CMU 15-445 -- Multi-Version Concurrency Control - 16
- 引言
- MVCC
- Example #1
- Example #2
- 小结
- Design Decisions
- Concurrency Control Protocol
- Version Storage
- Append-Only Storage
- Time-Travel Storage
- Delta Storage
- Garbage Collection
- Tuple-Level GC
- Transaction-Level GC
- Index Management
- Primary Key Index
- Secondary Indexes
- MVCC Implementations
- Mvcc delete
- Mvcc indexes
- 重复键问题
- 小结
- Conclusion
引言
本系列为 CMU 15-445 Fall 2022 Database Systems 数据库系统 [卡内基梅隆] 课程重点知识点摘录,附加个人拙见,同样借助CMU 15-445课程内容来完成MIT 6.830 lab内容。
简而言之,实现 MVCC 的 DBMS 在内部维持着单个逻辑数据的多个物理版本,当事务修改某数据时,DBMS 将为其创建一个新的版本;当事务读取某数据时,它将读到该数据在事务开始时刻之前的最新版本。
MVCC 首次被提出是在 1978 年的一篇 MIT 的博士论文中。在 80 年代早期,DEC 的 Rdb/VMS 和 InterBase 首次真正实现了 MVCC,其作者是 Jim Starkey,NuoDB 的联合创始人。如今,Rdb/VMS 成了 Oracle Rdb,InterBase 成为开源项目 Firebird。
MVCC
MVCC 的核心优势可以总结为以下两句话:
Writers don’t block readers. 写不阻塞读
Readers don’t block writers. 读不阻塞写
