前言
Java 语言已经走过了 20 多个年头,在此期间虽然新语言层出不穷,但是都没有撼动 Java 的位置。可能是历史选择了 Java,也可能是 Java 改变了历史,总之,Java 无疑是一门成功的编程语言。这门语言之所以能如此成功,高性能语言虚拟机 HotSpot 功不可没。
客观地说,HotSpot VM 是目前顶级的语言虚拟机之一,它的模板解释器是语言解释器的最终状态,除非有重大技术突破和方法论的改变,否则很难被超越。它的垃圾回收器也日臻完善,新的无停顿 GC 的出现标志着 JVM 正在迈向 GC 顶级俱乐部。它的即时编译器是权衡编译开销与应用吞吐量后得到的一个卓越且精湛的艺术品。

本文既考虑到内容的广度也关注了技术的深度,详细描述了虚拟机的底层实现,并与上层 Java 语言或者库结合,以实用为目标展开介绍,同时还讨论了它们的深刻意义。
从内容广度的角度看,本文除了讨论耳熟能详的 Java 虚拟机技术外,还详细讨论了业界最新的通用虚拟机平台 Graal VM、CDS/AppCDS/DynamicCDS、Instrumentation 库、编译重放、非标准字节码、栈上替换,RTM 锁、JIT 编译器 IR、JIT 编译器可视化工具、编译逃离、EpsilonGC/ShenandoahGC/ZGC、G1 字符串去重等技术。
从内容深度的角度看,本文详细讨论了:
-
G1 GC 的回收策略和底层代码实现;
-
C1 编译器的 HIR 和 LIR,以及针对不同 IR 上应用的优化;
