时间:2023年07月27日
作者:小蒋聊技术
邮箱:wei_wei10@163.com
微信:wei_wei10
【温故而知新】【中间件】Redis为什么这么快?_小蒋聊技术_免费在线阅读收听下载 - 喜马拉雅欢迎收听小蒋聊技术的类最新章节声音“【温故而知新】【中间件】Redis为什么这么快?”。大家好,欢迎来到小蒋聊技术。小蒋准备和大家一起聊聊技术的那些事。文字版材料在CSDN博客,“小蒋聊技术”的同名文章里。文字版地...![]() https://www.ximalaya.com/sound/652066777
https://www.ximalaya.com/sound/652066777
前言
大家好,欢迎来到小蒋聊技术,小蒋准备和大家一起聊聊技术的那些事。
上次咱们一起分析了Java中的线程实现方式,这次咱们来换换,聊一下中间件Redis。
咱们来看这样一个经典面的问题:“Redis为什么这么快?”
分析
Redis 作为优秀的内存数据库,其拥有非常高的性能。在互联网公司经常被用作缓存、分布式数据共享、分布式锁、消息队列,等等功能。官方称单个实例的OPS(Operations Per Second)能够达到10W左右。
这里插一句,官方说的是Redis的OPS,Operations Per Second 可不是QPS。OPS是命令执行速度,这个在Redis实例中可以直接通过命令获得。但是QPS在Redis统计数据里是没有的,一般是由外部测试所得。你一次pipeline几十条命令,OPS按命令条数计数,但是QPS这一次请求可就算一次啊,差别巨大!!!
咱们重新回到这个问题,Redis为什么快?这个问题,已经有很多人都发表了自己的意见和看法。所以小蒋这次分享的是一个“思考问题的思路”,答案其实并不是重点。
咱们来尝试从语言设计和架构的角度来思考,如果你是Redis的“架构师”你会如何回答这个问题呢?
如果你让我回答这个问题Redis为什么快?,我的答案是:“Redis就是快,它的设计思想就是‘快’, ‘快’才是Redis的目标,所以一切在新功能(Feature)的设计和研发过程中,如何‘快’是必须要考虑的问题!”
OK,这是小蒋我个人的理解。
Redis基于C代码实现,其核心思想就是“简单”、“高效”。所以Redis其内部采用了很多高效的机制来进行实现,以保证速度够“快”。很多公司将Redis用作“缓存”,其目的就是提供更快的响应和灵活的数据处理,这正是Redis其价值所在。
那咱们来具体看看Redis的设计思想。
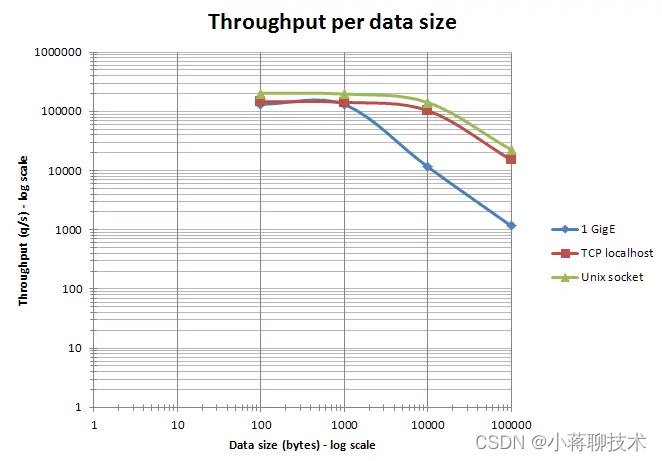
(根据官网的性能测试,当data size处于合适区间时,Redis的吞吐量可达10W/s)
(Redis benchmark | Redis)
Redis设计思想
首先呢,Redis将数据存储在内存中,这样读写数据的时候都不会受到磁盘I/O速度的限制,所以速度极快。也正因为Redis将数据存储在内存中,所有没有磁盘寻道(Disk Seek),另外也不会有访问地址不存在错误(Page Fault),这样将大大提升效率。
咱们说优点明显,缺点一定突出,优缺点是相互的。内存存储虽然速度快,但是缺点就是当服务器宕机或者意外断电等场景发生时,它的数据会全部丢失,这将是一场灾难!所以,在使用Redis的时候,一定,一定要考虑在意外情况下,数据丢失这个场景和相应的处理解决方案!