只读事务无需加锁就可以读取数据库某一时刻的快照,如果保留数据的所有历史版本,DBMS 甚至能够支持读取任意历史版本的数据,即 time-travel。
Example #1
事务 T1 和 T2 分别获得时间戳 1 和 2,二者的执行过程如下图所示。开始前,数据库存有数据 A 的原始版本 A0 , T1 先读取 A 数据:

然后 T2修改 A 数据,这时 DBMS 中将增加 A 数据的新版本 A1,同时标记 A1的开始时间戳为 2, A0 的结束时间戳为 2:
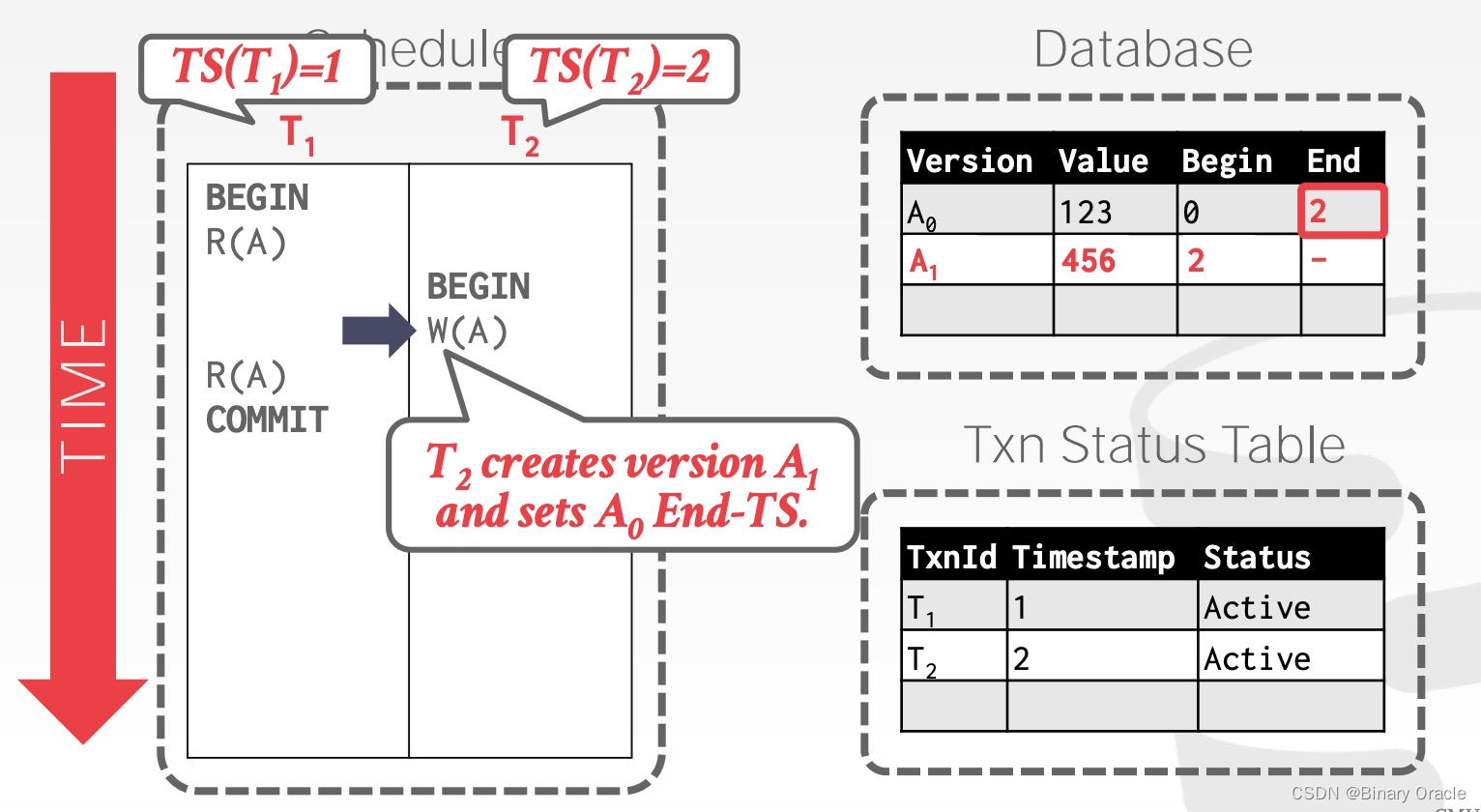
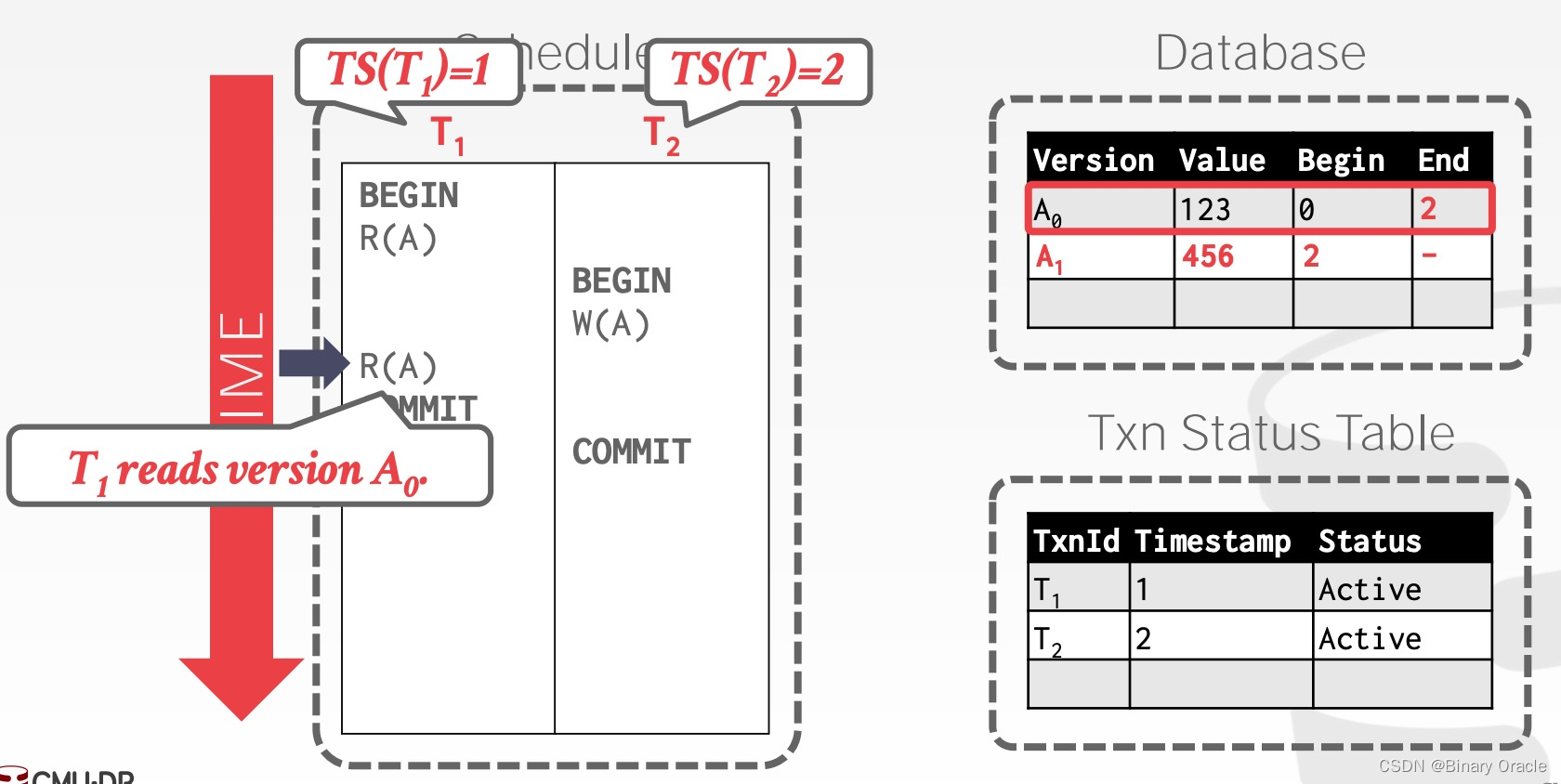
T1再次读取 A,因为它的时间戳为 1,根据记录的信息,DBMS 将 A0返回给 T1 :
Example #2
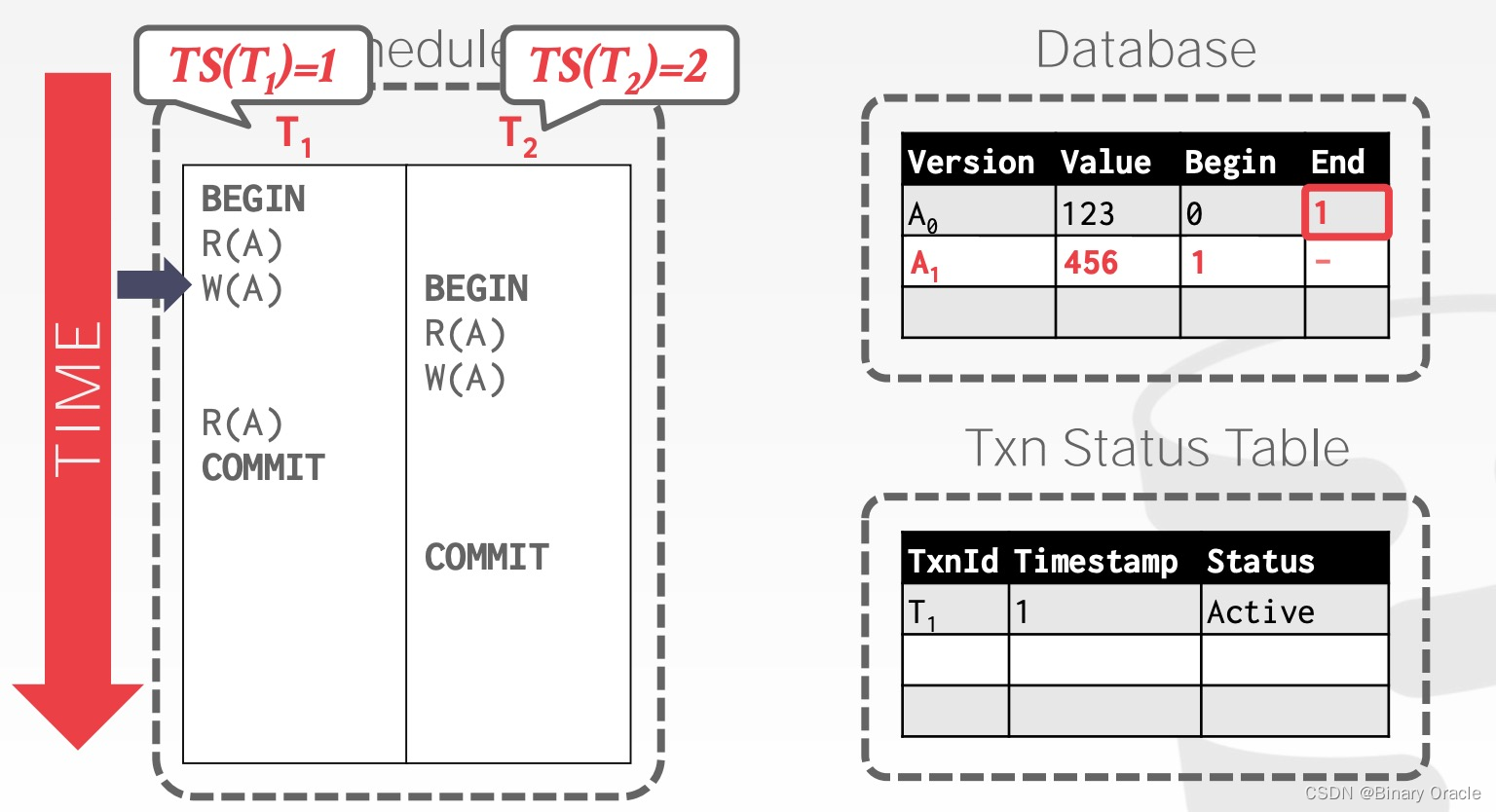
例 2 与例 1 类似,T1先修改数据 A:
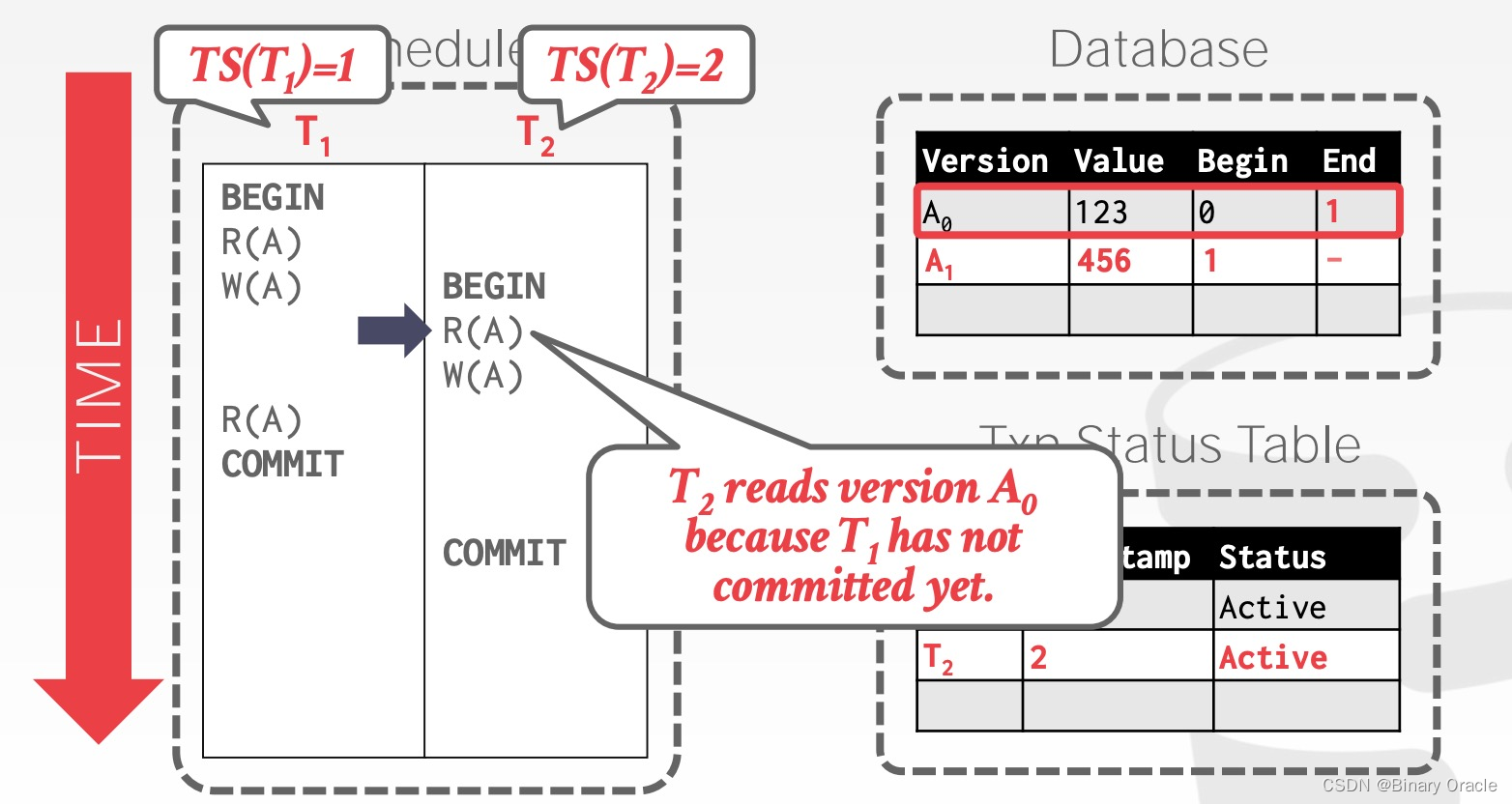
此时 T2 读取 A,由于 T1 尚未提交, T2 只能读取 A0:
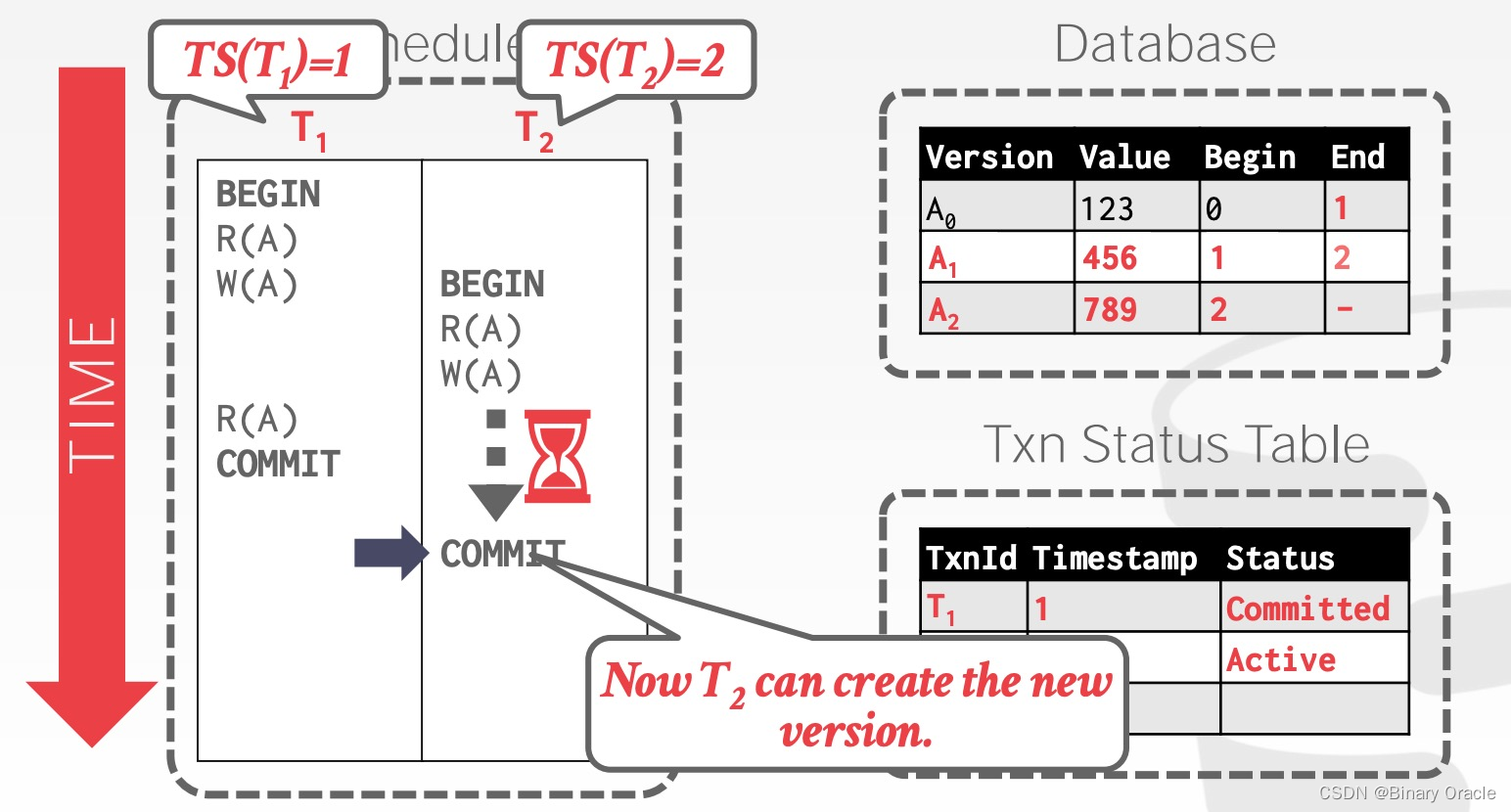
T2想修改 A,但由于有另一个活跃的事务 T1正在修改 A , T2 需要等待 T1提交后才能继续推进:

T1 提交后, T2 创建了 A 的下一个版本 A2:
小结
MVCC 并不只是一个并发控制协议,并发控制协议只是它的一个组成部分。它深刻地影响了 DBMS 管理事务和数据的方式,使用 MVCC 的 DBMS 数不胜数:

Design Decisions
上文提到,MVCC 不止是一个并发控制协议,它由许多部分组成,这些部分包括:
- Concurrency Control Protocol
- Version Storage
- Garbage Collection
- Index Management
每一部分都可以选择不同的方案,可以根据具体场景作出最优的设计选择。
