文章目录
- 一、背景
- 二、方法
- 2.1 对新类别的定位 Localization
- 2.2 使用 cropped regions 进行开放词汇检测
- 2.3 ViLD
- 三、效果
论文:Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
代码:https://github.com/tensorflow/tpu/tree/master/models/official/detection/projects/vild
效果:
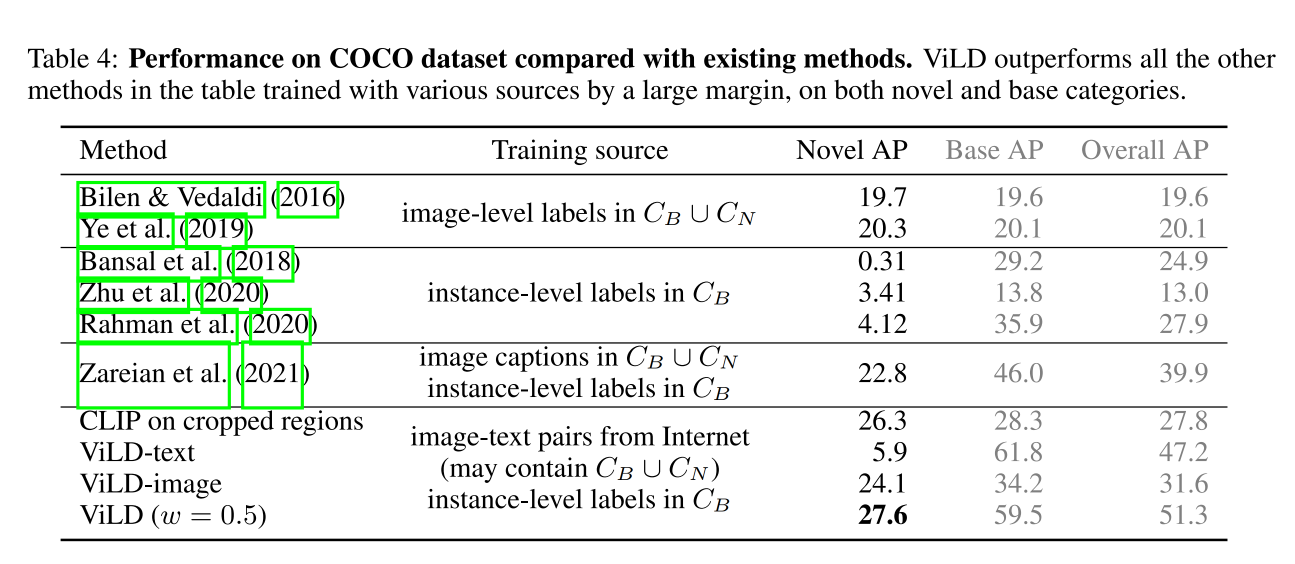
- 在 zero-shot 测试下,coco 达到了 36.6 AP,PASCAL VOC 达到了 72.2AP,Object365 达到了 11.8AP
