"天道不争而善胜"
- 1. Ceres库
- 1.1 名词解释
- 1.2 具体例子
- 1.3 C++实现
- 1. 定义代价函数
- 2. 构建最小二乘问题
- 3. 配置求解器,开始优化
- 4. 优化完毕,查看结果
- 2. G2O(General Graphic Optimization)
- 2.1 图优化
- 2.2 具体例子
- 2.3 C++实现
- 1. 定义顶点
- 2. 定义边
- 3. 配置求解器
- 4. 配置图模型
- 5. 向图添加边
- 6. 执行优化
- 7. 查看
- 3. 总结
注意:有个概念需要通俗的了解一下
-
非线性最小二乘:它属于一种优化问题。即用一个模型来描述现实中的一系列数据时,模型的预测结果与实际的测量结果总会存在一定偏差,这一偏差就称为残差。非线性最小二乘的目的就是,调整模型的参数,使得总的残差最小。
-
优化算法:为获得更好的结果,而采取的方法
1. Ceres库
1.1 名词解释
Ceres求解最小二乘的问题通用形式如下:
min
x
1
2
∑
i
ρ
i
(
∣
∣
f
i
(
x
i
1
,
.
.
.
,
x
i
n
∣
∣
2
)
s
.
t
.
l
j
≤
x
j
≤
u
j
\min\limits_x \;\frac{1}{2}\sum\limits_i\rho_i\Big(||f_i(x_{i_1},...,x_{i_n}||^2\Big) \\ s.t. \quad l_j \le x_j \le u_j
xmin21i∑ρi(∣∣fi(xi1,...,xin∣∣2)s.t.lj≤xj≤uj
- 核函数: ρ ( ⋅ ) \rho(\cdot) ρ(⋅),用于在计算残差时对其进行加权,以减小噪声的影响。暂时取恒等函数
- 优化变量: min \min min 底下的,即 x 1 , . . . , x n x_1,...,x_n x1,...,xn
- 目标函数: 总的大式子,核函数取恒等函数的时候,它是许多项的平方和;
- 代价函数: f i f_i fi, SLAM中的误差项
- 边界: l j l_j lj 和 u j u_j uj 是优化变量的取值范围,分别是下界和上界,暂时取正负无穷
当核函数恒等时,整个问题就是无约束的最小二乘问题。
1.2 具体例子
设待估计曲线为:
y
=
e
x
p
(
a
x
2
+
b
x
+
c
)
+
w
w
为误差,满足高斯分布
y = exp(ax^2+bx+c)+w\qquad\qquad w为误差,满足高斯分布
y=exp(ax2+bx+c)+ww为误差,满足高斯分布
我们现在有很多
x
i
,
y
i
x_i, y_i
xi,yi 点,待估计变量为
a
,
b
,
c
a, b, c
a,b,c。
则我们要求解的最小二乘问题为:
min
a
,
b
,
c
1
2
∑
i
=
1
N
(
∣
∣
y
i
−
e
x
p
(
a
x
i
2
+
b
x
i
+
c
)
∣
∣
2
)
\min\limits_{a,b,c} \;\frac{1}{2}\sum\limits_{i=1}^N\Big(||y_i-exp(ax_i^2+bx_i+c)||^2\Big)
a,b,cmin21i=1∑N(∣∣yi−exp(axi2+bxi+c)∣∣2)
可以看到
y
i
y_i
yi 和
x
i
x_i
xi 已知,误差就是真实值和待估计曲线的估计值的残差。
1.3 C++实现
按照以下步骤来,基本是个通式(只有关键的几步): 仍然以 1.2 的例子进行
1. 定义代价函数