接下来,咱们再来说说Redis为什么这么快的另外一个原因,那就是它采用单线程,避免了不必要的上下文切换,同时也不存在多进程或者多线导致的用户态和内核态的频繁切换。单线程最大的优点是没有并发的安全问题,同样也不需要加锁,所以他的执行效率高。但,同样的缺点是无法利用多核CPU,线程一旦错误会引起整个应用的错误,健壮性值得考验。
不过,CPU问题,官方FAQ表示,因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用“单线程”的方案了
这里小蒋多嘴插一句,这里我们一直在强调的“单线程”,只是在处理我们的网络请求的时候只有一个线程来处理,一个正式的Redis Server运行的时候肯定是不止一个线程的,这里需要大家明确的注意一下!
咱们再来分析一下Redis的数据结构,Redis其中常见的数据结构类型有:String、List、Set、Hash、ZSet这5种。Redis中的数据结构是专门进行设计的,为的就是快。它的特点是数据结构简单,对数据操作也简单。
先来说String,Redis是C语言开发的,但在C语言中并没有字符串类型,只能使用 指针 和 字符数组 的形式来保存一个字符串。所以Redis设计了一个简单的动态字符串(SDS [Simple Dynamic String])来作为底层实现,时间复杂度:O(1)。
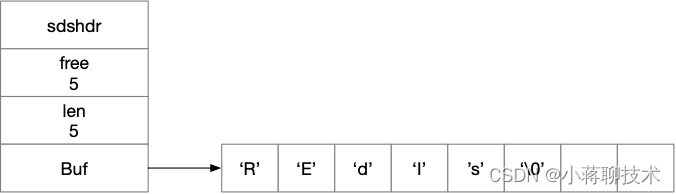
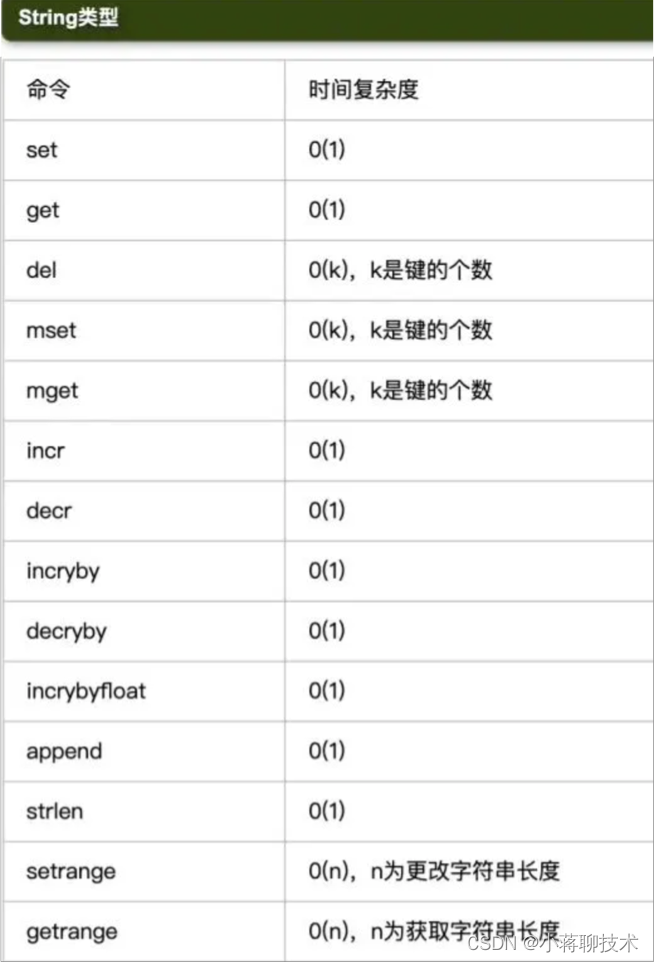
再来说List,列表 List 更多是被当作队列或栈来使用的,队列和栈的特性一个先进先出,一个先进后出。双端链表很好的支持了这些特性。
链表里每个节点(Node)都带有两个指针,prev 指向前节点,next 指向后节点,这样在时间复杂度为 O(1) 内就能快速获取到前后节点(Node)。
