读锁可以加载多个,所以适用于“读多写少”的场景。
RUnlock()方法
func (rw *RWMutex) RUnlock()
读锁解锁,RUnlock 撤销单次RLock调用,它对于其它同时存在的读取器则没有效果。若rw并没有为读取而锁定,调用RUnlock就会引发一个运行时错误。
Lock()方法
func (rw *RWMutex) Lock()
写锁,如果在添加写锁之前已经有其他的读锁和写锁,则Lock就会阻塞直到该锁可用,为确保该锁最终可用,已阻塞的Lock调用会从获得的锁中排除新的读取锁,即写锁权限高于读锁,有写锁时优先进行写锁定。
Unlock()方法
func (rw *RWMutex) Unlock()
写锁解锁,如果没有进行写锁定,则就会引起一个运行时错误。
示例代码
package main
import (
"fmt"
"sync"
"time"
)
var rwMutex *sync.RWMutex
var wg *sync.WaitGroup
func main() {
rwMutex = new(sync.RWMutex)
wg = new(sync.WaitGroup)
//wg.Add(2)
//
多个同时读取
//go readData(1)
//go readData(2)
wg.Add(3)
go writeData(1)
go readData(2)
go writeData(3)
wg.Wait()
fmt.Println("main..over...")
}
func writeData(i int) {
defer wg.Done()
fmt.Println(i, "开始写:write start。。")
rwMutex.Lock() //写操作上锁
fmt.Println(i, "正在写:writing。。。。")
time.Sleep(3 * time.Second)
rwMutex.Unlock()
fmt.Println(i, "写结束:write over。。")
}
func readData(i int) {
defer wg.Done()
fmt.Println(i, "开始读:read start。。")
rwMutex.RLock() //读操作上锁
fmt.Println(i, "正在读取数据:reading。。。")
time.Sleep(3 * time.Second)
rwMutex.RUnlock() //读操作解锁
fmt.Println(i, "读结束:read over。。。")
}
运行结果:
3 开始写:write start。。
2 开始读:read start。。
3 正在写:writing。。。。
1 开始写:write start。。
3 写结束:write over。。
2 正在读取数据:reading。。。
2 读结束:read over。。。
1 正在写:writing。。。。
1 写结束:write over。。
main..over...
最后概括:
- 读锁不能阻塞读锁
- 读锁需要阻塞写锁,直到所有读锁都释放
- 写锁需要阻塞读锁,直到所有写锁都释放
- 写锁需要阻塞写锁
channel通道
通道可以被认为是Goroutines通信的管道。类似于管道中的水从一端到另一端的流动,数据可以从一端发送到另一端,通过通道接收。
在前面讲Go语言的并发时候,我们就说过,当多个Goroutine想实现共享数据的时候,虽然也提供了传统的同步机制,但是Go语言强烈建议的是使用Channel通道来实现Goroutines之间的通信。
“不要通过共享内存来通信,而应该通过通信来共享内存” 这是一句风靡golang社区的经典语
Go语言中,要传递某个数据给另一个goroutine(协程),可以把这个数据封装成一个对象,然后把这个对象的指针传入某个channel中,另外一个goroutine从这个channel中读出这个指针,并处理其指向的内存对象。Go从语言层面保证同一个时间只有一个goroutine能够访问channel里面的数据,为开发者提供了一种优雅简单的工具,所以Go的做法就是使用channel来通信,通过通信来传递内存数据,使得内存数据在不同的goroutine中传递,而不是使用共享内存来通信。
什么是通道
通道的概念
通道是什么,通道就是goroutine之间的通道。它可以让goroutine之间相互通信。
每个通道都有与其相关的类型。该类型是通道允许传输的数据类型。(通道的零值为nil。nil通道没有任何用处,因此通道必须使用类似于map和切片的方法来定义。)
通道的声明
声明一个通道和定义一个变量的语法一样:
//声明通道
var 通道名 chan 数据类型
//创建通道:如果通道为nil(就是不存在),就需要先创建通道
通道名 = make(chan 数据类型)
示例代码:
package main
import "fmt"
func main() {
var a chan int
if a == nil {
fmt.Println("channel 是 nil 的, 不能使用,需要先创建通道。。")
a = make(chan int)
fmt.Printf("数据类型是: %T", a)
}
}
运行结果:
channel 是 nil 的, 不能使用,需要先创建通道。。
数据类型是: chan int
也可以简短的声明:
a := make(chan int)
channel的数据类型
channel是引用类型的数据,在作为参数传递的时候,传递的是内存地址。
示例代码:
package main
import (
"fmt"
)
func main() {
ch1 := make(chan int)
fmt.Printf("%T,%p\n",ch1,ch1)
test1(ch1)
}
func test1(ch chan int){
fmt.Printf("%T,%p\n",ch,ch)
}
运行结果:
chan int,0xc00001e180
chan int,0xc00001e180
我们能够看到,ch和ch1的地址是一样的,说明它们是同一个通道。
通道的注意点
Channel通道在使用的时候,有以下几个注意点:
-
1.用于goroutine,传递消息的。
-
2.通道,每个都有相关联的数据类型,
nil chan,不能使用,类似于nil map,不能直接存储键值对 -
3.使用通道传递数据:<-
chan <- data,发送数据到通道。向通道中写数据
data <- chan,从通道中获取数据。从通道中读数据 -
4.阻塞:
发送数据:chan <- data,阻塞的,直到另一条goroutine,读取数据来解除阻塞
读取数据:data <- chan,也是阻塞的。直到另一条goroutine,写出数据解除阻塞。 -
5.本身channel就是同步的,意味着同一时间,只能有一条goroutine来操作。
最后:通道是goroutine之间的连接,所以通道的发送和接收必须处在不同的goroutine中。
通道的使用语法
发送和接收
发送和接收的语法:
data := <- a // read from channel a
a <- data // write to channel a
在通道上箭头的方向指定数据是发送还是接收。
另外:
v, ok := <- a //从一个channel中读取
发送和接收默认是阻塞的
一个通道发送和接收数据,默认是阻塞的。当一个数据被发送到通道时,在发送语句中被阻塞,直到另一个Goroutine从该通道读取数据。相对地,当从通道读取数据时,读取被阻塞,直到一个Goroutine将数据写入该通道。
这些通道的特性是帮助Goroutines有效地进行通信,而无需像使用其他编程语言中非常常见的显式锁或条件变量。
示例代码:
package main
import "fmt"
func main() {
var ch1 chan bool //声明,没有创建
fmt.Println(ch1) //<nil>
fmt.Printf("%T\n", ch1) //chan bool
ch1 = make(chan bool) //0xc0000a4000,是引用类型的数据
fmt.Println(ch1)
go func() {
for i := 0; i < 10; i++ {
fmt.Println("子goroutine中,i:", i)
}
// 循环结束后,向通道中写数据,表示要结束了。。
ch1 <- true
fmt.Println("结束。。")
}()
data := <-ch1 // 从ch1通道中读取数据
fmt.Println("data-->", data)
fmt.Println("main。。over。。。。")
}
运行结果:
<nil>
chan bool
0xc000086120
子goroutine中,i: 0
子goroutine中,i: 1
子goroutine中,i: 2
子goroutine中,i: 3
子goroutine中,i: 4
子goroutine中,i: 5
子goroutine中,i: 6
子goroutine中,i: 7
子goroutine中,i: 8
子goroutine中,i: 9