-
C2 编译器的 Ideal Graph 以及平台无关的优化技术;
-
CPU 重排序与 ObjectMonitor、Mutex 的底层实现;
-
模板解释器的代码片段生成逻辑和字节码模板生成逻辑;
-
【深入解析 Java 虚拟机 HotSpot 手册原文档见文末】
目录

主要内容
本文共 11 章,全文从逻辑上可分为运行时、编译器、垃圾回收器三个部分。
第一部分(第 1~6 章),介绍 Java 虚拟机运行时的相关知识;
第 1 章 Java 大观园;作为本书的开篇,本章将围绕 Java 的生态系统,简单介绍 JDK、JVM、JEP,引导读者走进虚拟机的世界。
1.1 节介绍了各具特色的 JDK 分支和 OpenJDK 的子项目。1.2 节介绍了 Java 改进提案,它们代表类 Java 社区最新的工作动向。1.3 节简单描述了历史长河中存在或者曾经存在的 Java 虚拟机。1.4 节讨论了 HotSpotVM 的组件、源码结构、构建、调试以及修改代码后如何回归测试。最后 1.5 节展望未来,讨论了 Java 的前沿技术 Graal VM。
第 2 章类可用机制;一个类需要经过漫长的旅程才能被虚拟机其他组件,如解释器、编译器、GC 等在运行时使用,下面将详细介绍类的一个完整生命周期,即加载、链接、初始化三部曲。