本文提出了 Vision and Language knowledge Distillation(ViLD):
- 通过将预训练的开集分类模型作为 teacher model,来蒸馏两阶段目标检测器 student model
- 即使用 teacher model 来对 category texts 和 proposal region进行编码
- 然后训练 student detector 来对齐 text 和 region embedding
一、背景
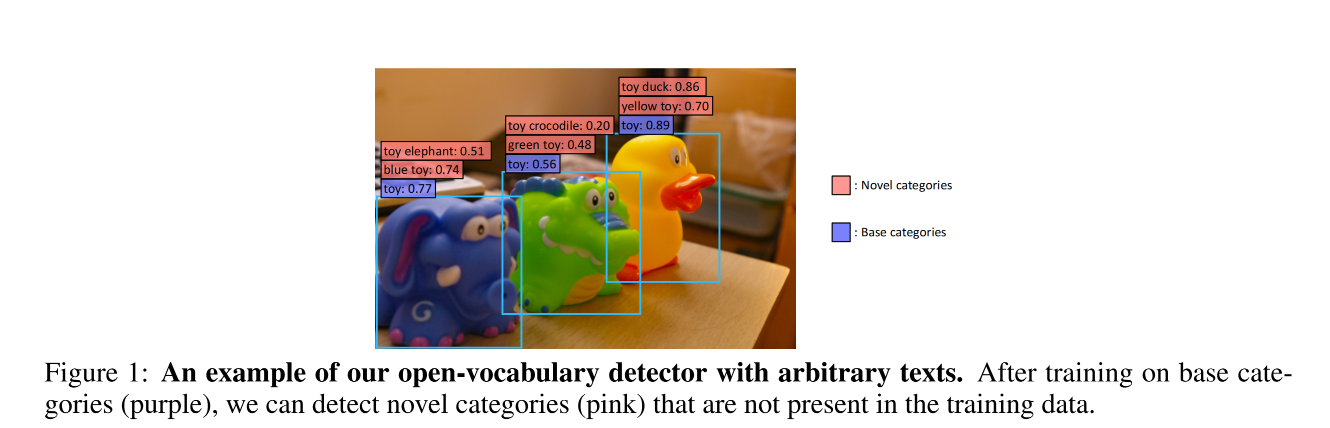
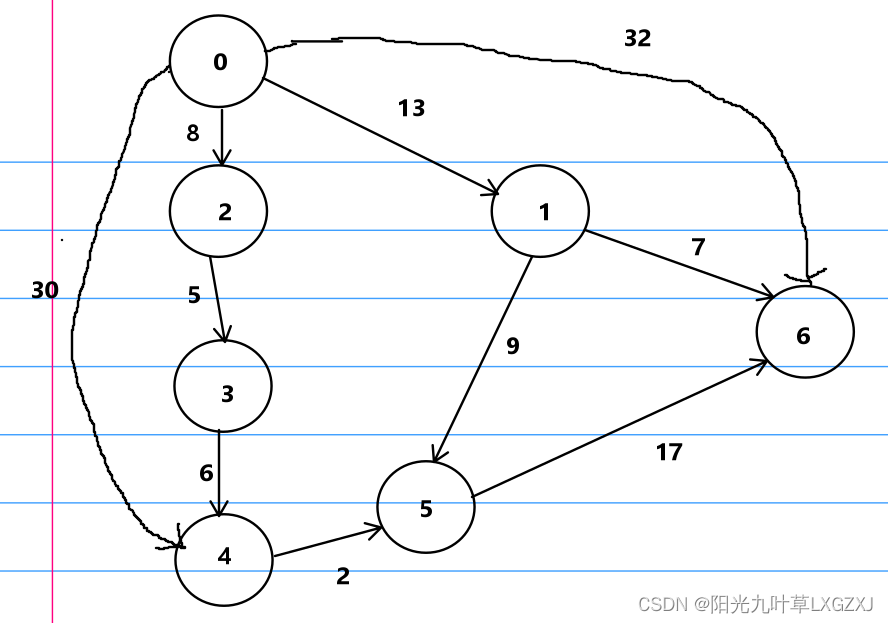
如图 1 所示,作者思考,目标检测器能否识别 base category 之外的类别?
