🎄欢迎来到@边境矢梦°的csdn博文,本文主要讲解Java 中正则表达式 的相关知识🎄
🌈我是边境矢梦°,一个正在为秋招和算法竞赛做准备的学生🌈
🎆喜欢的朋友可以关注一下🫰🫰🫰,下次更新不迷路🎆
Ps: 月亮越亮说明知识点越重要 (重要性或者难度越大)🌑🌒🌓🌔🌕
目录
🌓一. 问题的引出
🌓二. 解决问题
🌒三. 正则表达式的好处
🌕四. 正则表达式语法
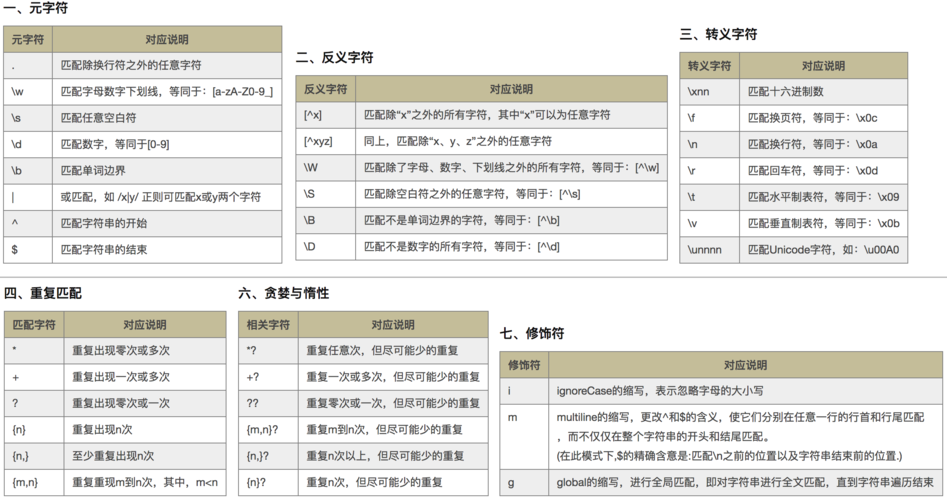
🌔1.限定符
🌔 2.选择匹配符
🌕3.分组组合和反向引用符
🌕4. 特殊字符
🌕5.字符匹配符
🌔6.定位符
🌔五. 修饰符
🌔六. 运算符优先级
🌔七. 元字符
现实中, 检索是非常常见的,为了加快检索速度, 引出了正则表达式, 正则表达式是一种强大的文本模式匹配工具,可以用来搜索、识别和提取文本中的特定模式.一个正则表达式,就是用某种模式去匹配字符串的一个公式。很多人因为它们看上去比较古怪而且复杂所以不敢去使用,不过,经过练习后,就觉得这些复杂的表达式写起来还是相当简单的,而且,一旦你弄懂它们,你就能把数小时辛苦而且易错的文本处理工作缩短在几分钟(甚至几秒钟)内完成.
