链接的接口——符号
链接过程的本质就是要把多个不同的目标文件之间相互“粘”到一起,或者说像玩具积木一样,可以拼装形成一个整体。为了使不同目标文件之间能够相互粘合,这些目标文件之间必须有固定的规则才行,就像积木模块必须有凹凸部分才能够拼合。在链接中,目标文件之间相互拼合实际上是目标文件之间对地址的引用,即对函数和变量的地址的引用。比如目标文件B要用到了目标文件A中的函数“foo”,那么我们就称目标文件A定义(Define) 了函数“foo”,称目标文件B引用(Reference) 了目标文件A中的函数“foo”。这两个概念也同样适用于变量。每个函数或变量都有自己独特的名字,才能避免链接过程中不同变量和函数之间的混淆。在链接中,我们将函数和变量统称为符号(Symbol),函数名或变量名就是符号名(Symbol Name)。
我们可以将符号看作是链接中的粘合剂,整个链接过程正是基于符号才能够正确完成。链接过程中很关键的一部分就是符号的管理,每一个目标文件都会有一个相应的符号表(Symbol Table),这个表里面记录了目标文件中所用到的所有符号。每个定义的符号有一个对应的值,叫做符号值(Symbol Value),对于变量和函数来说,符号值就是它们的地址。除了函数和变量之外,还存在其他几种不常用到的符号。我们将符号表中所有的符号进行分类,它们有可能是下面这些类型中的一种:
1.定义在本目标文件的全局符号,可以被其他目标文件引用。比如SimpleSection.o里面的“func1”、“main”和“global_init_var”。
2.在本目标文件中引用的全局符号,却没有定义在本目标文件,这一般叫做外部符号(External Symbol),也就是我们前面所讲的符号引用。比如 SimpleSection.o 里面的“printf”。
3.段名,这种符号往往由编译器产生,它的值就是该段的起始地址。比如SimpleSection.o里面的“.text”、“.data”等。
4.局部符号,这类符号只在编译单元内部可见。比如SimpleSection.o里面的“static_var"和“static_var2”。调试器可以使用这些符号来分析程序或崩溃时的核心转储文件。这些局部符号对于链接过程没有作用,链接器往往也忽略它们。
5.行号信息,即目标文件指令与源代码中代码行的对应关系,它也是可选的。
对于我们来说,最值得关注的就是全局符号,即上面分类中的第一类和第二类。因为链接过程只关心全局符号的相互“粘合”,局部符号、段名、行号等都是次要的,它们对于其他目标文件来说是“不可见”的,在链接过程中也是无关紧要的。我们可以使用很多工具来查看ELF文件的符号表,比如readelf、objdump、nm等,比如使用“nm”来查看“SimpleSection.o”的符号结果如下:
nm SimpleSection.o

1.ELF符号表结构
ELF文件中的符号表往往是文件中的一个段,段名一般叫“.symtab”。符号表的结构很简单,它是一个 Elf32_Sym结构(32位ELF文件)的数组,每个Elf32_Sym结构对应一个符号。这个数组的第一个元素,也就是下标0的元素为无效的“未定义”符号。Elf32_Sym的结构定义如下:
typedef struct{
Elf32_Word st_name;
Elf32_Addr st_value;
Elf32_Word st_size;
unsigned char st_into;
unsigned char st_other;
Elf32_Half st_shndx;
}Elf32_Sym;
这几个成员的定义如下所示:

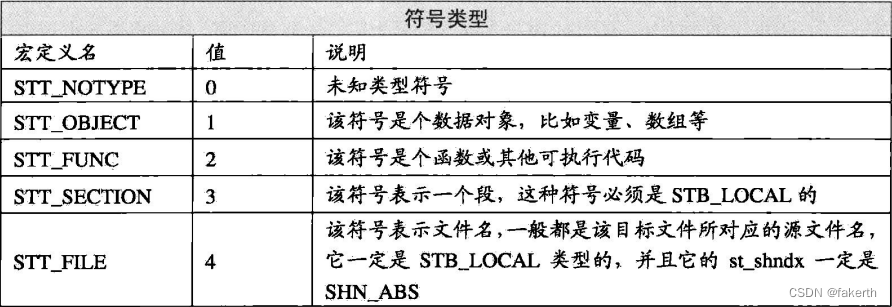
符号类型和绑定信息(st_info) 该成员低4位表示符号的类型(Symbol Type),高28位表示符号绑定信息(Symbol Binding),如下所示:

符号所在段(st_shndx) 如果符号定义在本目标文件中,那么这个成员表示符号所在的段在段表中的下标;但是如果符号不是定义在本目标文件中,或者对于有些特殊符号,sh_shndx的值有些特殊,如图所示:

符号值(st_value) 我们前面已经介绍过,每个符号都有一个对应的值,如果这个符号是一个函数或变量的定义,那么符号的值就是这个函数或变量的地址,更准确地讲应该按下面这几种情况区别对待。
1.主目标文件中,如果是符号的定义并且该符号不是“COMMON块”类型的(即st_shndx不为SHN_COMMON),则st_value表示该符号在段中的偏移。即符号所对应的函数或变量位于由st_shndx 指定的段,偏移st_value的位置。这也是目标文件中定义全局变量的符号的最常见情况,比如SimpleSection.o中的“func1"、“main”和“global_init_var”。
2.在目标文件中,如果符号是“COMMON块”类型的(即st_shndx为 SHN_COMMON),则st_value表示该符号的对齐属性。比如SimpleSection.o中的“global_uninit_var”。
3.在可执行文件中,st_value表示符号的虚拟地址。这个虚拟地址对于动态链接器来说十分有用。
根据上面的介绍,我们对ELF文件的符号表有了大致的了解,接着将以 SimpleSection.o里面的符号为例子,分析各个符号在符号表中的状态。这里使用readelf工具来查看ELF文件的符号:
readelf -s SimpleSection.o
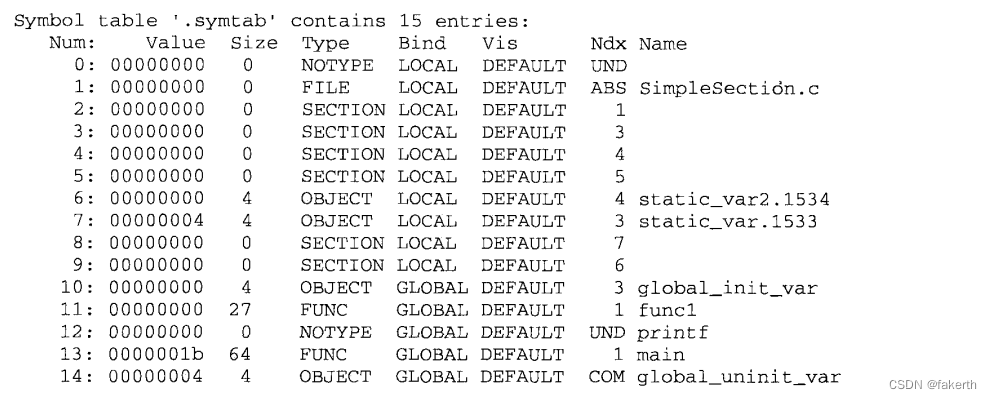
readelf的输出格式与上面描述的Elf32_Sym的各个成员几乎一一对应,第一列Num表示符号表数组的下标,从О开始,共15个符号;第二列Value就是符号值,即st_value;第三列Size为符号大小,即st_size;第四列和第五列分别为符号类型和绑定信息,即对应st_info的低4位和高28位;第六列Vis目前在C/C++语言中未使用,我们可以暂时忽略它;第七列Ndx即st_shndx,表示该符号所属的段;当然最后一列也最明显,即符号名称。从上面的输出可以看到,第一个符号,即下标为0的符号,永远是一个未定义的符号。对于另外几个符号解释如下:
1.func1和main函数都是定义在SimpleSection.c里面的,它们所在的位置都为代码段,所以Ndx为1,即SimpleSection.o里面,.text段的下标为1。这一点可以通过readelf -a或objdump -x得到验证。它们是函数,所以类型是STT_FUNC;它们是全局可见的,所以是STB_GLOBAL;Size表示函数指令所占的字节数;Value表示函数相对于代码段起始位置的偏移量。
2.再来看printf这个符号,该符号在SimpleSection.c里面被引用,但是没有被定义。所以它的Ndx是SHN_UNDEF。
3.global_init_var是已初始化的全局变量,它被定义在.bss 段,即下标为3。
4.global_init_var是已初始化的全局变量,它被定义在.bss段,即下标为3。
5.global_uninit_var是未初始化的全局变量,它是一个SHN_COMMON类型的符号,它本身并没有存在于BSS 段。
6.static_var.1533和static_var2.1534是两个静态变量,它们的绑定属性是STB_LOCAL,即只是编译单元内部可见。
7.对于那些STT_SECTION类型的符号,它们表示下标为Ndx 的段的段名。它们的符号名没有显示,其实它们的符号名即它们的段名。比如2号符号的Ndx为 1,那么它即表示.text段的段名,该符号的符号名应该就是“.text”。如果我们使用“objdump -t”就可以清楚地看到这些段名符号。
8.“SimpleSection.c”这个符号表示编译单元的源文件名。
2.特殊符号
当我们使用ld作为链接器来链接生产可执行文件时,它会为我们定义很多特殊的符号,这些符号并没有在你的程序中定义,但是你可以直接声明并且引用它,我们称之为特殊符号。其实这些符号是被定义在ld链接器的链接脚本中的。链接器会在将程序最终链接成可执行文件的时候将其解析成正确的值,注意,只有使用ld链接生产最终可执行文件的时候这些符号才会存在。几个很具有代表性的特殊符号如下:
1.__executable_start,该符号为程序起始地址,注意,不是入口地址,是程序的最开始的地址。
2.__etext或_etext或etext,该符号为代码段结束地址,即代码段最末尾的地址。
3._edata 或edata,该符号为数据段结束地址,即数据段最末尾的地址。
4._end或end,该符号为程序结束地址。
以上地址都为程序被装载时的虚拟地址,我们可以在程序中直接使用这些符号:
/*
* SpecialSymbol.c
*/
#include<stdio.h>
extern char __executable_start[];
extern char etext[],_etext[],__etext[];
extern char edata[],_edata[];
extern char end[],_end[];
int main()
{
printf("Executable Start %X\n",__executable_start);
printf("Text End %X %X %X\n",etext,_etext,__etext);
printf("Data End %X %X\n",edata,_edata);
printf("Executable End %X %X\n",end,_end);
return 0;
}
gcc SpecialSymbol.c -o SpecialSymbol
./SpecialSymbol

3.符号修饰与函数签名
约在20世纪70年代以前,编译器编译源代码产生目标文件时,符号名与相应的变量和函数的名字是一样的。比如一个汇编源代码里面包含了一个函数foo,那么汇编器将它编译成目标文件以后,foo在目标文件中的相对应的符号名也是foo。当后来UNIX平台和C语言发明时,已经存在了相当多的使用汇编编写的库和目标文件。这样就产生了一个问题,那就是如果一个C程序要使用这些库的话,C语言中不可以使用这些库中定义的函数和变量的名字作为符号名,否则将会跟现有的目标文件冲突。比如有个用汇编编写的库中定义了一个函数叫做main,那么我们在C语言里面就不可以再定义一个main函数或变量了。同样的道理,如果一个C语言的目标文件要用到一个使用Fortran语言编写的目标文件,我们也必须防止它们的名称冲突。
为了防止类似的符号名冲突,UNIX下的C语言就规定,C语言源代码文件中的所有全局的变量和函数经过编译以后,相对应的符号名前加上下划线“”。而Fortran语言的源代码经过编译以后,所有的符号名前加上“”,后面也加上“_”。比如一个C语言函数“foo”,那么它编译后的符号名就是“._foo”;如果是Fortran语言,就是“ _ foo _ ”。
这种简单而原始的方法的确能够暂时减少多种语言目标文件之间的符号冲突的概率,但还是没有从根本上解决符号冲突的问题。比如同一种语言编写的目标文件还有可能会产生符号冲突,当程序很大时,不同的模块由多个部门(个人)开发,它们之间的命名规范如果不严格,则有可能导致冲突。于是像C++这样的后来设计的语言开始考虑到了这个问题,增加了名称空间(Namespace) 的方法来解决多模块的符号冲突问题。
但是随着时间的推移,很多操作系统和编译器被完全重写了好几遍,比如UNIX也分化成了很多种,整个环境发生了很大的变化,上面所提到的跟Fortran 和古老的汇编库的符号冲突问题已经不是那么明显了。在现在的Linux下的GCC编译器中,默认情况下已经去掉了在C语言符号前加“ _ ”的这种方式;但是Windows平台下的编译器还保持的这样的传统,比如Visual C++编译器就会在C语言符号前加“ _ ”,GCC在 Windows平台下的版本(cygwin、mingw)也会加“ _ ”。GCC编译器也可以通过参数选项“-fleading-underscore”或“-fno-leading-underscore”来打开和关闭是否在C语言符号前加上下划线。
