1.Python 爬虫
1.1什么是网络爬虫
网络爬虫,又称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
1.2 网络爬虫的特点
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成,传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
1.3 网络爬虫的种类
1.3.1 通用网络爬虫
通用网络爬虫又称全网爬虫,爬行对象从一些种子URL扩充到整个Web,主要为门户站点搜索引擎和大型Web服务提供商采集数据,这类网络爬虫的爬行范围和数量巨大,对于爬行速度和存储空间要求较高,对于爬行页面的顺序要求相对较低,同时由于待刷新的页面太多,通常采用并行工作方式,但需要较长时间才能刷新一次页面。
1.3.2 聚焦网络爬虫
聚焦网络爬虫,又称主题网络爬虫,是指选择性地爬行那些与预先定义好的主题相关页面的网络爬虫,和通用网络爬虫相比,聚焦爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,还可以很好地满足一些特定人群对特定领域信息的需求。
1.4 爬虫的作用
统计数据
冷数据启动时丰富数据的主要工具,新业务开始时,由于刚起步,所以没有多少数据,此时就需要爬取其他平台的数据来填充我们的业务数据。
爬虫抢票
相信每逢春运或是节假日,大家都用过一些抢票的软件,就为了获得一张机票或者是一张火车票,而这种出行类软件正是运用网络爬虫技术来达到抢票的目的,像抢票软件这样的网络爬虫,会不停地爬取交通出行的售票网站,一旦有票就会点击拍下来,放到自己的网站售卖。
参考文章:网络爬虫是什么意思 (baidu.com)
2. post 请求 和 get 请求
2.1 post请求
1. 首先 post请求本质上就是TCP链接;
2. post请求一般作为发送数据到后台,传递数据,创建数据;
3. post请求则是将传递的参数放在request body中,不会在地址栏显示,安全性比get请求高,参数没有长度限制;
4.刷新浏览器或者回退的时候 , post请求则会重新请求一遍;
5. post请求不会被缓存,也不好保留在浏览器的历史记录中;
6. post常见的则是form表单请求;
7. 对参数的数据类型,post没有限制;
2.2 get 请求
1. 首先 get请求本质上就是TCP链接;
2. get请求也可以传参到后台,但是传递的参数则显示在地址栏,安全性低,且参数的长度也有限制(2048字符);