Concurrency Control Protocol
前面 2 节课已经介绍了各种并发控制协议,MVCC 可以选择其中任意一个:
Approach #1: Timestamp Ordering (T/O):为每个事务赋予时间戳,并用以决定执行顺序
Approach #2: Optimistic Concurrency Control (OCC):为每个事务创建 private workspace,并将事务分为 read, write 和 validate 3 个阶段处理
Approach #3: Two-Phase Locking (2PL):按照 2PL 的约定获取和释放锁
Version Storage
如何存储一条数据的多个版本?DBMS 通常会在每条数据上拉一条版本链表 (version chain),所有相关的索引都会指到这个链表的 head,DBMS 可以利用它找到一个事务应该访问到的版本。不同的版本存储方案在 version chain 上存储的数据不同,主要有 3 种存储方案:
Approach #1: Append-Only Storage:新版本通过追加的方式存储在同一张表中
Approach #2: Time-Travel Storage:老版本被复制到单独的一张表中
Approach #3: Delta Storage:老版本数据的被修改的字段值被复制到一张单独的增量表 (delta record space) 中
Append-Only Storage
如下图所示,同一个逻辑数据的所有物理版本都被存储在同一张表上,每次更新时,就往表上追加一个新的版本记录,并在旧版本的数据上增加一个指针指向新版本:
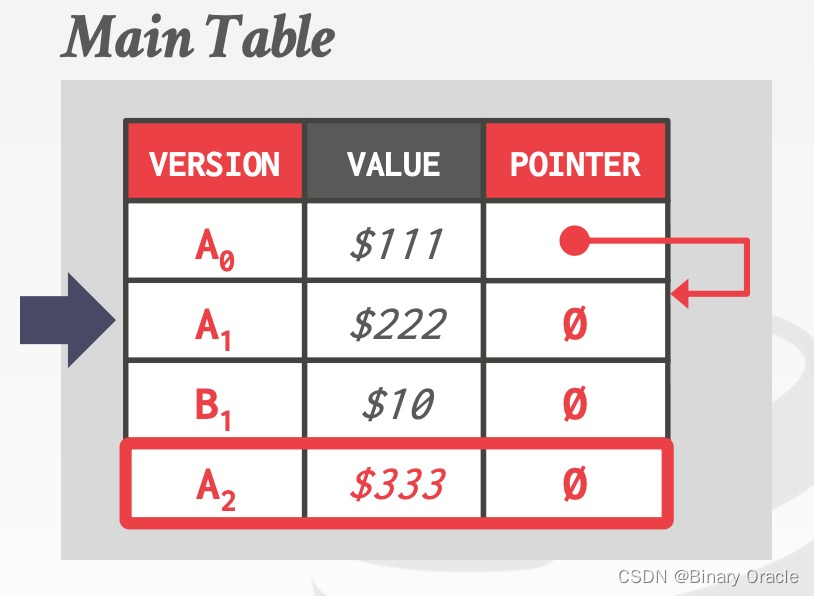
再次更新的行为类似:
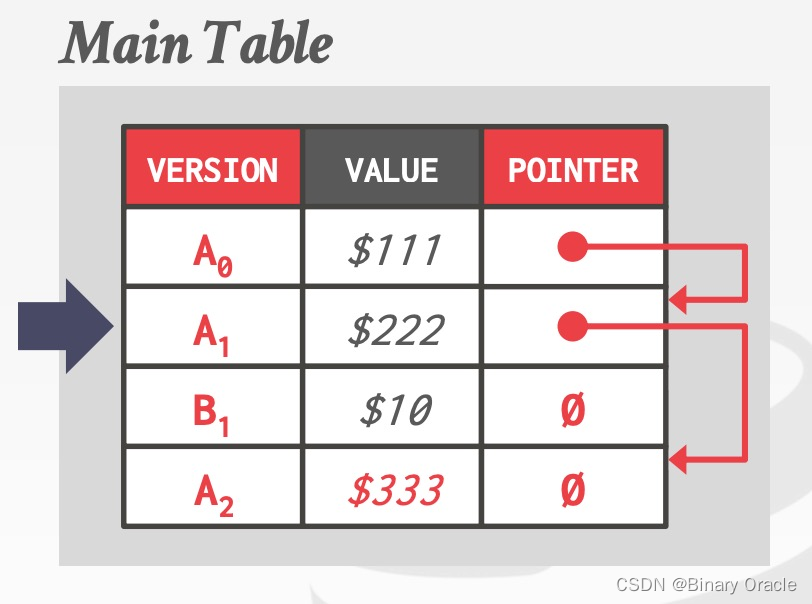
也许你已经注意到,指针的方向也可以从新到旧,二者的权衡如下:
-
Approach #1:Oldest-to-Newest (O2N):写的时候追加即可,读的时候需要遍历链表