struct CURVE_FITTING_COST
{
CURVE_FITTING_COST(double x, double y) : _x(x), _y(y) {}
// 残差的计算
template <typename T>
bool operator()( // 重载括号运算符
const T *const abc, // 模型参数,有3维
T *residual) const // 残差
{
residual[0] = T(_y) - ceres::exp(abc[0] * T(_x) * T(_x) + abc[1] * T(_x) + abc[2]); // y-exp(ax^2+bx+c)
return true;
}
const double _x, _y; // x,y数据
};
- 也就是这么构造cost_function,重要的是残差函数
residual[0]定义在重载小括号中, - 将其封装成这样的结构体后,加入cost_function后,残差函数是优化过程中后台调用的
2. 构建最小二乘问题
ceres::Problem problem;
for (int i = 0; i < N; i++)
{
problem.AddResidualBlock(
new ceres::AutoDiffCostFunction<CURVE_FITTING_COST, 1, 3>(new CURVE_FITTING_COST(x_data[i], y_data[i])),
nullptr,
abc
);
}
- 不同问题,构建的形式也是很固定的,首先创建
problem对象 - 依次向
problem对象中添加误差项。具体的: AddResidualBlock函数的三个参数分别为cost_function类,核函数,待估计参数的地址。不同的是,这里的cost_function类用的是模板类AutoDiffCostFunction,详细解释下这个AutoDiffCostFunctionAutoDiffCostFunction的模板参数为:函数结构体类型CostFunctor,待估计参数块的维度,待估计参数块的数量- 在 Ceres 中,
cost_function结构体的实例必须通过ceres::AutoDiffCostFunction或ceres::NumericDiffCostFunction对象来进行封装,以便 Ceres 能够自动计算其梯度 - Ceres 会自动计算残差函数关于每个参数块的偏导数,从而得到残差函数的梯度。
3. 配置求解器,开始优化
//配置求解器,这里有很多options的选项,自查
ceres::Solver::Options options;
options.linear_solver_type = ceres::DENSE_QR; //增量方程如何求解,QR分解的方法
options.minimizer_progress_to_stdout = true; //输出到命令行
ceres::Solver::Summary summary; // 优化信息
ceres::Solve(options, &problem, &summary); // 开始优化
- options求解器配置还有很多选项,自行了解
- 将其输出到命令行,保存迭代信息
4. 优化完毕,查看结果
cout << summary.BriefReport() << endl;
cout << "estimated a,b,c = ";
for (auto i : abc)
cout << i << " ";
