编译软件:IntelliJ IDEA 2019.2.4 x64
操作系统:win10 x64 位 家庭版
Maven版本:apache-maven-3.6.3
Mybatis版本:3.5.6
文章目录
- 一、Mybatis中的自动映射是什么?
- 二、Mybatis中的自定义映射是什么?
- 三、为什么要使用自定义映射[resultMap]?
- 四、自定义映射[resultMap]可以适用哪些场景?
- 4.1 resultMap之级联映射
- 4.1.1 级联映射之association映射[1:1]
- 4.1.2 级联映射之collection映射[1:m]
- 4.2 总结ResultMap中的相关标签及属性
- 4.3 分步查询
- 4.3.1 一对一的关联关系
- 4.3.2 一对多的关联关系
- 4.3.3 扩展
- 五、Mybatis如何使用延迟加载【懒加载】?

一、Mybatis中的自动映射是什么?
Mybatis中的自动映射不是什么高大上的技术名词,而是我们使用Mybatis框架进行持久化层开发时常用select元素中的常见属性resultType,它可以自动将数据库内表中的字段与类中的属性进行关联映射,故而得名。
二、Mybatis中的自定义映射是什么?
👉定义
自定义映射,简而言之,就是resultMap。Mybatis官方将resultMap称为结果映射,在为一些比如连接的复杂语句编写映射代码的时候,一份 resultMap 能够代替实现同等功能的数千行代码。
👉设计思想
对简单的语句做到零配置,对于复杂一点的语句,只需要描述语句之间的关系就行了。
三、为什么要使用自定义映射[resultMap]?
💡原因
它可以解决自动映射[resultType]解决不了的两类问题
❓ 哪两类问题?
-
🍓多表连接查询时,需要返回多张表的结果集
不信?请看如下测试案例
测试案例:通过员工id获取员工信息及员工所属的部门信息
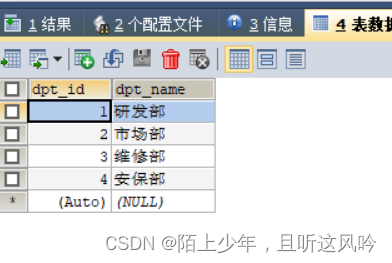
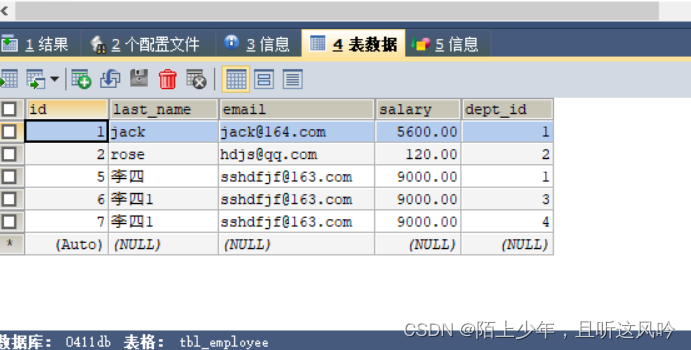
①准备数据
②在Mapper接口书写相应的方法
代码示例如下:
//通过员工id获取员工信息及员工所属的部门信息 public List<Employee> showempByempId(int empId);③在接口对应的映射文件中书写相应的sql
代码示例如下:
<select id="showempByempId" resultType="employee"> SELECT e.`id`, e.`last_name`, e.`email`, e.`salary`, d.`dpt_id`, d.`dpt_name` FROM `tbl_employee` e, `tbl_department` d WHERE e.`dept_id`=d.`dpt_id` AND e.`id`=1; </select>③测试
@Test public void test01(){ try { String resource = "mybatis-config.xml"; InputStream inputStream = Resources.getResourceAsStream(resource); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream); //通过SqlSessionFactory对象调用openSession(); SqlSession sqlSession = sqlSessionFactory.openSession(); //获取EmployeeMapper的代理对象 EmployeeMapper employeeMapper = sqlSession.getMapper(EmployeeMapper.class); List<Employee> employees = employeeMapper.showempByempId(1); System.out.println(employees); } catch (IOException e) { e.printStackTrace(); } }
🙋 为什么员工所属的部门信息查不出来?