-
Approach #2:Newest-to-Oldest (N2O):写的时候需要更新所有索引指针,读的时候不需要遍历链表
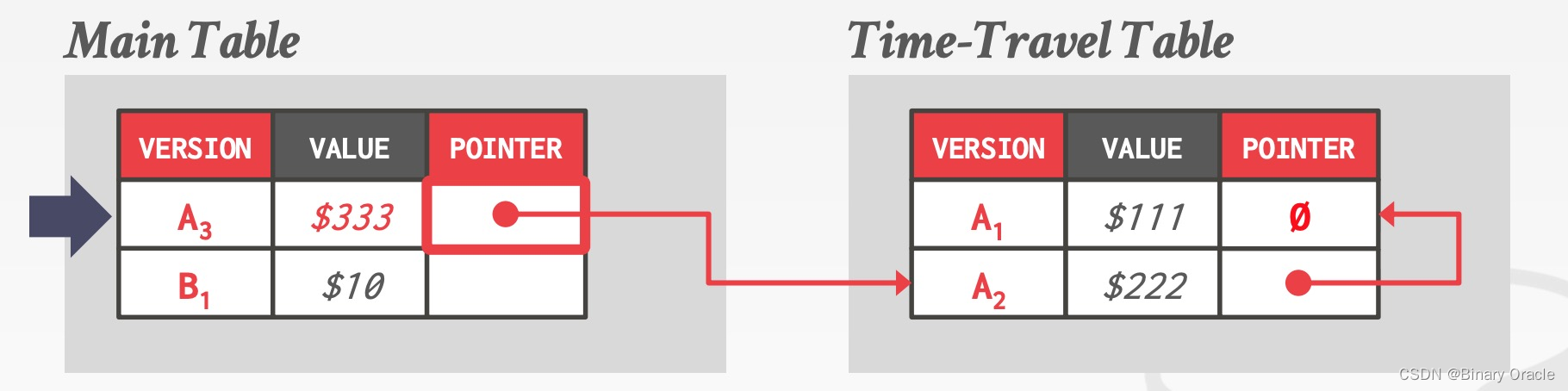
Time-Travel Storage
单独拿一张表 (Time-Travel Table) 来存历史数据,每当更新数据时,就把当前版本复制到 TTT 中,并更新指针:
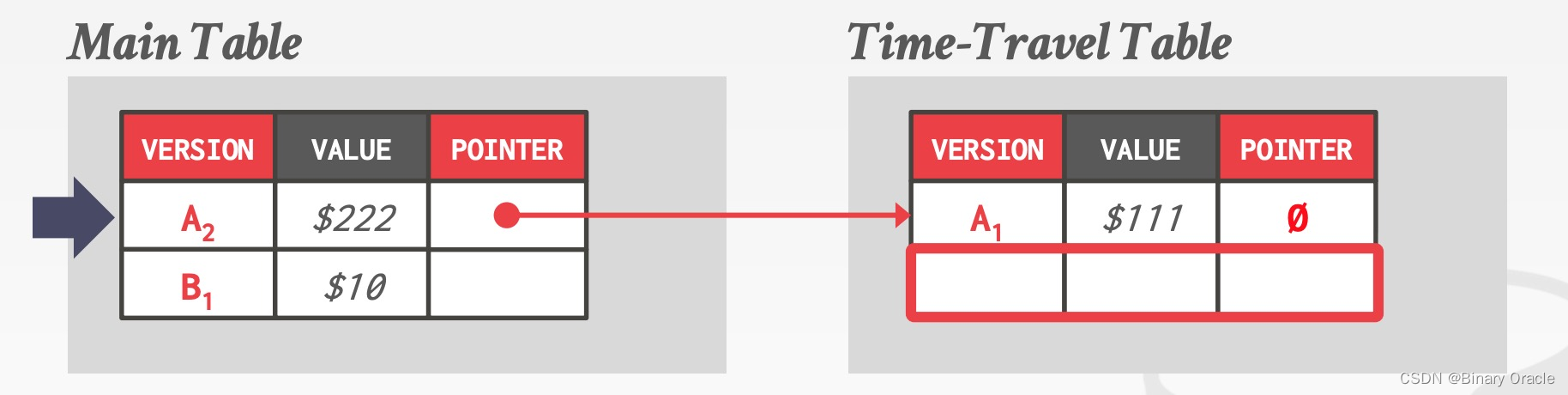
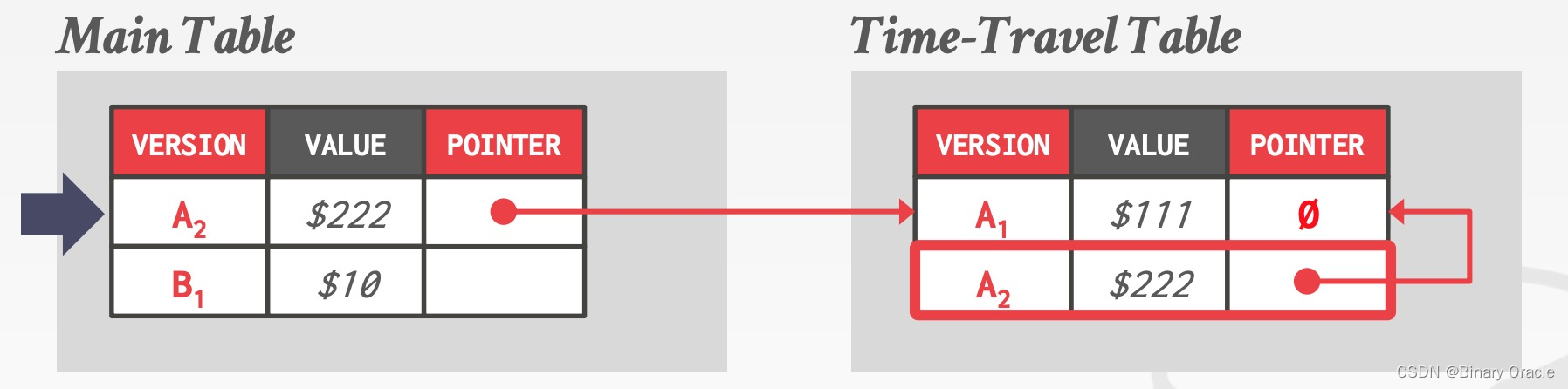
Delta Storage
每次更新,仅将变化的字段信息存储到 delta storage segment 中:
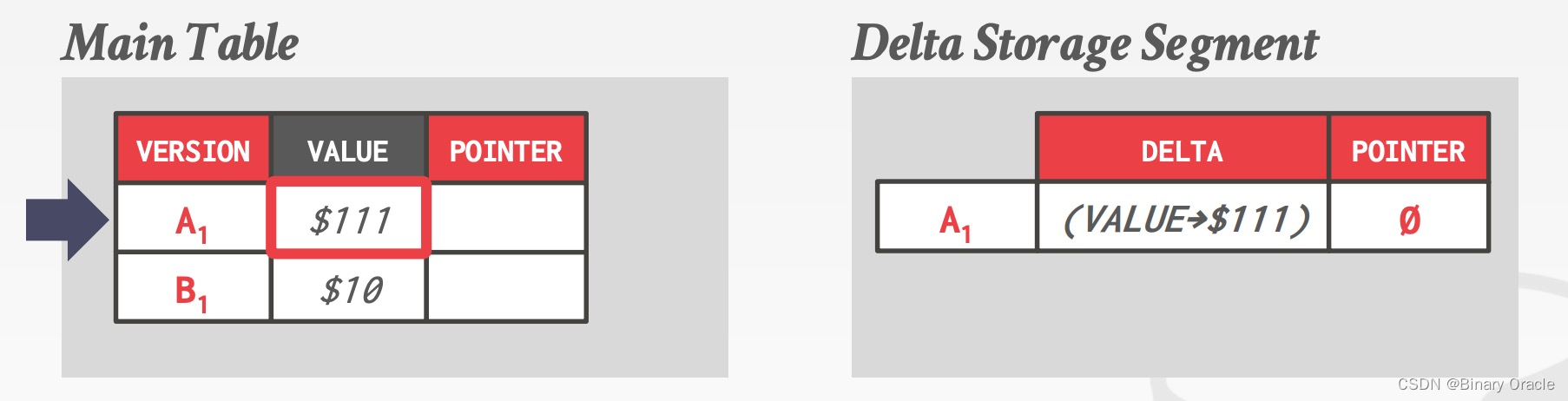

DBMS 可以通过 delta 数据逆向恢复数据到之前的版本。
Garbage Collection
随着时间的推移,DBMS 中数据的旧版本可能不再会被用到,如:
- 已经没有活跃的事务需要看到该版本
- 该版本是被一个已经中止的事务创建
这时候 DBMS 需要删除这些可以回收的物理版本,这个过程也被称为 GC。在 GC 的过程中,还有两个附加设计决定:
- 如何查找过期的数据版本
- 如何确定某版本数据是否可以被安全回收
GC 可以从两个角度出发:
- Approach #1:Tuple-level:直接检查每条数据的旧版本数据
- Approach #2:Transaction-level:每个事务负责跟踪数据的旧版本,DBMS 不需要亲自检查单条数据
Tuple-Level GC
Background Vacuuming
如下图所示,假设有 2 个活跃事务,它们的时间戳分别为 12 和 25:
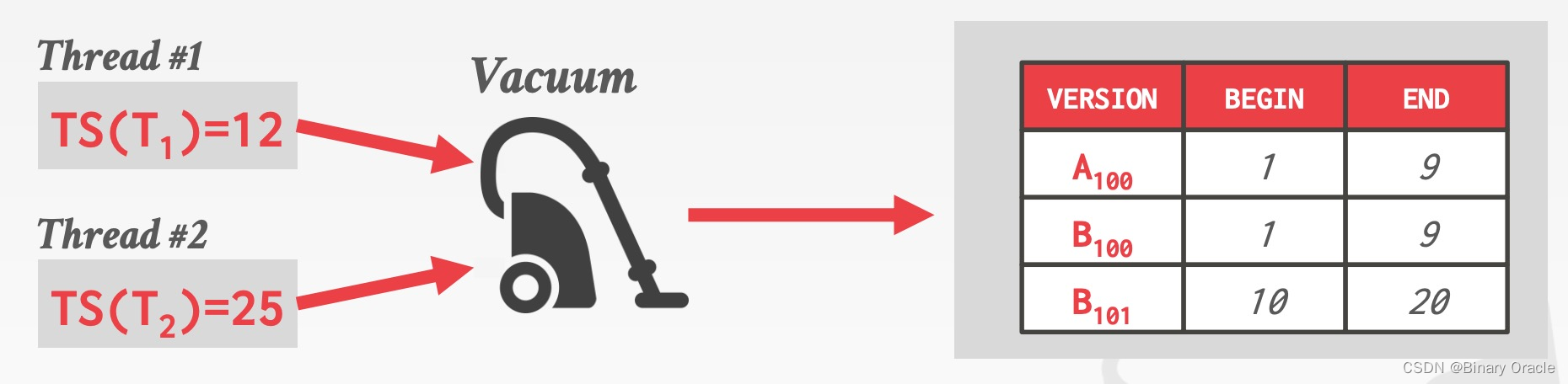
这时有个 Vacuum 守护线程会周期性地检查每条数据的不同版本,如果它的结束时间小于当前活跃事务的最小时间戳,则将其删除:
