本博客是一系列文章中的第一篇,解释了为什么使用大型语言模型(LLM)部署专用领域聊天机器人的主流管道成本太高且效率低下。在第一篇文章中,我们将讨论为什么矢量数据库尽管最近流行起来,但在实际生产管道中部署时从根本上受到限制。在下面的文章中,我们说明了我们在ThirdAI上发布的最新产品如何解决这些缺点,并实现以低成本在生产中部署LLM驱动的检索的愿景。
动机
专用领域聊天机器人是 ChatGPT 最受欢迎的企业应用程序。具有特定知识库的自动问答功能可以使任何雇主的员工提高工作效率,同时节省员工宝贵的时间。举例来说,如果员工与客户互动,那么触手可及的与客户的所有历史互动将非常方便。如果你想为一个大型代码库做出贡献,如果你能在细粒度级别快速掌握任何现有功能,它可以让你非常高效。这样的例子不胜枚举。
ChatGPT 是一个很棒的对话工具,它根据互联网上发现的大量文本信息进行了训练。如果你问ChatGPT关于互联网的一般知识,它可以很好地回答。但是,它有一些明显的局限性。ChatGPT 无法回答那些答案不属于其训练数据中的问题。因此,如果您问 ChatGPT,“谁赢得了 2022 年足球世界杯? 它将无法回答,因为它在 2021 年 9 月之后没有接受过任何信息的训练。企业坐拥一堆非常专业、特有且不断更新的信息语料库,而开箱即用的 ChatGPT 不会成为该知识库的查询助手。更糟糕的是,众所周知,在没有适当保护机制的情况下,对 ChatGPT 的查询可能会导致虚构的答案。
幸运的是,有着大量措施正围绕使用提示解决上述两个缺陷。
什么是提示?
提示是一种新术语,用于告诉会话代理回答问题所需的所有特定信息。然后,它依靠座席的对话能力来生成精美的答案。如果你想让 ChatGPT 回答一个不属于其训练集的特定问题,你必须基本上让 ChatGPT 知道它需要知道的所有信息,少于 4096 个令牌(或大约 3200 个单词,GPT-4的单词上限达到了25000个),然后用给定的“上下文”问它同样的问题。
无论这听起来多么愚蠢,提示仍然是一种有价值的功能。像人类那样进行自动化的对话是我们最近在生成式人工智能方面取得显著进步的罕见壮举。实际上,构建查询助手可以归结为经典问题,即“检索与查询相关的信息”,然后使用 ChatGPT 的功能生成基于检索到的信息的对话答案。我们可以看到,这会自动在幻觉周围设置护栏,因为会话代理被迫将答案接地到检索到的文本中,而这是知识库的子集。
最难的部分是总是大海捞针!
嵌入和向量数据库生态系统:在任何给定的语料库上使用 ChatGPT 构建接地气的查询助手。
使用Langchain构建了一系列聊天机器人应用程序,您可以在其中引入任何文本语料库并使用ChatGPT与之交互。所有这些应用程序都建立在基于嵌入的标准信息检索过程之上。
该过程分为两个主要阶段。第一阶段是预处理步骤,用于生成嵌入向量并构建用于近邻搜索的向量索引。生成索引后,下一阶段是查询。我们简要介绍一下这两个阶段。