所以,本文作者就构建了一个 open-vocabulary 目标检测器,用于检测从 text 输入的任意类别的目标
现有的目标检测方法都是只学习数据集中出现的类别,而扩充检测类别的方法就是收集更多的类别标注数据,如 LVIS 包括 1203 个类别,有较为丰富的词汇量,但也不够强大。
另外一方面,互联网上有丰富的 image-text pairs,CLIP 就尝试使用 4 亿图文对儿来联合训练模型,并且在 30 个数据集上展示了很好的效果
zero-shot 迁移的效果很大程度上来源于预训练的 text encoder 对任意类别文本的编码能力,尽管现在对 image-level 特征表达的编码能力已经被证明挺好的了,但还 object-level 的特征编码仍然很有挑战
所以,本文作者思考能否从开集分类模型中拿到一些能力来用于开集检测
作者首先从 R-CNN 类的方法入手,将开集目标检测也构建为两个子问题:
- object proposal 的生成
- open-vocabulary 图像分类
如何操作 R-CNN 类的模型:
- 先基于基础类别训练一个 region proposal model
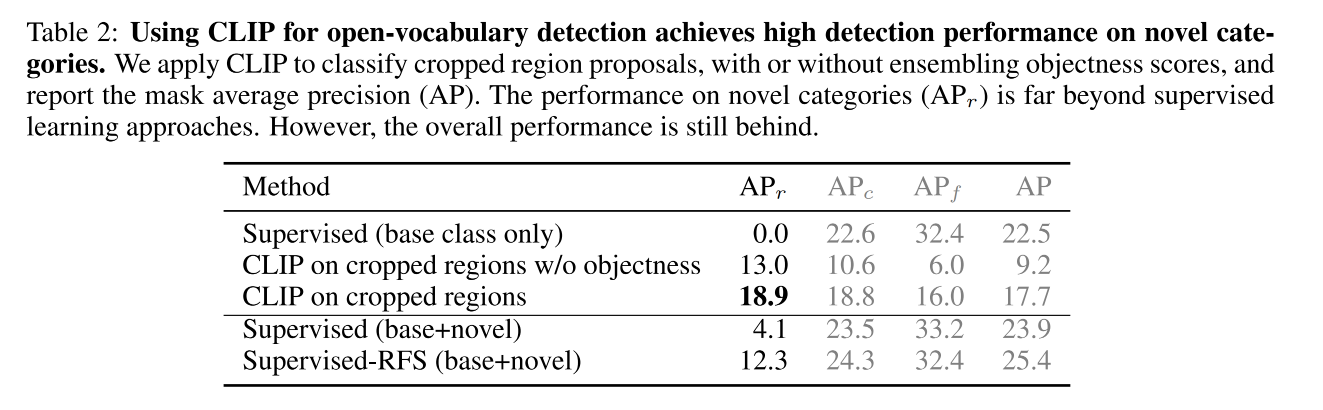
- 然后使用预训练好的图像分类器来对 cropped object proposal 进行分类,可以包括新类和基础类
- 作者使用 LVIS 当做 benchmark,把 rare 类别作为 novel categories,将其他类当做 base categories
- 缺点:很慢,因为每个 object proposal 都是一个个的进入分类器来分类的
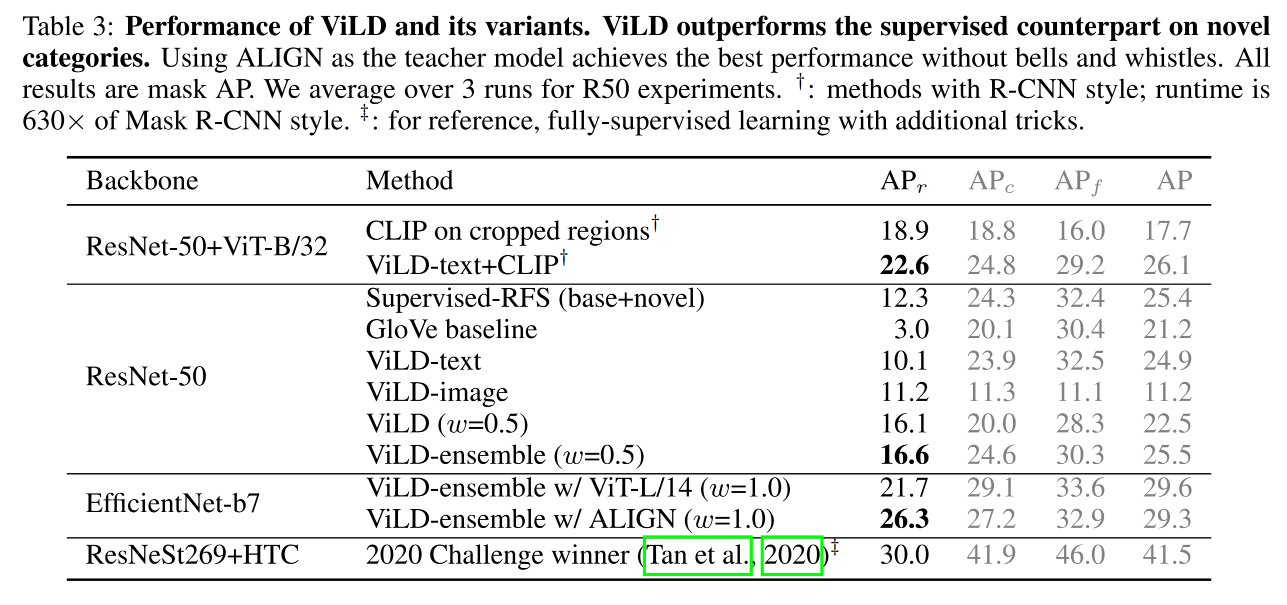