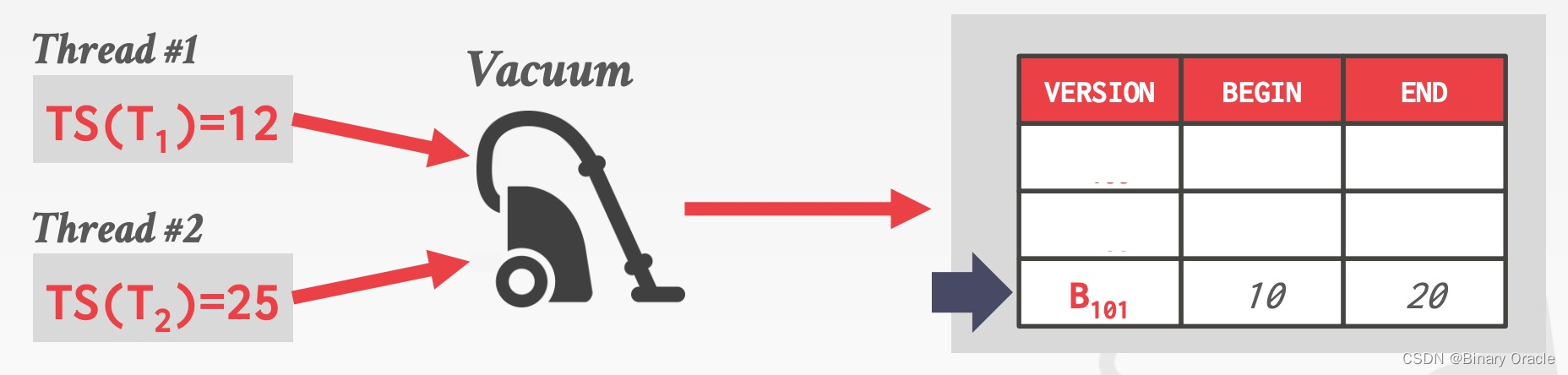
为了加快 GC 的速度,DBMS 可以再维护一个脏页位图 (dirty page bitmap),利用它,Vacuum 线程可以只检查发生过改动的数据,用空间换时间。Background Vacuuming 被用于任意 Version Storage 的方案。
Cooperative Cleaning
还有一种做法是当 worker thread 查询数据时,顺便将不再使用物理数据版本删除:


cooperative cleaning 只能用于使用 O2N 的 version chain 方案。
Transaction-Level GC
让每个事务都保存着它的读写数据集合 (read/write set),当 DBMS 决定什么时候这个事务创建的各版本数据可以被回收时,就按照集合内部的数据处理即可。
Index Management
Primary Key Index
主键索引直接指向 version chain 的头部。
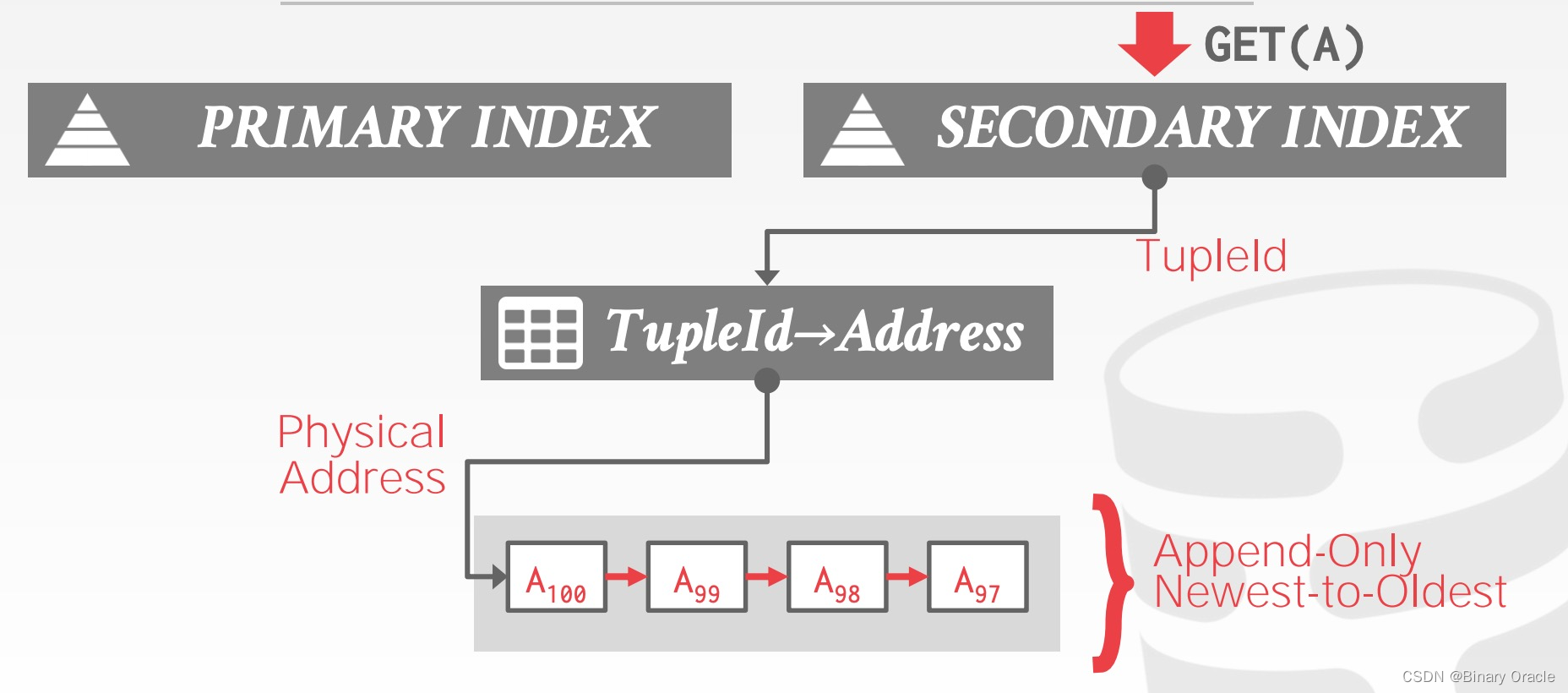
Secondary Indexes
二级索引有两种方式指向数据本身:
- Approach #1:逻辑指针,即存储主键值或 Tuple Id
- Approach #2:物理指针,即存储指向 version chain 头部的指针
Physical Pointer
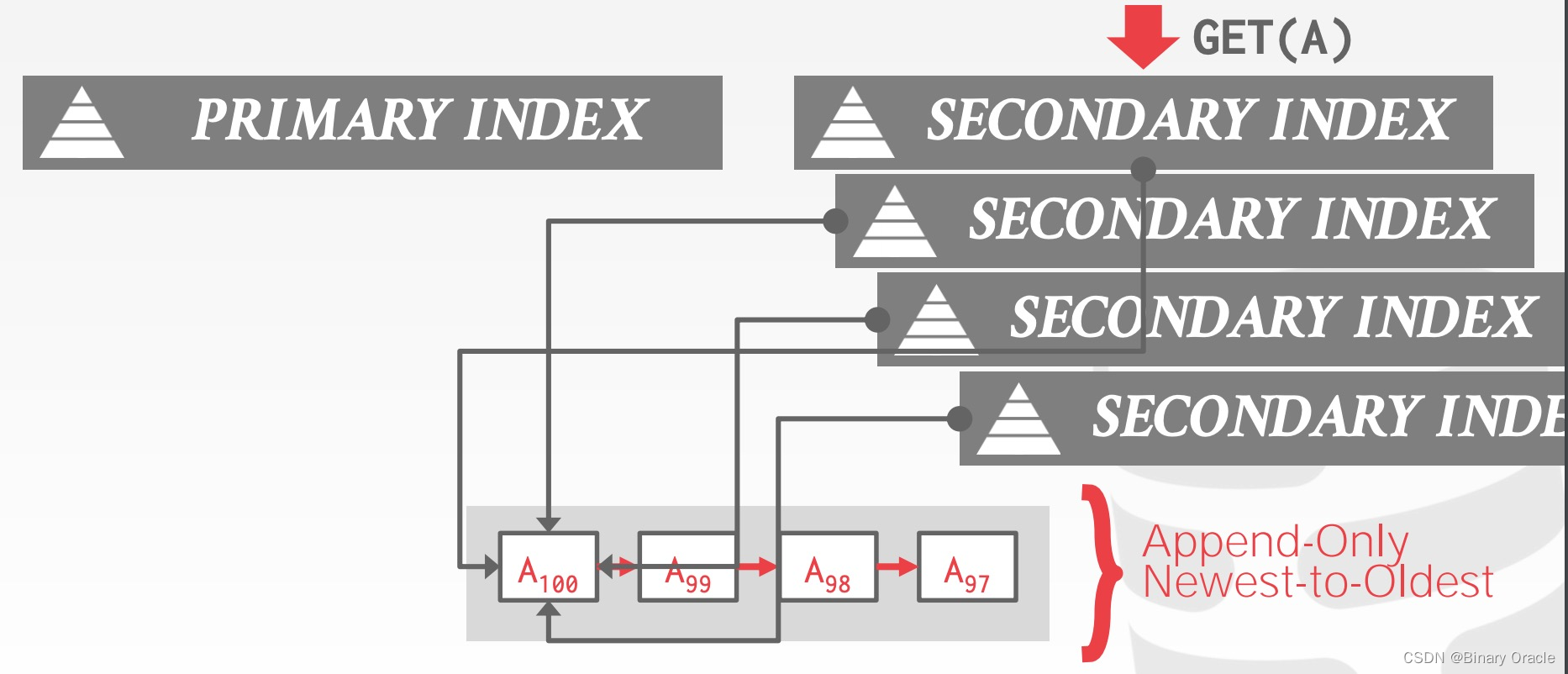
Logical Pointer by Primary Key

Logical Pointer by Tuple Id
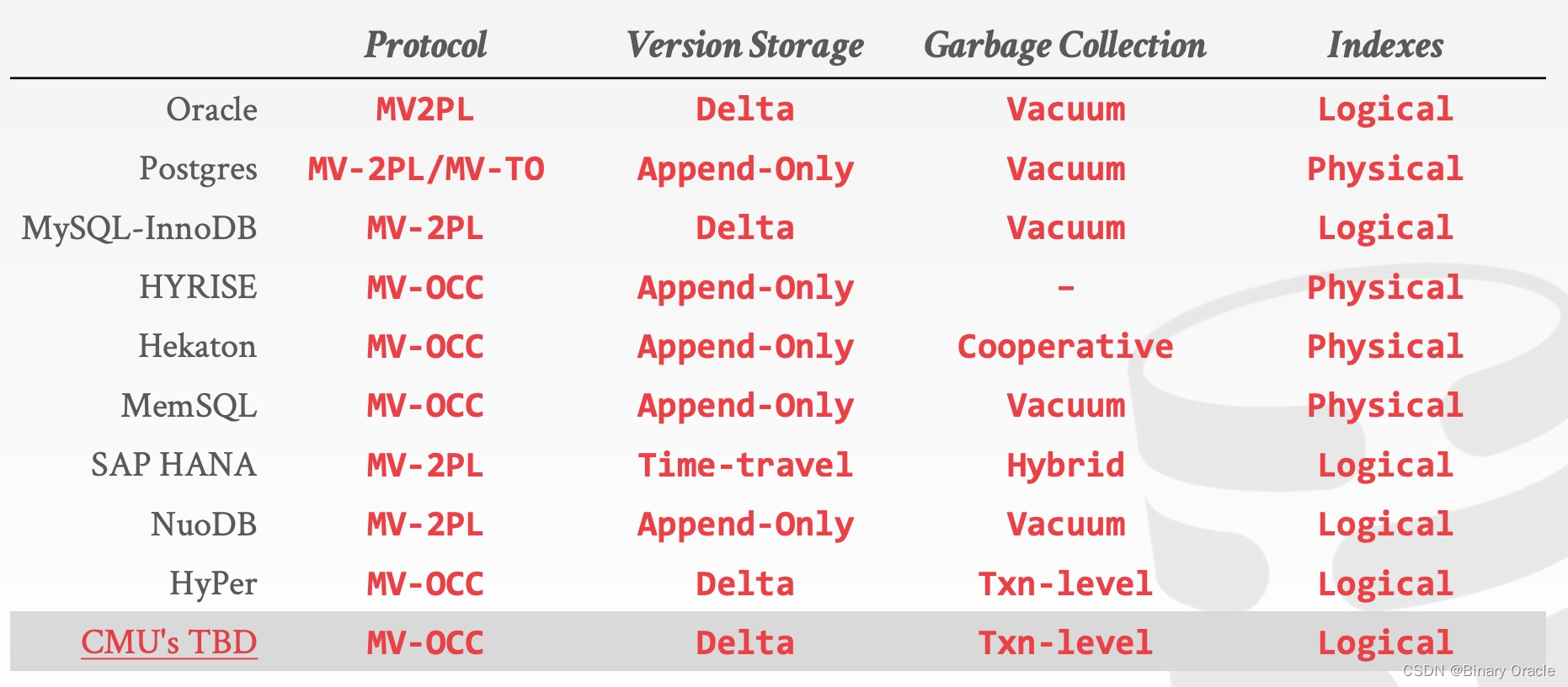
MVCC Implementations
市面上 MVCC 的实现所做的设计决定如下表所示:
Mvcc delete
数据库管理系统(DBMS)只有在所有逻辑删除的元组版本都不可见时,才会从数据库中物理删除一个元组 :
