文章目录
- cmu 445 poject 1笔记
- Extendible hashing
- LRU-K
- BufferPool Manager
cmu 445 poject 1笔记
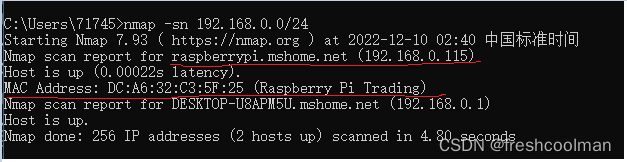
2022年的任务 https://15445.courses.cs.cmu.edu/fall2022/project1/
- extendible hashing
- lru-k
- bufferpool manger
本文不写代码,只记录遇到的一些思维盲点
Extendible hashing
参考说明,见下面的链接1和2。
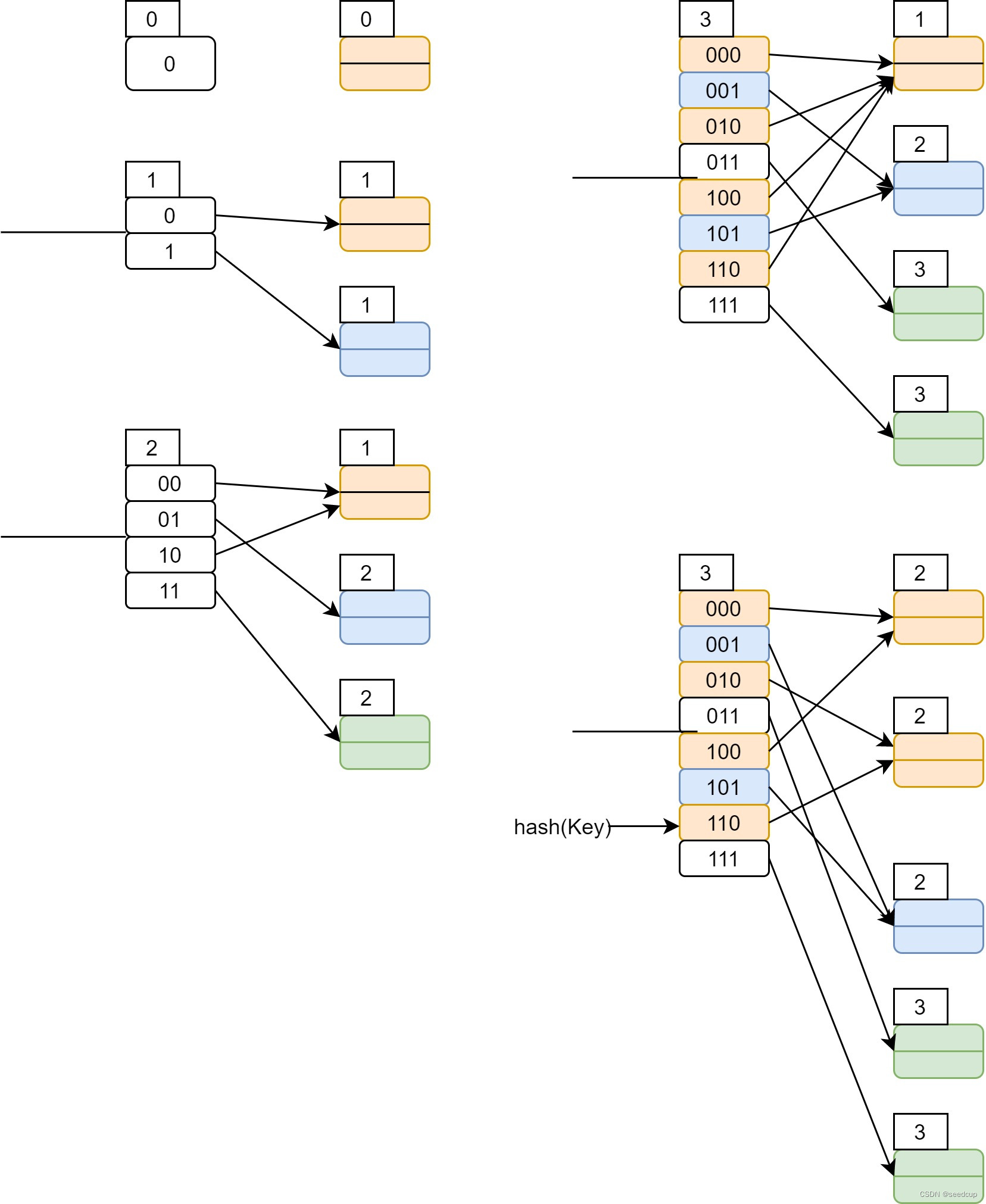
下面就举一个例子说明一下大概流程:
- 左边是bucket目录和global depth
- 右边是bucket和local depth
查找流程:
- 根据key进行hash后对目录总数进行求模就得到了对应的bucket指针
- 然后从bucket里进行查找即可,能找到就找到,找不到就是没有
插入流程:
- 正常插入,跟查询流程一样,先找到bucket,然后bucket插入
- 重点说明下如果bucket满了,怎么处理:
- 如果local depth == global depth
1. 增加global depth
2. bucket目录项翻倍,并且将原来的目录项按顺序拷贝到新的目录项中 - 如果local depth < global depth
1. 拆分旧bucket,此时需要根据第local depth位为0 和为1来将目录项拆分到两个bucket里
- 如果local depth == global depth
例如下面的右图上面,橙色的bucket满了。此时其local depth=1, global depth=3, 并且有4个目录项指向该bucket。
要插入一个key,经过计算后为6(即110),那怎么来拆分这个bucket呢。
- local depth原来为1,表示所有指向该bucket的目录项的值只用看最后一位,并且最后一位肯定是一致的
- local depth新变成2,那就需要看两位了。因此此时跟6的最后两位,即10相同的目录项才会跟6一起共享一个bucket。而之前跟6最后一位相同但是倒数第二位不同的目录项,则应该共享另外一个bucket。
LRU-K
主要踩坑点:
- 历史记录队列是FIFO策略,而非LRU
- 缓存队里是LRU策略
- 如果设置可以弹出的frame id从来没有access记录,那就没必要记它,可能会导致计算可以弹出的个数错误
BufferPool Manager
主要踩的坑有三点:
- unpin时,对于dirty,如果传入的dirty为false,不要将page对应的dirty设置为false了,因为如果之前设置为true,unpin不应该能把它设置为false
- delete时,如果page为dirty的,需要刷盘
- fetch时,如果在缓存中找到了,需要设置一下不能从缓存里弹出
参考:
- https://blog.csdn.net/Altair_alpha/article/details/127745308
- https://www.inlighting.org/archives/cmu-15-445-notes


![[附源码]计算机毕业设计基于Java酒店管理系统Springboot程序](https://img-blog.csdnimg.cn/8b77efbf25c64a7fac9bd35a9e476171.png)