C++修饰
众所周知,强大而又复杂的C++拥有类、继承、虚机制、重载、名称空间等这些特性,它们使得符号管理更为复杂。最简单的例子,两个相同名字的函数func(int)和 func(double),尽管函数名相同,但是参数列表不同,这是C++里面函数重载的最简单的一种情况,那么编译器和链接器在链接过程中如何区分这两个函数呢?为了支持C++这些复杂的特性,人们发明了符号修饰(Name Decoration) 或符号改编(Name Mangling) 的机制,下面我们来看看C++的符号修饰机制。
首先出现的一个问题是C++允许多个不同参数类型的函数拥有一样的名字,就是所谓的函数重载;另外C++还在语言级别支持名称空间,即允许在不同的名称空间有多个同样名字的符号。比如下面这段代码:
int func(int);
float func(float);
class C{
int func(int);
class C2{
int func(int);
};
};
namespace N{
int func(int);
class C{
int func(int);
};
}
这段代码中有6个同名函数叫func,只不过它们的返回类型和参数及所在的名称空间不同。我们引入一个术语叫做函数签名(Function Signature),函数签名包含了一个函数的信息,包括函数名、它的参数类型、它所在的类和名称空间及其他信息。函数签名用于识别不同的函数,就像签名用于识别不同的人一样,函数的名字只是函数签名的一部分。由于上面6个同名函数的参数类型及所处的类和名称空间不同,我们可以认为它们的函数签名不同。在编译器及链接器处理符号时,它们使用某种名称修饰的方法,使得每个函数签名对应一个修饰后名称(Decorated Name)。编译器在将C++源代码编译成目标文件时,会将函数和变量的名字进行修饰,形成符号名,也就是说,C++的源代码编译后的目标文件中所使用的符号名是相应的函数和变量的修饰后名称。C++编译器和链接器都使用符号来识别和处理函数和变量,所以对于不同函数签名的函数,即使函数名相同,编译器和链接器都认为它们是不同的函数。上面的6个函数签名在GCC编译器下,相对应的修饰后名称如下示:
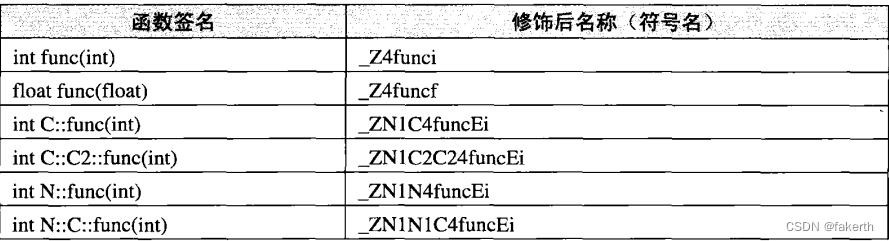
GCC的基本C++名称修饰方法如下:所有的符号都以“Z”开头,对于嵌套的名字(在名称空间或在类里面的),后面紧跟“N”,然后是各个名称空间和类的名字,每个名字前是名字字符串长度,再以“E”结尾。比如 N::C::func经过名称修饰以后就是_ZN1N1C4funcE。对于一个函数来说,它的参数列表紧跟在“E”后面,对于int类型来说,就是字母“i”。所以整个N::C::func(int)函数签名经过修饰为_ZN1N1C4funcEi。更为具体的修饰方法我们在这里不详细介绍,有兴趣的读者可以参考GCC的名称修饰标准。幸好这种名称修饰方法我们平时程序开发中也很少手工分析名称修饰问题,所以无须很详细地了解这个过程。binutils里面提供了一个叫“c++filt”的工具可以用来解析被修饰过的名称,比如:
c++filt -ZN1N1C4funcEi
N::N::func(int)
签名和名称修饰机制不光被使用到函数上,C++中的全局变量和静态变量也有同样的机制。对于全局变量来说,它跟函数一样都是一个全局可见的名称,它也遵循上面的名称修饰机制,比如一个名称空间foo中的全局变量bar,它修饰后的名字为:_ZN3foo3barE。值得注意的是,变量的类型并没有被加入到修饰后名称中,所以不论这个变量是整形还是浮点型甚至是一个全局对象,它的名称都是一样的。
名称修饰机制也被用来防止静态变量的名字冲突。比如main()函数里面有一个静态变量叫foo,而 func()函数里面也有一个静态变量叫foo。为了区分这两个变量,GCC会将它们的符号名分别修饰成两个不同的名字_ZZ4mainE3foo和_ZZ4funcvE3foo,这样就区分了这两个变量。