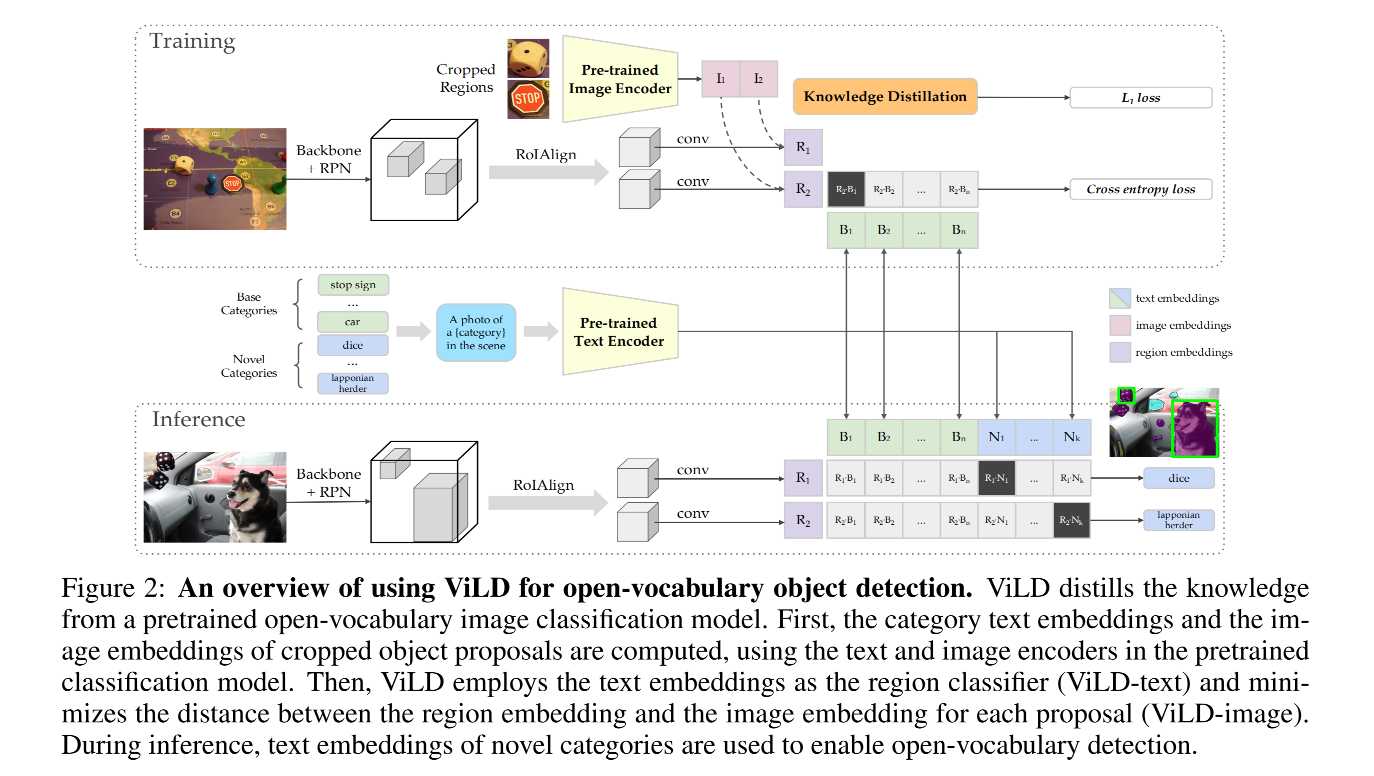
基于此,作者提出了 ViLD,来训练两阶段的开放词汇目标检测器,ViLD 包含两部分:从开集目标分类模型的输出中来学习 text embedding 和 image embedding
- ViLD-text:只会从基础类中蒸馏
- 首先,将类别名称输入预训练好的 text encoder 来得到 text embedding
- 然后,使用推理的 text embedding 结果来对检测到的 region 进行分类
- ViLD-image:会同时从基础类和新类中来蒸馏,因为 proposal 网络可能会检测到包含新类的区域
- 首先,将 object proposal 输入预训练好的 image encoder 来得到 image embedding
- 然后,训练一个 Mask R-CNN 来将 region embedding 和 image embedding 来对齐
二、方法
作者将检测数据集中的类别分类 base 和 novel:
- base: C B C_B CB,参与训练
- novel: C N C_N CN
编码器符号:
- T ( . ) T(.) T(.):text encoder
- V ( . ) V(.) V(.):image encoder
2.1 对新类别的定位 Localization
开放词汇目标检测的第一个挑战就是对新类别目标的定位
作者以 Mask RCNN 为例,作者使用 class-agnostic 模块替换了 class-specific 定位模块,对每个 RoI,模型只能对所有类别预测一个 bbox 和一个 mask,而不是每个类别都会预测一个,所以,使用 class-agnostic 的模块可以扩展到用于新类别的定位
2.2 使用 cropped regions 进行开放词汇检测