cout << endl;
- summary中包含迭代次数,误差等信息
- 迭代完成后,数值会保存在待优化变量中,查看即可
2. G2O(General Graphic Optimization)
2.1 图优化
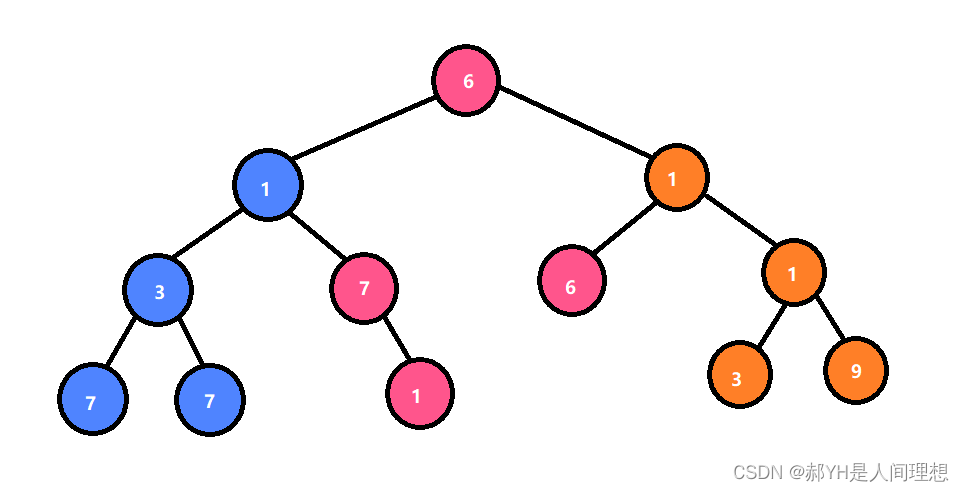
直观的观察到优化问题的样貌。
- 顶点(Vertex): 优化变量
- 边(Edge): 误差项
一个简单的图的例子:
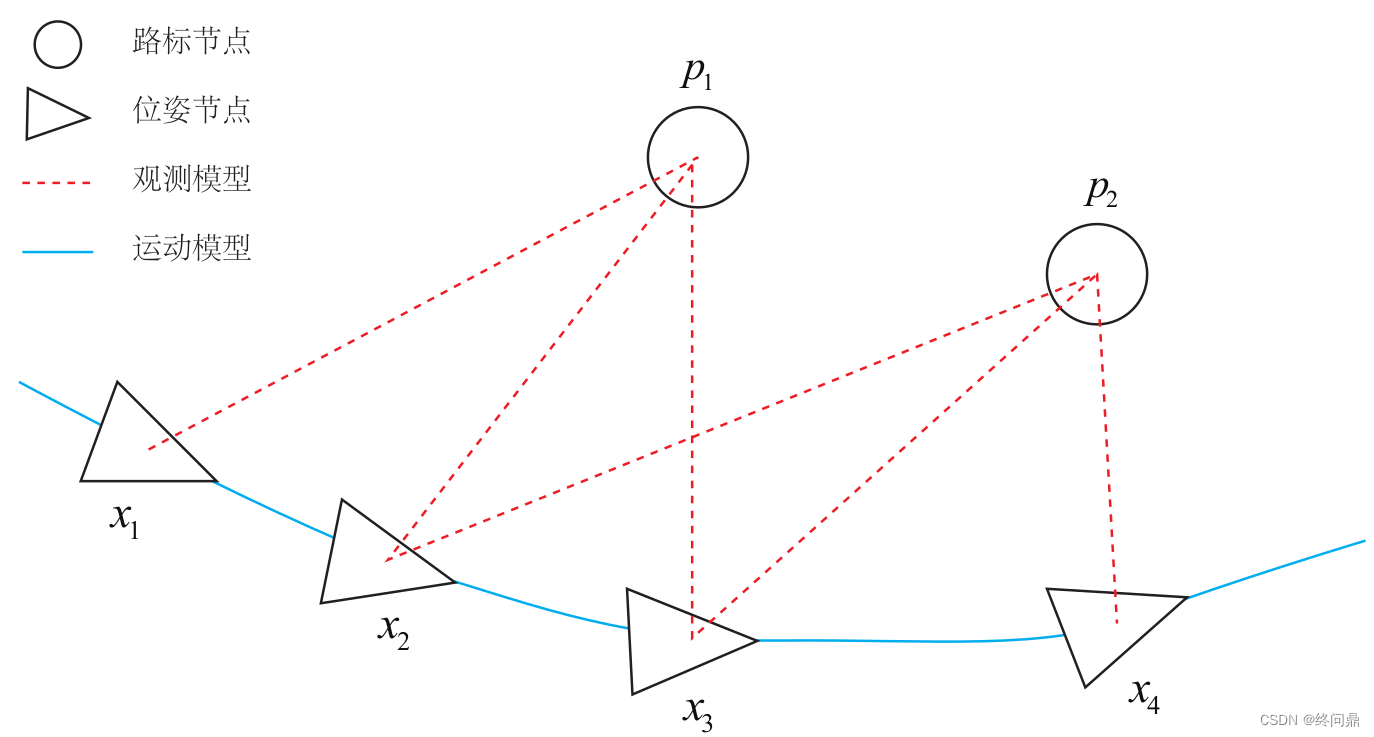
图优化的边:
- 蓝色线相机运动模型
- 红色虚线观测模型
2.2 具体例子
我们要求解的最小二乘问题为:
min
a
,
b
,
c
1
2
∑
i
=
1
N
(
∣
∣
y
i
−
e
x
p
(
a
x
i
2
+
b
x
i
+
c
)
∣
∣
2
)
\min\limits_{a,b,c} \;\frac{1}{2}\sum\limits_{i=1}^N\Big(||y_i-exp(ax_i^2+bx_i+c)||^2\Big)
a,b,cmin21i=1∑N(∣∣yi−exp(axi2+bxi+c)∣∣2)
我们的问题是曲线拟合问题,需要把它抽象成图优化的图。原则:节点为优化变量,边为误差项。则,不难将图优化为如下的样子:
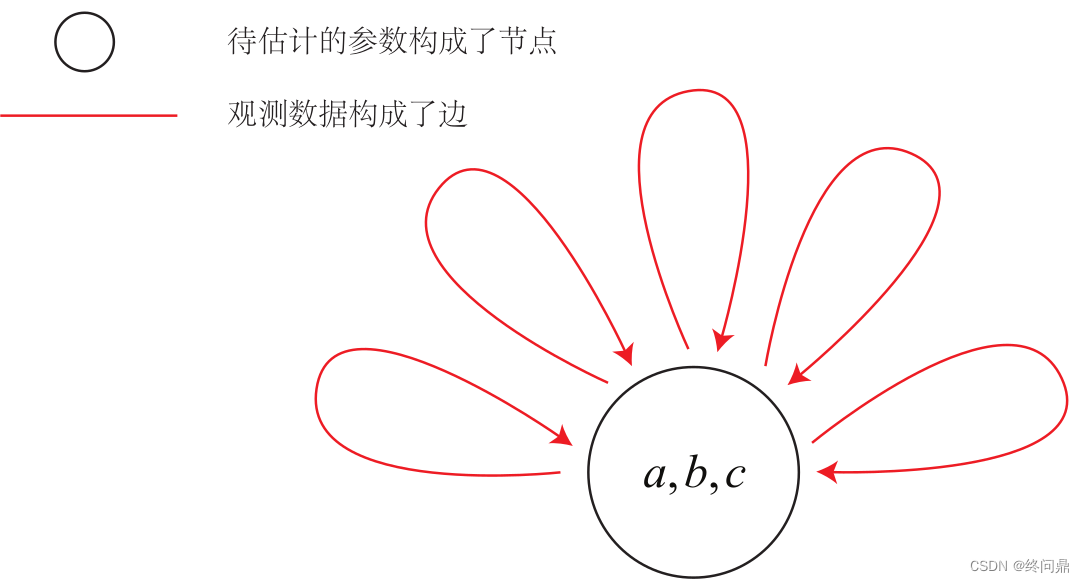
- 整个问题只有一个顶点:曲线模型参数 a , b , c a, b, c a,b,c
- 都是一元边: 每个数据点构成了一个个误差项
2.3 C++实现
按照以下步骤来,基本是个通式(只有关键的几步): 仍然以 2.2 的例子进行
1. 定义顶点
class CurveFittingVertex: public g2o::BaseVertex<3, Eigen::Vector3d>
{
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW
virtual void setToOriginImpl() // 重置
{
_estimate << 0,0,0;
}
virtual void oplusImpl( const double* update) // 更新
{
_estimate += Eigen::Vector3d(update);
}
};
EIGEN_MAKE_ALIGNED_OPERATOR_NEW的加入是解决字节对其问题,具体看Eigen字节对其- 第一个函数是第一次给初始值
- 第二个函数是以后更新的过程
- 该函数是顶点基函数的共有继承类,
<3, Eigen::Vector3d>模板中给出了<优化变量维度, 数据类型> oplusImpl函数很重要,是增量 Δ x \Delta x Δx的计算,即 x k + 1 = x k + Δ x x_{k+1} = x_k + \Delta x xk+1=xk+Δx 的过程
2. 定义边
class CurveFittingEdge: public g2o::BaseUnaryEdge<1,double,CurveFittingVertex>
{
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW
1. CurveFittingEdge( double x ): BaseUnaryEdge(), _x(x) {}
// 计算曲线模型误差
void computeError()
{