本章从 2.1 节开始,介绍了位于磁盘的二进制表示的字节码被类文件解析器加载并解析,得到虚拟机内部用于表示类的 InstanceKlass 数据结构。为了保证字节码是安全可靠的,在 2.2 节链接阶段,首先验证了字节码的结构正确性;出于性能考虑,链接阶段还可能调用重写器将一些字节码替换为高性能的版本,加快后面的解释执行;链接阶段的核心工作是设置编译器/解释器入口以便后续代码能够正常执行,同时为了保障后续解释/编译模式的切换,还会设置适配器来消除两种模式之间的沟壑。接着,根据《Java 虚拟机规范》中赋予类初始化的语义,在 2.3 节介绍了初始化阶段同时执行用户的静态代码块和隐式静态字段初始化。最后 2.4 节特别讨论了类的重定义。

第 3 章对象和类;本章讨论 Java 对象和类在 HotSpot VM 内部的具体实现,探索虚拟机在底层是如何对这些 Java 语言的概念建模的。
本章主要围绕对象和类的相关内容展开。3.1 节介绍了 HotSpot VM 中对象和类的设计原则。3.2 节介绍了对象和类模型,它们在 JVM 层表示 Java 层的对象。3.3 节介绍了类模型,它们在 JVM 层表示 Java 层的 Class<?>。对象和类共同构成对象类二分模型,是 HotSpot VM 的核心数据结构。
第 4 章运行时;运行时,顾名思义是指虚拟机运行的时候,它表征程序执行时的状态,本章将讨论虚拟机运行时涉及的方方面面。