3. get请求刷新浏览器或者回退没有影响;
4. get请求可以被缓存,也会保留在浏览器的历史记录中;
5. get请求通常是通过url地址请求;
6. 对参数的数据类型,get只接受ASCII字符
7. get比post更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
参考文章:post和get请求的区别是什么-常见问题-PHP中文网
参考文章:get请求和post请求 理解 - 小log - 博客园 (cnblogs.com)
3. url 的组成和意义
3.1 url 的概念
Internet上的每一个网页都具有一个唯一的名称标识,通常称之为URL(Uniform Resource Locator, 统一资源定位器)。它是www的统一资源定位标志,简单地说URL就是web地址,俗称“网址”。
3.2 url 的组成
url 由 协议、主机名、域名、端口、路径、以及文件名这六个部分构成,其中端口可以省略。具体语法规则如下:
scheme://host.domain:port/path/filename
协议 :// 主机名 . 域名 / 端口(可以省略)/ 路径 / 文件 (注意符号)
3.3 协议有哪些
| 协议 | 使用场景 |
| http | 超文本传输协议。http 协议可以将编码为超文本的数据从一台计算机传送到另一台计算机,不进行加密。 |
| https | 安全超文本传输协议。以安全为目标的 http 通道,安全网页,加密所有信息交换。 |
| ftp | 文件传输协议。 格式 FTP:// |
| file | 本机上的文件 file:///,注意后边应是三个斜杠。 |
| gopher | 通过 Gopher 协议访问该资源。 |
| mailto |
3.4 主机名
主机名的含义是机器本身的名字,域名是方面记录IP地址才做的一种IP映射,主机名用于局域网中;域名用于公网中。
http://blog.sina.com.cn/中,blog是提供博客服务的那台机器的名字,http://sina.com.cn是域名,http://blog.sina.com.cn是主机名。,计算机名+域名才是主机名
3.5 域名
3.5.1 域名可以认为是主机在公网环境中的标识,在在公网下,对应一个唯一的IP,例如我们访问百度的主页:http://www.baidu.com
