NLP-1-词嵌入(word2vec)
参考:
《动手学深度学习 Pytorch 第1版》第10章 自然语言处理 第1、2、3 和 4节 (词嵌入)
词嵌入 (word2vec):
- 词向量:自然语言中,词是表义的基本单元。词向量是用来表示词的向量。
- 词嵌入 (word embedding):将词映射为实数域向量的技术称为词嵌入。
- 词嵌入出现的原因:由于
one-hot编码的词向量不能准确表达不同词之间的相似度(任何两个不同词的one-hot向量的余弦相似度都为0),为了解决这个问题而出现了词嵌入方法word2vec。word2vec将每个词表示为一个定长的向量,而且这些向量能够表达不同词之间的相似性。word2vec包含两个模型:跳字模型 (skip-gram) 和 连续词袋模型 (continuous bag of words, CBOW)。
skip-gram
skip-gram:基于某个词来生成它在文本序列周围的词,即以某个词为中心,与距离该中心不超过窗口大小的背景词出现的条件概率。- 在
skip-gram中,每个词被表示为两个d维向量(中心词的向量和背景词的向量),用以计算背景词出现的条件概率。 skip-gram训练结束后,对于任意一个索引为i的词,都可得到该词为中心词和背景词的两组向量 v i v_i vi和 u i u_i ui。- 在 NLP 中,一般使用
skip-gram的中心词向量作为词的表征向量。
CBOW
CBOW与skip-gram类似,但最大区别在于CBOW基于某个中心词在文本序列前后的背景词来生成该中心词。【简单来说:skip-gram假设基于中心词来生成背景词;CBOW假设基于背景词来生成中心词】CBOW中,因为背景词有多个,所以将这些背景词向量取平均,再使用和skip-gram一样的方法计算条件概率。- 在 NLP 中,一般使用
CBOW的背景词向量作为词的表征向量。
word2vec 的整个过程实现:
1. word2vec 的数据集的预处理:
所用数据集是 Penn Tree Bank (PTB),该语料库曲取自“华尔街日报”。
1.1 下载数据集:
## 导入模块
import math
import os
import random
import torch
from d2l_model import d2l_torch as d2l
## 使用 d2l 封装的方法下载 PTB 数据集
d2l.DATA_HUB["ptb"] = (d2l.DATA_URL + 'ptb.zip',
'319d85e578af0cdc590547f26231e4e31cdf1e42')
def read_ptb():
data_dir = d2l.download_extract("ptb") ## 该方法用来读取zip或者tar文件,返回的数据所在的路径
with open(os.path.join(data_dir, "ptb.train.txt")) as f:
raw_text = f.read()
return [line.split() for line in raw_text.split("\n")] ## 返回文本中每一行句子中以空格分开的每个词所构成的列表
#sentences = read_ptb()
#f'# sentences数: {len(sentences)}'
1.2 下采样:
删掉文本中某些高频词,缩短句子长度,加快训练。
def subsample(sentences, vocab):
sentences = [[token for token in line if vocab[token]!=vocab.unk]
for line in sentences] ## 如果 token 不是 <unk> 的话,就会被保留下来
counter = d2l.count_corpus(sentences) ## 统计 token 出现的次数
num_tokens = sum(counter.values())
def keep(token):
return (random.uniform(0,1) < math.sqrt(1e-4 / counter[token]*num_tokens)) ## 如果满足条件,则返回True
return ([[token for token in line if keep(token)] for line in sentences],
counter)
1.3 中心词和上下文词的提取:
从 corpus 中提取所有中心词和上下文词。
随机采样[1:max_window_size]之间的证书作为上下文窗口。
对于任意一个中心词,与其不超过上下文窗口大小的词为它的上下文词。
def get_centers_and_contexts(corpus, max_window_size):
centers, contexts = [], []
for line in corpus:
if len(line) < 2: ## 要构成“中心词-上下文词”对,每个句子至少有2个词
continue
centers += line ## 所有句子中的每一个词都可作为中心词
for i in range(len(line)):
window_size = random.randint(1, max_window_size) ## 生成一个随机整数作为窗口大小
indices = list(range(max(0, i-window_size), min(len(line), i+1+window_size))) ## 以i为中心,获取[i-window: i+window]范围内的词
indices.remove(i) ## 去掉中心词i本身,剩下上下文词
contexts.append([line[idx] for idx in indices])
return centers, contexts
1.4 负采样:
使用负采样进行近似训练,根据定义的分布对噪声词进行采样。
class RandomGenerator:
def __init__(self, sampling_weights):
self.population = list(range(1, len(sampling_weights)+1))
self.sampling_weights = sampling_weights
self.candidates = []
self.i = 0
def draw(self):
if self.i == len(self.candidates):