4.1 节讨论了 JVM 中五花八门的线程以及它们的作用。4.2 节从源码角度分析线程 API 的实现,同时扩展分析线程 API 实现时涉及的其他重要模块如 JavaCalls、os,并简单提及 ParkEvent、Parker、OrderAccess 组件。4.3 节讨论了线程栈帧的实现。4.4 节讨论虚拟机层的代码如何与 Java 层的代码交互,以此引出 JNI 和 JavaCalls 模块。4.5 节讨论 JDK 中的 Unsafe 类,并给出它在虚拟机的具体实现。
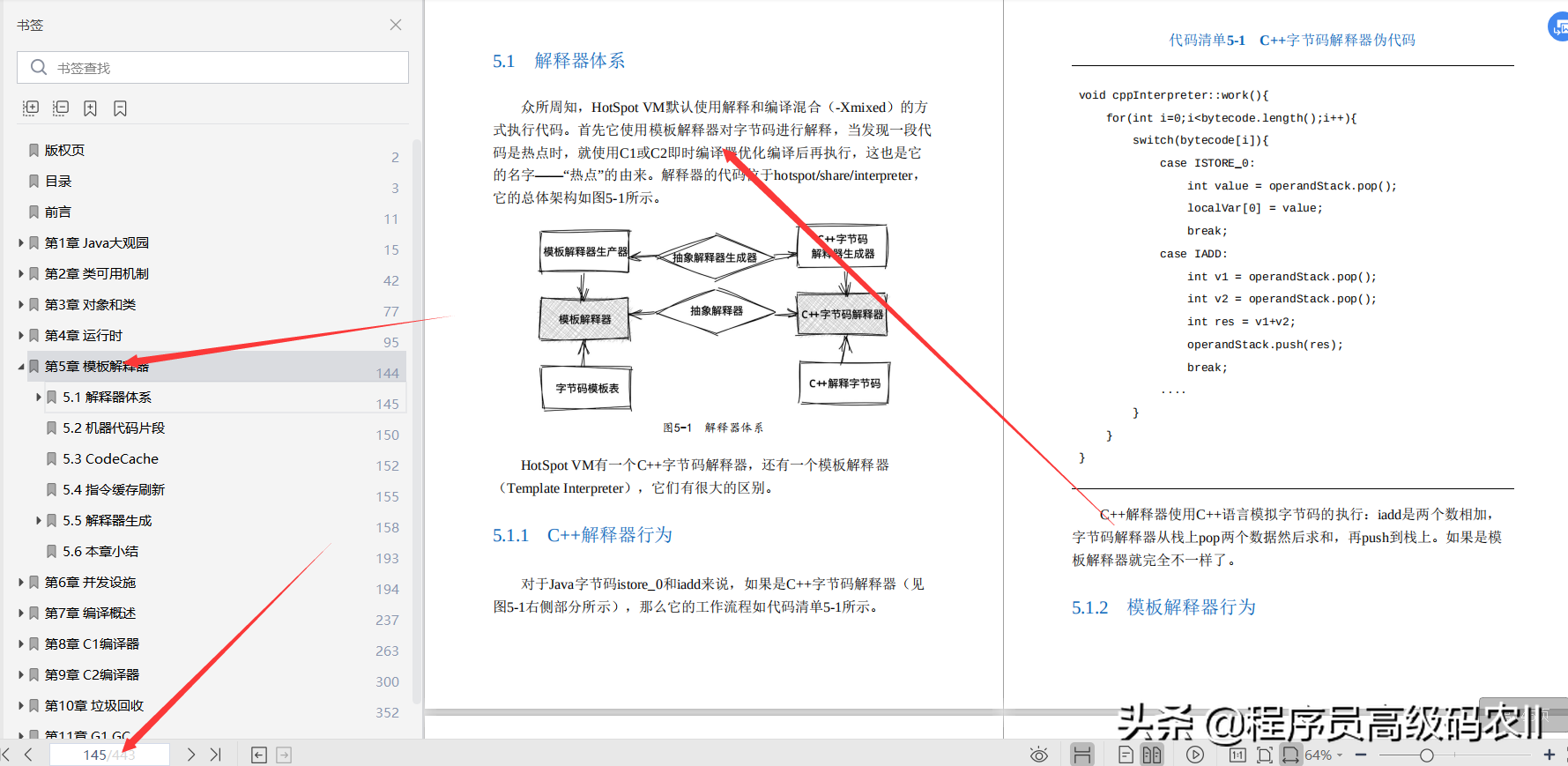
第 5 章模板解释器;最简单的 Java 虚拟机可以只包括类加载器和解释器:类加载器加载字节码 iconst_1、iconst_1、iadd 并传给虚拟机,解释器按照字节码计算并得到结果。在没有 JIT 编译器的情况下,解释器从某种程度上来说就是虚拟机本体,有关虚拟机的绝大部分问题都能在解释器中找到答案。本章将详细讨论解释器的内部构造和解释执行过程。
本章讨论了 HotSpot VM 中最重要组件之一——解释器的构成和工作机制。5.1 节讨论解释器的源码结构和构成解释器的基础设施;5.2 节讨论了构成解释器的元素;5.3 节和 5.4 节描述了解释器与其他虚拟机组件的合作方式;5.5 节详细讨论了解释器实现,包括解释器如何执行普通 Java 方法和 native 方法、标准字节码是如何实现的,以及非标准字节码是如何实现的。
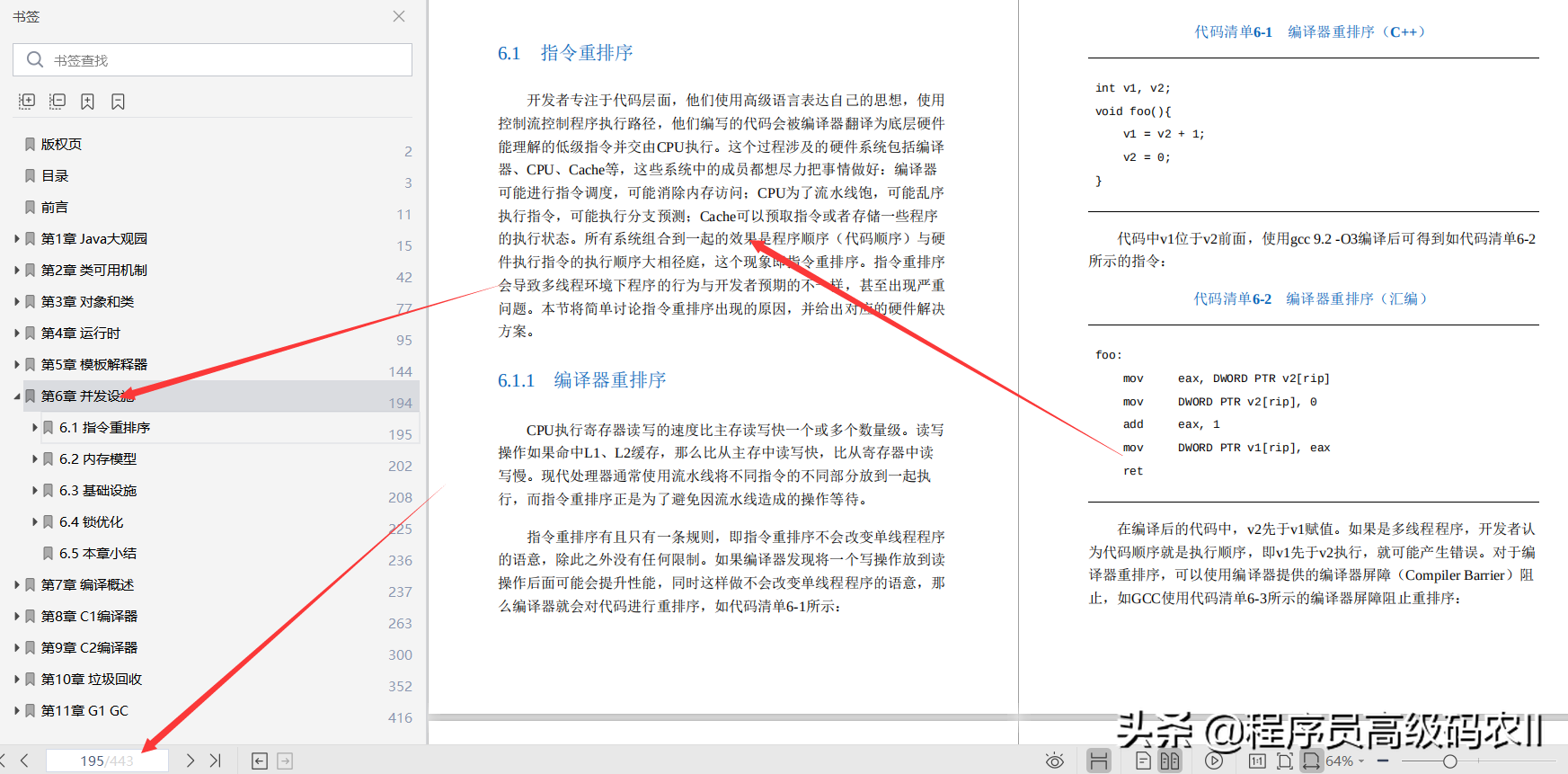