3.5.2 域名还分级,从后往前级别依次降低,http://sina.com.cn中,cn是顶级域名,表示中国,com是二级域名,表示商业机构(commercial),sina是三级域名,一般用自己的名字。
3.6 端口
一串用来区分不同程序的数字,通过它我们将信息传给指定程序。
或者说是一个个程序占据了一个线程,一个线程占据了一个端口。
3.7 路径
由零或多个“/”符号隔开的字符串,一般用来表示主机上的一个目录或文件地址。
参考文章:(2条消息) URL的概念与组成_url组成_小宝的宝呢的博客-CSDN博客
参考文章:(4条消息) URL的构成_url组成_sunmengting0123的博客-CSDN博客
4. requests 和 chardet 的功能 (模块需要下载)
4.1 requests 模块介绍 (这里只是简单介绍,详细的参考文章中看)
1.发送HTTP请求
2.处理响应
3.会话管理
4.文件上传和下载
参考文章:python—requests模块详解_python requests模块_W0ngk的博客-CSDN博客
参考文章:requests库的100种妙用! (baidu.com)
4.2 chardet 模块介绍 (这里只是简单介绍,详细的参考文章中看)
chardet 支持检测中文、日文、韩文等多种语言 和 字符串编码 的识别
参考文章:[转]python 模块 chardet下载及介绍 - 道高一尺 - 博客园 (cnblogs.com)
参考文章:【python】chardet函数用法_微雨停了的博客-CSDN博客
5. requests 和 charde 模块 函数的使用
5.1 requests 模块的 get(url, params, headers) 函数介绍
参数url :是一个网路地址,目的连接对应服务器。
参数params : 向网站传递信息。 (例如是:为了查询信息而传递的参数)(我的理解)
参数 headers : headers 请求头信息,是为了我们的代码访问更像 正常的网站访问。
5.2 url 参数
5.2.1 怎么寻找 url
答: 打开一个页面直接 复制它的地址
为什么只有这一节, 因为后面是传递的参数(params)。

5.3 params 参数
5.3.1 怎么寻找 params参数
答: 打开一个页面观看 地址
5.3.2 想了解更多的 params参数 符号的意义
参考文章:百度/谷歌搜索结果中URL路径中的各参数详解_url后面参数wd是什么_爱上小飞鱼的博客-CSDN博客