结束。。
data--> true
main。。over。。。。
在上面的程序中,我们先创建了一个chan bool通道。然后启动了一条子Goroutine,并循环打印10个数字。然后我们向通道ch1中写入输入true。然后在主goroutine中,我们从ch1中读取数据。这一行代码是阻塞的,这意味着在子Goroutine将数据写入到该通道之前,主goroutine将不会执行到下一行代码。因此,我们可以通过channel实现子goroutine和主goroutine之间的通信。当子goroutine执行完毕前,主goroutine会因为读取ch1中的数据而阻塞。从而保证了子goroutine会先执行完毕。这就消除了对时间的需求。在之前的程序中,我们要么让主goroutine进入睡眠,以防止主要的Goroutine退出。要么通过WaitGroup来保证子goroutine先执行完毕,主goroutine才结束。
示例代码:以下代码加入了睡眠,可以更好的理解channel的阻塞
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan int)
done := make(chan bool) // 通道
go func() {
fmt.Println("子goroutine执行。。。")
time.Sleep(3 * time.Second)
data := <-ch1 // 从通道中读取数据
fmt.Println("data:", data)
done <- true
}()
// 向通道中写数据。。
time.Sleep(5 * time.Second)
ch1 <- 100
<-done
fmt.Println("main。。over")
}
运行结果:
子goroutine执行。。。
data: 100
main。。over
再举一个例子,下面这段程序将打印一个数字的各位的平方和以及立方和。
package main
import (
"fmt"
)
func calcSquares(number int, squareop chan int) {
sum := 0
for number != 0 {
digit := number % 10
sum += digit * digit
number /= 10
}
squareop <- sum
}
func calcCubes(number int, cubeop chan int) {
sum := 0
for number != 0 {
digit := number % 10
sum += digit * digit * digit
number /= 10
}
cubeop <- sum
}
func main() {
number := 123
sqrch := make(chan int)
cubech := make(chan int)
go calcSquares(number, sqrch)
go calcCubes(number, cubech)
squares, cubes := <-sqrch, <-cubech
fmt.Println("Final output", squares, cubes)
}
运行结果:
Final output 14 36
死锁
使用通道时要考虑的一个重要因素是死锁。如果Goroutine在一个通道上发送数据,那么预计其他的Goroutine应该接收数据。如果这种情况不发生,那么程序将在运行时出现死锁。
类似地,如果Goroutine正在等待从通道接收数据,那么另一些Goroutine将会在该通道上写入数据,否则程序将会死锁。
关闭通道
发送者可以通过关闭信道,来通知接收方不会有更多的数据被发送到channel上。
close(ch)
接收者可以在接收来自通道的数据时使用额外的变量来检查通道是否已经关闭。
语法结构:
v, ok := <- ch
类似map操作,存储key,value键值对
v,ok := map[key] //根据key从map中获取value,如果key存在, v就是对应的数据,如果key不存在,v是默认值
在上面的语句中,如果ok的值是true,表示成功的从通道中读取了一个数据value。如果ok是false,这意味着我们正在从一个封闭的通道读取数据。从闭通道读取的值将是通道类型的零值。
例如,如果通道是一个int通道,那么从封闭通道接收的值将为0。
示例代码:
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan int)
go sendData(ch1)
/*
子goroutine,写出数据10个
每写一个,阻塞一次,主程序读取一次,解除阻塞
主goroutine:循环读
每次读取一个,堵塞一次,子程序,写出一个,解除阻塞
发送发,关闭通道的--->接收方,接收到的数据是该类型的零值,以及false
*/
//主程序中获取通道的数据
for {
time.Sleep(1 * time.Second)
v, ok := <-ch1 //其他goroutine,显示的调用close方法关闭通道。
if !ok {
fmt.Println("已经读取了所有的数据,", ok, v)
break
}
fmt.Println("取出数据:", v, ok)
}
fmt.Println("main...over....")
}
func sendData(ch1 chan int) {
// 发送方:10条数据
for i := 0; i < 10; i++ {
ch1 <- i //将i写入通道中
}
close(ch1) //将ch1通道关闭了。
}
运行结果
取出数据: 0 true
取出数据: 1 true
取出数据: 2 true
取出数据: 3 true
取出数据: 4 true
取出数据: 5 true
取出数据: 6 true
取出数据: 7 true
取出数据: 8 true
取出数据: 9 true
已经读取了所有的数据, false 0
main...over....
在上面的程序中,send Goroutine将0到9写入chl通道,然后关闭通道。主函数里有一个无限循环。它检查通道是否在发送数据后,使用变量ok关闭。如果ok是假的,则意味着通道关闭,因此循环结束。还可以打印接收到的值和ok的值。
通道上的范围循环
我们可以循环从通道上获取数据,直到通道关闭。for循环的for range形式可用于从通道接收值,直到它关闭为止。
使用range循环,示例代码:
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan int)
go sendData(ch1)
// for循环的for range形式可用于从通道接收值,直到它关闭为止。
for v := range ch1 {
fmt.Println("读取数据:", v)
}
fmt.Println("main..over.....")
}
func sendData(ch1 chan int) {
for i := 0; i < 10; i++ {
time.Sleep(1 * time.Second)
ch1 <- i
}
close(ch1) //通知对方,通道关闭
}
运行结果:
读取数据: 0
读取数据: 1
读取数据: 2
读取数据: 3
读取数据: 4
读取数据: 5
读取数据: 6
读取数据: 7
读取数据: 8
读取数据: 9
main..over.....
缓冲通道
非缓冲通道
之前学习的所有通道基本上都没有缓冲。发送和接收到一个未缓冲的通道是阻塞的。
一次发送操作对应一次接收操作,对于一个goroutine来讲,它的一次发送,在另一个goroutine接收之前都是阻塞的。同样的,对于接收来讲,在另一个goroutine发送之前,它也是阻塞的。
缓冲通道
缓冲通道就是指一个通道,带有一个缓冲区。发送到一个缓冲通道只有在缓冲区满时才被阻塞。类似地,从缓冲通道接收的信息只有在缓冲区为空时才会被阻塞。
可以通过将额外的容量参数传递给make函数来创建缓冲通道,该函数指定缓冲区的大小。
语法:
ch := make(chan type, capacity)
上述语法的容量应该大于0,以便通道具有缓冲区。默认情况下,无缓冲通道的容量为0,因此在之前创建通道时省略了容量参数。
示例代码
以下的代码中,chan通道,是带有缓冲区的。
package main
import (
"fmt"
"strconv"
"time"
)
func main() {
/*
非缓存通道:make(chan T)
缓存通道:make(chan T ,size)
缓存通道,理解为是队列:
非缓存,发送还是接受,都是阻塞的
缓存通道,缓存区的数据满了,才会阻塞状态。。
*/
ch := make(chan string, 4)
go sendData3(ch)
for {
time.Sleep(time.Second / 2)
v, ok := <-ch
if !ok {
fmt.Println("读完了,,", ok)
break
}
fmt.Println("\t读取的数据是:", v)
}
fmt.Println("main...over...")