一. 问题的引出
当不使用正则表达式时,以下示例说明可能会遇到的缺点:
- 代码复杂度提高:
// 字符串验证(电子邮件地址)
String email = "test@example.com";
if (email.contains("@")) {
String[] parts = email.split("@");
if (parts.length == 2) {
String domain = parts[1];
if (domain.contains(".") && domain.length() > 2) {
System.out.println("Valid email address");
}
}
}
相比使用正则表达式,上述代码需要多个条件判断和字符串操作来验证电子邮件地址的合法性,使得代码变得冗长且可读性较差。
- 可读性降低:
// 提取文本中的所有日期(格式为YYYY-MM-DD)
String text = "Today is 2023-07-28. Tomorrow will be 2023-07-29. Next week is 2023-08-04.";
String[] words = text.split(" ");
for (String word : words) {
if (word.length() == 10) {
String[] dateParts = word.split("-");
if (dateParts.length == 3 && dateParts[0].length() == 4 && dateParts[1].length() == 2 && dateParts[2].length() == 2) {
try {
int year = Integer.parseInt(dateParts[0]);
int month = Integer.parseInt(dateParts[1]);
int day = Integer.parseInt(dateParts[2]);
if (year >= 1900 && year <= 2099 && month >= 1 && month <= 12 && day >= 1 && day <= 31) {
System.out.println(word);
}
} catch (NumberFormatException e) {
// Ignore invalid dates
}
}
}
}
上述代码在提取文本中的日期时,需要多个条件判断和字符串操作,使得代码变得晦涩难懂,对于日期格式的要求也不易于理解。
- 匹配和处理效率低:
如果需要从一段文本中获取所有以字母 “a” 开头的单词,而不使用正则表达式,可能需要编写如下的代码:
String text = "apple is a fruit, and it tastes amazing. An animal starts with aardvark.";
String[] words = text.split(" ");
for (String word : words) {
if (word.toLowerCase().startsWith("a")) {
System.out.println(word);
}
}
由于需要对每一个单词进行字符串操作和条件判断,代码的效率较低,尤其是在处理大量文本时可能会造成性能问题。
- 处理复杂模式困难:
如果需要从 HTML 文档中提取所有的超链接文本和 URL,而不使用正则表达式,可能需要编写复杂的代码来处理各种标签和属性:
String html = "<a href=\"https://www.example.com\">Example</a> website. <a href=\"https://www.google.com\">Google</a> search engine.";
int startIndex = html.indexOf("<a");
while (startIndex != -1) {
int endIndex = html.indexOf("</a>", startIndex);
if (endIndex != -1) {
String link = html.substring(startIndex, endIndex);
int urlStartIndex = link.indexOf("href=\"");
if (urlStartIndex != -1) {
urlStartIndex += 6;
int urlEndIndex = link.indexOf("\"", urlStartIndex);
if (urlEndIndex != -1) {
String url = link.substring(urlStartIndex, urlEndIndex);
int textStartIndex = link.indexOf(">", urlEndIndex);
if (textStartIndex != -1) {