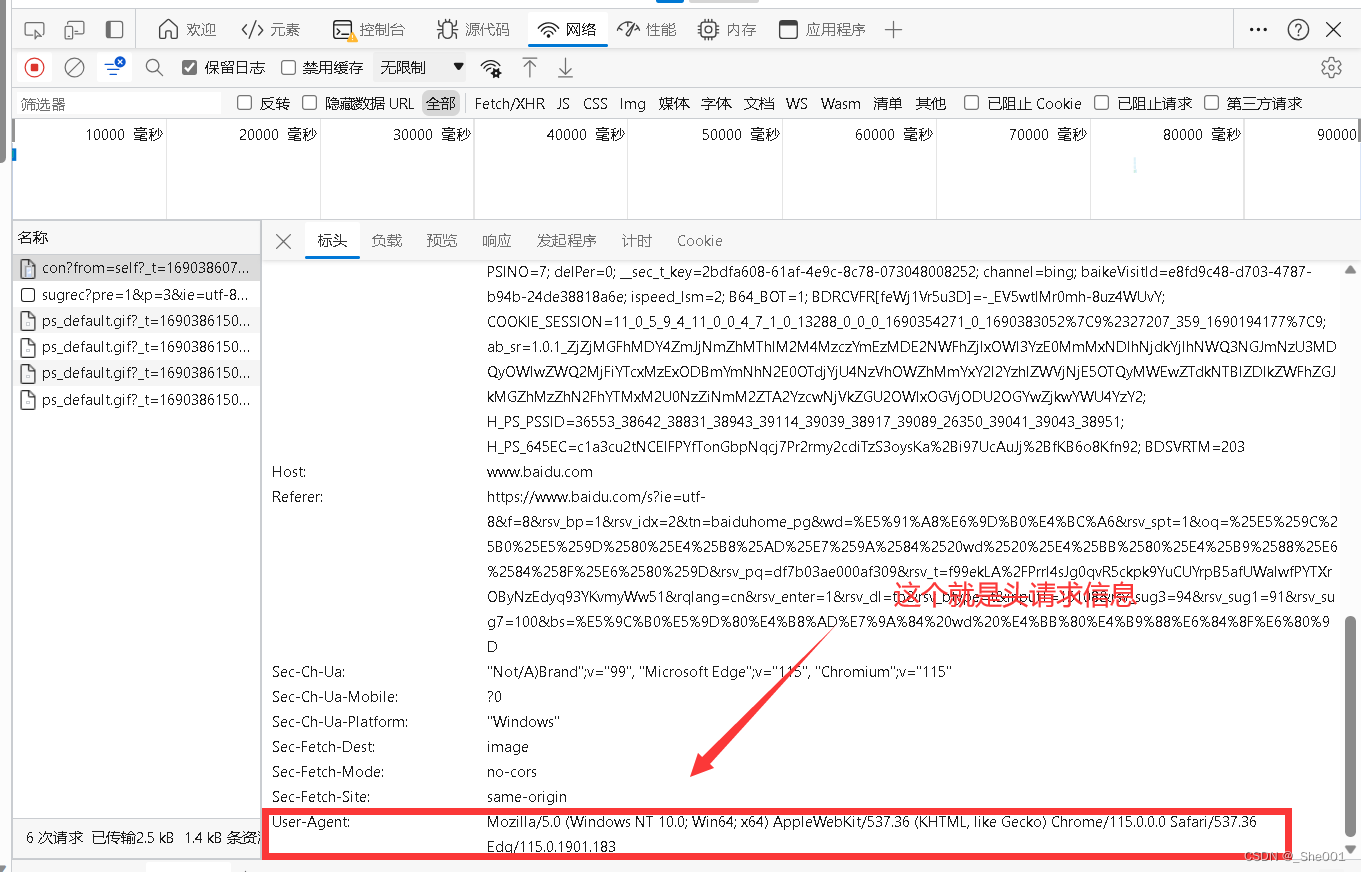
5.4 headers 参数
5.4.1 怎么找到这个参数
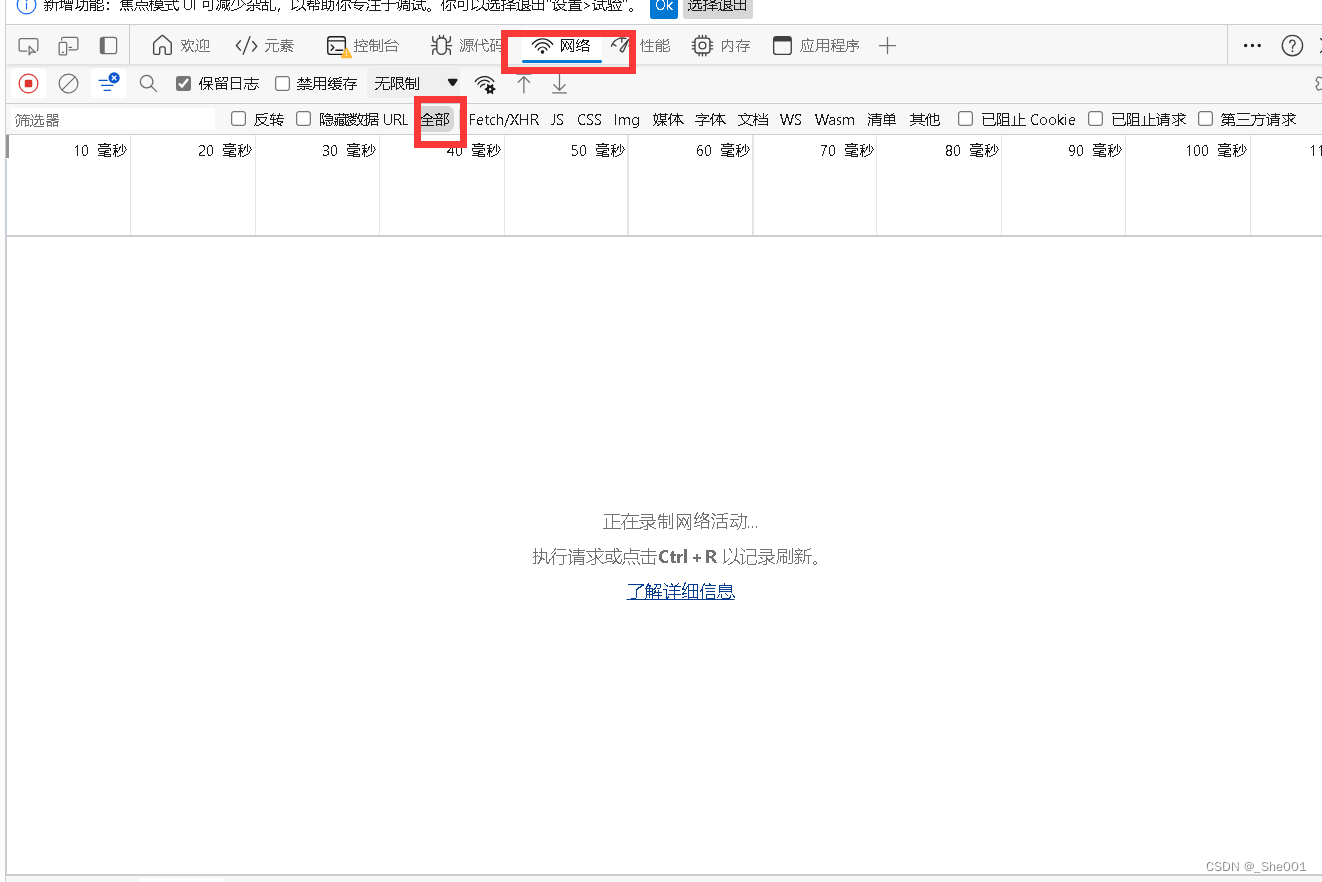
第一步 : 打开页面 (右键--》 检查 ) 或者 (按下F12)
结果图片:
第二步 : 点击网络 再点击all 或者全部 (没有反应就点击旁边不是 控制界面的地方就行了)
结果图片:
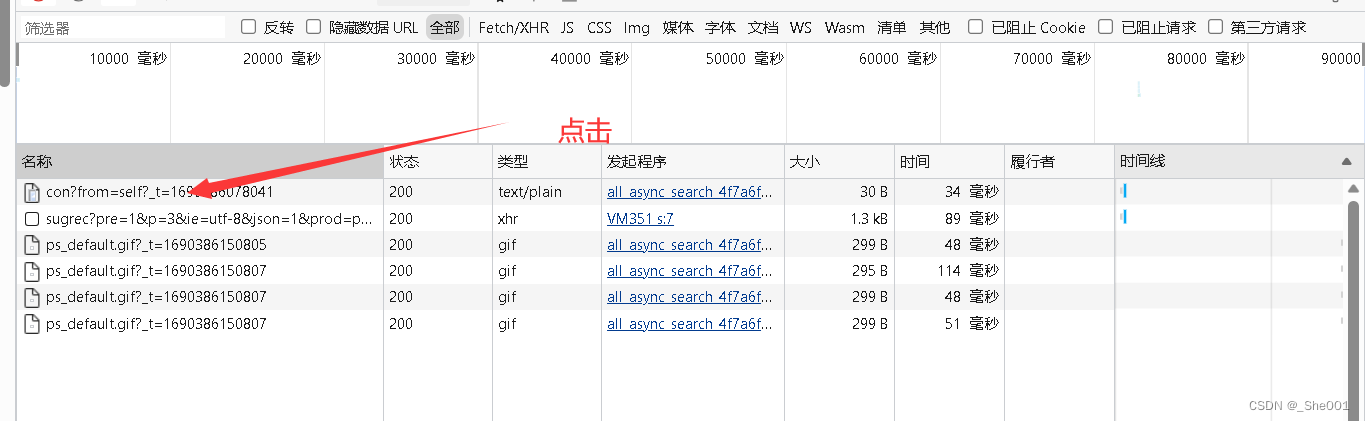
第三步: 点击数据
结果图片:
第四步, 把数据转换为 字典数据模式
html_headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.183" } #获取这个网站的 请求头文件
5.5 样例代码
import requests # http 请求函数的库
import chardet #chardet 支持检测中文、日文、韩文等多种语言 和 字符串编码 函数库
url = 'https://www.baidu.com/s?'
html = requests.get(url)
#print(html.text.encode('utf-8')) #打印源代码
if html.status_code == 200 :
print(html.url,end='') #输出网址
print("第一个 数据访问成功")
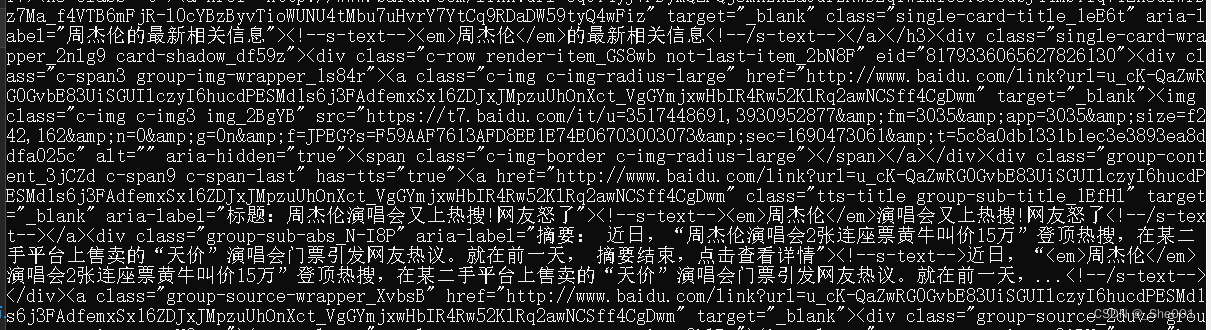
html_params = {"wd":"周杰伦"} # get函数 params 参数 这个参数是用来 向这个网站来传递 数据
html_headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.183"
} #获取这个网站的 请求头文件
html1 = requests.get(url,params = html_params,headers = html_headers) #params 使用传递参数(比如传输 ,账号密码), headers 传递头信息,是为了我们的代码访问更像 正常的网站访问
if html1.status_code == 200:
print(html.url,end='')
print("第二个 数据访问成功")
html1.encoding = 'utf-8'
print(html1.text)
else:
past
else:
print("数据访问失败")