第 6 章并发设施;并发是 Java 的一大特色,通过并发,可以在 Java 层实现多个线程协同工作或者互斥执行。上层应用的易用性、安全性、高效性都是由 HotSpot VM 中的并发设施来保证的。并发设施是 HotSpot VM 中相当复杂的组件,本章将简单讨论虚拟机在并发方面付出的努力。
6.1 节介绍了重排序和内存屏障,它们是 Java 内存模型的基础。6.2 节简单介绍了 Java 内存模型,它在程序的一些特定的地方设置内存屏障,禁止指令重排序的发生,使程序顺序和执行顺序保持一致。6.3 节介绍了虚拟机内部并发基础设施,包括原子操作、ParkEvent、Parker、Monitor,它们广泛用于虚拟机内部的各种需要同步的地方。6.4 节介绍了更高层次的基于并发继承设施的锁优化策略。
第二部分(第 7~9 章),介绍编译基础知识和虚拟机的两个即时编译器;
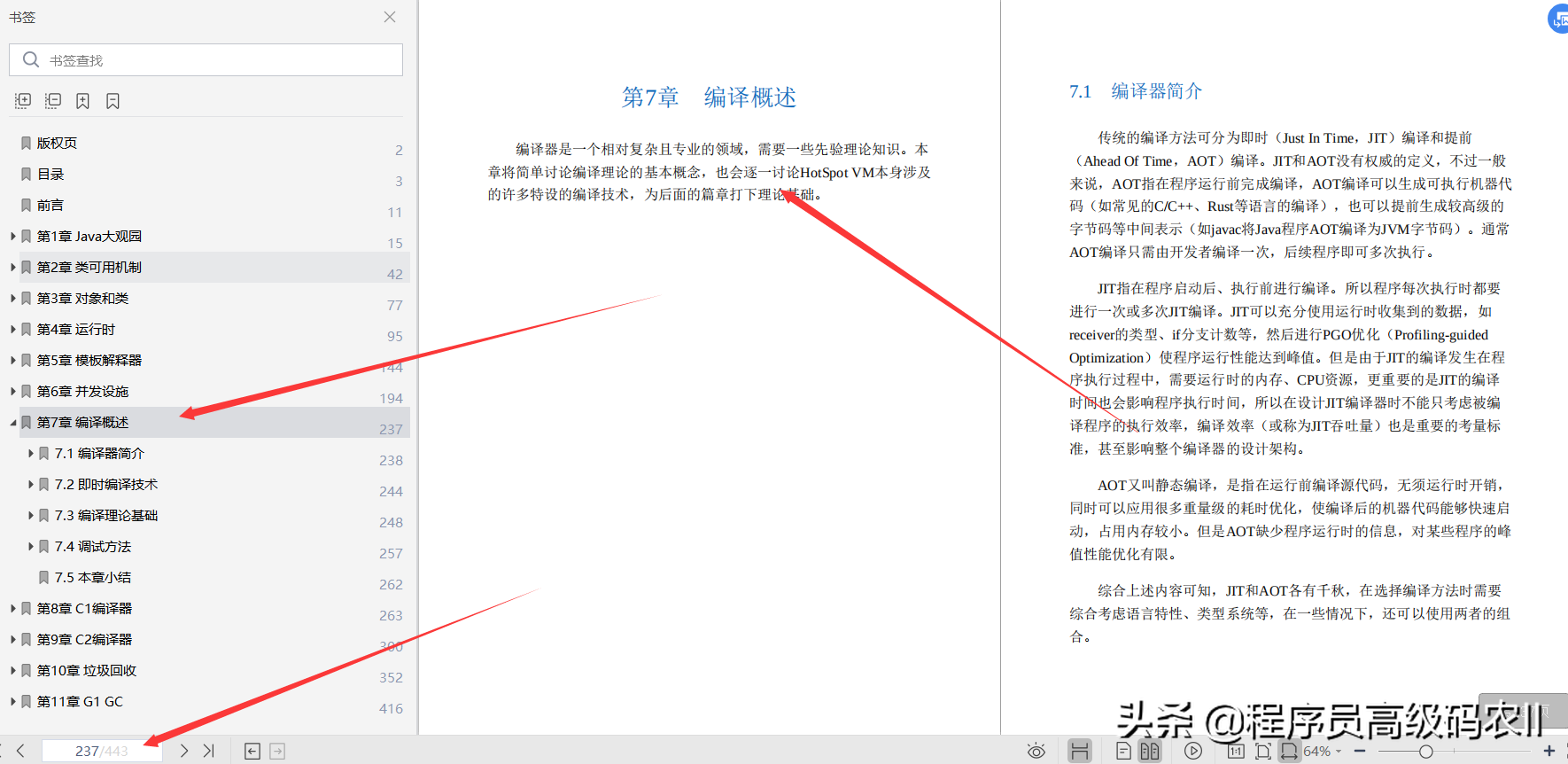
第 7 章编译概述;编译器是一个相对复杂且专业的领域,需要一些先验理论知识。本章将简单讨论编译理论的基本概念,也会逐一讨论 HotSpot VM 本身涉及的许多特设的编译技术,为后面的篇章打下理论基础。
本章简单介绍了虚拟机涉及的编译技术。7.1 节介绍了即时编译器依赖的运行时代码生成技术,然后分门别类地介绍了 HotSpot VM 的各类编译器。7.2 节介绍 HotSpot VM 特设的编译技术,它们和虚拟机运行时紧密相连。为了理解后面两章,7.3 节介绍了一些编译术语的基本概念,读者如果在后面两章遇到疑问,可以回顾本节的内容。最后 7.4 节介绍了编译器的调试方法和调试工具,便于读者深入理解即时编译器的行为。