🙇 原因
书写的sql涉及到多表查询,映射文件中相应select子标签的属性为resultType。该属性不支持映射多表查询后的结果集,需要用到自定义映射来解决该问题
-
🍓单表查询时,不支持驼峰式自动映射【如果不想为字段定义别名】
自定义映射【resultMap】:自动映射解决不了的问题,可以交给自定义映射
👇 注意
resultType与resultMap只能同时使用一个
四、自定义映射[resultMap]可以适用哪些场景?
4.1 resultMap之级联映射
🙋 何为级联映射?
👇 答曰
级联映射是指在保存主对象时,将关联的对象也一起保存到数据库中。例如,对于一对多或者多对一、多对多等关系对象时,当保存某个一对象时,与这个依赖的对象都应该自动保存或更新。比如:部门和员工表,一对多关系,当保存部门数据时,和部门有关联的员工表也同时保存。
用法案例
基于第三节中的案例,在映射文件中使用resultMap来解决多表查询后结果集中dept值为null的问题
代码示例如下:
①在在映射文件中使用自定义映射
<resultMap id="empAnddeptResultMap" type="employee">
<!-- column:返回的结果集中的字段 property:返回值类型(employee)中的属性,要映射的类 -->
<!-- id属性是定义主键字段与属性之间的关联关系 -->
<id column="id" property="id"></id>
<!-- result属性是定义非主键字段与属性之间的关联关系 -->
<result column="last_name" property="lastName"></result>
<result column="email" property="email"></result>
<result column="salary" property="salary"></result>
<result column="dpt_id" property="dept.deptId"></result>
<result column="dpt_name" property="dept.deptName"></result>
</resultMap>
<select id="showempByempId" resultMap="empAnddeptResultMap">
SELECT
e.`id`,
e.`last_name`,
e.`email`,
e.`salary`,
d.`dpt_id`,
d.`dpt_name`
FROM
`tbl_employee` e, `tbl_department` d
WHERE
e.`dept_id`=d.`dpt_id`
AND
e.`id`=1;
</select>
②测试运行
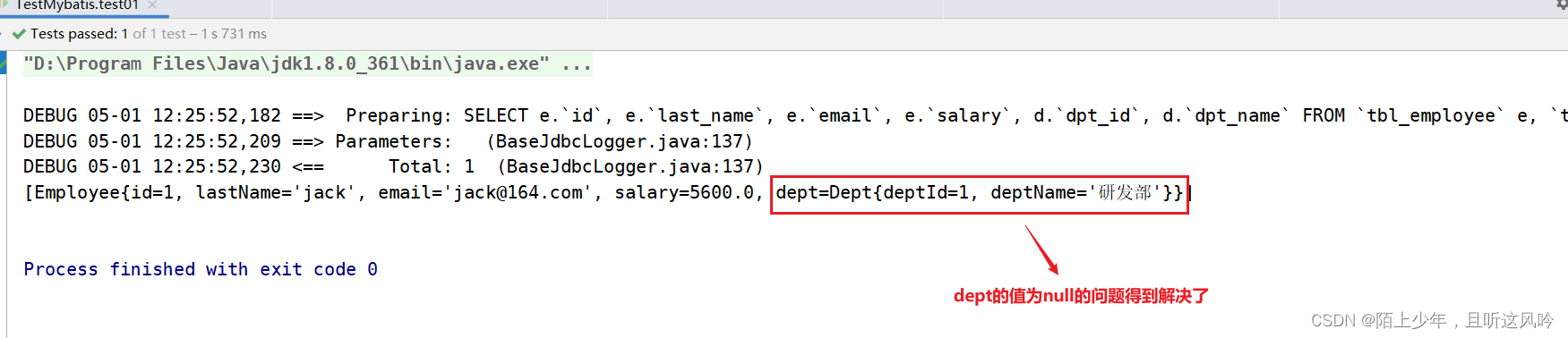
4.1.1 级联映射之association映射[1:1]
👉特点
解决一对一的关联关系
👉用法案例
基于4.1小结中的案例,对映射文件中的sql部分进行association映射的改写,观察效果
代码示例如下:
①对映射文件中的sql部分进行association映射的改写
<resultMap id="empAnddeptResultMap" type="employee">
<!-- column:返回的结果集中的字段 property:返回值类型(employee)中的属性,要映射的类 -->
<!-- id属性是定义主键字段与属性之间的关联关系 -->
<id column="id" property="id"></id>
<!-- result属性是定义非主键字段与属性之间的关联关系 -->