}
func sendData3(ch chan string) {
for i := 0; i < 10; i++ {
ch <- "数据" + strconv.Itoa(i)
fmt.Println("子goroutine,写出第", i, "个数据")
}
close(ch)
}
运行结果:
子goroutine,写出第 0 个数据
子goroutine,写出第 1 个数据
子goroutine,写出第 2 个数据
子goroutine,写出第 3 个数据
读取的数据是: 数据0
子goroutine,写出第 4 个数据
子goroutine,写出第 5 个数据
读取的数据是: 数据1
子goroutine,写出第 6 个数据
读取的数据是: 数据2
读取的数据是: 数据3
子goroutine,写出第 7 个数据
读取的数据是: 数据4
子goroutine,写出第 8 个数据
读取的数据是: 数据5
子goroutine,写出第 9 个数据
读取的数据是: 数据6
读取的数据是: 数据7
读取的数据是: 数据8
读取的数据是: 数据9
读完了,, false
main...over...
定向通道
双向通道
通道,channel,是用于实现goroutine之间的通信的。一个goroutine可以向通道中发送数据,另一条goroutine可以从该通道中获取数据。截止到现在我们所学习的通道,都是既可以发送数据,也可以读取数据,我们又把这种通道叫做双向通道。
data := <- a // read from channel a
a <- data // write to channel a
package main
import "fmt"
func main() {
ch1 := make(chan string) // 双向,可读,可写
done := make(chan bool)
go sendData(ch1, done)
data := <-ch1 //阻塞
fmt.Println("子goroutine传来:", data)
ch1 <- "我是main。。" // 阻塞
<-done
fmt.Println("main...over....")
}
// 子goroutine-->写数据到ch1通道中
// main goroutine-->从ch1通道中取
func sendData(ch1 chan string, done chan bool) {
ch1 <- "我是小明" // 阻塞
data := <-ch1 // 阻塞
fmt.Println("main goroutine传来:", data)
done <- true
}
运行结果:
子goroutine传来: 我是小明
main goroutine传来: 我是main。。
main...over....
单向通道
单向通道,也就是定向通道。
之前我们学习的通道都是双向通道,我们可以通过这些通道接收或者发送数据。我们也可以创建单向通道,这些通道只能发送或者接收数据。
创建仅能发送数据的通道,示例代码:
示例代码:
package main
import "fmt"
func main() {
/*
单向:定向
chan <- T,
只支持写,
<- chan T,
只读
*/
ch1 := make(chan int)//双向,读,写
//ch2 := make(chan <- int) // 单向,只写,不能读
//ch3 := make(<- chan int) //单向,只读,不能写
//ch1 <- 100
//data :=<-ch1
//ch2 <- 1000
//data := <- ch2
//fmt.Println(data)
// <-ch2 //invalid operation: <-ch2 (receive from send-only type chan<- int)
//ch3 <- 100
// <-ch3
// ch3 <- 100 //invalid operation: ch3 <- 100 (send to receive-only type <-chan int)
//go fun1(ch2)
go fun1(ch1)
data:= <- ch1
fmt.Println("fun1中写出的数据是:",data)
//fun2(ch3)
go fun2(ch1)
ch1 <- 200
fmt.Println("main。。over。。")
}
//该函数接收,只写的通道
func fun1(ch chan <- int){
// 函数内部,对于ch只能写数据,不能读数据
ch <- 100
fmt.Println("fun1函数结束。。")
}
func fun2(ch <-chan int){
//函数内部,对于ch只能读数据,不能写数据
data := <- ch
fmt.Println("fun2函数,从ch中读取的数据是:",data)
}
运行结果:
fun1函数结束。。
fun1中写出的数据是: 100
fun2函数,从ch中读取的数据是: 200
main。。over。。
time包中的通道相关函数
主要就是定时器,标准库中的Timer让用户可以定义自己的超时逻辑,尤其是在应对select处理多个channel的超时、单channel读写的超时等情形时尤为方便。
Timer是一次性的时间触发事件,这点与Ticker不同,Ticker是按一定时间间隔持续触发时间事件。
Timer常见的创建方式:
t:= time.NewTimer(d)
t:= time.AfterFunc(d, f)
c:= time.After(d)
虽然说创建方式不同,但是原理是相同的。
Timer有3个要素:
定时时间:就是那个d
触发动作:就是那个f
时间channel: 也就是t.C
time.NewTimer()
NewTimer()创建一个新的计时器,该计时器将在其通道上至少持续d之后发送当前时间。它的返回值是一个Timer。
源代码:
// NewTimer creates a new Timer that will send
// the current time on its channel after at least duration d.
func NewTimer(d Duration) *Timer {
c := make(chan Time, 1)
t := &Timer{
C: c,
r: runtimeTimer{
when: when(d),
f: sendTime,
arg: c,
},
}
startTimer(&t.r)
return t
}
通过源代码我们可以看出,首先创建一个channel,关联的类型为Time,然后创建了一个Timer并返回。
- 用于在指定的Duration类型时间后调用函数或计算表达式。
- 如果只是想指定时间之后执行,使用time.Sleep()
- 使用NewTimer(),可以返回的Timer类型在计时器到期之前,取消该计时器
- 直到使用<-timer.C发送一个值,该计时器才会过期
示例代码:
package main
import (
"fmt"
"time"
)
func main() {
/*
func NewTimer(d Duration) *Timer