textStartIndex += 1;
String text = link.substring(textStartIndex);
System.out.println("URL: " + url + ", Text: " + text);
}
}
}
}
startIndex = html.indexOf("<a", startIndex + 1);
}
上述代码需要进行多次的字符串搜索和子字符串提取,处理起来较为繁琐和不直观。
通过上述示例可以看出,在处理字符串匹配和操作时,不使用正则表达式可能会导致代码复杂度提高、可读性降低、匹配和处理效率降低、处理复杂模式困难等问题。因此,正则表达式的简洁和强大的语法规则可以帮助我们更轻松地处理这些任务,提高代码的效率和可读性。
二. 解决问题
当使用正则表达式来解决前述提到的缺点时,可以得到以下示例:
- 代码复杂度提高:
// 字符串验证(电子邮件地址)
String email = "test@example.com";
String pattern = "^[a-zA-Z0-9]+@[a-zA-Z0-9]+(\\.[a-zA-Z]{2,})+$";
if (email.matches(pattern)) {
System.out.println("Valid email address");
}
通过使用正则表达式,可以将复杂的验证逻辑简化为一行代码,使代码更加简洁和易读。
- 可读性降低:
// 提取文本中的所有日期(格式为YYYY-MM-DD)
String text = "Today is 2023-07-28. Tomorrow will be 2023-07-29. Next week is 2023-08-04.";
String pattern = "\\d{4}-\\d{2}-\\d{2}";
Pattern regex = Pattern.compile(pattern);
Matcher matcher = regex.matcher(text);
while (matcher.find()) {
String date = matcher.group();
System.out.println(date);
}
使用正则表达式提取日期时,通过使用简洁明了的正则表达式模式,可以更清晰地表达我们所需的日期格式要求。
- 匹配和处理效率低:
// 获取所有以字母 "a" 开头的单词
String text = "apple is a fruit, and it tastes amazing. An animal starts with aardvark.";
String pattern = "\\ba\\w*\\b";
Pattern regex = Pattern.compile(pattern);
Matcher matcher = regex.matcher(text);
while (matcher.find()) {
String word = matcher.group();
System.out.println(word);
}
通过使用正则表达式,可以利用其内部的优化算法,提高匹配和处理效率,避免了对每个单词进行字符串操作和条件判断的情况。
- 处理复杂模式困难:
// 从 HTML 文档中提取超链接文本和 URL
String html = "<a href=\"https://www.example.com\">Example</a> website. <a href=\"https://www.google.com\">Google</a> search engine.";
String pattern = "<a\\s+href=\"([^\"]+)\"[^>]*>(.*?)</a>";
Pattern regex = Pattern.compile(pattern);
Matcher matcher = regex.matcher(html);
while (matcher.find()) {
String url = matcher.group(1);
String text = matcher.group(2);
System.out.println("URL: " + url + ", Text: " + text);
}
通过使用正则表达式,可以有效地处理复杂的模式,一次性提取出超链接的文本和 URL,不需要手动解析和提取标签和属性。
通过上述示例,使用正则表达式可以简化代码,提高可读性,并提供更高效和简洁的解决方案来处理字符串的匹配和操作。
三. 正则表达式的好处
学习正则表达式的好处有以下几个方面:
-
文本匹配和搜索:正则表达式是一种强大的文本模式匹配工具,可以用来搜索、识别和提取文本中的特定模式。通过学习正则表达式,可以更高效地处理文本数据,实现自动化的文本处理和分析。
-
数据验证和过滤:正则表达式广泛用于验证和过滤输入数据。可以利用正则表达式定义特定的模式要求,对用户输入的数据进行合法性验证,防止恶意输入和代码注入等安全问题。
-
