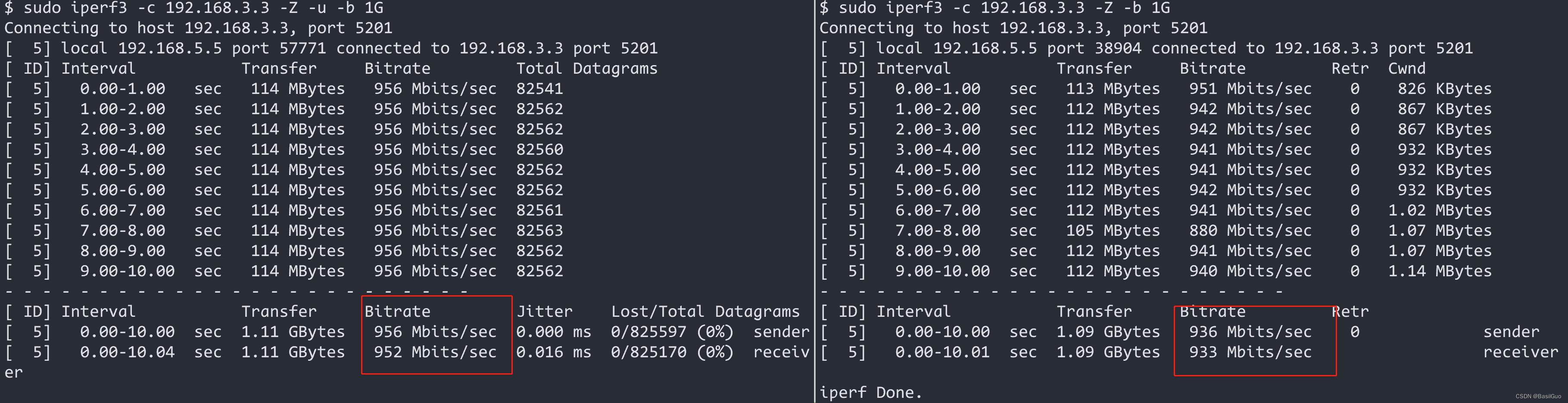
标题:Generative Adversarial Nets
摘要:
简写:作者提出了一个framework通过一个对抗的过程,在这里面会同时训练两个模型。
第一个模型为生成模型G,是用来抓住整个数据的分布
第二个模型为辨别模型D,是用来估计一个样本是否从G中产生。
如果G和D是一个MLP的话,那么真个系统可以通过一个误差反传来整个进行训练
导论:

简写:在这个框架钟有两种模型,一个是生成模型,一个是判别模型。
生成模型就类似于造假的人,制造假币
而判别模型就类似于警察把真币与假币分辨出来。
在这个过程中,造假者会不断提高造假能力,而警察也会不断提高判别能力。
模型:

这个框架最简单的应用是当你的生成器与辨别器都是MLP的时候,生成器要去学习一个叫pg的分布,在数据X上。定义一个先验的pz,把z映射为x。辨别器也有自己的学习参数,作用是把数据放进来,判断数据时来自真实数据还是生成器生成的数据。
min max均衡函数:
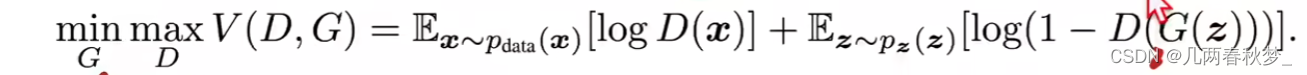
min max:如果达到均衡,则D不能进步,G也无法进步
GAN最后要求的结果:
辨别器对于生成器生成的数据跟真实数据之间在分布上是完全辨别不出来的。
理论结果:

当生成器G是固定的,则 辨别器D的最优解是这么算出来的。
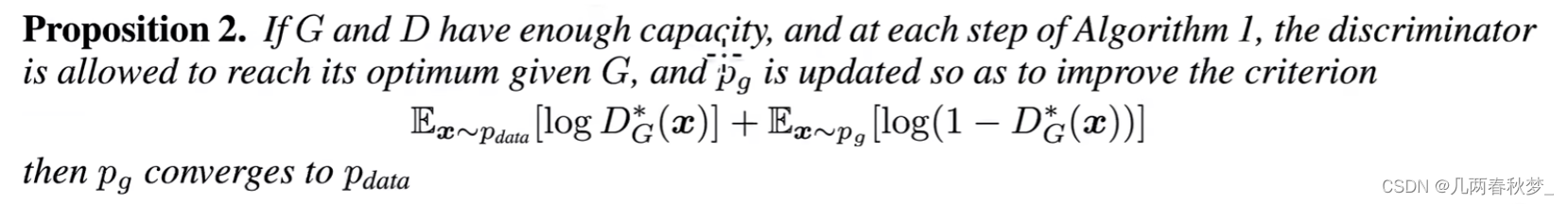
当G与D有足够的容量时, 我们允许每一步D是可以达到最优解,则如果我们对G的优化时区迭代下面这一步骤,则这个G已经换成最优解,那么说最后的Pg会收敛到Pdata。
总结:
写作非常明确,主要关注GAN是在干什么事情。
在相关工作中,写了自己的很多想法,在前人的工作中已经做过了,也说过真正伟大的工作不在乎你的那些想法在别的地方是否已经出现过。
第三块是介绍整个GAN的目标函数以及如何优化
第四块讲了一些证明,为什么目标函数可以得到最优解