创建一个计时器:d时间以后触发,go触发计时器的方法比较特别,就是在计时器的channel中发送值
*/
//新建一个计时器:timer
timer := time.NewTimer(3 * time.Second)
fmt.Printf("%T\n", timer) //*time.Timer
fmt.Println(time.Now()) //2023-07-07 16:26:45.5207225 +0800 CST m=+0.001542901
//此处在等待channel中的信号,执行此段代码时会阻塞3秒
ch2 := timer.C //<-chan time.Time
fmt.Println(<-ch2) //2023-07-07 16:26:48.5308961 +0800 CST m=+3.011716501
}
timer.Stop
计时器停止:
示例代码:
package main
import (
"fmt"
"time"
)
func main() {
//新建计时器,一秒后触发
timer2 := time.NewTimer(3 * time.Second)
//新开启一个线程来处理触发后的事件
go func() {
//等触发时的信号
<-timer2.C
fmt.Println("Timer 2 结束。。")
}()
//由于上面的等待信号是在新线程中,所以代码会继续往下执行,停掉计时器
time.Sleep(1 * time.Second)
stop := timer2.Stop()
if stop {
fmt.Println("Timer 2 停止。。")
}
}
运行结果:
Timer 2 停止。。
time.After()
在等待持续时间之后,然后在返回的通道上发送当前时间。它相当于NewTimer(d).C。在计时器触发之前,垃圾收集器不会恢复底层计时器。如果效率有问题,使用NewTimer代替,并调用Timer。如果不再需要计时器,请停止。
示例代码:
package main
import (
"fmt"
"time"
)
func main() {
/*
func After(d Duration) <-chan Time
返回一个通道:chan,存储的是d时间间隔后的当前时间。
*/
ch1 := time.After(3 * time.Second) //3s后
fmt.Printf("%T\n", ch1) // <-chan time.Time
fmt.Println(time.Now()) //2023-07-07 16:36:10.8553299 +0800 CST m=+0.001792901
time2 := <-ch1
fmt.Println(time2) //2023-07-07 16:36:13.8602885 +0800 CST m=+3.006751501
}
select语句
select 是 Go 中的一个控制结构。select 语句类似于 switch 语句,但是select会随机执行一个可运行的case。如果没有case可运行,它将阻塞,直到有case可运行。
语法结构
select语句的语法结构和switch语句很相似,也有case语句和default语句:
select {
case communication clause :
statement(s);
case communication clause :
statement(s);
/* 你可以定义任意数量的 case */
default : /* 可选 */
statement(s);
}
说明:
-
每个case都必须是一个通信
-
所有channel表达式都会被求值
-
所有被发送的表达式都会被求值
-
如果有多个case都可以运行,select会随机公平地选出一个执行。其他不会执行。
-
否则:
如果有default子句,则执行该语句。
如果没有default字句,select将阻塞,直到某个通信可以运行;Go不会重新对channel或值进行求值。
示例代码
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go func() {
time.Sleep(2 * time.Second)
ch2 <- 200
}()
go func() {
time.Sleep(2 * time.Second)
ch1 <- 100
}()
select {
case num1 := <-ch1:
fmt.Println("ch1中取数据。。", num1)
case num2, ok := <-ch2:
if ok {
fmt.Println("ch2中取数据。。", num2)
} else {
fmt.Println("ch2通道已经关闭。。")
}
}
}
运行结果:可能执行第一个case,打印100,也可能执行第二个case,打印200。(多运行几次,结果就不同了)
select语句结合time包的和chan相关函数,示例代码:
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go func() {
ch1 <- 100
}()
select {
case <-ch1:
fmt.Println("case1可以执行。。")
case <-ch2:
fmt.Println("case2可以执行。。")
case <-time.After(3 * time.Second):
fmt.Println("case3执行。。timeout。。")
default:
fmt.Println("执行了default。。")
}
}
运行结果:case1可以执行。。或者执行了default。。
Go语言的CSP模型
go语言的最大两个亮点,一个是goroutine,一个就是chan了。二者合体的典型应用CSP,基本就是大家认可的并行开发神器,简化了并行程序的开发难度,我们来看一下CSP。
CSP是什么
CSP 是 Communicating Sequential Process 的简称,中文可以叫做通信顺序进程,是一种并发编程模型,是一个很强大的并发数据模型,是上个世纪七十年代提出的,用于描述两个独立的并发实体通过共享的通讯 channel(管道)进行通信的并发模型。相对于Actor模型,CSP中channel是第一类对象,它不关注发送消息的实体,而关注与发送消息时使用的channel。
严格来说,CSP 是一门形式语言(类似于 ℷ calculus),用于描述并发系统中的互动模式,也因此成为一众面向并发的编程语言的理论源头,并衍生出了 Occam/Limbo/Golang…
而具体到编程语言,如 Golang,其实只用到了 CSP 的很小一部分,即理论中的 Process/Channel(对应到语言中的 goroutine/channel):这两个并发原语之间没有从属关系, Process 可以订阅任意个 Channel,Channel 也并不关心是哪个 Process 在利用它进行通信;Process 围绕 Channel 进行读写,形成一套有序阻塞和可预测的并发模型。
Golang CSP