不同的编译器厂商的名称修饰方法可能不同,所以不同的编译器对于同一个函数签名可能对应不同的修饰后名称。比如上面的函数签名中在Visual C++编译器下,它们的修饰后名称如下所示:
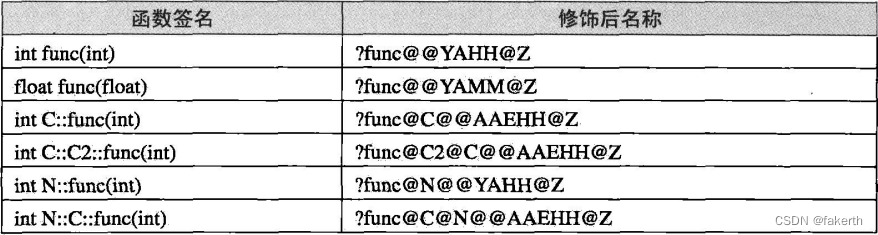
我们以int N::C::func(int)这个函数签名来猜测Visual C++的名称修饰规则。修饰后名字由“?”开头,接着是函数名由“@”符号结尾的函数名;后面跟着由“@”结尾的类名“C”和名称空间“N",再一个“@”表示函数的名称空间结束;第一个“A”表示函数调用类型为“__cdecl”,接着是函数的参数类型及返回值,由“@”结束,最后由“Z”结尾。可以看到函数名、参数的类型和名称空闾都被加入了修饰后名称,这样编译器和链接器就可以区别同名但不同参数类型或名字空间的函数,而不会导致link的时候函数多重定义。
Visual C++的名称修饰规则并没有对外公开,当然,一般情况下我们也无须了解这套规则,但是有时候可能须要将一个修饰后名字转换成函数签名,比如在链接、调试程序的时候可能会用到。Microsoft提供了一个UnDecorateSymbolName()的API,可以将修饰后名称转换成函数签名。
4.extern “C”
C++为了与C兼容,在符号的管理上,C++有一个用来声明或定义一个C的符号的“extern“C””关键字用法:
extern "C"{
int func(int);
int var;
}
C++编译器会将在extern“C”的大括号内部的代码当作C语言代码处理。所以很明显,上面的代码中,C++的名称修饰机制将不会起作用。它声明了一个C的函数func,定义了一个整形全局变量var。从上文我们得知,在Visual C++平台下会将C语言的符号进行修饰,所以上述代码中的func和 var的修饰后符号分别是_func和_var;但是在Linux版本的GCC编译器下却没有这种修饰,extern“C”里面的符号都为修饰后符号,即前面不用加下划线。如果单独声明某个函数或变量为C语言的符号,那么也可以使用如下格式:
extern "C" int func(int);
extern "C" int var;
上面的代码声明了一个C语言的函数func和变量var。我们可以使用上述的机制做一个小实验:
//ManualNameMangling.cpp
//g++ ManualNameMangling.cpp -o ManualNameMangling
#include<stdio.h>
namespace myname{
int var = 42;
}
extern "C" double _ZN6myname3varE;
int main(){
printf("%d\n",_ZN6myname3varE);
return 0;
}
上面的代码中,我们在myname的名称空间中定义了一个全局变量var。根据我们所掌握的GCC名称修饰规则,这个变量修饰后的名称为“_ZN6myname3varE”,然后我们手工使用extern “C”的方法声明一个外部符号_ZN6myname3varE,并将其打印出来。我们使用GCC来编译这个程序并且运行它,我们就可以得到程序输出为42:
g++ ManualNameMangling.cpp -o ManualNameMangling
./ManualNameMangling
很多时候我们会碰到有些头文件声明了一些C语言的函数和全局变量,但是这个头文件可能会被C语言代码或C++代码包含。比如很常见的,我们的C语言库函数中的 string.h中声明了memset这个函数,它的原型如下:
void *memset(void*,int,size_t);