预处理步骤:此步骤获取所有原始文本并构建可以有效搜索的索引。下图描述了该过程。

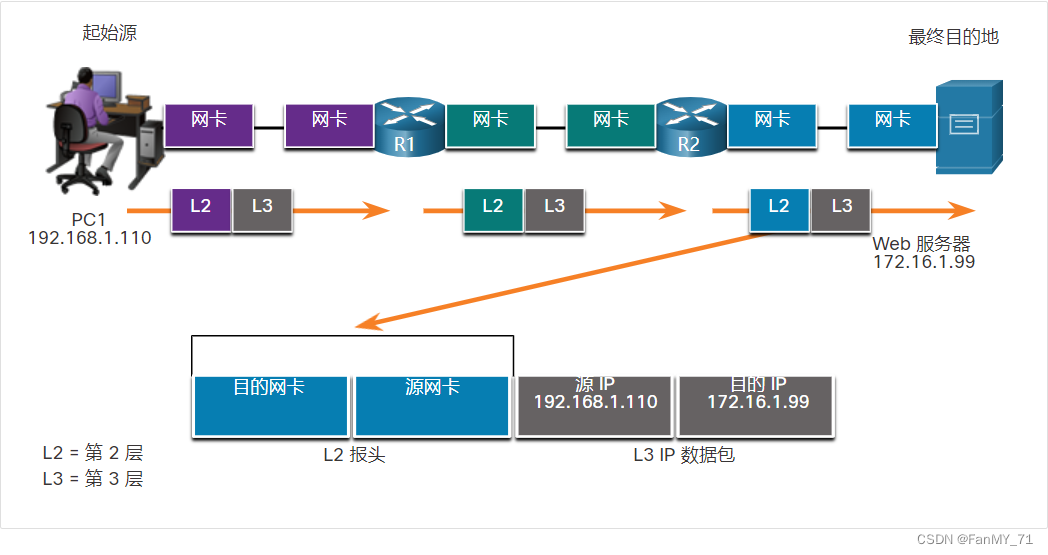
预处理步骤概述:您需要同时将文本和向量嵌入存储在数据库中,并以向量作为 KEY。该过程需要LLM将文本块转换为向量。LLM 在查询时候的逻辑应该是相同的。
注意: 对LLM的任何更改或更新都需要重新索引Vector DB中的所有内容。您需要完全相同的LLM进行查询。 不允许更改尺寸。
隐私风险:所有文本都需要转到嵌入模型和向量数据库。
昂贵: 完整文本语料库中的每个标记都转到LLM和Vector DB。
假设我们有一个文本文档语料库来准备问答。第一步是将语料库(或文本文档)分解成小块文本,我们称之为块(该过程也称为分块)。然后将每个块馈送到经过训练的语言模型(如 BERT 或 GPT)以生成向量表示,也称为嵌入。然后将文本嵌入对存储在矢量数据库或 <KEY, VALUE> 存储中,其中 KEY 是矢量嵌入,VALUE 是文本块。矢量数据库的独特之处在于能够有效地对矢量执行近似近邻 (ANN) 搜索以进行 KEY 匹配,而不是在传统数据库中执行精确的 KEY 匹配。
- 注意: 对LLM的任何更改或更新都需要重新索引Vector DB中的所有内容。您需要完全相同的LLM进行查询。 不允许更改尺寸。
- 隐私风险:所有文本都必须转到嵌入模型和矢量数据库。如果两者都是不同的托管服务,则可以在两个不同的位置创建 COMPLETE 数据的两个副本。
- 注意成本: 完整文本语料库中的每个标记都转到LLM和Vector DB。将来,如果您通过微调,升级模型甚至增加维度来更新LLM,则需要重新索引并再次支付全部费用。
- 使用托管服务进行成本估算:让我们适度估计一下使用所有Pubmed摘要的知识库来构建聊天机器人,以构建医疗保健问答应用程序。Pubmed有大约35万个摘要,大约需要100M个嵌入的块。假设每块 100 个代币,我们将有大约 25B 个代币。即使我们使用Pinecone的适度矢量数据库计划(性能)和OpenAI的更便宜的嵌入模型价格(Babbage V1),我们也在考虑向量数据库每月大约7000-8000美元的成本。此费用不包括任何仓储费。此外,根据代币数量生成嵌入的一次性成本为 12500 美元。每次更改嵌入模型时,我们也需要支付12500美元。如果我们每月进行 10亿次查询,那么我们每月至少支付 25000 美元的额外经常性费用,用于使用 OpenAI 进行查询嵌入服务和响应生成。值得注意的是,PubMed是较小的公共检索数据集之一。企业可能使用在10-100倍大的语料库之上进行上述工作。
查询阶段:嵌入和使用ANN搜索,然后通过提示生成
此步骤采用用户键入的问题,在矢量数据库中搜索与问题“最相关”的文本内容,然后根据该信息征求GenAI的响应。下图总结了这些步骤。
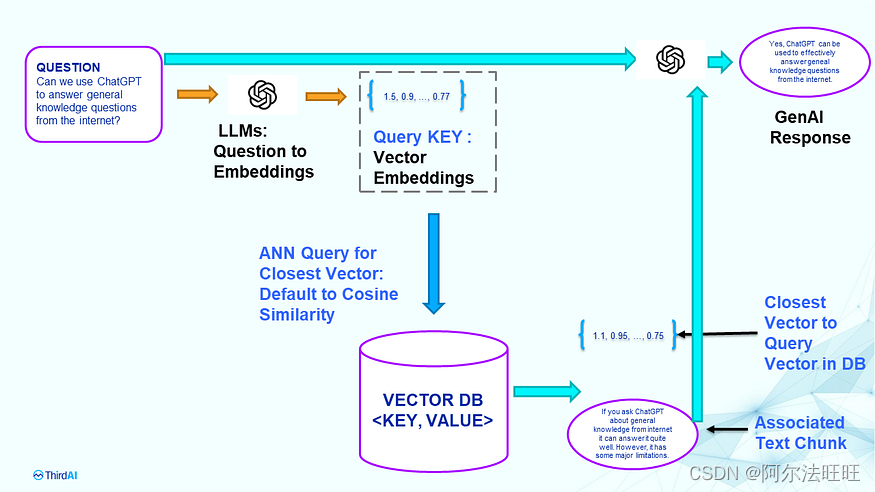