与主流语言通过共享内存来进行并发控制方式不同,Go 语言采用了 CSP 模式。这是一种用于描述两个独立的并发实体通过共享的通讯 Channel(管道)进行通信的并发模型。
Golang 就是借用CSP模型的一些概念为之实现并发进行理论支持,其实从实际上出发,go语言并没有完全实现CSP模型的所有理论,仅仅是借用了 process和channel这两个概念。process是在go语言上的表现就是 goroutine 是实际并发执行的实体,每个实体之间是通过channel通讯来实现数据共享。
Go语言的CSP模型是由协程Goroutine与通道Channel实现:
- Go协程goroutine: 是一种轻量线程,它不是操作系统的线程,而是将一个操作系统线程分段使用,通过调度器实现协作式调度。是一种绿色线程,微线程,它与Coroutine协程也有区别,能够在发现堵塞后启动新的微线程。
- 通道channel: 类似Unix的Pipe,用于协程之间通讯和同步。协程之间虽然解耦,但是它们和Channel有着耦合。
Channel
Goroutine 和 channel 是 Go 语言并发编程的两大基石。Goroutine 用于执行并发任务,channel 用于 goroutine 之间的同步、通信。
Channel 在 gouroutine 间架起了一条管道,在管道里传输数据,实现 gouroutine 间的通信;由于它是线程安全的,所以用起来非常方便;channel 还提供 “先进先出” 的特性;它还能影响 goroutine 的阻塞和唤醒。
相信大家一定见过一句话:
Do not communicate by sharing memory; instead, share memory by communicating.
不要通过共享内存来通信,而要通过通信来实现内存共享。
这就是 Go 的并发哲学,它依赖 CSP 模型,基于 channel 实现。
channel 实现 CSP
Channel 是 Go 语言中一个非常重要的类型,是 Go 里的第一对象。通过 channel,Go 实现了通过通信来实现内存共享。Channel 是在多个 goroutine 之间传递数据和同步的重要手段。
使用原子函数、读写锁可以保证资源的共享访问安全,但使用 channel 更优雅。
channel 字面意义是 “通道”,类似于 Linux 中的管道。声明 channel 的语法如下:
chan T // 声明一个双向通道
chan<- T // 声明一个只能用于发送的通道
<-chan T // 声明一个只能用于接收的通道
单向通道的声明,用 <- 来表示,它指明通道的方向。你只要明白,代码的书写顺序是从左到右就马上能掌握通道的方向是怎样的。
因为 channel 是一个引用类型,所以在它被初始化之前,它的值是 nil,channel 使用 make 函数进行初始化。可以向它传递一个 int 值,代表 channel 缓冲区的大小(容量),构造出来的是一个缓冲型的 channel;不传或传 0 的,构造的就是一个非缓冲型的 channel。
两者有一些差别:非缓冲型 channel 无法缓冲元素,对它的操作一定顺序是 “发送 -> 接收 -> 发送 -> 接收 -> ……”,如果想连续向一个非缓冲 chan 发送 2 个元素,并且没有接收的话,第一次一定会被阻塞;对于缓冲型 channel 的操作,则要 “宽松” 一些,毕竟是带了 “缓冲” 光环。
对 chan 的发送和接收操作都会在编译期间转换成为底层的发送接收函数。
Channel 分为两种:带缓冲、不带缓冲。对不带缓冲的 channel 进行的操作实际上可以看作 “同步模式”,带缓冲的则称为 “异步模式”。
同步模式下,发送方和接收方要同步就绪,只有在两者都 ready 的情况下,数据才能在两者间传输(后面会看到,实际上就是内存拷贝)。否则,任意一方先行进行发送或接收操作,都会被挂起,等待另一方的出现才能被唤醒。
异步模式下,在缓冲槽可用的情况下(有剩余容量),发送和接收操作都可以顺利进行。否则,操作的一方(如写入)同样会被挂起,直到出现相反操作(如接收)才会被唤醒。
小结一下:同步模式下,必须要使发送方和接收方配对,操作才会成功,否则会被阻塞;异步模式下,缓冲槽要有剩余容量,操作才会成功,否则也会被阻塞。
简单来说,CSP 模型由并发执行的实体(线程或者进程或者协程)所组成,实体之间通过发送消息进行通信,
这里发送消息时使用的就是通道,或者叫 channel。
CSP 模型的关键是关注 channel,而不关注发送消息的实体。Go 语言实现了 CSP 部分理论,goroutine 对应 CSP 中并发执行的实体,channel 也就对应着 CSP 中的 channel。
Goroutine
Goroutine 是实际并发执行的实体,它底层是使用协程(coroutine)实现并发,coroutine是一种运行在用户态的用户线程,类似于 greenthread,go底层选择使用coroutine的出发点是因为,它具有以下特点:
- 用户空间 避免了内核态和用户态的切换导致的成本
- 可以由语言和框架层进行调度
- 更小的栈空间允许创建大量的实例
可以看到第二条 用户空间线程的调度不是由操作系统来完成的,像在java 1.3中使用的greenthread的是由JVM统一调度的(后java已经改为内核线程),还有在ruby中的fiber(半协程) 是需要在重新中自己进行调度的,而goroutine是在golang层面提供了调度器,并且对网络IO库进行了封装,屏蔽了复杂的细节,对外提供统一的语法关键字支持,简化了并发程序编写的成本。
Goroutine 调度器
Go并发调度: G-P-M模型
在操作系统提供的内核线程之上,Go搭建了一个特有的两级线程模型。goroutine机制实现了M : N的线程模型,goroutine机制是协程(coroutine)的一种实现,golang内置的调度器,可以让多核CPU中每个CPU执行一个协程。
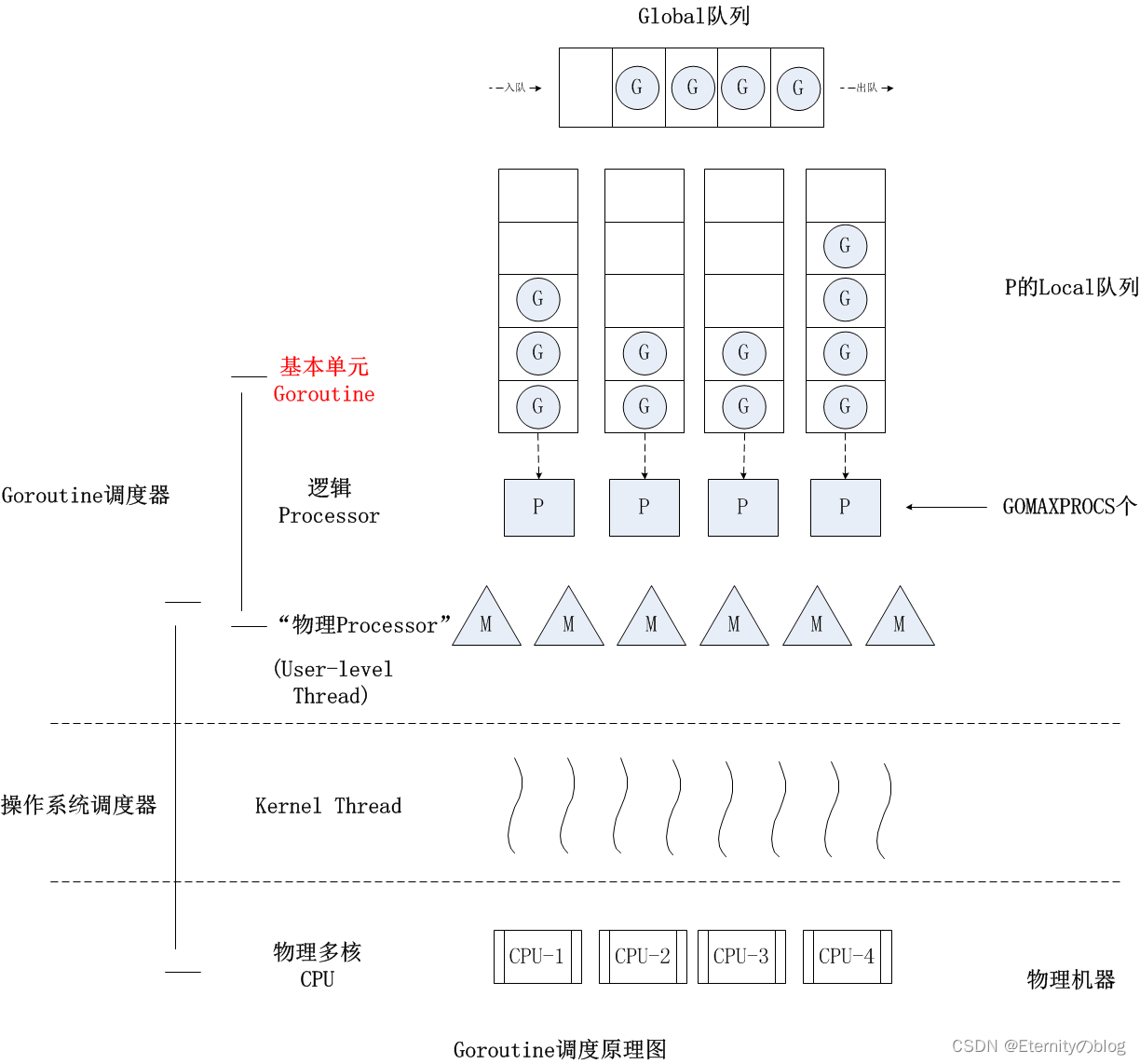
最后
Golang 的 channel 将 goroutine 隔离开,并发编程的时候可以将注意力放在 channel 上。在一定程度上,这个和消息队列的解耦功能还是挺像的。如果大家感兴趣,还是来看看 channel 的源码吧,对于更深入地理解 channel 还是挺有用的。
Go 通过 channel 实现 CSP 通信模型,主要用于 goroutine 之间的消息传递和事件通知。
有了 channel 和 goroutine 之后,Go 的并发编程变得异常容易和安全,得以让程序员把注意力留到业务上去,实现开发效率的提升。
要知道,技术并不是最重要的,它只是实现业务的工具。一门高效的开发语言让你把节省下来的时间,留着去做更有意义的事情,比如写写文章。
反射
引入
先看官方Doc中Rob Pike给出的关于反射的定义:
Reflection in computing is the ability of a program to examine its own structure, particularly through types; it’s a form of metaprogramming. It’s also a great source of confusion.