2. const CurveFittingVertex* v = static_cast<const CurveFittingVertex*> (_vertices[0]);
3. const Eigen::Vector3d abc = v->estimate();
4. _error(0,0) = _measurement - std::exp( abc(0,0)*_x*_x + abc(1,0)*_x + abc(2,0) ) ;
}
virtual bool read( istream& in ) {}
virtual bool write( ostream& out ) const {}
public:
double _x;
};
class CurveFittingEdge: public g2o::BaseUnaryEdge<1,double,CurveFittingVertex>是基类一元边的共有继承,模板<1,double,CurveFittingVertex>中的内容分别是观测值维度,观测值类型,该边要连接的顶点类型(也就是上边1.中定义的)2.代码static_cast是强制类型转换符,将顶点转成我们自定义支持的类型3.代码表示提取当前值,estimate()就是查看现在V中的值4.代码就是误差,由于我们只有一个顶点,所以过程略微简单些
3. 配置求解器
typedef g2o::BlockSolver< g2o::BlockSolverTraits<3,1> > Block;
- BlockSolver类模板的使用了3X3的稠密矩阵块储存海森矩阵,每个块的大小为1X1的求解器
- 每个误差项优化变量维度(顶点参数数量)为3,误差值维度为1
std::unique_ptr<Block::LinearSolverType> linearSolver ( new g2o::LinearSolverDense<Block::PoseMatrixType>());
- 线性方程求解器
LinearSolverType是线性求解器的类型:用于指定解线性方程的算法。 - 用
new创建LinearSolverDense实例,是G2O库中用于求解稠密矩阵的线性求解器,PoseMatrixType指定了矩阵块的类型,也就是上边BlockSolverTraits中的类型 - 最后
linearSolver现在是一个std::unique_ptr(Block::LinearSolverType)对象,它有一个LinearSolverDense类的实例 LinearSolverDense是LinearSolverType类的一种实现
std::unique_ptr<Block> solver_ptr (new Block ( std::move(linearSolver)));
// 梯度下降方法,从GN, LM, DogLeg 中选
g2o::OptimizationAlgorithmLevenberg* solver = new g2o::OptimizationAlgorithmLevenberg ( std::move(solver_ptr));
- 还可以用其他方法,如下两句替换上边的也可以
g2o::OptimizationAlgorithmGaussNewton* solver = new g2o::OptimizationAlgorithmGaussNewton( std::move(solver_ptr));
