BERT模型简介
BERT模型是基于Transformers的双向编码器表示(BERT),在所有层中调整左右情境(学习上下层语义信息)。
Transformer是一种深度学习组件,能够处理并行序列、分析更大规模的数据、加快模型训练速度、拥有注意力机制,能够更好地收集词语相关上下文语境的信息。能够学习其他词语的衍生信息。更改产生更好质量的embedding表示。
双向模型在自然语言处理范围内被广泛应用。文本查看顺序为left-to-right(从左到右)和right-to-left(从右到左)。
BERT适合创建高质量情境化embedding表示。能运用语言建模等自我监督任务(无人工标注)训练BERT模型。
下图是BERT信息流动的方向(BERT能够较好地将文本表示应用于所有层中)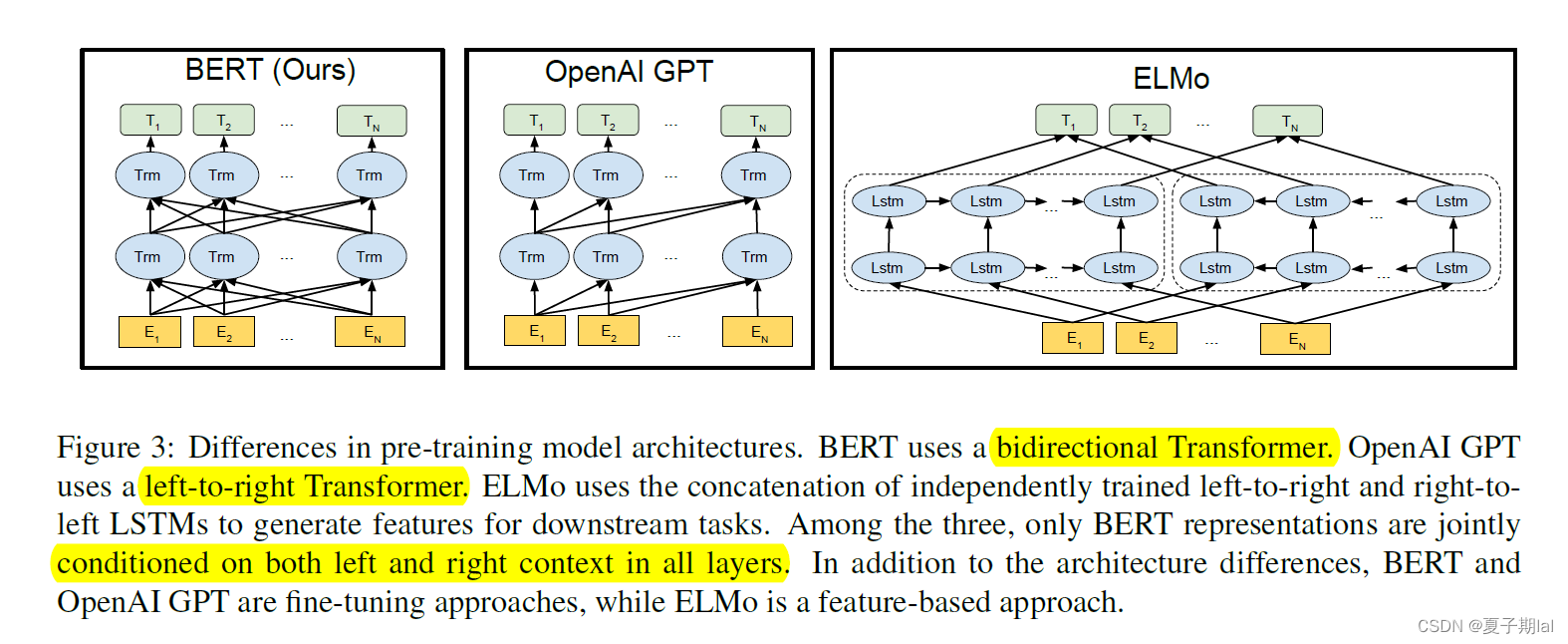
BERT的输入(基于Transformer)
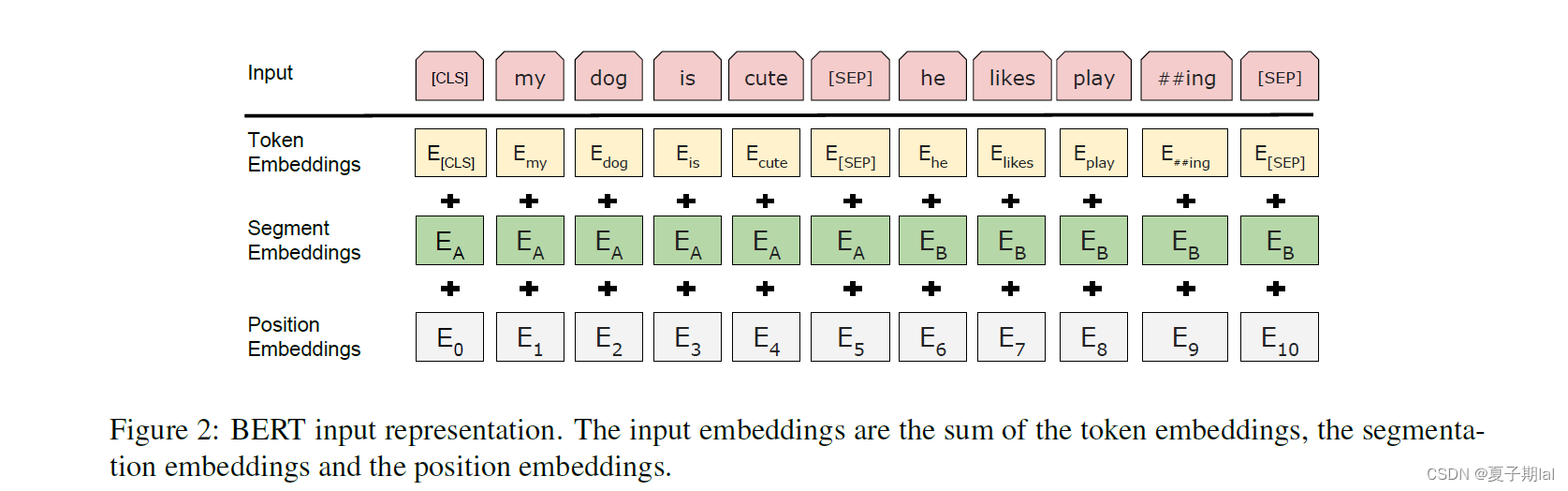
BERT的input embedding主要由Token Embeddings, Segment Embeddings, Position Embeddings相加获得。