(在计算机领域,反射是一种让程序——主要是通过类型——理解其自身结构的一种能力。它是元编程的组成之一,同时它也是一大引人困惑的难题。)
维基百科中的定义:
在计算机科学中,反射是指计算机程序在运行时(Run time)可以访问、检测和修改它本身状态或行为的一种能力。用比喻来说,反射就是程序在运行的时候能够“观察”并且修改自己的行为。
不同语言的反射模型不尽相同,有些语言还不支持反射。《Go 语言圣经》中是这样定义反射的:
Go 语言提供了一种机制在运行时更新变量和检查它们的值、调用它们的方法,但是在编译时并不知道这些变量的具体类型,这称为反射机制。
为什么要用反射
需要反射的 2 个常见场景:
- 有时你需要编写一个函数,但是并不知道传给你的参数类型是什么,可能是没约定好;也可能是传入的类型很多,这些类型并不能统一表示。这时反射就会用的上了。
- 有时候需要根据某些条件决定调用哪个函数,比如根据用户的输入来决定。这时就需要对函数和函数的参数进行反射,在运行期间动态地执行函数。
但是对于反射,还是有几点不太建议使用反射的理由:
- 与反射相关的代码,经常是难以阅读的。在软件工程中,代码可读性也是一个非常重要的指标。
- Go 语言作为一门静态语言,编码过程中,编译器能提前发现一些类型错误,但是对于反射代码是无能为力的。所以包含反射相关的代码,很可能会运行很久,才会出错,这时候经常是直接 panic,可能会造成严重的后果。
- 反射对性能影响还是比较大的,比正常代码运行速度慢一到两个数量级。所以,对于一个项目中处于运行效率关键位置的代码,尽量避免使用反射特性。
相关基础
反射是如何实现的?我们以前学习过 interface,它是 Go 语言实现抽象的一个非常强大的工具。当向接口变量赋予一个实体类型的时候,接口会存储实体的类型信息,反射就是通过接口的类型信息实现的,反射建立在类型的基础上。
Go 语言在 reflect 包里定义了各种类型,实现了反射的各种函数,通过它们可以在运行时检测类型的信息、改变类型的值。在进行更加详细的了解之前,我们需要重新温习一下Go语言相关的一些特性,所谓温故知新,从这些特性中了解其反射机制是如何使用的。
| 特点 | 说明 |
|---|---|
| go语言是静态类型语言。 | 编译时类型已经确定,比如对已基本数据类型的再定义后的类型,反射时候需要确认返回的是何种类型。 |
| 空接口interface{} | go的反射机制是要通过接口来进行的,而类似于Java的Object的空接口可以和任何类型进行交互,因此对基本数据类型等的反射也直接利用了这一特点 |
| Go语言的类型: |
-
变量包括(type, value)两部分
理解这一点就知道为什么nil != nil了
-
type 包括 static type和concrete type. 简单来说 static type是你在编码是看见的类型(如int、string),concrete type是runtime系统看见的类型
-
类型断言能否成功,取决于变量的concrete type,而不是static type。因此,一个 reader变量如果它的concrete type也实现了write方法的话,它也可以被类型断言为writer。
Go语言的反射就是建立在类型之上的,Golang的指定类型的变量的类型是静态的(也就是指定int、string这些的变量,它的type是static type),在创建变量的时候就已经确定,反射主要与Golang的interface类型相关(它的type是concrete type),只有interface类型才有反射一说。
在Golang的实现中,每个interface变量都有一个对应pair,pair中记录了实际变量的值和类型:
(value, type)
value是实际变量值,type是实际变量的类型。一个interface{}类型的变量包含了2个指针,一个指针指向值的类型【对应concrete type】,另外一个指针指向实际的值【对应value】。
例如,创建类型为*os.File的变量,然后将其赋给一个接口变量r:
tty, err := os.OpenFile("/dev/tty", os.O_RDWR, 0)
var r io.Reader
r = tty
接口变量r的pair中将记录如下信息:(tty, *os.File),这个pair在接口变量的连续赋值过程中是不变的,将接口变量r赋给另一个接口变量w:
var w io.Writer
w = r.(io.Writer)
接口变量w的pair与r的pair相同,都是:(tty, *os.File),即使w是空接口类型,pair也是不变的。
interface及其pair的存在,是Golang中实现反射的前提,理解了pair,就更容易理解反射。反射就是用来检测存储在接口变量内部(值value;类型concrete type) pair对的一种机制。
所以我们要理解两个基本概念 Type 和 Value,它们也是 Go语言包中 reflect 空间里最重要的两个类型。
反射的使用
我们一般用到的包是reflect包。
TypeOf和ValueOf
既然反射就是用来检测存储在接口变量内部(值value;类型concrete type) pair对的一种机制。那么在Golang的reflect反射包中有什么样的方式可以让我们直接获取到变量内部的信息呢? 它提供了两种类型(或者说两个方法)让我们可以很容易的访问接口变量内容,分别是reflect.ValueOf() 和 reflect.TypeOf(),看看官方的解释:
// ValueOf returns a new Value initialized to the concrete value
// stored in the interface i. ValueOf(nil) returns the zero
func ValueOf(i interface{}) Value {...}
翻译一下:ValueOf用来获取输入参数接口中的数据的值,如果接口为空则返回0
// TypeOf returns the reflection Type that represents the dynamic type of i.
// If i is a nil interface value, TypeOf returns nil.
func TypeOf(i interface{}) Type {...}
翻译一下:TypeOf用来动态获取输入参数接口中的值的类型,如果接口为空则返回nil
reflect.TypeOf()是获取pair中的type,reflect.ValueOf()获取pair中的value。
首先需要把它转化成reflect对象(reflect.Type或者reflect.Value,根据不同的情况调用不同的函数。
t := reflect.TypeOf(i) //得到类型的元数据,通过t我们能获取类型定义里面的所有元素
v := reflect.ValueOf(i) //得到实际的值,通过v我们获取存储在里面的值,还可以去改变值
示例代码:
package main
import (
"fmt"
"reflect"
)
func main() {
//反射操作:通过反射,可以获取一个接口类型变量的 类型和数值
var x = 3.14
fmt.Println("type:", reflect.TypeOf(x)) //type: float64
fmt.Println("value:", reflect.ValueOf(x)) //value: 3.4
fmt.Println("-------------------")
//根据反射的值,来获取对应的类型和数值
v := reflect.ValueOf(x)
fmt.Println("kind is float64: ", v.Kind() == reflect.Float64)
fmt.Println("type : ", v.Type())
fmt.Println("value : ", v.Float())
}
运行结果:
type: float64
value: 3.14
-------------------
kind is float64: true
type : float64
value : 3.14
说明
- reflect.TypeOf: 直接给到了我们想要的type类型,如float64、int、各种pointer、struct 等等真实的类型
- reflect.ValueOf:直接给到了我们想要的具体的值,如1.2345这个具体数值,或者类似&{1 “Allen.Wu” 25} 这样的结构体struct的值
- 也就是说明反射可以将“接口类型变量”转换为“反射类型对象”,反射类型指的是reflect.Type和reflect.Value这两种
Type 和 Value 都包含了大量的方法,其中第一个有用的方法应该是 Kind,这个方法返回该类型的具体信息:Uint、Float64 等。Value 类型还包含了一系列类型方法,比如 Int(),用于返回对应的值。以下是Kind的种类:
// A Kind represents the specific kind of type that a Type represents.