链表本身还有head 和 tail 两个参数,分别指向头节点和尾节点,这样的设计能够对双端节点的处理时间复杂度降至 O(1) ,对于队列和栈来说再适合不过。同时链表迭代时从两端都可以进行。
另外Redis对链表长度也进行了设计,头节点里同时还有一个参数 len,和上边提到的 SDS 里类似,这里是用来记录链表长度的。因此获取链表长度时不用再遍历整个链表,直接拿到 len 值就可以了,这个时间复杂度是 O(1)。
从以上这些,咱们可以看到Redis对于底层的数据模型都做了相应的设计,目的就是为了“快”。不过,千万别高兴的太早,一定要记得优点明显,缺点肯定就突出。看到Redis使用了这么多自定义的结构来优化“速度”,那他究竟牺牲了什么呢?
牺牲的是“空间”和“复杂度”,因为一旦使用了额外的数据结构提升速度,那么这个数据结构里一定保存了额外的数据内容和额外的实现算法,这就是它付出的代价。
咱们再来看一下Redis的另外一个快的原因,Redis里大量使用Hash结构,让Redis它接收到一个键值对操作后,能以微秒级速度找到数据,并快速完成操作。
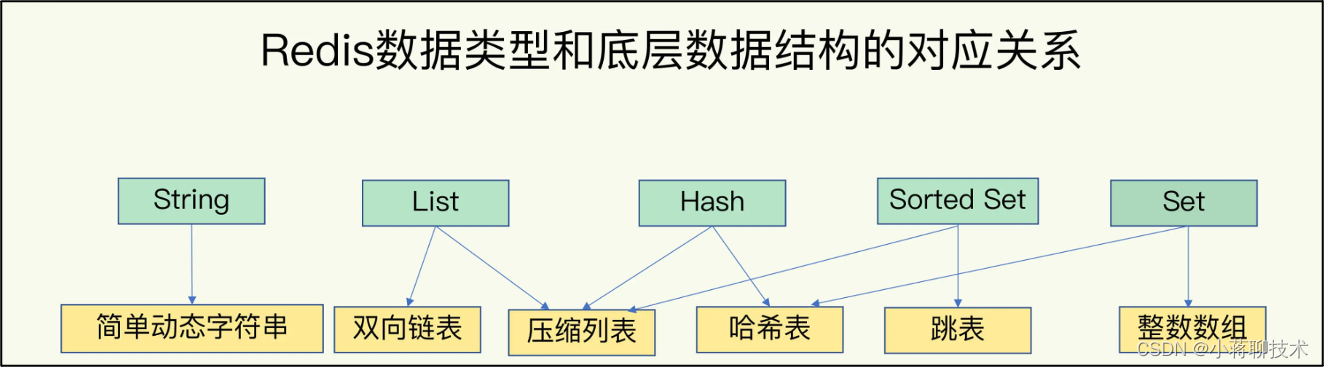
在Redis中咱们知道它是K-V这种数据类型 ,不过List、Hash、Set和Sorted Set这四种数据类型底层都有两种实现,但是它是集合。 咱们可以理解为就是一个KEY对应一个V,但是这个V是“集合”,。
为了实现从K到V快速访问,Redis使用哈希表保存所有KV对。使用哈希表的特点是它的查找时间复杂度是O(1),无论是 10万个K还是100万K,只需一次计算,就能找到对应K的V,这样Redis的速度是不是就非常快。