I
n
p
u
t
_
E
m
b
e
d
d
i
n
g
s
=
T
o
k
e
n
_
E
m
b
e
d
d
i
n
g
s
+
S
e
g
m
e
n
t
_
E
m
b
e
d
d
i
n
g
s
+
P
o
s
i
t
i
o
n
_
E
m
b
e
d
d
i
n
g
s
Input\_Embeddings = Token\_Embeddings + Segment\_Embeddings + Position\_Embeddings
Input_Embeddings=Token_Embeddings+Segment_Embeddings+Position_Embeddings
- Token Embeddings,主要将word切分为subword(子词),具体例子为将playing切分为play和##ing。
- Segment Embeddings,主要用于区分不同句子,比如输入有两个句子,所以Segmnt Embeddings有两种为 E A E_{A} EA和 E B E_{B} EB
- Position Embeddings,主要为存储位置信息,BERT 的 Position Embedding 也是通过学习得到的,在 BERT 中,假设句子最长为 512。
BERT的预训练任务Mask LM
BERT预训练任务主要为Mask LM任务(掩码预测任务)和Next sentence predict(NSP)(下一句预测)任务。
Mask LM任务较好缓解了双向文本查看顺序的信息泄露问题。信息泄露的图示具体如下(有些模型在编码的时候已知预测的信息)
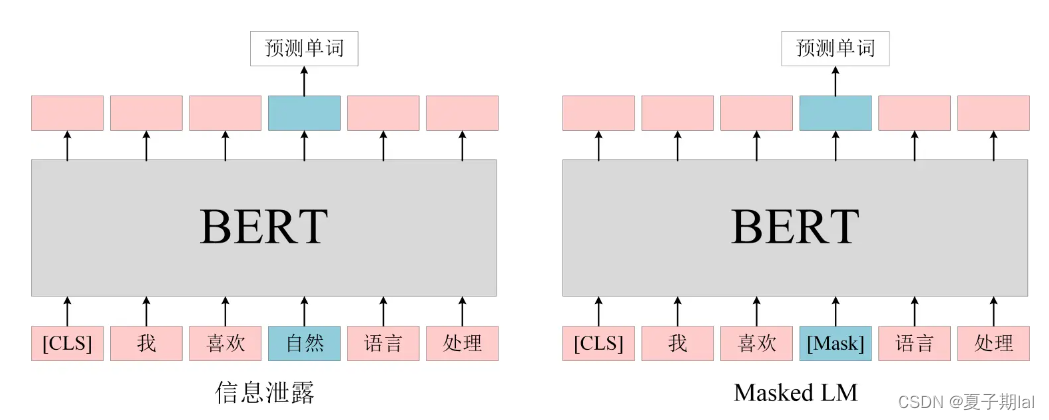
BERT在预训练任务Mask LM的时候只预测MASK位置的单词,这样能够更好的利用上下文信息,能够获得更高质量的embedding表示。但在后续的任务中句子都为一个完整的句子(不出现MASK),为了缓解此类问题,在训练过程中采取下列操作,具体操作如下所示。
例句为"my dog is hairy", 选择了hairy 作为MASK。
- 80%的概率,将句子"my dog is hairy"转化为"my dog is [MASK]"
- 10%的概率,句子"my dog is hairy"不做任何修改