- 如果一个元组被删除,那么在最新版本之后不会有该元组的新版本。
- 没有写-写冲突/第一写入者优先。
我们需要一种方法来表示在某个时间点上元组已经被逻辑删除:
- 方法一:删除标志(Deleted Flag)
- 维护一个标志,用于指示在最新的物理版本之后,逻辑元组已被删除。
- 可以放在元组头部或者单独的一列中。
- 方法二:墓碑元组(Tombstone Tuple)
- 创建一个空的物理版本,用于指示逻辑元组已被删除。
- 使用单独的池来存储墓碑元组,并使用一个特殊的位模式来标记版本链指针,以区分正常的数据版本和墓碑元组,以减少存储开销。
Mvcc indexes
在多版本并发控制(MVCC)的数据库管理系统中,索引通常不会存储关于元组版本的信息,而仅仅关联键值与元组的对应关系。
MVCC是一种数据库并发控制技术,允许多个事务在不互相干扰的情况下并发执行,每个事务看到的数据版本都是一致的。为了实现MVCC,数据库系统会在对数据进行修改时创建新的版本,而不是直接覆盖原始数据。
在MVCC的数据库中,索引的目标是帮助快速定位数据,而不涉及数据版本的管理。索引通常会关联键值与对应的元组物理位置,但不会存储关于该元组的版本信息。
然而,有一些例外情况。例如,一些数据库(如MySQL)支持索引组织表(Index-organized tables),这种表结构允许将数据行存储在索引树的叶子节点中,因此索引本身就包含了数据行的内容。在这种情况下,索引可能会存储有关元组版本的信息。
此外,不同快照(事务开始时的数据库状态)可能导致相同的键指向不同的逻辑元组。这是因为在MVCC中,每个事务在执行时看到的数据版本是一致的,因此不同事务的快照可能包含不同版本的数据,导致相同的键在不同快照中指向不同的逻辑元组。
总之,MVCC的数据库索引主要用于定位数据,不涉及版本信息。然而,在特定情况下,某些数据库可能会在索引中包含版本信息,而且同一个键可能指向不同的逻辑元组,这是MVCC并发控制的特性之一。
重复键问题