但是,别高兴太早,咱们刚刚说的是“查询”,除了查询之外还有一个“写入”呢。在实际Redis的生产环境下,因为哈希表的容量是有限的,所以随着Redis不断地向哈希表写入更多数据,这个时候就会发生哈希冲突。Redis的解决方案是通过链式哈希方式解决,也就是数组+链表的方式。
举个例子,在哈希表有限容量的情况下,插入条目1(entry1)、条目2(entry2)、条目3(entry3),但是这三个条目哈希后的结果相同,都是3,那么这三个条目都会放在哈希表中3的位置,也有人称呼为哈希桶3,条目1(entry1)会通过一个*next指向条目2(entry2),条目2(entry2)会通过*next指向条目3(entry3),以此类推。这就形成了一个链表,也叫哈希冲突链。这个哈希冲突链越长,元素查找耗就越慢,效率就会越低。
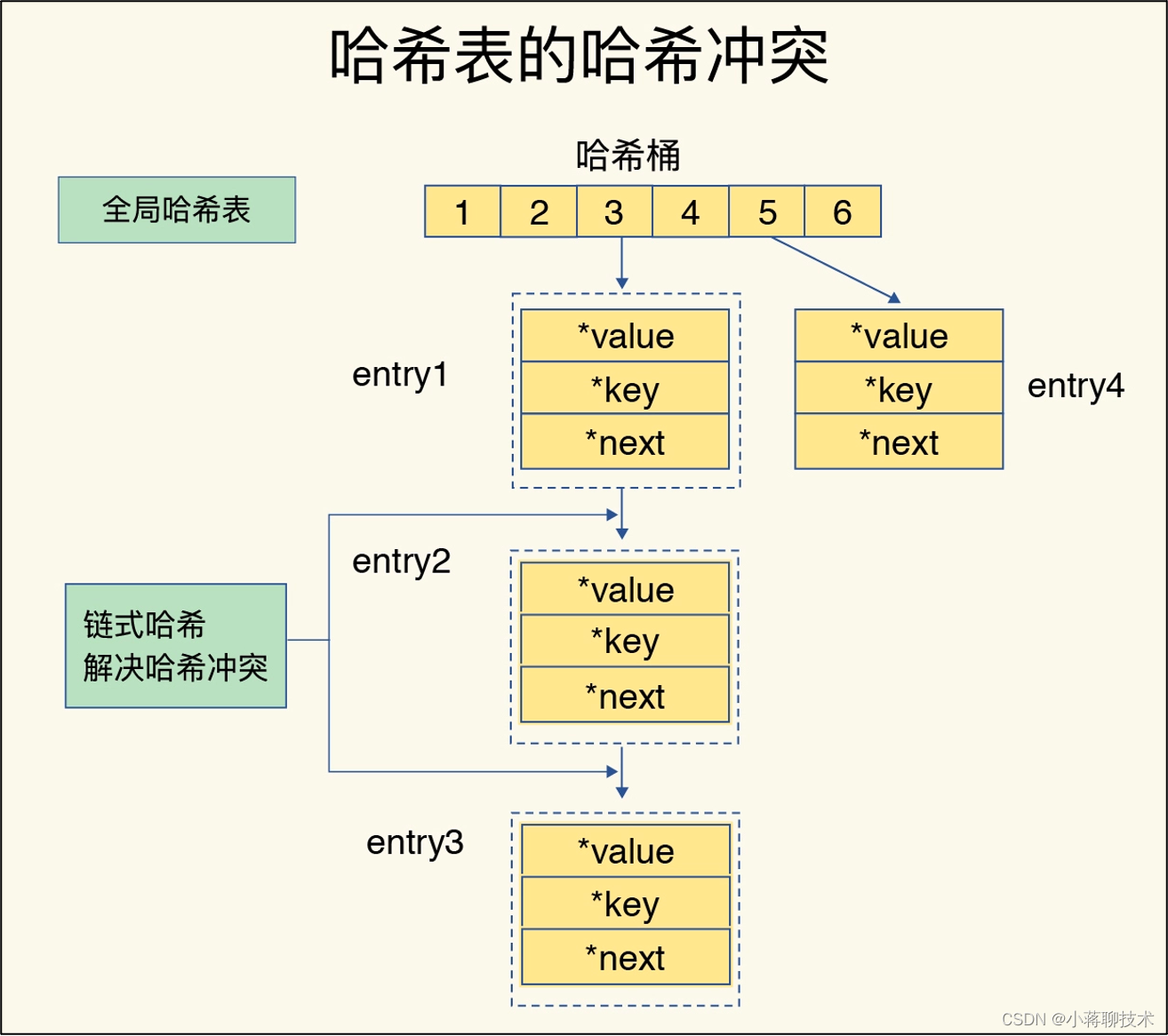
这个,对于目标是“快”的Redis简直是无法容忍的,所以Redis会在必要的时候对哈希表进行扩容,并且对数据进行rehash,让逐渐增多的条目(entry)元素能在更多的桶之间分散保存,减少单个桶中冲突的元素的数量,从而增加查找效率。
理想是丰满的,现实却是骨感的。数据rehash过程中需要把原来哈表中的元素,从旧的位置映射到新的位置,这样就会有大量的数据拷贝。如果一次性全部迁移完成,就会造成Redis线程阻塞,这样Redis就无法服务其他请求了,这种情况和Redis的设计目标“快”严重不符!!!
Redis为了解决这个问题,采用了渐进式rehash的方案,默认使用了2个全局哈希表。
- Redis会給哈希表2分配一个更大的空间,例如扩容到当前哈希表1的2倍大小。
- 紧接着Redis需要把哈当前希表1中的数据重新映射并拷贝到哈希表2种,然后释放哈希表1的空间。