<result column="last_name" property="lastName"></result>
<result column="email" property="email"></result>
<result column="salary" property="salary"></result>
<!-- javaType: 用来指定某个属性(dept)或字段在 Java 代码中所对应的具体数据类型 (mybatis.pojo.Dept) -->
<!-- dept属性指的是employee对象中的属性 -->
<association property="dept" javaType="mybatis.pojo.Dept">
<id column="dpt_id" property="deptId"></id>
<result column="dpt_name" property="deptName"></result>
</association>
</resultMap>
<select id="showempByempId" resultMap="empAnddeptResultMap">
SELECT
e.`id`,
e.`last_name`,
e.`email`,
e.`salary`,
d.`dpt_id`,
d.`dpt_name`
FROM
`tbl_employee` e, `tbl_department` d
WHERE
e.`dept_id`=d.`dpt_id`
AND
e.`id`=1;
</select>
②测试运行
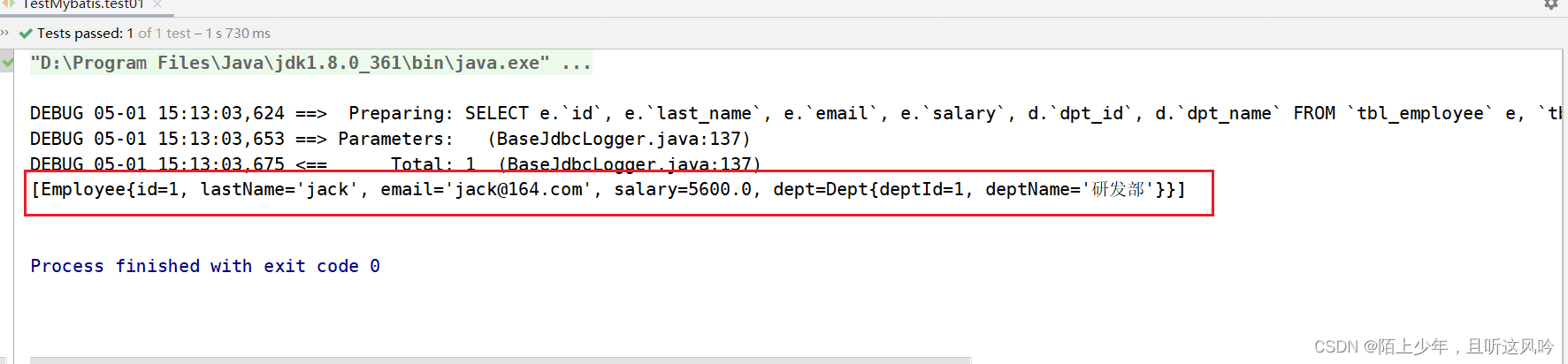
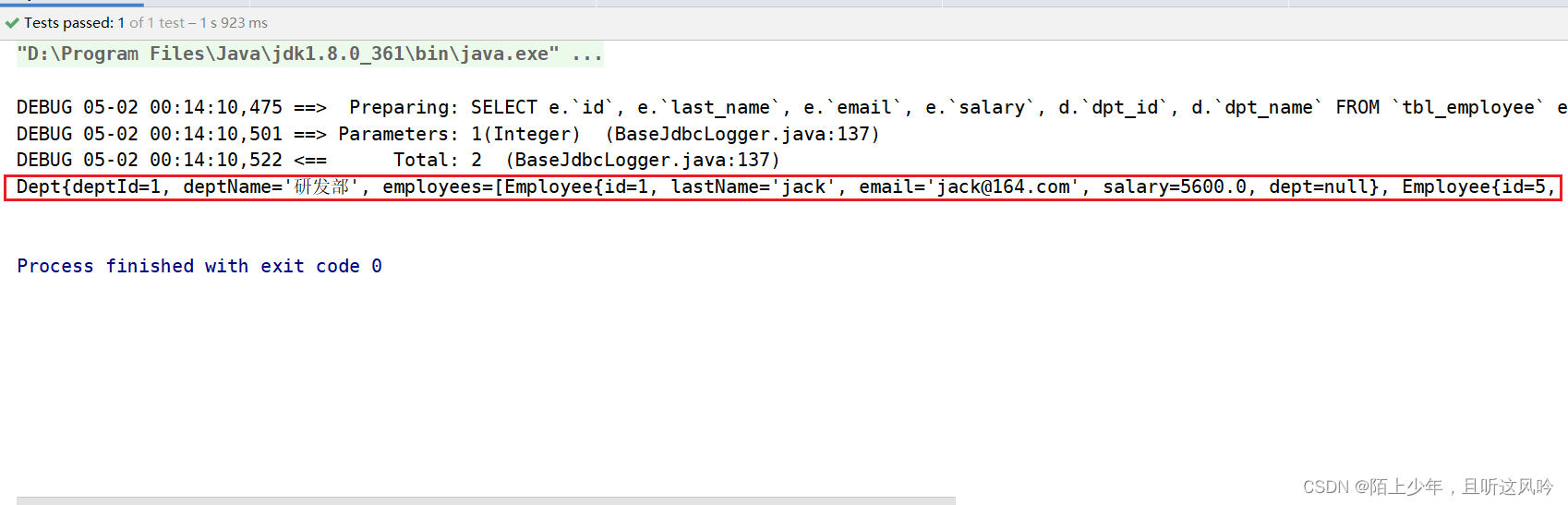
4.1.2 级联映射之collection映射[1:m]
👉特点
解决一对多的关联关系
👉用法案例
根据部门编号查询对应的部门信息,然后拿着部门编号去员工表里去找所属的员工信息(此时部门与员工是一对多的关系)
代码示例如下:
准备数据
①在DeptMapper接口书写相应的方法
//根据部门编号查询对应的部门信息,然后拿着部门编号去员工表里去找所属的员工信息(一对多)
public Dept showEmployeesByDeptId(int deptId);
②在在DeptMapper接口对应的映射文件中书写相应的sql
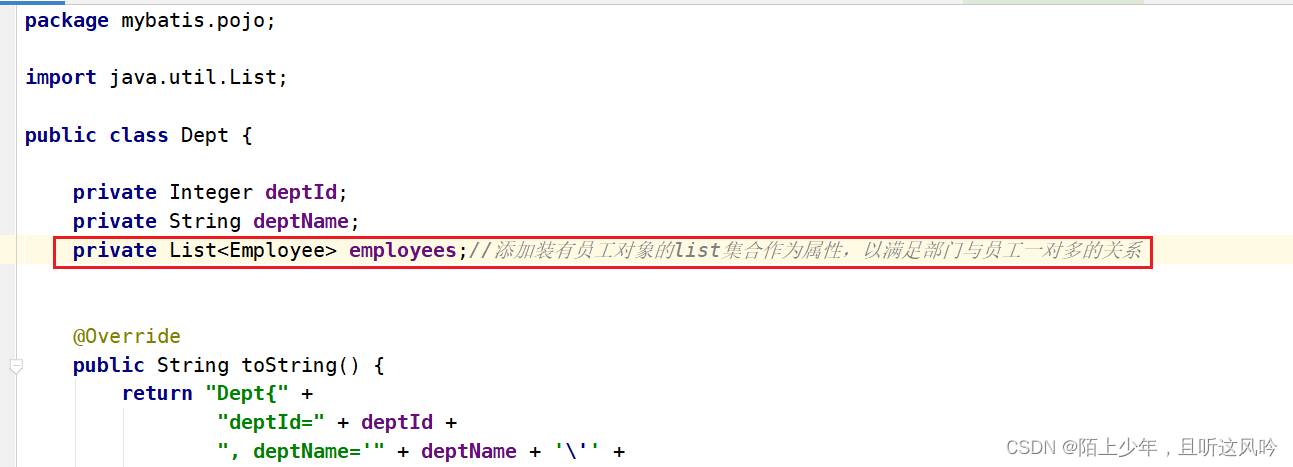
<!-- collection property="employees" ofType="mybatis.pojo.Employee" -> 在Dept类中名为employees的集合中存储的元素类型 -->
<resultMap id="showEmployeesByDeptIdResultMap" type="dept">
<id property="deptId" column="dpt_id"></id>
<result property="deptName" column="dpt_name"></result>
<collection property="employees" ofType="mybatis.pojo.Employee">
<!-- id属性是定义主键字段与属性之间的关联关系 -->
<id column="id" property="id"></id>
<!-- result属性是定义非主键字段与属性之间的关联关系 -->
<result column="last_name" property="lastName"></result>
<result column="email" property="email"></result>