// The zero Kind is not a valid kind.
type Kind uint
const (
Invalid Kind = iota
Bool
Int
Int8
Int16
Int32
Int64
Uint
Uint8
Uint16
Uint32
Uint64
Uintptr
Float32
Float64
Complex64
Complex128
Array
Chan
Func
Interface
Map
Ptr
Slice
String
Struct
UnsafePointer
)
从relfect.Value中获取接口interface的信息
当执行reflect.ValueOf(interface)之后,就得到了一个类型为”relfect.Value”变量,可以通过它本身的Interface()方法获得接口变量的真实内容,然后可以通过类型判断进行转换,转换为原有真实类型。不过,我们可能是已知原有类型,也有可能是未知原有类型,因此,下面分两种情况进行说明。
已知原有类型【进行“强制转换”】
已知类型后转换为其对应的类型的做法如下,直接通过Interface方法然后强制转换,如下:
realValue := value.Interface().(已知的类型)
示例代码:
package main
import (
"fmt"
"reflect"
)
func main() {
var num float64 = 1.2345
pointer := reflect.ValueOf(&num)
value := reflect.ValueOf(num)
// 可以理解为“强制转换”,但是需要注意的时候,转换的时候,如果转换的类型不完全符合,则直接panic
// Golang 对类型要求非常严格,类型一定要完全符合
// 如下两个,一个是*float64,一个是float64,如果弄混,则会panic
convertPointer := pointer.Interface().(*float64)
convertValue := value.Interface().(float64)
fmt.Println(convertPointer)
fmt.Println(convertValue)
}
运行结果:
0xc000098000
1.2345
说明
- 转换的时候,如果转换的类型不完全符合,则直接panic,类型要求非常严格!
- 转换的时候,要区分是指针类型还是非指针类型
- 也就是说反射可以将“反射类型对象”再重新转换为“接口类型变量”
未知原有类型【遍历探测其Filed】
很多情况下,我们可能并不知道其具体类型,那么这个时候,该如何做呢?需要我们进行遍历探测其Filed来得知,示例如下:
package main
import (
"fmt"
"reflect"
)
type Person struct {
Name string
Age int
Sex string
}
func (p Person) Say(msg string) {
fmt.Println("hello,", msg)
}
func (p Person) PrintInfo() {
fmt.Printf("姓名:%s,年龄:%d,性别:%s\n", p.Name, p.Age, p.Sex)
}
func main() {
p1 := Person{"王二狗", 30, "男"}
GetMessage(p1)
}
// GetMessage 获取input的信息
func GetMessage(input interface{}) {
getType := reflect.TypeOf(input) //先获取input的类型
fmt.Println("get Type is :", getType.Name()) //Person
fmt.Println("get Kind is :", getType.Kind()) //struct
getValue := reflect.ValueOf(input)
fmt.Println("get all Fields is :", getValue) //{王二狗 30 男}
//获取字段
/*
step1:先获取Type对象:reflect.Type,
NumField()
Field(index)
step2:通过Filed()获取每一个Filed字段
step3:Interface(),得到对应的Value
*/
for i := 0; i < getType.NumField(); i++ {
filed := getType.Field(i)
value := getValue.Field(i).Interface() //获取第一个数值
fmt.Printf("字段名称:%s,字段类型:%s,字段数值:%v\n", filed.Name, filed.Type, value)
}
//获取方法
for i := 0; i < getType.NumMethod(); i++ {
method := getType.Method(i)
fmt.Printf("方法名称:%s,方法类型:%v\n", method.Name, method.Type)
}
}
运行结果:
get Type is : Person
get Kind is : struct
get all Fields is : {王二狗 30 男}
字段名称:Name,字段类型:string,字段数值:王二狗
字段名称:Age,字段类型:int,字段数值:30
字段名称:Sex,字段类型:string,字段数值:男
方法名称:PrintInfo,方法类型:func(main.Person)
方法名称:Say,方法类型:func(main.Person, string)
说明
通过运行结果可以得知获取未知类型的interface的具体变量及其类型的步骤为:
- 先获取interface的reflect.Type,然后通过NumField进行遍历
- 再通过reflect.Type的Field获取其Field
- 最后通过Field的Interface()得到对应的value
通过运行结果可以得知获取未知类型的interface的所属方法(函数)的步骤为:
- 先获取interface的reflect.Type,然后通过NumMethod进行遍历
- 再分别通过reflect.Type的Method获取对应的真实的方法(函数)
- 最后对结果取其Name和Type得知具体的方法名
- 也就是说反射可以将“反射类型对象”再重新转换为“接口类型变量”
- struct 或者 struct 的嵌套都是一样的判断处理方式
通过reflect.ValueOf设置实际变量的值
reflect.Value是通过reflect.ValueOf(X)获得的,只有当X是指针的时候,才可以通过reflec.Value修改实际变量X的值,即:要修改反射类型的对象就一定要保证其值是“addressable”的。
这里需要一个方法:
func (v Value) Elem() Value
解释起来就是:Elem返回接口v包含的值或指针v指向的值。如果v的类型不是interface或ptr,它会恐慌。如果v为零,则返回零值。
如果你的变量是一个指针、map、slice、channel、Array。那么你可以使用reflect.Typeof(v).Elem()来确定包含的类型。
package main
import (
"reflect"
"fmt"
)
func main() {
//1.“接口类型变量”=>“反射类型对象”
var circle float64 = 6.28
var icir interface{}
icir = circle
fmt.Println("Reflect : circle.Value = ", reflect.ValueOf(icir)) //Reflect : circle.Value = 6.28
fmt.Println("Reflect : circle.Type = ", reflect.TypeOf(icir)) //Reflect : circle.Type = float64
// 2. “反射类型对象”=>“接口类型变量
v1 := reflect.ValueOf(icir)
fmt.Println(v1) //6.28
fmt.Println(v1.Interface()) //6.28
y := v1.Interface().(float64)
fmt.Println(y) //6.28
//v1.SetFloat(4.13) //panic: reflect: reflect.Value.SetFloat using unaddressable value
//fmt.Println(v1)
//3.修改
fmt.Println(v1.CanSet())//是否可以进行修改
v2 := reflect.ValueOf(&circle) // 传递指针才能修改
v4:=v2.Elem()// 传递指针才能修改,获取Elem()才能修改
fmt.Println(v4.CanSet()) //true
v4.SetFloat(3.14)
fmt.Println(circle) //3.14
}
运行结果:
Reflect : circle.Value = 6.28
Reflect : circle.Type = float64
6.28
6.28
6.28
false
true
3.14
说明
- 需要传入的参数是* float64这个指针,然后可以通过pointer.Elem()去获取所指向的Value,注意一定要是指针。
- 如果传入的参数不是指针,而是变量,那么
- 通过Elem获取原始值对应的对象则直接panic
- 通过CanSet方法查询是否可以设置返回false
- newValue.CantSet()表示是否可以重新设置其值,如果输出的是true则可修改,否则不能修改,修改完之后再进行打印发现真的已经修改了。
- reflect.Value.Elem() 表示获取原始值对应的反射对象,只有原始对象才能修改,当前反射对象是不能修改的
- 也就是说如果要修改反射类型对象,其值必须是“addressable”【对应的要传入的是指针,同时要通过Elem方法获取原始值对应的反射对象】
- struct 或者 struct 的嵌套都是一样的判断处理方式
通过reflect.ValueOf来进行方法的调用