问答阶段: 对于索引文本块时使用的问题嵌入,您需要完全相同的 LLM。索引后无法修改 LLM。任何训练、调优都将使搜索过程无法使用,因为 ANN over KEY 可能不一致。如果要更新或更改LLM,则需要重新索引。注意:查询延迟是嵌入延迟 + 矢量数据库查询延迟 + GenAI 的文本生成延迟之和。
对于问答阶段,这个过程很简单。我们首先使用用于索引向量数据库的相同 LLM 生成查询的向量嵌入。此嵌入用作查询 KEY,并执行近似近邻搜索 (ANN) 以查找数据库中最接近查询嵌入的几个向量。接近度的度量是预定义和固定的,通常是余弦相似性。识别最接近的向量后,其相应的文本块用作与问题相关的信息。然后,相关信息和问题通过提示提供给生成AI,如ChatGPT,以生成响应。
- 注意:查询延迟是三个延迟的总和:嵌入问题文本延迟 + 向量数据库检索延迟 + GenAI 的文本响应生成延迟。如果您使用多个托管服务和不同的微服务,请准备好等待至少数百毫秒才能获得答案。显然,对于搜索引擎、电子商务和其他延迟关键型应用程序来说,这太慢了,其中超过 100 毫秒的延迟会导致糟糕的用户体验。这是一篇亚马逊博客,介绍了每 100 毫秒延迟如何花费 1% 的销售额。
- 成本:如上一节所述,一旦数据位于外部托管服务上,查询成本可能会很高并被锁定。
已知嵌入和矢量搜索的基本限制:为什么现代信息检索智慧提倡学习索引?
除了上面提到的延迟、成本、更新模型的不灵活性和隐私等问题外,还有一个根本的缺点,即使用基于余弦相似性的ANN(文本检索)断开了嵌入过程(KEY生成)的连接。
一个假设和Andrej Karpathy最近的实验比较接近:整个生态系统背后的隐含假设是向量嵌入之间的余弦相似性在检索相关文本。 众所周知,可能有更好的选择。这些LLM没有针对余弦相似性检索进行微调,其他相似性函数可能工作得更好。这是Andrej Karpathy的帖子和他的笔记本,以及关于他如何发现基于SVM的相似性更好。
深度学习革命告诉我们,联合优化的检索系统总是比嵌入然后ANN的断开连接的过程更好,在ANN过程中,ANN过程完全忽略了嵌入部分,反之亦然。
因此,如果矢量搜索生态系统的最终目标是为所提出的问题检索“相关文本”,为什么有两个互不关联的过程?为什么不有一个统一的学习系统,在给定问题文本时返回“最相关”的文本?难怪Andrej发现学习的SVM比简单的点积检索更好。近五年来,信息检索社区一直在构建这种联合优化的嵌入和检索系统。
神经信息检索系统最有效的形式是学习索引。在本博客的第 2/3 部分中,我们将回顾学习索引并讨论行业中以前部署的学习系统。我们将介绍神经数据库,这是一个端到端的学习索引系统,它完全绕过了昂贵而繁琐的高维近邻搜索向量。
在最后一部分(第 3/3 部分),我们将讨论 ThirdAI 的生产上使用的神经数据库 API 及其与 Langchain 和 ChatGPT 的集成。我们的解决方案完美避开了嵌入过程以及矢量数据库检索的昂贵、缓慢和严格的限制!