字符串操作和替换:正则表达式提供了强大的字符串操作功能,可以实现字符串的查找、替换、切割等操作。通过学习正则表达式,可以编写灵活且高效的字符串处理代码,提高开发效率。
-
数据提取和分析:当处理非结构化的文本数据时,正则表达式可以帮助从中提取出所需信息。例如,从日志文件中提取出特定格式的日志记录,从 HTML 文档中提取出特定标签的内容等。学习正则表达式可以使数据提取和分析更加便捷和准确。
-
编程语言和工具支持:正则表达式是许多编程语言和工具的一部分,包括Java、JavaScript、Python、Perl等。学习正则表达式可以使得在编程中能够更好地利用和应用正则表达式,实现更高级的文本处理功能。
总体来说,学习正则表达式可以提升文本处理和数据操作的能力,减少重复工作,简化代码逻辑,并且广泛应用于软件开发、数据分析、文本处理等领域。无论是在后端开发、数据科学还是网络安全等领域,掌握正则表达式都是一项有价值的技能。
四. 正则表达式语法
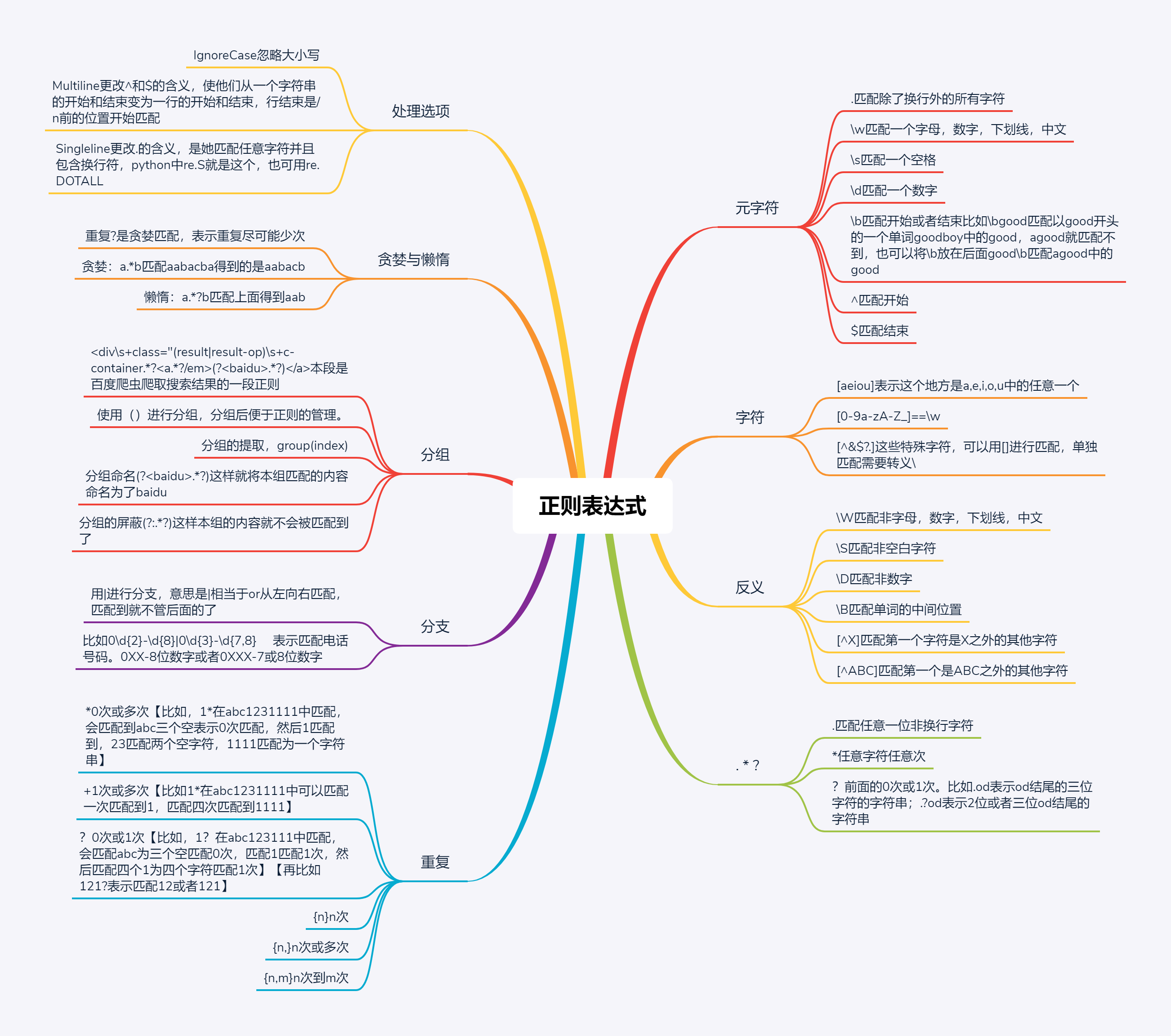
1.限定符
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于 {0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,zo+ 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
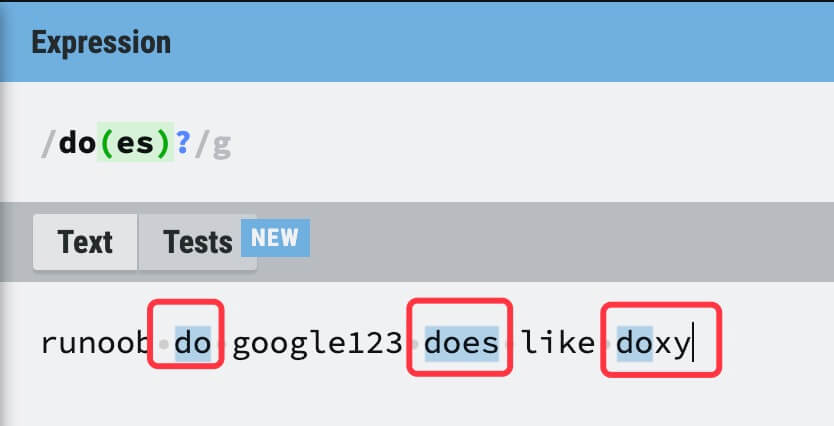
| ? | 匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 "do" 、 "does"、 "doxy" 中的 "do" 和 "does"。? 等价于 {0,1}。
|
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,o{2} 不能匹配 "Bob" 中的 o,但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,o{2,} 不能匹配 "Bob" 中的 o,但能匹配 "foooood" 中的所有 o。o{1,} 等价于 o+。o{0,} 则等价于 o*。 |
| {n,m} | m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3} 将匹配 "fooooood" 中的前三个 o。o{0,1} 等价于 o?。请注意在逗号和两个数之间不能有空格。 |
2.选择匹配符
| | | 指明两项之间的一个选择。要匹配 |,请使用 \|。 |
3.分组组合和反向引用符
分组由圆括号 () 定义,在其中可以放置一个子表达式或多个模式。这些模式可以按照所需的方式组合在一起。
反向引用符 \ 后跟分组的编号用于引用先前匹配的子字符串。分组的编号从左到右,从 1 开始。
var str = "apple apple banana";
// 匹配两个相同的单词
var pattern1 = /(\w+) \1/;
console.log(str.match(pattern1));
// 输出: ["apple apple", "apple"]
// 匹配连续出现的相同字符
var pattern2 = /(\w)\1+/g;
console.log(str.match(pattern2));
// 输出: ["pp", "pp", "n"]
// 匹配重复出现的单词
var pattern3 = /\b(\w+)\b\s+\1\b/g;
console.log(str.match(pattern3));
// 输出: ["apple apple"]在上述示例中:
(\w+)是第一个分组,匹配一个或多个连续的单词字符。\1是对第一个分组的反向引用,确保第一个分组中的内容在字符串中再次出现。(\w)\1+匹配连续出现的相同字符,例如 “pp” 和 “n”。\b(\w+)\b\s+\1\b匹配重复出现的单词,在单词之间可能有空白字符。\b是单词边界,\s+匹配一个或多个空白字符。
分组组合和反向引用可以提供更高级的模式匹配和处理能力,尤其在需要匹配重复出现的内容或需要引用先前匹配的内容时非常有用。但请注意,不同的编程语言和工具在处理反向引用时可能有细微差异,因此要确保在特定环境中正确使用它们。
4. 特殊字符
| 特别字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。要匹配 $ 字符本身,请使用 \$。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 \[。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\\' 匹配 "\",而 '\(' 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 \^。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 \{。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 \|。 |