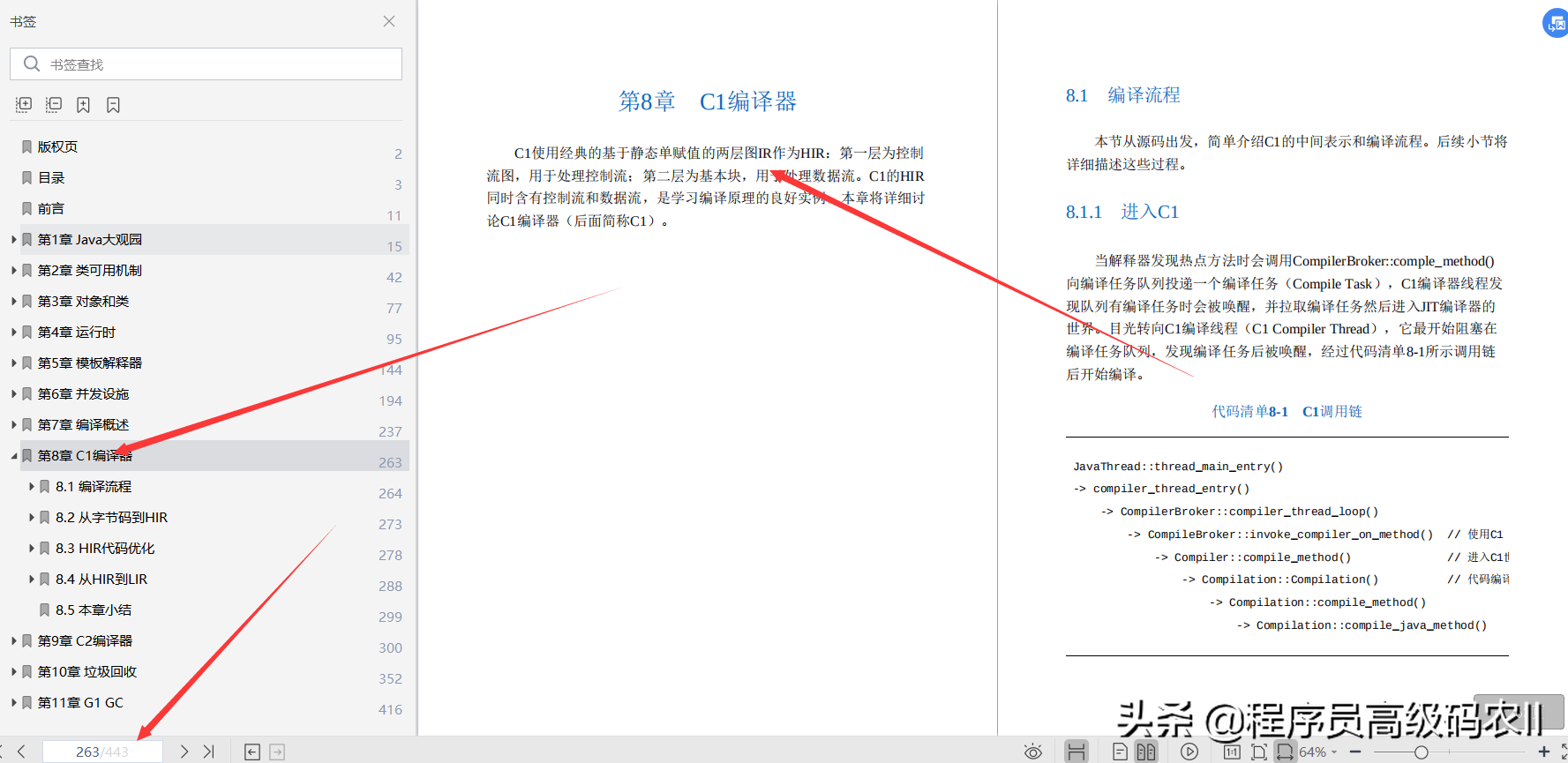
第 8 章 C1 编译器;C1 使用经典的基于静态单赋值的两层图 IR 作为 HIR:第一层为控制流图,用于处理控制流;第二层为基本块,用于处理数据流。C1 的 HIR 同时含有控制流和数据流,是学习编译原理的良好实例,本章将详细讨论 C1 编译器(后面简称 C1)。
8.1 节描述了解释器到 C1 编译器的调用栈以及 C1 编译的主要流程,即字节码到 HIR,再到 LIR,最后生成机器代码的过程。其中,8.2 节描述了字节码到 HIR 的实现。8.3 节描述了 C1 中比较复杂的代码优化过程,基本涵盖了 HIR 的所有优化操作。8.4 节描述了从 HIR 到 LIR 的生成过程,由于 LIR 到机器代码大部分是线性映射过程,所以不再赘述。
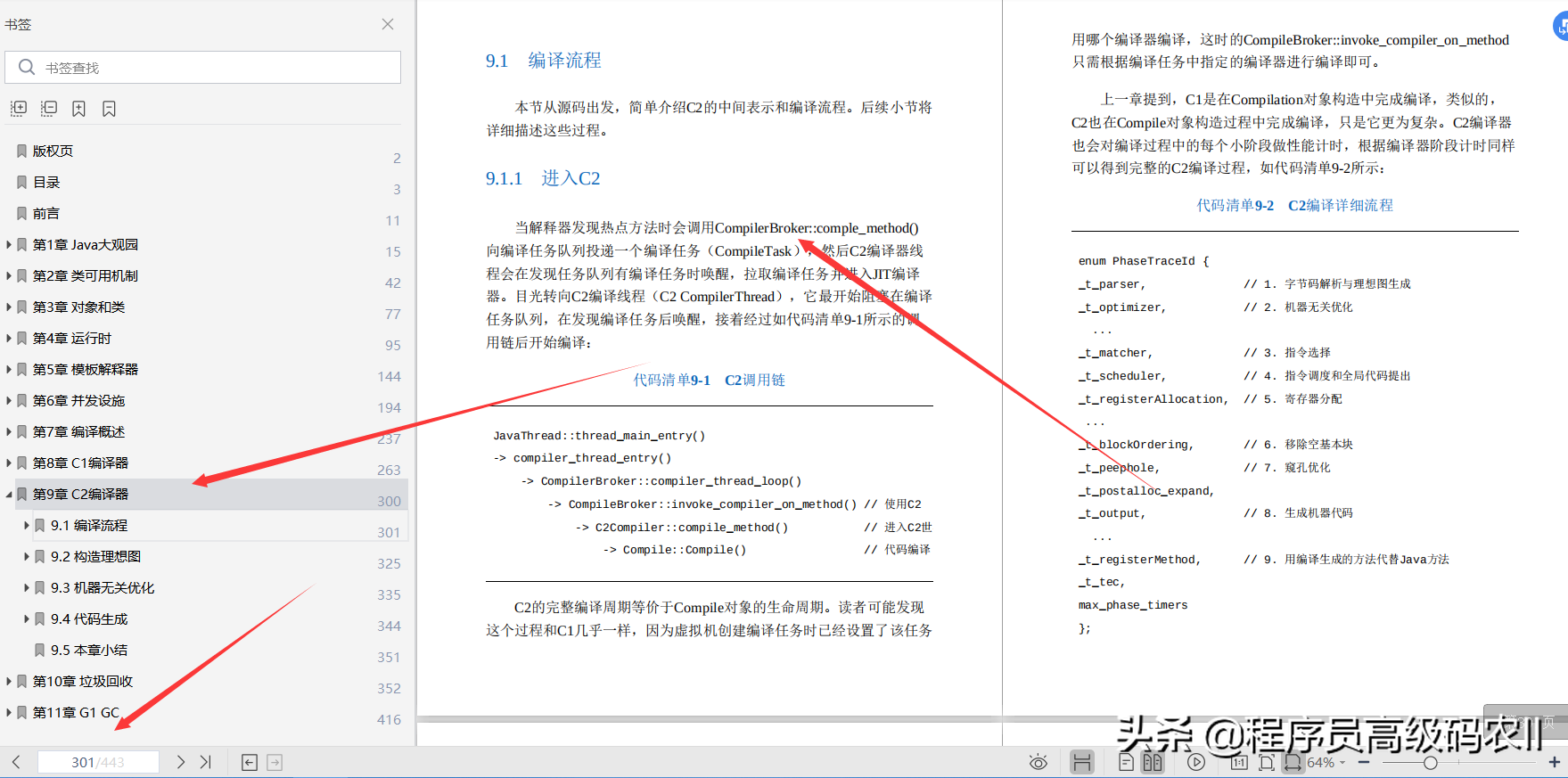
第 9 章 C2 编译器;C2 编译器即 Op to Compiler,又叫 Server Compiler,它的定位与 C1 相反:C1 面向客户端程序,需要快速响应用户请求;C2 面向长期运行的服务端程序,它允许在编译上花更多时间,以此换取程序峰值执行性能。本章将详细讨论大名鼎鼎的 C2 编译器(后面简称 C2)。
