练习0:填写已有实验
具体更改的地方如下:
proc.c 中alloc_proc新增加内容
proc->rq = NULL;
list_init(&proc->run_link);
//proc->run_link.next = proc->run_link.prev = NULL ;
proc->time_slice = 0;
proc->lab6_run_pool.left = proc->lab6_run_pool.right = proc->lab6_run_pool.parent = NULL;
proc->lab6_stride = 0;
proc->lab6_priority = 1;
链表初始化应该用list_init而不是空
priority要设置成1,不能设置为0,因为后续有的代码会除以这个数字,设置为0可能有bug
练习1: 使用 Round Robin 调度算法(不需要编码)
-
请理解并分析sched_class中各个函数指针的用法,并结合Round Robin 调度算法描ucore的调度执行过程
struct sched_class { // 算法名称 const char *name; //初始化算法用数据 void (*init)(struct run_queue *rq); // 当有进程设置为可调度时调用该函数放入就绪队列 void (*enqueue)(struct run_queue *rq, struct proc_struct *proc); //在就绪队列中选出一个去运行然后在就绪队列中一出该信息 void (*dequeue)(struct run_queue *rq, struct proc_struct *proc); //查看就绪队列中下一个是谁可以运行 struct proc_struct *(*pick_next)(struct run_queue *rq); //每次时钟中断时调用该函数,该函数需要处理,占用cpu时间片的剩余以及是否可调度 void (*proc_tick)(struct run_queue *rq, struct proc_struct *proc); };ucore调度过程:
void schedule(void) { bool intr_flag; struct proc_struct *next; local_intr_save(intr_flag); { current->need_resched = 0; if (current->state == PROC_RUNNABLE) { // cprintf("insert into %p\n" , current); sched_class_enqueue(current); } if ((next = sched_class_pick_next()) != NULL) { // cprintf("dequeue out %p\n" , next); sched_class_dequeue(next); } if (next == NULL) { next = idleproc; } next->runs ++; if (next != current) { // cprintf("run %p \n" , next); proc_run(next); } } local_intr_restore(intr_flag); } 首先就是创建俩个内核线程,一个执行初始化后是死循环调度,另一个则是创建子进程然后调度
子线程通过do_fork 一出生就被挂到proc_list和hash_list这个链表上了,顺带调用wakeup_proc这个函数然 后就通过进程 调度算法的入队方式挂上去了
void wakeup_proc(struct proc_struct *proc) { assert(proc->state != PROC_ZOMBIE); bool intr_flag; local_intr_save(intr_flag); { if (proc->state != PROC_RUNNABLE) { proc->state = PROC_RUNNABLE; proc->wait_state = 0; if (proc != current) { sched_class_enqueue(proc);//这个函数就是挂到调度算法列表上 } } else { warn("wakeup runnable process.\n"); } } local_intr_restore(intr_flag); }接下来就是,要么时钟中断,要么进程自己放弃cpu然后同过调度算法切换另一个进程,而该算法逻辑是给进程分配一个时间片,然后每一个时钟中断检测一下进程的时间片,要是用完了,就通过调度算法,将进程放到就绪列表尾部。,然后等待下次调度
static void RR_enqueue(struct run_queue *rq, struct proc_struct *proc) { assert(list_empty(&(proc->run_link))); list_add_before(&(rq->run_list), &(proc->run_link));//放到尾部 if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice) { proc->time_slice = rq->max_time_slice; } proc->rq = rq; rq->proc_num ++; }其中trap.c中是通过run_timer_list函数来实现每次进程时间片减少的
void run_timer_list(void) { bool intr_flag; local_intr_save(intr_flag); { list_entry_t *le = list_next(&timer_list); if (le != &timer_list) { timer_t *timer = le2timer(le, timer_link); assert(timer->expires != 0); timer->expires --; while (timer->expires == 0) { le = list_next(le); struct proc_struct *proc = timer->proc; if (proc->wait_state != 0) { assert(proc->wait_state & WT_INTERRUPTED); } else { warn("process %d's wait_state == 0.\n", proc->pid); } wakeup_proc(proc); del_timer(timer); if (le == &timer_list) { break; } timer = le2timer(le, timer_link); } } sched_class_proc_tick(current);就走了个这个 } local_intr_restore(intr_flag); }嗯~~ 一大堆代码,但是在lab6中好像没有用到if里的就走了 sched_class_proc_tick(current);来调用调度算法的RR_proc_tick这个
-
请在实验报告中简要说明如何设计实现”多级反馈队列调度算法“,给出概要设计,鼓励给出详细设计
嗯~ 不会
练习2: 实现 Stride Scheduling 调度算法(需要编码)
首先是这个BIG_STRIDE应该取多少值:
static int
proc_stride_comp_f(void *a, void *b)