<result column="salary" property="salary"></result>
</collection>
</resultMap>
<select id="showEmployeesByDeptId" resultMap="showEmployeesByDeptIdResultMap">
SELECT
e.`id`,
e.`last_name`,
e.`email`,
e.`salary`,
d.`dpt_id`,
d.`dpt_name`
FROM
`tbl_employee` e, `tbl_department` d
WHERE
e.`dept_id`=d.`dpt_id`
AND
d.`dpt_id`=#{dptId};
</select>
③测试
@Test
public void test04(){
try {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//通过SqlSessionFactory对象调用openSession();
SqlSession sqlSession = sqlSessionFactory.openSession();
//获取EmployeeMapper的代理对象
DeptMapper deptMapper = sqlSession.getMapper(DeptMapper.class);
//查询部门编号为1的部门信息,并得到所属员工的所有员工信息
Dept dept = deptMapper.showEmployeesByDeptId(1);
System.out.println(dept);
} catch (IOException e) {
e.printStackTrace();
}
}

4.2 总结ResultMap中的相关标签及属性
-
resultMap标签:自定义映射标签id属性:定义唯一标识type属性:设置映射类型
-
resultMap子标签-
id标签:定义主键字段与属性关联关系 -
result标签:定义非主键字段与属性关联关系column属性:定义表中字段名称property属性:定义类中属性名称
-
associationi标签:定义一对一的关联关系property属性:定义关联关系属性javaType属性:定义关联关系属性的类型select属性:设置分步查询SQL全路径colunm属性:设置分步查询SQL中需要参数fetchType:设置局部延迟加载【懒加载】
-
collection标签:定义一对多的关联关系property属性:定义关联关系属性ofType属性:定义关联关系属性类型select属性:设置分步查询SQL全路径colunm属性:设置分步查询SQL中需要参数fetchType:设置局部延迟加载【懒加载】是否开启
-
4.3 分步查询
🙋 为什么使用分步查询【分步查询优势】?
将多表连接查询,改为【分步单表查询】,从而提高程序运行效率
4.3.1 一对一的关联关系
👉用法案例
使用分步查询实现通过员工id获取员工信息及员工所属的部门信息,比如说1.通过员工id获取员工信息,2.通过员工信息中的部门id获得所属部门得信息(员工与部门是一对一的关系,即一个员工只能归属一个部门)
代码示例如下:
①在EmployeeMapper接口中定义实现通过员工id获取员工信息的方法
//使用分步查询实现通过员工id获取员工信息及员工所属的部门信息
//1.通过员工id获取员工信息
//2.通过员工信息中的部门id获得所属部门得信息
public Employee selectEmpByempId(int empId);
②在DeptMapper接口中定义实现通过从查出来的员工信息中的部门编号去查所属部门信息