g2o::OptimizationAlgorithmDogleg* solver = new g2o::OptimizationAlgorithmDogleg( std::move(solver_ptr));
4. 配置图模型
g2o::SparseOptimizer optimizer; // 图模型
optimizer.setAlgorithm( solver ); // 设置求解器
optimizer.setVerbose( true ); // 打开调试输出
// 往图中增加顶点
CurveFittingVertex* v = new CurveFittingVertex();
//设置位姿估计值,V一个位姿估计器(pose estimater),这里是0初始位姿
v->setEstimate( Eigen::Vector3d(0,0,0) );
//区分不同的位姿估计器,一个估计器一个id
v->setId(0);
optimizer.addVertex(v);
- 除最后一句,其他的都是将顶点按照图要求的配置
- 最后一句将
v加入图中,告诉优化器应该优化该机器人的pose
5. 向图添加边
for ( int i=0; i<N; i++ )
{
1. CurveFittingEdge* edge = new CurveFittingEdge(x_data[i]); //残差做边
2. edge->setId(i); // 该残差边的id
3. edge->setVertex(0, v); // 设置连接的顶点,v就是顶点,就是要优化的系数a,b,c,通过优化器估计顶点值
4. edge->setMeasurement(y_data[i]); // 观测数值y,也许是为了弥补构造函数中计算代价函数时候没有y(_measurement)的原因
5. edge->setInformation(Eigen::Matrix<double,1,1>::Identity()*1/(w_sigma*w_sigma)); // 信息矩阵,也就是边的权重:协方差矩阵之逆,也就是高斯分布最大似然里边的那个
6. optimizer.addEdge(edge);
}
1.残差做边2.设置该残差边的id3.设置连接的顶点v,即包含a,b,c的4.向边加入观测值/真实值 y(_measurement)5.设置该边的权重,也称信息矩阵6.边配置完毕,将该边加入图中。其实这个配置点和边,最后一步加入途中的步骤很像。
6. 执行优化
1. optimizer.initializeOptimization(); //对图模型初始化
2. optimizer.optimize(100); //最大迭代次数,每次迭代会更新顶点
1.初始化图模型,为顶点和边分配内存空间2.对图模型进行优化,设置最大迭代次数为100.每次迭代都会更新图模型中的顶点
7. 查看
Eigen::Vector3d abc_estimate = v->estimate();
cout<<"estimated model: "<<abc_estimate.transpose()<<endl;
3. 总结
- 实际上G2O并不是用来做曲线拟合的,在SLAM中带有多个相机位姿和空间点较为复杂,在G2O中有很好的定义,而CERES中需要自己实现
Cost function - 基本处理这种东西,该库是通式,多看两遍就熟悉了
- 在G2O的顶点定义中有 Δ x \Delta x Δx 的计算,但是在SLAM中,它不仅仅是数值的加法,要用到李群李代数的左乘或者右乘更新了。
本节主要介绍了非线性优化问题:许多个误差项平方组成的最小二乘问题。(SLAM中较为常见)