一旦对目标候选区域定位成功,就可以使用预训练好的分类器来对区域进行分类
Image embedding:
- 作者基于基础类别 C B C_B CB 训练了一个 proposal 网络,来提取感兴趣区域
- 首先 crop 并 resize proposal,然后输入 image encoder 中计算 image embedding
- 作者使用了两种 crop 区域的 resize 方式:1x 和 1.5x,1.5x 的用于提供更多的上下文信息,整合后的 embedding 然后会被归一化
Text embedding:
- 作者会使用 prompt 模版(如 “a photo of {} in the scene”)来送入 text encoder,并得到 text embedding
相似度:
- 计算完两个 embedding 之后,作者使用 cosine similarities 来计算 image embedding 和 text embedding 的相似程度,然后使用 softmax 激活和类内的 NMS 来得到最终的检测结果
效率:
- 由于每个 cropped region 都会被送入 image encoder 来提取 image embedding,所以效率很低
2.3 ViLD
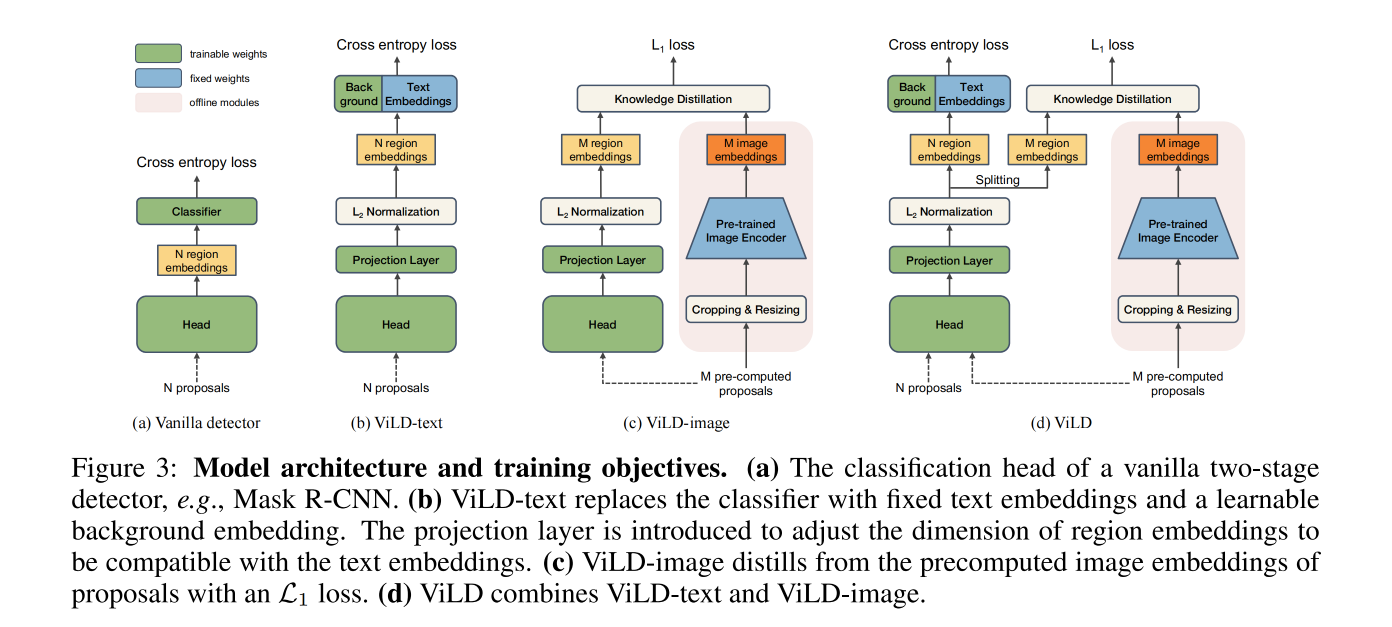
作者提出了 ViLD 来缓解上面提到的效率低的问题
使用 text embedding 来代替分类器:
- 首先,引入了 ViLD-text,目标是训练一个可以使用 text embedding 来分类的 region embedding
- 如图 3b 展示了训练的目标函数,使用 text embedding 来代替了如图 3a 的分类器,只有 text embedding 用于训练