//通过部门id查询所属部门得信息
public Dept selectDeptByDeptId(int deptId);
③在EmployeeMapper接口对应的映射文件书写相应的sql
<resultMap id="selectEmpByempIdResultMap" type="mybatis.pojo.Employee">
<id property="id" column="id"></id>
<result property="lastName" column="last_name"></result>
<result property="email" column="email"></result>
<result property="salary" column="salary"></result>
<!-- column="deptId" 设置分步查询SQL中需要得参数dept_Id;将此值传入到mybatis.mapper.DeptMapper中的selectDeptByDeptId()方法中 -->
<association property="dept"
select="mybatis.mapper.DeptMapper.selectDeptByDeptId"
column="dept_Id" >
</association>
</resultMap>
<select id="selectEmpByempId" resultMap="selectEmpByempIdResultMap">
SELECT
`id`,
`last_name`,
`email`,
`salary`,
`dept_id`
FROM
`tbl_employee`
WHERE
`id`=#{empId};
</select>
④在DeptMapper接口对应的映射文件中书写相应的sql
<resultMap id="selectDeptByDeptIdResultMap" type="dept">
<id property="deptId" column="dpt_Id"></id>
<result property="deptName" column="dpt_name"></result>
</resultMap>
<select id="selectDeptByDeptId" resultMap="selectDeptByDeptIdResultMap">
select
dpt_Id,
dpt_name
from
tbl_department
where
dpt_Id=#{dptId}
</select>
⑤测试
@Test
public void test02(){
try {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//通过SqlSessionFactory对象调用openSession();
SqlSession sqlSession = sqlSessionFactory.openSession();
//获取EmployeeMapper的代理对象
EmployeeMapper employeeMapper = sqlSession.getMapper(EmployeeMapper.class);
Employee employee = employeeMapper.selectEmpByempId(2);
System.out.println(employee);
} catch (IOException e) {
e.printStackTrace();
}
}
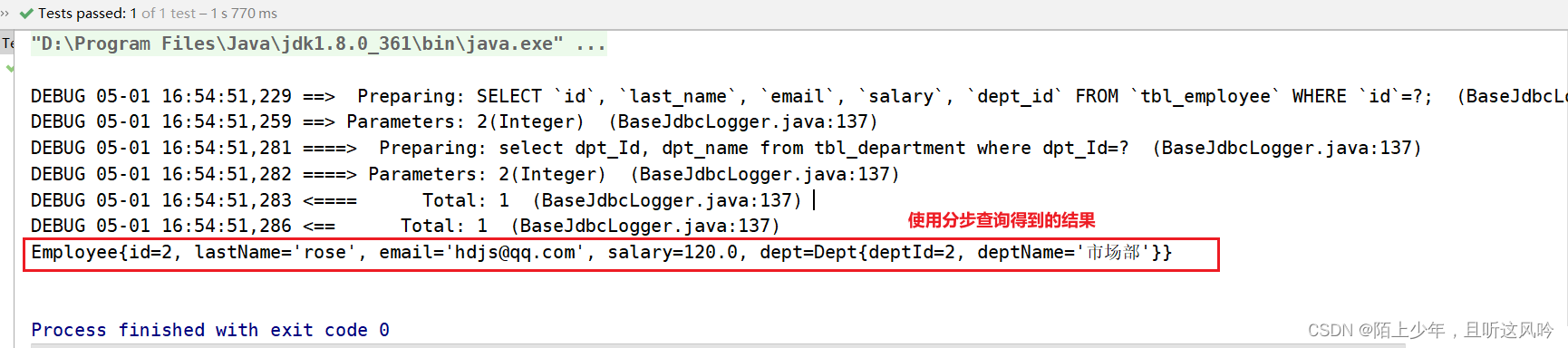
4.3.2 一对多的关联关系
👉用法案例