这算是一个高级用法了,前面我们只说到对类型、变量的几种反射的用法,包括如何获取其值、其类型、如果重新设置新值。但是在工程应用中,另外一个常用并且属于高级的用法,就是通过reflect来进行方法【函数】的调用。比如我们要做框架工程的时候,需要可以随意扩展方法,或者说用户可以自定义方法,那么我们通过什么手段来扩展让用户能够自定义呢?关键点在于用户的自定义方法是未可知的,因此我们可以通过reflect来搞定。
示例代码
package main
import (
"fmt"
"reflect"
)
type Person struct {
Name string
Age int
Sex string
}
func (p Person) Say(msg string){
fmt.Println("hello,",msg)
}
func (p Person) PrintInfo(){
fmt.Printf("姓名:%s,年龄:%d,性别:%s\n",p.Name,p.Age,p.Sex)
}
func (p Person) Test(i,j int,s string){
fmt.Println(i,j,s)
}
func main() {
/*
通过反射来进行方法的调用
思路:
step1:接口变量-->对象反射对象:Value
step2:获取对应的方法对象:MethodByName()
step3:将方法对象进行调用:Call()
*/
p1 := Person{"Ruby",20,"男"}
value :=reflect.ValueOf(p1)
fmt.Printf("kind : %s, type:%s\n",value.Kind(),value.Type()) //kind : struct, type:main.Person
methodValue1 :=value.MethodByName("PrintInfo")
fmt.Printf("kind:%s,type:%s\n",methodValue1.Kind(),methodValue1.Type()) //kind:func,type:func()
//没有参数,进行调用
methodValue1.Call(nil) //没有参数,直接写nil
args1 := make([]reflect.Value,0) //或者创建一个空的切片也可以
methodValue1.Call(args1)
methodValue2:=value.MethodByName("Say")
fmt.Printf("kind:%s, type:%s\n",methodValue2.Kind(),methodValue2.Type()) //kind:func, type:func(string)
args2:=[]reflect.Value{reflect.ValueOf("反射机制")}
methodValue2.Call(args2)
methodValue3:=value.MethodByName("Test")
fmt.Printf("kind:%s,type:%s\n",methodValue3.Kind(),methodValue3.Type())//kind:func,type:func(int, int, string)
args3:=[]reflect.Value{reflect.ValueOf(100),reflect.ValueOf(200),reflect.ValueOf("Hello World")}
methodValue3.Call(args3)
}
运行结果:
kind : struct, type:main.Person
kind:func,type:func()
姓名:Ruby,年龄:20,性别:男
姓名:Ruby,年龄:20,性别:男
kind:func, type:func(string)
hello, 反射机制
kind:func,type:func(int, int, string)
100 200 Hello World
通过反射,调用函数
package main
import (
"fmt"
"reflect"
"strconv"
)
func main() {
//函数的反射
/*
思路:函数也是看做接口变量类型
step1:函数--->反射对象,Value
step2:kind-->func
step3:call()
*/
f1 := fun1
value := reflect.ValueOf(f1)
fmt.Printf("kind:%s, type :%s\n", value.Kind(), value.Type()) //kind:func, type :func()
value2 := reflect.ValueOf(fun2)
value3 := reflect.ValueOf(fun3)
fmt.Printf("kind:%s,type:%s\n", value2.Kind(), value2.Type()) //kind:func,type:func(int, string)
fmt.Printf("kind:%s,type:%s\n", value3.Kind(), value3.Type()) //kind:func,type:func(int, string) string
//通过反射调用函数
value.Call(nil)
value2.Call([]reflect.Value{reflect.ValueOf(1000), reflect.ValueOf("张三")})
resultValue := value3.Call([]reflect.Value{reflect.ValueOf(2000), reflect.ValueOf("Ruby")})
fmt.Printf("%T\n", resultValue) //[]reflect.Value
fmt.Println(len(resultValue)) //1
fmt.Printf("kind:%s,type:%s\n", resultValue[0].Kind(), resultValue[0].Type()) //kind:string,type:string
s := resultValue[0].Interface().(string)
fmt.Println(s)
fmt.Printf("%T\n", s)
}
func fun1() {
fmt.Println("我是函数fun1(),无参的...")
}
func fun2(i int, s string) {
fmt.Println("我是函数fun2(),有参的。。", i, s)
}
func fun3(i int, s string) string {
fmt.Println("我是函数fun3(),有参的,也有返回值。。", i, s)
return s + strconv.Itoa(i)
}
运行结果:
kind:func, type :func()
kind:func,type:func(int, string)
kind:func,type:func(int, string) string
我是函数fun1(),无参的...
我是函数fun2(),有参的。。 1000 张三
我是函数fun3(),有参的,也有返回值。。 2000 Ruby
[]reflect.Value
1
kind:string,type:string
Ruby2000
string
结构体
匿名结构体
package main
import (
"fmt"
"reflect"
)
type Animal struct {
Name string
Age int
}
type Cat struct {
Animal
Color string
}
// 获取匿名字段
func main() {
c1 := Cat{Animal{"猫咪", 1}, "白色"}
t1 := reflect.TypeOf(c1)
for i := 0; i < t1.NumField(); i++ {
fmt.Println(t1.Field(i))
/*
{Animal main.Animal 0 [0] true}
{Color string 24 [1] false}
*/
}
// FiledByIndex()的参数是一个切片,第一个数是Animal字段,第二个参数是Animal的第一个字段
f1 := t1.FieldByIndex([]int{0, 0})
f2 := t1.FieldByIndex([]int{0, 1})
fmt.Println(f1) //{Name string 0 [0] false}
fmt.Println(f2) //{Age int 16 [1] false}
v1 := reflect.ValueOf(c1)
fmt.Println(v1.Field(0)) //{猫咪 1}
fmt.Println(v1.FieldByIndex([]int{0, 0})) //猫咪
}
运行结果:
{Animal main.Animal 0 [0] true}
{Color string 24 [1] false}
{Name string 0 [0] false}
{Age int 16 [1] false}
{猫咪 1}
猫咪
通过反射,修改结构体的数据
示例代码:
package main
import (
"reflect"
"fmt"
)
type Student struct {
Name string
Age int
School string
}
func main() {
/*
修改内容
*/
s1:= Student{"王二狗",18,"清华大学"}
v1 := reflect.ValueOf(&s1)
if v1.Kind() ==reflect.Ptr && v1.Elem().CanSet(){
v1 = v1.Elem()
fmt.Println("可以修改。。")
}
f1:=v1.FieldByName("Name")
fmt.Println(f1.CanSet())
f1.SetString("王三狗")
f2:=v1.FieldByName("Age")
fmt.Println(f2.CanSet())
f2.SetInt(20)
fmt.Println(s1)
}
运行结果:
可以修改。。
true
true
{王三狗 20 清华大学}





![golangd\pycharm-ai免费代码助手安装使用gpt4-免费使用--[推荐]](https://img-blog.csdnimg.cn/5c495b2d60d441d0a337152c54086d14.png)