- 对于没有匹配到任何 gt 的 proposal,被分配到背景类别,可以学习其自己的编码 e b g e_{bg} ebg,
- 对所有类别编码,都计算 region embedding 和 category embedding 的余弦相似性,包括前景和背景 e b g e_{bg} ebg,
- 然后,计算带温度参数的 softmax 激活后的分布并计算 cross-entropy loss
- 为了训练第一个阶段,也就是 region proposal 网络,作者在线抽取 region proposal r,并且从头开始使用 ViLD-text 来训练
ViLD-text 的 loss 如下:
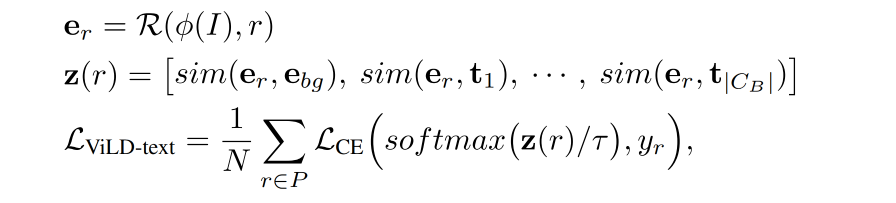
蒸馏 image embedding:
训练 ViLD-image 时,主要是从 teacher model 来蒸馏到 student model 上,也就是将 region embedding 和 image embedding 对齐
为了提升训练速度,对每个 training image 先离线抽取 M 个 proposal,并且计算其对应的 image embedding
这些 proposal 包含了基础类和新类,所以网络是可以扩展的
但 ViLD-text 只能从基础类学习
ViLD-image loss 是 region embedding 和 image embedding 的 L1 loss:
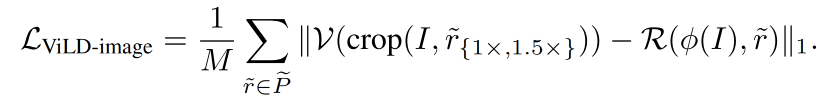
ViLD 的整个训练 loss 如下:w 是超参数
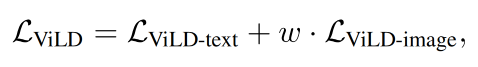
三、效果