- 但是,Redis为了实现“快”这个设计目标,采用了渐进式rehash。
- Redis会每处理一个请求时,从哈希表1的第一个索引位置开始,将该索引位置的中的全部数据一个接着一个的重新映射并复制到哈希表2中。
- Redis在处理下一个请求时,再处理哈希表1的下一个索引位置。
- 以此类推,Redis就把一次大的数据拷贝分摊到无数次的请求处理过程中。
- 从而通过空间换时间,一次换多次的方式,让Redis实现“快”这个设计目标。
小蒋简单的翻译一下,Redis其实就是牺牲空间换取速度,直接采用了2个全局哈希表。再牺牲简单的一次性数据拷贝方案,把数据拷贝分散到无数次的请求处理中化整为零,但是这无疑牺牲了数据拷贝的处理效率,让数据拷贝的总时间变得更长,同时增加了系统设计复杂度和实现难度,在集群场景中渐进式rehash也会导致数据倾斜的问题。
优点明显,缺点肯定就突出。
总结
之所以Redis这么快,是因为:
- Redis基于存内存操作,没有耗时的磁盘IO,所以大大提升了效率;
- Redis是单线程工作,单线程它的优点是工作不存在操作系统的上下文切换(context switch)和锁(lock)操作。
- Redis的每种底层数据模型的复杂度都很低一般为O(1)及O(N),且采用了空间换时间的方式,集合类型的object都有一个字段size,读取集合长度时的复杂度为O(1),不需要遍历集合。一切向高性能靠近;
- Redis大量使用哈希;
言而总之,因为Redis的产品定位,决定了Redis它的处理速度必须非常“快”,“快”就是它的产品价值所在。也正是因为这个“快的”特点,所以Redis并不适合海量数据的高性能读写,而更适合有限容量情况下的高性能操作和运算上。所以,缓存、分布式数据共享、分布式锁、计数器、等等,这些是Redis常见的使用场景。
以上是小蒋聊技术的全部分享,谢谢大家!