在MVCC(多版本并发控制)中,可能会出现重复键问题,特别是在处理主键或唯一索引时。这个问题是由于多个事务同时尝试插入或更新具有相同键值的数据行,导致在某个时间点上出现多个数据行具有相同的键。
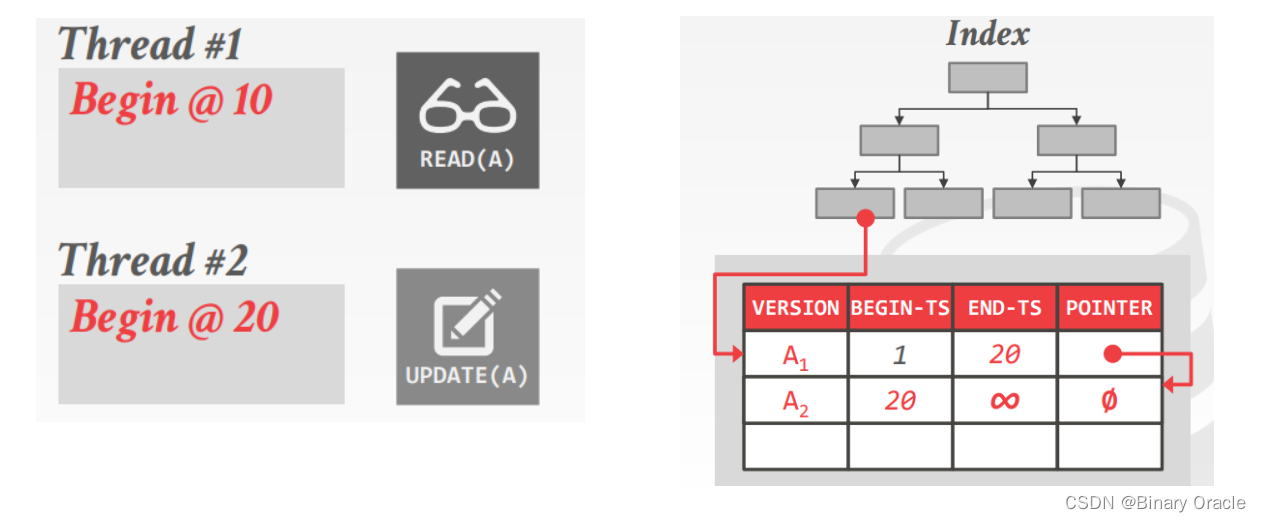
- 线程1尝试读取记录A,此时根据MVCC可见性规则,其能读取到A记录的A1版本
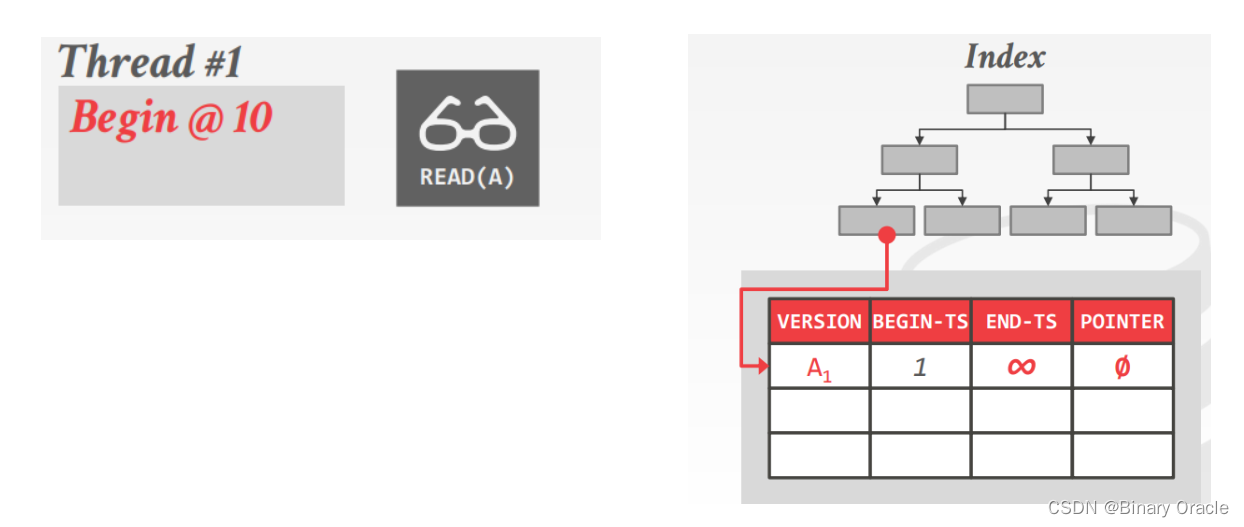
- 线程2同时更新记录A,此时会在A1版本基础上产生一个新的A2版本
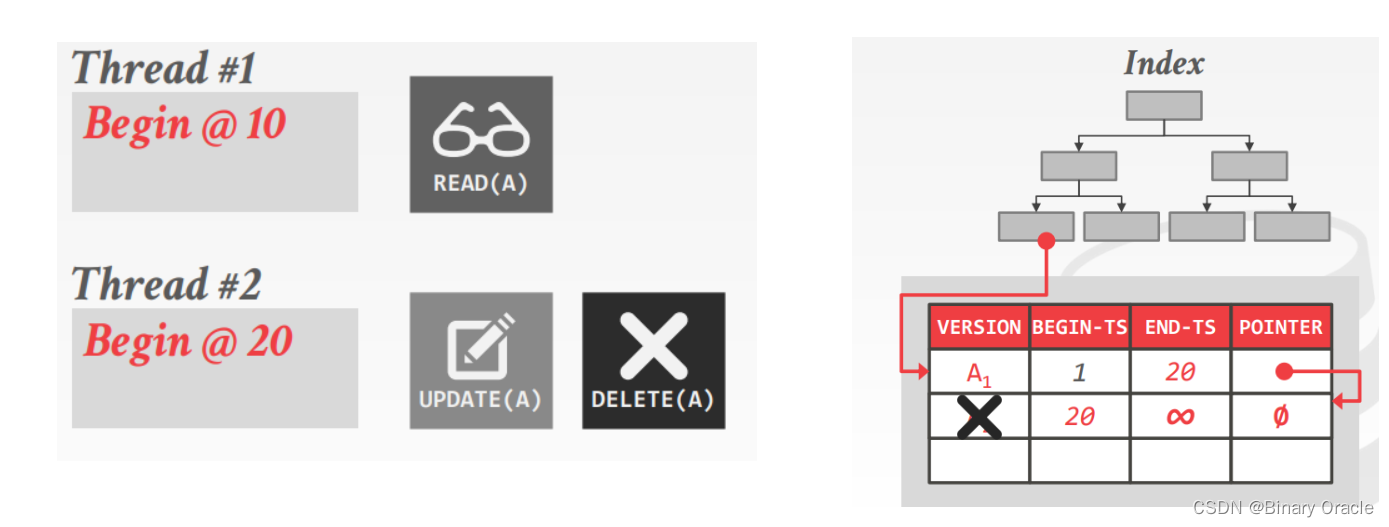
- 线程2接着尝试删除当前A记录,此时会在A记录最新版本A2上添加一个删除标志
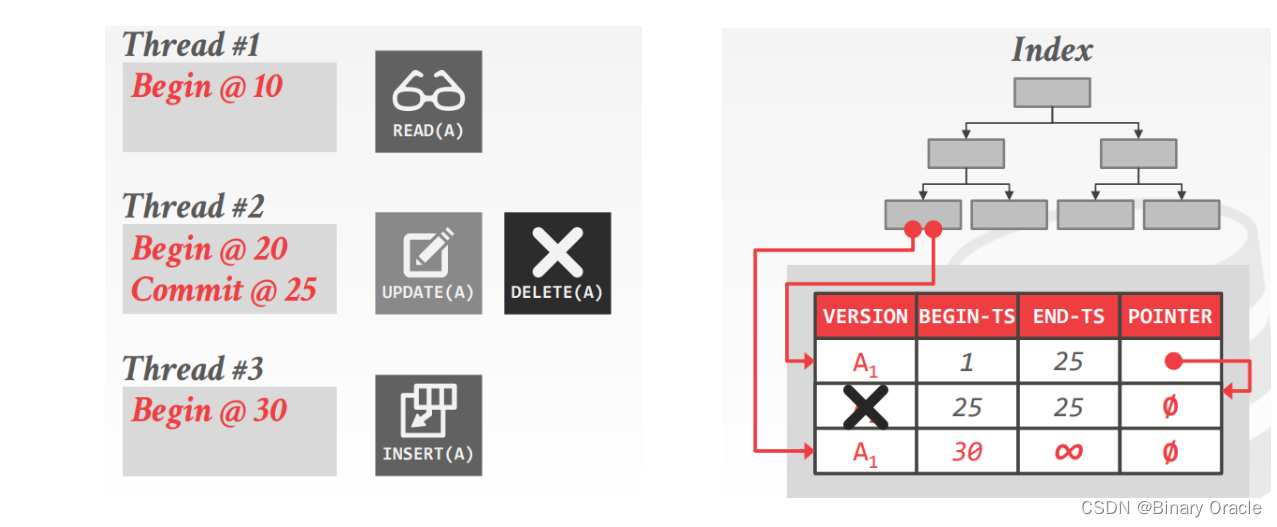
- 线程2将本次事务提交

- 线程3同时尝试插入一条同样名为A的记录到表中,该插入操作与线程2的更新,和线程1的查询操作同时发生
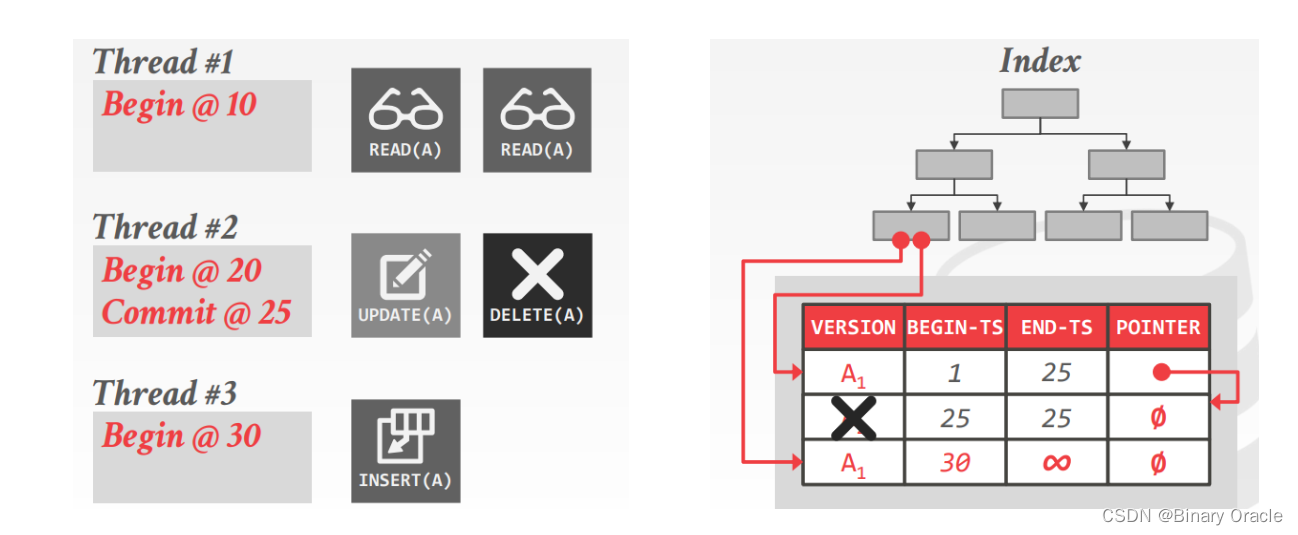
- 此时由于存在多个事务并发执行插入和更新情况,如果没有做好并发控制,可能会导致出现重复键问题
当多个事务并发地执行插入或更新操作时,每个事务看到的数据版本是一致的。如果多个事务都试图插入或更新相同的键值,它们可能在没有相互通知的情况下同时进行操作。在一些数据库系统中,可能会通过乐观并发控制机制来允许多个事务同时执行,而不会立即检查键的唯一性。
然而,当这些事务提交时,数据库需要确保键的唯一性约束得到满足。这可能导致其中一些事务的插入或更新操作失败,并被回滚,因为它们引起了重复键的问题。这样,系统保持了数据库的完整性,确保在同一时间点,每个键只对应一个唯一的数据行。
为了解决MVCC中的重复键问题,数据库系统通常会使用锁或其他并发控制机制来保护对具有相同键的数据行的并发访问。这样,当一个事务在处理某个键的插入或更新时,其他事务会被阻塞或进入等待状态,直到第一个事务完成并释放相关资源。这种并发控制机制确保在任何时刻只有一个事务能够插入或更新具有相同键的数据行,从而解决了重复键问题。