通过部门id获取部门信息,及部门所属员工信息【使用分步查询来实现】,其中按1.通过部门id获取部门信息;2.通过部门id获取员工信息等这两个步骤完成分步查询
代码示例如下:
①在DeptMapper接口中书写查询通过部门id获取部门信息的方法
//通过部门id获取部门信息
public Dept showEmployeesByDeptIdBetter(int deptId);
②在DeptMapper接口对应的映射文件中书写相应的sql
<!-- type="dept" 设置映射类型为dept,为什么不是dept类的全称,因为我在配置文件给它起了别名 -->
<resultMap id="showEmployeesByDeptIdBetterResultMap" type="dept">
<id property="deptId" column="dpt_id"></id>
<result property="deptName" column="dpt_name"></result>
<collection property="employees"
select="mybatis.mapper.EmployeeMapper#selectEmployeeByempId"
column="dpt_Id">
</collection>
</resultMap>
<select id="showEmployeesByDeptIdBetter" resultMap="showEmployeesByDeptIdBetterResultMap">
SELECT
`dpt_id`,
`dpt_name`
FROM
`tbl_department`
WHERE
`dpt_id`=#{dptId};
</select>
③在EmployeeMapper接口中书写查询通过部门id获取所属员工信息的方法
//通过部门id查询对应的员工信息
public Employee selectEmployeeByempId(int empId);
④在EmployeeMapper接口对应的映射文件中书写相应的sql
<select id="showEmployeesByDeptIdBetter" resultMap="showEmployeesByDeptIdBetterResultMap">
SELECT
`dpt_id`,
`dpt_name`
FROM
`tbl_department`
WHERE
`dpt_id`=#{dptId};
</select>
⑤测试
@Test
//测试分步查询版(根据部门编号查询对应的部门信息,然后拿着部门编号去员工表里去找所属的员工信息)
public void test05(){
try {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//通过SqlSessionFactory对象调用openSession();
SqlSession sqlSession = sqlSessionFactory.openSession();
//获取EmployeeMapper的代理对象
DeptMapper deptMapper = sqlSession.getMapper(DeptMapper.class);
Dept dept = deptMapper.showEmployeesByDeptId(1);
System.out.println(dept);
} catch (IOException e) {
e.printStackTrace();
}
}
4.3.3 扩展
如果使用分步查询时,需要传递给调用的查询中多个参数,则需要将多个参数封装成 Map来进行传递,语法如下:{k1=v1,k2=v2}
五、Mybatis如何使用延迟加载【懒加载】?