5.字符匹配符
\d:匹配一个数字字符。等效于[0-9]。\D:匹配一个非数字字符。等效于[^0-9]。\w:匹配一个单词字符(字母、数字、下划线)。等效于[A-Za-z0-9_]。\W:匹配一个非单词字符。等效于[^A-Za-z0-9_]。\s:匹配一个空白字符(空格、制表符、换行符等)。等效于[\t\n\r\f\v]。\S:匹配一个非空白字符。等效于[^\t\n\r\f\v]。.:匹配除换行符以外的任意字符。[ ]:字符类,匹配括号内的任意一个字符。[^ ]:否定字符类,匹配除了括号内的字符以外的任意字符。
var str = "123 abc $%^";
// 匹配一个数字字符
var pattern1 = /\d/;
console.log(str.match(pattern1));
// 输出: ["1"]
// 匹配一个非数字字符
var pattern2 = /\D/;
console.log(str.match(pattern2));
// 输出: [" "]
// 匹配一个单词字符
var pattern3 = /\w/;
console.log(str.match(pattern3));
// 输出: ["1"]
// 匹配一个非单词字符
var pattern4 = /\W/;
console.log(str.match(pattern4));
// 输出: [" "]
// 匹配一个空白字符
var pattern5 = /\s/;
console.log(str.match(pattern5));
// 输出: [" "]
// 匹配一个非空白字符
var pattern6 = /\S/;
console.log(str.match(pattern6));
// 输出: ["1"]
// 匹配除换行符以外的任意字符
var pattern7 = /./g;
console.log(str.match(pattern7));
// 输出: ["1", "2", "3", " ", "a", "b", "c", " ", "$", "%", "^"]
// 匹配 "a"、"b" 或 "c"
var pattern8 = /[abc]/;
console.log(str.match(pattern8));
// 输出: ["a"]
// 匹配非数字和非字母的任意字符
var pattern9 = /[^a-zA-Z0-9]/g;
console.log(str.match(pattern9));
// 输出: [" ", " ", "$", "%", "^"]6.定位符
| 字符 | 描述 |
|---|---|
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
| \B | 非单词边界匹配。 |
五. 修饰符
标记也称为修饰符,正则表达式的标记用于指定额外的匹配策略。
标记不写在正则表达式里,标记位于表达式之外,格式如下:
/pattern/flags
以下是一些常见的正则表达式修饰符:
i:忽略大小写。添加i修饰符后,正则表达式匹配将不区分大小写。g:全局匹配。添加g修饰符后,正则表达式将会匹配字符串中所有的匹配项,而不仅仅是第一个。m:多行匹配。添加m修饰符后,正则表达式将会跨越多行进行匹配,而不仅仅是单行。s:单行匹配。添加s修饰符后,.元字符将匹配包括换行符在内的任何字符。u:Unicode 匹配。添加u修饰符后,正则表达式将使用 Unicode 模式进行匹配。
修饰符通常被放置在正则表达式的斜杠 / 后面。
以下是使用正则表达式修饰符的一些示例:
var str = "Hello world!";
// 使用 "i" 修饰符忽略大小写
var pattern1 = /hello/i;
console.log(pattern1.test(str));
// 输出: true
// 使用 "g" 修饰符全局匹配
var pattern2 = /o/g;
console.log(str.match(pattern2));
// 输出: ["o", "o"]
// 使用 "m" 修饰符多行匹配
var pattern3 = /^w/m;
console.log(str.match(pattern3));
// 输出: ["w"]
// 使用 "s" 修饰符单行匹配
var pattern4 = /o.s/;
console.log(str.match(pattern4));
// 输出: ["orld"]
// 使用 "u" 修饰符 Unicode 匹配
var pattern5 = /\u{1F600}/u;
console.log(pattern5.test(str));
// 输出: false
请注意,修饰符在不同的编程语言和工具中可能略有不同
六. 运算符优先级