9.1 节简单概括了 C2 的编译流程,并简要介绍了 C2 的核心数据结构理想图。9.2 节描述了编译流程的开始,即理想图的构造过程。9.3 节描述了编译流程的中间优化步骤。最后 9.4 节简单介绍了编译流程的后面部分,也就是核心的代码生成过程。
第三部分(第 10~11 章),介绍各种垃圾回收器并深入分析 G1GC。
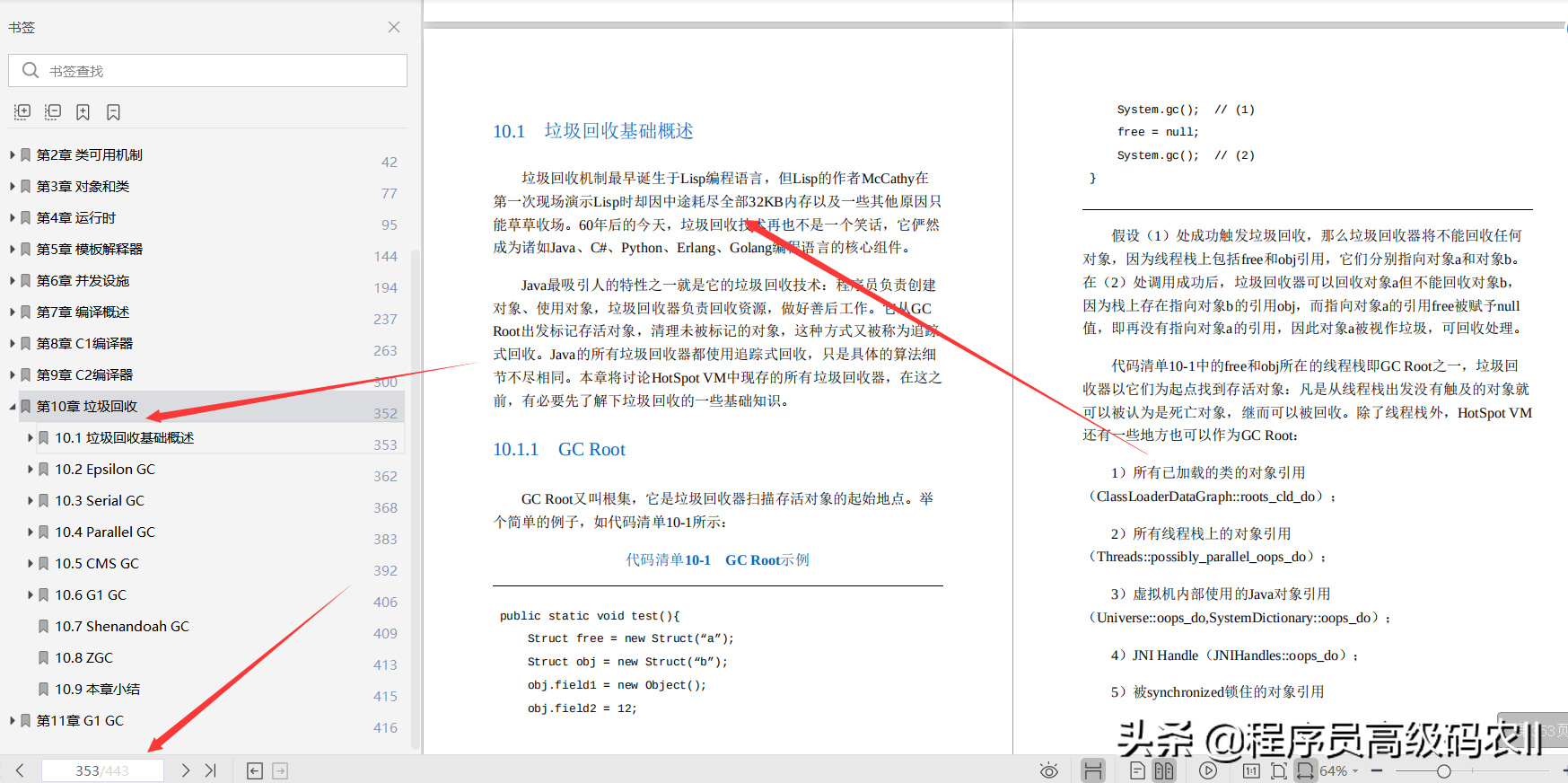
第 10 章垃圾回收;垃圾回收是 JDK 开发者社区最活跃的主题,在-XX:+RunReallyFast 虚拟机参数没有到来之前,了解垃圾回收运行机制和工作原理对于 Java 开发者是很有必要的。本章将从最简单的垃圾回收器开始,逐个介绍垃圾回收器的原理和底层实现。
本章根据历史时间线介绍了 HotSpot VM 现存的所有垃圾回收器。10.1 节简单讨论虚拟机与垃圾回收器交互的机制。10.2 节介绍了 SerialGC,它使用单线程清理垃圾。10.3 节的 Parallel GC 解决了 Serial GC 的不足,使用多线程清理垃圾。10.4 节的 CMS GC 部分解决了 Parallel GC 的不足,除了多线程清理垃圾外,还允许清理垃圾过程中 Mutator 线程继续运行。10.5 节的 G1GC 解决了 CMS GC 的不足,将堆划分为 Region,回收过程中整理 Region,消除碎片化。10.6 节的 Shenandoah GC 解决了 G1 GC 的不足,它的回收停顿时间不会随着堆变大而增长,同时允许对象复制阶段 Mutator 线程继续工作。