🙋什么是延迟加载?
需要时加载,不需要暂时不加载,如何理解?举个生活中的例子,就好比当你非常饥饿时,才会去吃饭
👉优势
可以提高程序运行效率
👉语法
🚀①全局设置
在核心配置文件中这样写,示例代码如下
<settings>
<!-- 开启驼峰命名自动映射 -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
<!-- 开启全局延迟加载模式 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 关闭按需延迟加载模式,在3.4.2版本及以后该步骤可省略 -->
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
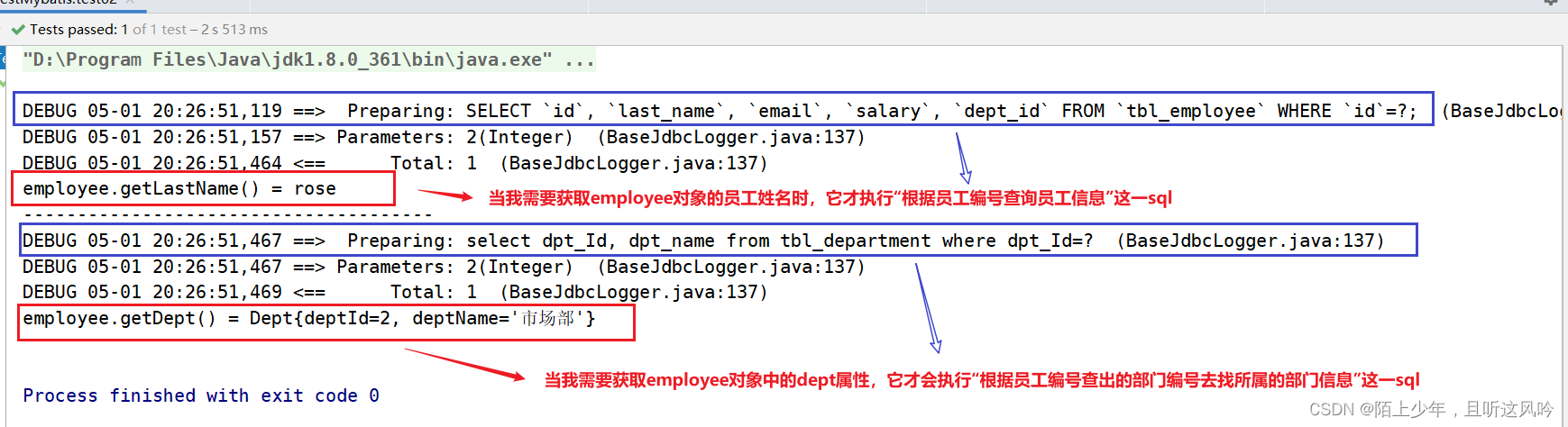
👉用法案例
在核心配置文件开启全局延迟加载模式,借助8.6小结中的案例代码,演示全局延迟加载模式的效果
代码示例如下:
测试运行如下
try {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//通过SqlSessionFactory对象调用openSession();
SqlSession sqlSession = sqlSessionFactory.openSession();
//获取EmployeeMapper的代理对象
EmployeeMapper employeeMapper = sqlSession.getMapper(EmployeeMapper.class);
Employee employee = employeeMapper.selectEmpByempId(2);
System.out.println("employee.getLastName() = "+employee.getLastName());
System.out.println("--------------------------------------");
System.out.println("employee.getDept() = "+employee.getDept());
} catch (IOException e) {
e.printStackTrace();
}
🚀②局部设置
- fetchType
eager:关闭局部延迟加载lazy:开启局部延迟加载
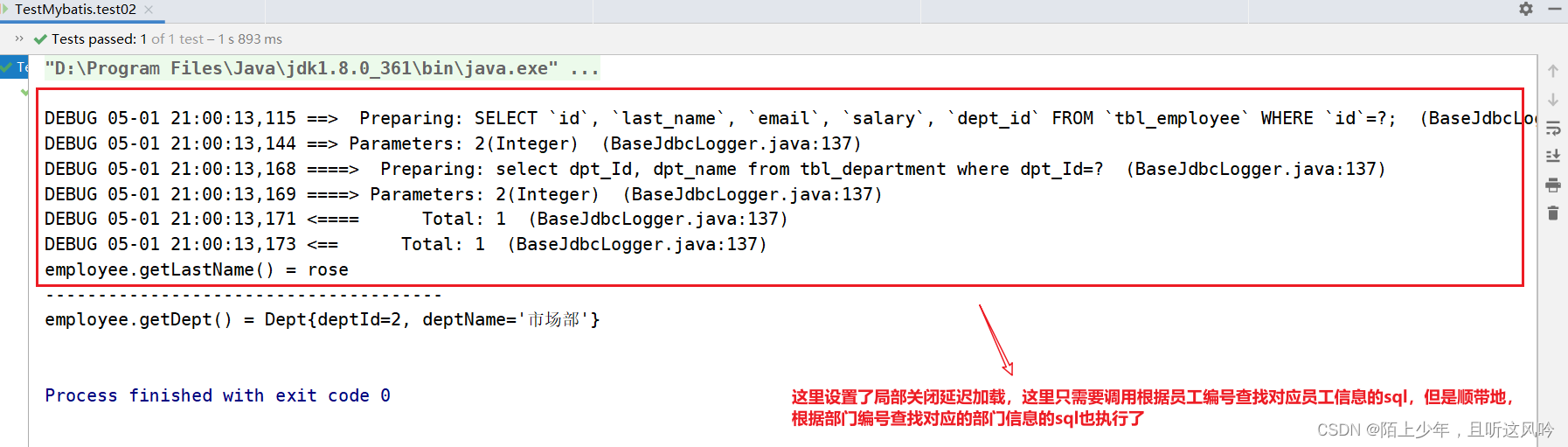