## 缓存 k 个随机采样结果,每次从里面取一个,取完后再生成新的缓存结果
self.candidates = random.choices(self.population, self.sampling_weights, k=10000) ## 按照 sampling_weight 采样概率对 population 进行采样,采样k次
self.i = 0
self.i += 1
return self.candidates[self.i-1]
## 负采样
def get_negatives(all_contexts, vocab, counter, K):
sampling_weights = [counter[vocab.to_tokens(i)]**0.75 for i in range(1, len(vocab))] ## 采样权重 = token出现次数 * 0.75
all_negatives, generator = [], RandomGenerator(sampling_weights)
for contexts in all_contexts:
negatives = []
while len(negatives) < len(contexts) * K: ## K 对于一对“中心词-上下文词”,随机抽取的噪声词的个数
neg = generator.draw()
if neg not in contexts: ## 噪声词不能是该中心词的上下文词,其他的上下文词是可以的
negatives.append(neg)
all_negatives.append(negatives)
return all_negatives
1.5 定义 dataloader 的处理方式:
class PTBDataset(torch.utils.data.Dataset):
def __init__(self, centers, contexts, negatives):
assert len(centers) == len(contexts) == len(negatives) ## 不成立则引发AssertionError
self.centers = centers
self.contexts = contexts
self.negatives = negatives
def __getitem__(self, index):
return (self.centers[index], self.contexts[index], self.negatives[index])
def __len__(self):
return len(self.centers)
def batchify(data):
max_len = max(len(c) + len(n) for _, c, n in data) ## 因为不同中心词对应的上下文、负采样的向量长度不一样,所以按照最长的进行填充
centers, contexts_negatives, masks, labels = [], [], [], []
for center, context, negative in data: ## 中心词、上下文、负采样
cur_len = len(context) + len(negative)
centers += [center]
contexts_negatives += [context + negative + [0]*(max_len - cur_len)] ## 用0进行填充
masks += [[1]*cur_len + [0]*(max_len - cur_len)] ## 填充部分用0标记,非填充部分用1标记 (主要用于计算损失时,填充部分不参与计算)
labels += [[1]*len(context) + [0]*(max_len - len(context))] ## 标签,上下文词为1,其他(负采样部分、填充部分)为0
return (torch.tensor(centers).reshape((-1,1)),\
torch.tensor(contexts_negatives),\
torch.tensor(masks),\
torch.tensor(labels)) ## reshape((-1,1)) => .shape=(n,1)
## 中心词(centers), 上下文及负采样(context_negatives), 掩码(masks),标签(labels)
代码合并及数据集的生成:
包括上面的1.1, 1.2, 1.3, 1.4, 1.5
def load_data_ptb(batch_size, max_window_size, num_noise_words):
#num_workers = d2l.get_dataloader_workers() ## 使用4个进程读取数据(但实际操作会出错)
sentences = read_ptb() ## 第一步的读取数据
vocab = d2l.Vocab(sentences, min_freq=10) ## 第一步中用 "<unk>" 替换低频词
subsampled, counter = subsample(sentences, vocab) ## 第二步下采样,去掉某些意义不大的高频词,缩短句子长度
corpus = [vocab[line] for line in subsampled] ## 第二步将下采样后的句子映射为词表中的索引
all_centers, all_contexts = get_centers_and_contexts(corpus, max_window_size) ## 第三步,中心词和上下文词(上或下文词数目不超过max_window_size)
all_negatives = get_negatives(all_contexts, vocab, counter, num_noise_words) ## 第四步负采样,生成噪声词
dataset = PTBDataset(all_centers, all_contexts, all_negatives)
data_iter = torch.utils.data.DataLoader(
dataset, batch_size, shuffle=True,
collate_fn=batchify, ## collate_fn 定义了小批量数据加载后需要做的处理(可见http://t.csdn.cn/4zhEj 的评论)
num_workers=0
)
return data_iter, vocab
## 生成数据集
batch_size, max_window_size, num_noise_words = 512, 5, 5