10.7 和 10.8 节的 ZGC 与 Shenandoah GC 同属于新一代的低延时垃圾回收器,它们的目标 STW 时间均小于 10ms,且不会随着堆的增大而变长。最后对所有垃圾回收器做了简单总结。
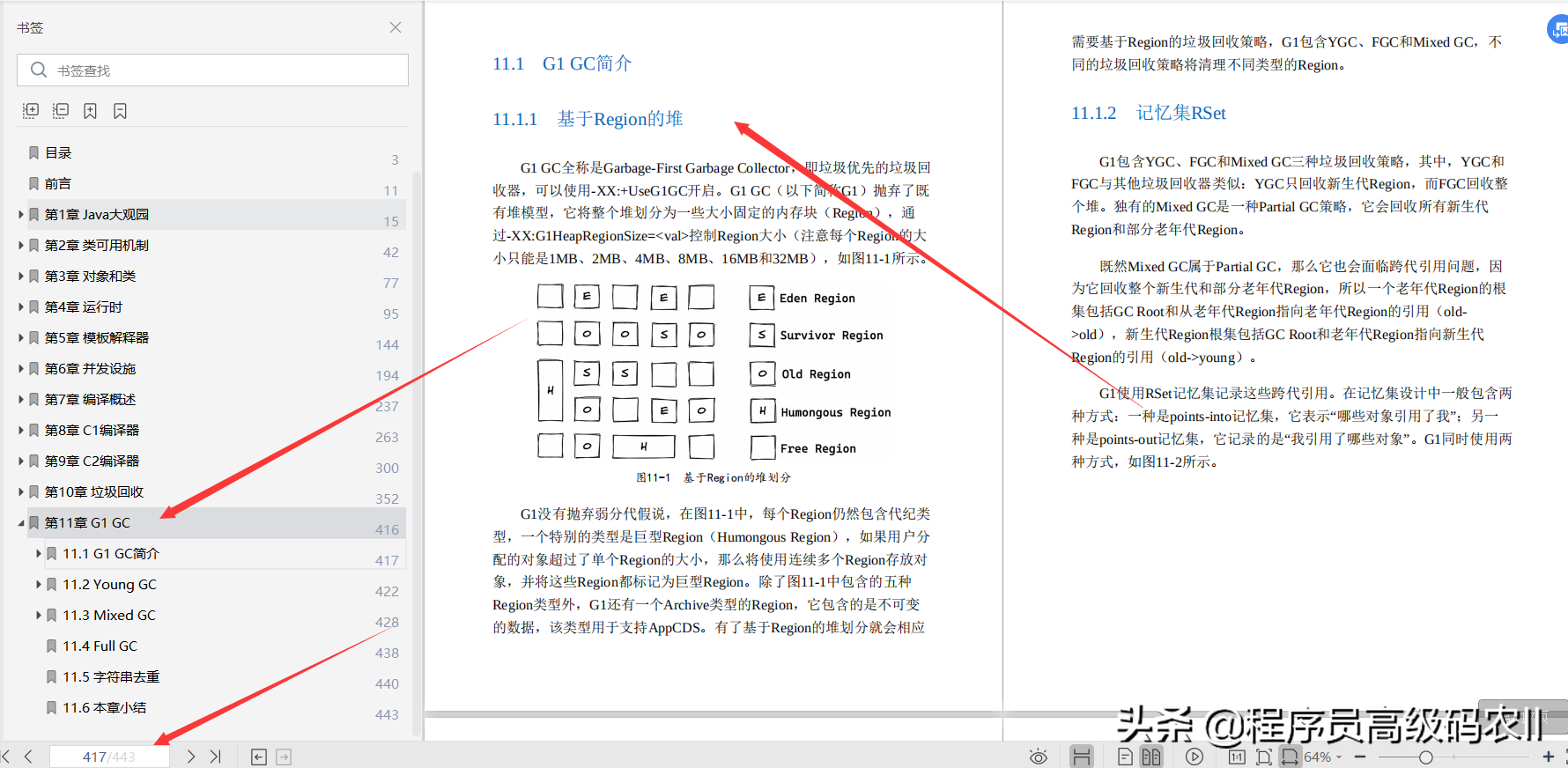
第 11 章 G1GC;G1 GC 是面向服务端应用程序的垃圾回收器,通过新的堆设计和停顿预测模型,可以到达用户指定的一个比较合理的软实时目标。本章将详细分析 G1 GC 的设计和实现。
11.1 节简单介绍了 G1 的基本概念及其垃圾回收策略。11.2 节详细讨论了 YGC。11.3 节重点讨论了 G1 独有的 Mixed GC,具体回收过程可分为全局并发标记和对象复制过程。其中,全局并发标记选择收益较高的对象,对象复制借用 YGC 的代码将对象复制到新的 Region,然后清理原来的 Region。11.4 节简单讨论了 FGC,在 YGC 或者 FGC 过程中 G1 可以可选地执行字符串去重操作。11.5 节以 YGC 为例介绍了 G1 字符串去重。
本文适合的读者对象
本文适合那些希望在 Java 语言方面有进一步提升的开发者,也适合任何对 JVM 底层感兴趣且想要一探究竟的开发者。
同时,对编译器或垃圾回收器感兴趣的读者也能从中受益。
【深入解析 Java 虚拟机 HotSpot 手册原文档👇】