| 运算符 | 描述 |
|---|---|
| \ | 转义符 |
| (), (?:), (?=), [] | 圆括号和方括号 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, $, \任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
| | | 替换,"或"操作 字符具有高于替换运算符的优先级,使得"m|food"匹配"m"或"food"。若要匹配"mood"或"food",请使用括号创建子表达式,从而产生"(m|f)ood"。 |
七. 元字符
| 字符 | 描述 |
|---|---|
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,'n' 匹配字符 "n"。'\n' 匹配一个换行符。序列 '\\' 匹配 "\" 而 "\(" 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个 "o",而 'o+' 将匹配所有 'o'。 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用像"(.|\n)"的模式。 |
| (pattern) | 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 '\(' 或 '\)'。 |
| (?:pattern) | 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 "或" 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 'industry|industries' 更简略的表达式。 |
| (?=pattern) | 正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,"Windows(?=95|98|NT|2000)"能匹配"Windows2000"中的"Windows",但不能匹配"Windows3.1"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如"Windows(?!95|98|NT|2000)"能匹配"Windows3.1"中的"Windows",但不能匹配"Windows2000"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?<=pattern) | 反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。例如,"(?<=95|98|NT|2000)Windows"能匹配"2000Windows"中的"Windows",但不能匹配"3.1Windows"中的"Windows"。 |
| (?<!pattern) | 反向否定预查,与正向否定预查类似,只是方向相反。例如"(?<!95|98|NT|2000)Windows"能匹配"3.1Windows"中的"Windows",但不能匹配"2000Windows"中的"Windows"。 |
| x|y | 匹配 x 或 y。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'、'l'、'i'、'n'。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,'[^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \cx | 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
| \w | 匹配字母、数字、下划线。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配非字母、数字、下划线。等价于 '[^A-Za-z0-9_]'。 |
| \xn | 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,'\x41' 匹配 "A"。'\x041' 则等价于 '\x04' & "1"。正则表达式中可以使用 ASCII 编码。 |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,'(.)\1' 匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 |
| \nml | 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 |
| \un | 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 |
正则表达式 – 教程 | 菜鸟教程 (runoob.com)