data_iter, vocab = load_data_ptb(batch_size, max_window_size, num_noise_words)
2. 预训练 word2vec:
构建并训练模型。
from torch import nn
2.1 构建嵌入层:
- 嵌入层将词元的索引映射到其特征向量 (上面数据预处理已经得到了词元的索引)。
- 嵌入层的权重是一个矩阵,行数等于字典大小,列数等于向量的维数。
- 在嵌入层训练完成之后,权重矩阵就是所需要的。每一行都是一个词的特征向量。
- 该层的输入就是词元的索引,对于任何词元索引 i i i,其向量表示可以从嵌入层中的权重矩阵的第 i i i行获得。
2.2 定义 skip-gram:
通过 embedding 层将索引映射为特征向量。
def skip_gram(center, contexts_and_negatives, embed_v, embed_u):
v = embed_v(center)
u = embed_u(contexts_and_negatives)
pred = torch.bmm(v, u.permute(0,2,1))
return pred
2.3 定义二元交叉熵损失函数:
class SigmoidBCELoss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, inputs, target, mask=None):
out = nn.functional.binary_cross_entropy_with_logits(
inputs, target, weight=mask, reduce="none"
)
return out.mean()
loss = SigmoidBCELoss()
2.3 定义初始化模型参数:
## 两个嵌入层,特征向量维度为100
## 第一层计算中心词,第二层计算上下文词
embed_size = 100
net = nn.Sequential(nn.Embedding(num_embeddings=len(vocab),
embedding_dim=embed_size),
nn.Embedding(num_embeddings=len(vocab),
embedding_dim=embed_size))
2.4 训练:
## 定义训练函数
def train(net, data_iter, lr, num_epochs, device=d2l.try_gpu()):
## 模型初始化
def init_weights(m):
if type(m) == nn.Embedding:
nn.init.xavier_uniform_(m.weight) ## 函数最后有一个下划线表示该函数输出直接替换
net.apply(init_weights)
net = net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
animator = d2l.Animator(xlabel="epoch", ylabel="loss", xlim=[1, num_epochs]) ## 训练过程中的 epoch-loss 进行可视化
metric = d2l.Accumulator(2) ## 加快求和计算的速度
for epoch in range(num_epochs):
timer, num_batches = d2l.Timer(), len(data_iter)
for i, batch in enumerate(data_iter):
optimizer.zero_grad()
center, conter_negative, mask, label = [data.to(device) for data in batch]
pred = skip_gram(center, conter_negative, net[0], net[1])
l = (loss(pred.reshape(label.shape).float(), label.float(), mask) / mask.sum(axis=1)*mask.shape[1])
l.sum().backward()
optimizer.step()
metric.add(l.sum(), l.numel())
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i+1)/num_batches, (metric[0]/metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, '
f'{metric[1] / timer.stop():.1f} tokens/sec on {str(device)}')
## 进行训练
lr, num_epochs = 0.001, 10
train(net, data_iter, lr, num_epochs)
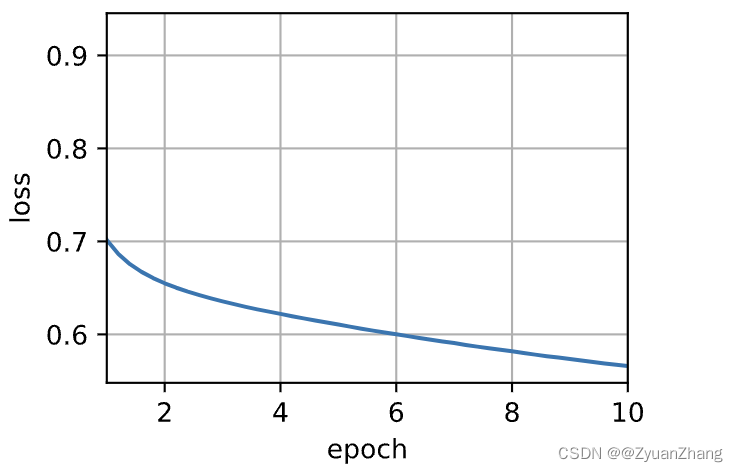
loss 0.566, 223737.2 tokens/sec on mps
3. 使用预训练的word2vec寻找语义上相近的词:
def get_similar_tokens(query_token, k, embed):
W = embed.weight.data ## 我们预训练词嵌入就是为了得到这个权重矩阵,该权重矩阵就是由每个词的特征向量构成的
x = W[vocab[query_token]]
## 计算余弦相似度
cos = torch.mv(W,x) / torch.sqrt(torch.sum(W*W, dim=1) * torch.sum(x*x)+1e-9)
topk = torch.topk(cos, k=k+1)[1].cpu().numpy().astype("int32")
for i in topk[1:]:
print(f'cosine sim={float(cos[i]):.3f}: {vocab.to_tokens(i)}')
get_similar_tokens('chip', 3, net[0])
cosine sim=0.777: intel
cosine sim=0.714: bugs
cosine sim=0.647: computer



![[SSM]Spring中的JdbcTemplate](https://img-blog.csdnimg.cn/feb255d32aee4bc98a20af59da798062.png)