- 10%的概率,替换hairy替换为apple,将句子"my dog is hairy"转化为"my dog is apple"
BERT的预训练任务Next Sentence Prediction(NSP)
NSP(next sentence prediction)任务具体如下。先假设有A和B两个句子。BERT将A和B拼接在一起,具体如下所示, [CLS] A1 A2 A3 … An [SEP] B1 B2 B3 … Bn 。在NSP任务中,BERT会有50%的概率选择相连的两个句子(A和B为上下句)A,B。有50%的概率没有选择到相连的两个句子A,B。通过BERT输入的[CLS]的标志位的输出C判断(预测)句子A下一句是否是B。具体情况如图所示。

BERT代码
Github上的Bert official code
BERT模型效果
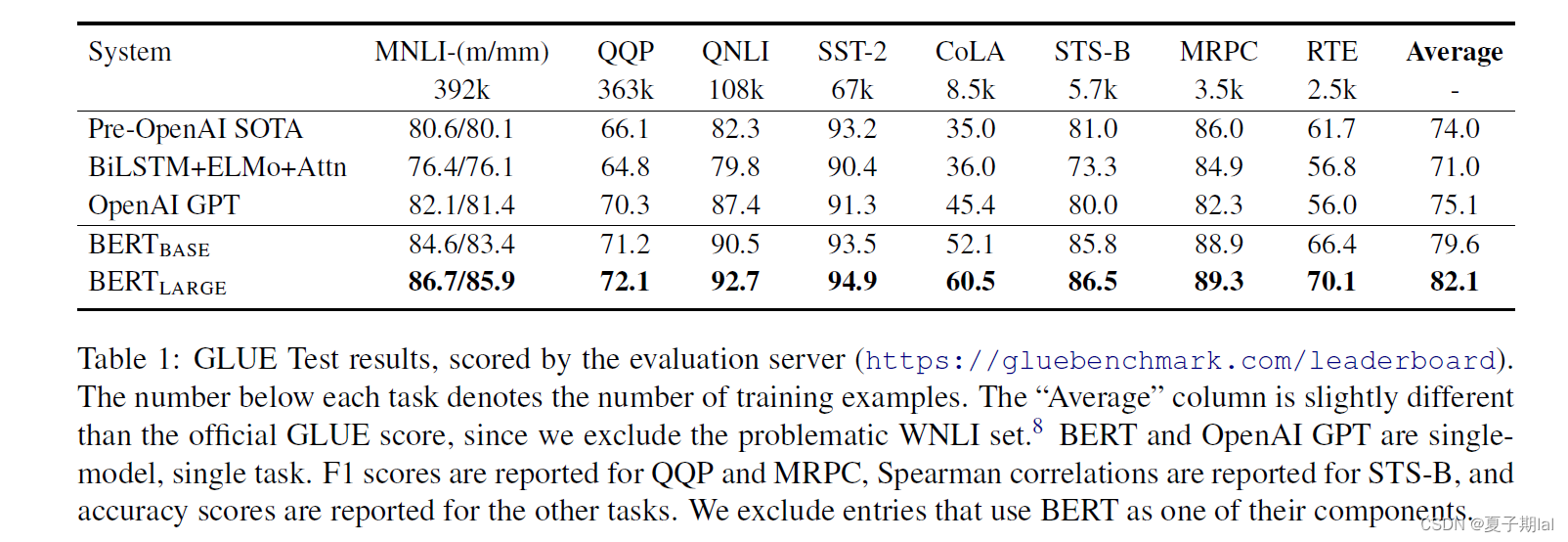
GLUE九个任务的实验结果
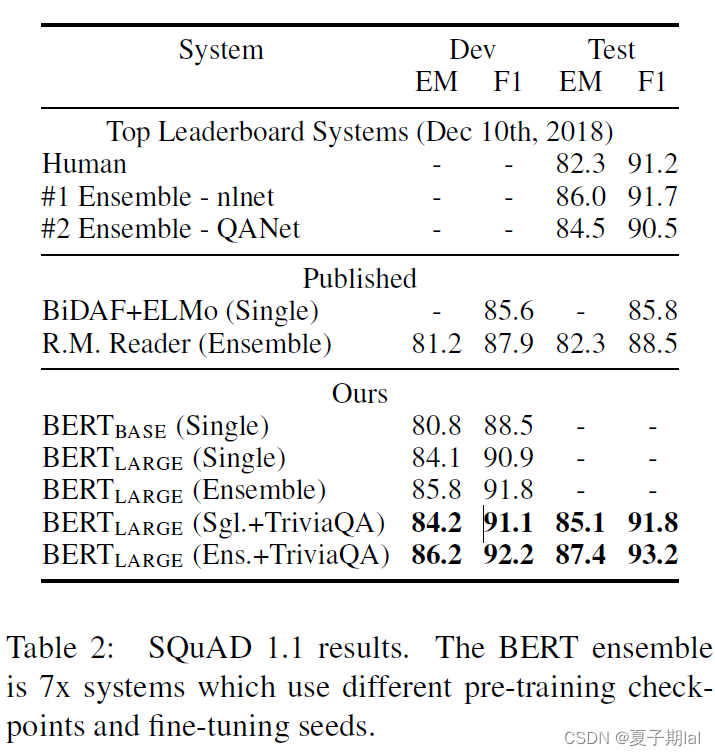
SQuAD1.1任务的实验结果
Big Bird模型
参考
Big Bird
英伟达bert介绍
彻底理解 Google BERT 模型