如果不加任何处理,当我们的C语言程序包含string.h的时候,并且用到了memset这个函数,编译器会将memset符号引用正确处理;但是在C++语言中,编译器会认为这个memset函数是一个C++函数,将memset 的符号修饰成_Z6memsetPvii,这样链接器就无法与C语言库中的memset符号进行链接。所以对于C++来说,必须使用extern “C”来声明memset 这个函数。但是C语言又不支持extern “C”语法,如果为了兼容C语言和C++语言定义两套头文件,未免过于麻烦。幸好我们有一种很好的方法可以解决上述问题,就是使用C++的宏“_cplusplus”,C++编译器会在编译C++的程序时默认定义这个宏,我们可以使用条件宏来判断当前编译单元是不是C++代码。具体代码如下:
#ifdef __cplusplus
extern "C"{
#endif
void *memset(void*,int,size_t);
#ifdef __cplusplus
}
#endif
如果当前编译单元是C++代码,那么memset会在extern “C”里面被声明;如果是C代码,就直接声明。上面这段代码中的技巧几乎在所有的系统头文件里面都被用到。
5.弱符号与强符号
我们经常在编程中碰到一种情况叫符号重复定义。多个目标文件中含有相同名字全局符号的定义,那么这些目标文件链接的时候将会出现符号重复定义的错误。比如我们在目标文件A和目标文件B都定义了一个全局整形变量global,并将它们都初始化,那么链接器将A和B进行链接时会报错:

这种符号的定义可以被称为强符号(Strong Symbol)。有些符号的定义可以被称为弱符号( Weak Symbol)。对于C/C++语言来说,编译器默认函数和初始化了的全局变量为强符号,未初始化的全局变量为弱符号。我们也可以通过GCC的“attribute((weak))”来定义任何一个强符号为弱符号。注意,强符号和弱符号都是针对定义来说的,不是针对符号的引用。比如我们有下面这段程序:
extern int ext;
int weak;
int strong = 1;
__attribute__((weak)) weak2 = 2;
int main(){
return 0;
}
上面这段程序中,“weak”和“weak2”是弱符号,“strong”和“main”是强符号,而“ext”既非强符号也非弱符号,因为它是一个外部变量的引用。针对强弱符号的概念,链接器就会按如下规则处理与选择被多次定义的全局符号:
1.不允许强符号被多次定义(即不同的目标文件中不能有同名的强符号);如果有多个强符号定义,则链接器报符号重复定义错误。
2.如果一个符号在某个目标文件中是强符号,在其他文件中都是弱符号,那么选择强符号。
3.如果一个符号在所有目标文件中都是弱符号,那么选择其中占用空间最大的一个。比如目标文件A定义全局变量global为int型,占4个字节;目标文件B定义global为double型,占8个字节,那么目标文件A和B链接后,符号global占8个字节(尽量不要使用多个不同类型的弱符号,否则容易导致很难发现的程序错误)。
弱引用和强引用 目前我们所看到的对外部目标文件的符号引用在目标文件被最终链接成可执行文件时,它们须要被正确决议,如果没有找到该符号的定义,链接器就会报符号未定义错误,这种被称为强引用(Strong Reference)。与之相对应还有一种弱引用(WeakReference),在处理弱引用时,如果该符号有定义,则链接器将该符号的引用决议;如果该符号未被定义,则链接器对于该引用不报错。链接器处理强引用和弱引用的过程几乎一样,只是对于未定义的弱引用,链接器不认为它是一个错误。一般对于未定义的弱引用,链接器默认其为0,或者是一个特殊的值,以便于程序代码能够识别。弱引用和弱符号主要用于库的链接过程。
在GCC中,我们可以通过使用“_ attribute _((weakref))”这个扩展关键字来声明对一个外部函数的引用为弱引用,比如下面这段代码:
__attribute__ ((weakref)) void foo();
int main()
{
foo();
}
我们可以将它编译成一个可执行文件,GCC并不会报链接错误。但是当我们运行这个可执行文件时,会发生运行错误。因为当main函数试图调用foo函数时,foo函数的地址为0,于是发生了非法地址访问的错误。一个改进的例子是:
__attribute__ ((weakref)) void foo();
int main()
{
if(foo) foo();
}
这种弱符号和弱引用对于库来说十分有用,比如库中定义的弱符号可以被用户定义的强符号所覆盖,从而使得程序可以使用自定义版本的库函数;或者程序可以对某些扩展功能模块的引用定义为弱引用,当我们将扩展模块与程序链接在一起时,功能模块就可以正常使用;如果我们去掉了某些功能模块,那么程序也可以正常链接,只是缺少了相应的功能,这使得程序的功能更加容易裁剪和组合。
在Linux程序的设计中,如果一个程序被设计成可以支持单线程或多线程的模式,就可以通过弱引用的方法来判断当前的程序是链接到了单线程的Glibc库还是多线程的Glibc库(是否在编译时有-lpthread选项),从而执行单线程版本的程序或多线程版本的程序。我们可以在程序中定义一个pthread_create函数的弱引用,然后程序在运行时动态判断是否链接到pthread库从而决定执行多线程版本还是单线程版本:
#include<stdio.h>
#include<pthread.h>
int pthread_create(pthread_t*,const pthread_attr_t*,void* (*)(void*),void*) __attribute__ ((weak));
int main()
{
if(pthread_create){
printf("This is multi_thread version!\n");
//run the multi-thread version
//main_multi_thread()
}
else {
printf("This is single-thread version!\n");
//run the single-thread version
//main_single_thread()
}
return 0;
}
编译运行结果如下:
gcc pthread.c -o pt
./pt
This is single_thread version!
gcc pthread.c -lpthread -o pt
./pt
This is multi_thread version!
调试信息
目标文件里面还有可能保存的是调试信息。几乎所有现代的编译器都支持源代码级别的调试,比如我们可以在函数里面设置断点,可以监视变量变化,可以单步行进等,前提是编译器必须提前将源代码与目标代码之间的关系等,比如目标代码中的地址对应源代码中的哪一行、函数和变量的类型、结构体的定义、字符串保存到目标文件里面。甚至有些高级的编译器和调试器支持查看STL容器的内容,即程序员在调试过程中可以直接观察STL容器中的成员的值。
如果我们在GCC编译时加上“-g”参数,编译器就会在产生的目标文件里面加上调试信息,我们通过readelf 等工具可以看到,目标文件里多了很多“debug”相关的段:
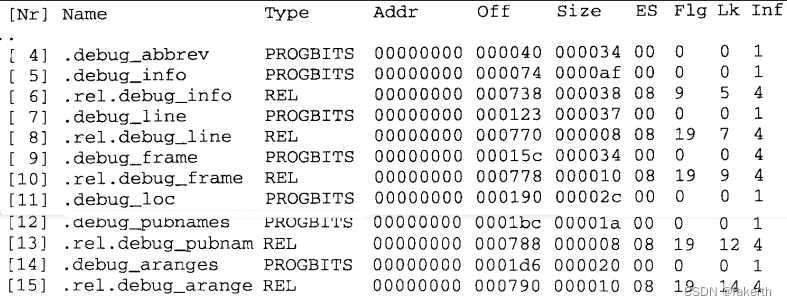
这些段中保存的就是调试信息。现在的 ELF文件采用一个叫DWARF(Debug With Arbitrary Record Format)的标准的调试信息格式,现在该标准已经发展到了第三个版本,即DWARF3,由DWARF标准委员会由2006年颁布。Microsoft也有自己相应的调试信息格式标准,叫CodeView。值得一提的是,调试信息在目标文件和可执行文件中占用很大的空间,往往比程序的代码和数据本身大好几倍,所以当我们开发完程序并要将它发布的时候,须要把这些对于用户没有用的调试信息去掉,以节省大量的空间。在Linux 下,我们可以使用“strip”命令来去掉ELF文件中的调试信息:
strip foo

![[附源码]计算机毕业设计海南琼旅旅游网Springboot程序](https://img-blog.csdnimg.cn/ecb6b1b282614eae8d48c14f15275afa.png)