👉用法案例
在上述案例中EmployeeMapper接口对应的映射文件里属性id的值为"selectEmpByempId"的sql设置关闭延迟加载(已经设置了全局延迟加载模式,这里再开启局部延迟加载,效果不明显,遂采用关闭局部延迟加载测试效果)
代码示例如下:
<resultMap id="selectEmpByempIdResultMap" type="mybatis.pojo.Employee">
<id property="id" column="id"></id>
<result property="lastName" column="last_name"></result>
<result property="email" column="email"></result>
<result property="salary" column="salary"></result>
<!-- column="deptId" 设置分步查询SQL中需要得参数dept_Id;将此值传入到mybatis.mapper.DeptMapper中的selectDeptByDeptId()方法中 -->
<!-- fetchType="lazy" 为此方法设置局部延迟加载 -->
<association property="dept"
select="mybatis.mapper.DeptMapper.selectDeptByDeptId"
column="dept_Id"
fetchType="lazy" >
</association>
</resultMap>
<select id="selectEmpByempId" resultMap="selectEmpByempIdResultMap">
SELECT
`id`,
`last_name`,
`email`,
`salary`,
`dept_id`
FROM
`tbl_employee`
WHERE
`id`=#{empId};
</select>
运行测试如下



![[ 容器 ] consul 容器服务更新与发现](https://img-blog.csdnimg.cn/c0f2af38347240909770df7d97cd2264.png)






![如何将路径字符串数组(string[])转成树结构(treeNode[])?](https://img-blog.csdnimg.cn/img_convert/f9f060c8f56b9eea23673cb9bb1102fa.png)