总之,MVCC中的重复键问题是由多个事务同时尝试插入或更新具有相同键值的数据行而引起的。为了解决这个问题,数据库系统会使用并发控制机制来保护对具有相同键的数据行的并发访问,以确保数据库的唯一性约束得到满足。
小结
在MVCC的数据库中,每个索引的底层数据结构必须支持存储非唯一的键(即允许多个不同的数据行关联到相同的键)。对于主键(pkey)或唯一索引(unique indexes),需要额外的执行逻辑来进行条件性的插入。
为了在主键或唯一索引上执行条件性插入,通常会采取以下步骤:
-
原子性检查键是否存在:在执行插入之前,需要检查索引中是否已经存在具有相同键的数据行。这是为了确保不会插入重复的键值,以保持主键或唯一索引的唯一性约束。
-
插入数据行:如果键不存在,说明是一个新的数据行,可以进行插入操作。
-
考虑并发情况:在多并发事务的环境下,多个事务可能同时尝试插入具有相同键的数据行。为了确保数据的一致性,数据库系统需要处理并发情况,通常会使用锁或其他并发控制技术来保护数据的完整性。
对于工作线程(或查询)来说,当它们从索引中获取数据时,可能会得到多个具有相同键的数据行。这是因为在MVCC中,每个事务可能看到不同的数据版本,因此在某个特定的时间点,可能存在多个数据行与相同的键相关联。
工作线程在处理这种情况时,需要根据指向下一个版本的指针来找到正确的物理版本。因为在MVCC中,每个数据行可能有多个版本,这些版本通过指针链表进行连接。工作线程需要遵循指针链表,沿着版本链找到符合当前事务快照的正确版本。
总之,MVCC中的索引数据结构支持存储非唯一键,而在执行插入时需要特殊的条件性逻辑来确保主键或唯一索引的完整性。对于工作线程,在获取数据后可能需要遵循版本链指针来找到适合当前快照的正确版本。这些措施都是为了实现数据库的并发控制和数据一致性。
Conclusion
MVCC 被许多 DBMS 采用,即使那些不支持多语句事务 (multi-statement txns) 的 DBMS 也会使用这种方案,如一些 NoSQL 项目。
本节对应教材PDF