{
struct proc_struct *p = le2proc(a, lab6_run_pool);
struct proc_struct *q = le2proc(b, lab6_run_pool);
int32_t c = p->lab6_stride - q->lab6_stride;
if (c > 0)
return 1;
else if (c == 0)
return 0;
else
return -1;
}
下面来仔细分析一下吧:
在具体实现时,有一个需要注意的地方:stride属性的溢出问题,在之前的实现里面我们并没有考虑 stride 的数值范围,而这个值在理论上是不断增加的,在 stride溢出以后,基于stride的比较可能会出现错误。比如假设当前存在两个进程A和B,stride属性采用16位无符号整数进行存储。当前队列中元素如下(假设当前运行的进程已经被重新放置进运行队列中):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jMnZa3UF-1690546856134)(https://chyyuu.gitbooks.io/ucore_os_docs/content/lab6_figs/image001.png)]
此时应该选择 A 作为调度的进程,而在一轮调度后,队列将如下:
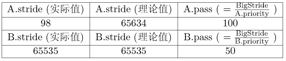
可以看到由于溢出的出现,进程间stride的理论比较和实际比较结果出现了偏差。我们首先在理论上分析这个问题:令PASS_MAX为当前所有进程里最大的步进值。则我们可以证明如下结论:对每次Stride调度器的调度步骤中,有其最大的步进值STRIDE_MAX和最小的步进值STRIDE_MIN之差:
STRIDE_MAX – STRIDE_MIN <= PASS_MAX
有了该结论,在加上之前对优先级有Priority > 1限制,我们有STRIDE_MAX – STRIDE_MIN <= BIG_STRIDE,于是我们只要将BigStride取在某个范围之内,即可保证对于任意两个 Stride 之差都会在机器整数表示的范围之内。而我们可以通过其与0的比较结构,来得到两个Stride的大小关系。在上例中,虽然在直接的数值表示上 98 < 65535,但是 98 - 65535 的结果用带符号的 16位整数表示的结果为99,与理论值之差相等。所以在这个意义下 98 > 65535。基于这种特殊考虑的比较方法,即便Stride有可能溢出,我们仍能够得到理论上的当前最小Stride,并做出正确的调度决定。
所以最后应该取 0x7FFFFFFF 即 (((uint32_t)-1) / 2)
#define BIG_STRIDE 0x7FFFFFFF /* you should give a value, and is ??? */
然后就是
stride调度算法是抢占式的。在stride_enqueue中,每当就绪队列入队时都会为其分配一定的时间片,当线程运行的过程中发生时钟中断时则会通过stride_proc_tick函数扣减对应的时间片。当为线程分配的时间片扣减为0时,则会将线程的need_resched设置为1。
在trap中断处理函数中,当对应中断号的处理例程返回时会单独的检查need_resched的值,当发现为1时,则会触发schedule函数进行一次强制的线程调度,从而令当前时间片扣减为0的线程得以让出CPU,使其它的就绪线程能得到执行的机会。这也是stride调度算法被称为抢占式调度算法的原因:无论当前执行的线程是否主动的让出cpu,在分配的时间片用完之后,操作系统将会强制的撤下当前线程,进行一次调度,通过如下就可以看出
void trap(struct trapframe *tf)
{
// dispatch based on what type of trap occurred
// used for previous projects
if (current == NULL)
{
trap_dispatch(tf);
}
else
{
// keep a trapframe chain in stack
struct trapframe *otf = current->tf;
current->tf = tf;
bool in_kernel = trap_in_kernel(tf);
trap_dispatch(tf);
current->tf = otf;
if (!in_kernel)
{
if (current->flags & PF_EXITING)
{
do_exit(-E_KILLED);
}
if (current->need_resched)
{
schedule();
}
}
}
}
static void
stride_init(struct run_queue *rq)
{
list_init(&rq->run_list);
rq->lab6_run_pool = NULL;
rq->proc_num = 0;
}
static void
stride_enqueue(struct run_queue *rq, struct proc_struct *proc)
{
rq->lab6_run_pool = skew_heap_insert(rq->lab6_run_pool, &proc->lab6_run_pool, proc_stride_comp_f);
if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice)
{
proc->time_slice = rq->max_time_slice;
}
proc->rq = rq;
rq->proc_num++;
}
static void
stride_dequeue(struct run_queue *rq, struct proc_struct *proc)
{
rq->lab6_run_pool = skew_heap_remove(rq->lab6_run_pool, &proc->lab6_run_pool, proc_stride_comp_f);
rq->proc_num--;
}
static struct proc_struct *
stride_pick_next(struct run_queue *rq)
{
if (rq->lab6_run_pool == NULL)
return NULL;
struct proc_struct *p = le2proc(rq->lab6_run_pool, lab6_run_pool);
if(p->lab6_priority == 0){
p->lab6_stride += BIG_STRIDE;
}else{
p->lab6_stride += BIG_STRIDE / p->lab6_priority;
}
return p;
}
static void
stride_proc_tick(struct run_queue *rq, struct proc_struct *proc)
{
if (proc->time_slice > 0){
proc->time_slice--;
}
if (proc->time_slice == 0){
proc->need_resched = 1;
}
}
整体理解算法不难,因为人家的斜堆已经给出了,不需要自己实现
斜堆结构实现的就绪队列其入队、出队操作能达到O(logn)的对数复杂度,比其双向链表实现的就绪队列入队、出队效率O(n)要高出一个数量级