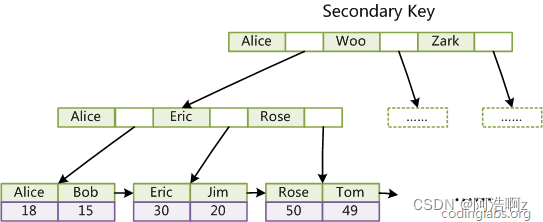
原文链接:https://aclanthology.org/2023.eacl-main.146.pdf
EACL 2023
介绍
对于information bottleneck (IB) principle信息瓶颈原理,要么使用生成模型,要么使用信息压缩模型来提高在目标任务上的性能,因此作者将这两种模型进行结合来提高模型在NER任务上的表现。
对于其中一种IB模型VAE(其实不太懂这个是啥?),将span重构和同义词生成这两个部分整合到一个span-based的NER模型中,用来更新span representation。对于另一种IB模型VIB(也不知道这个是啥),添加了一个有监督的IB层,对信息进行压缩以便在生成的span表征中保留对NER有用的信息。
方法
整体结构如下图所示:
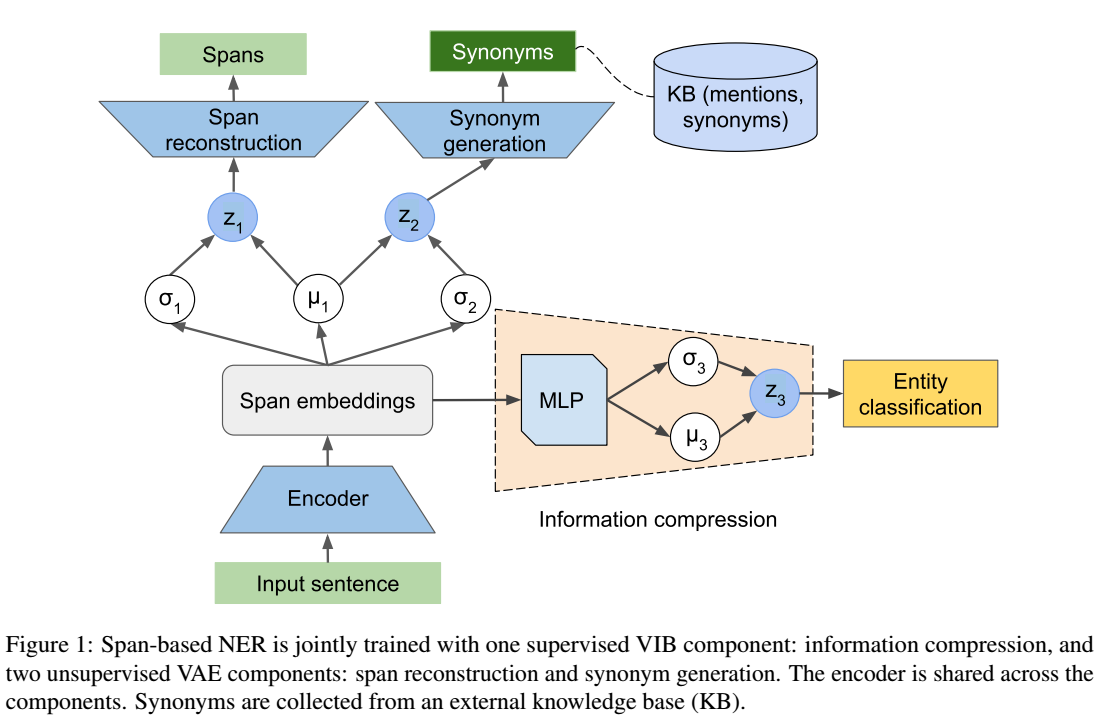
encoder输出的span embedding用于三个任务:1)实体的分类(分为实体类和非实体类两类);2)span的重构,用于recover gold 实体的input span(???为啥要recover?好像是因为要训练VAE??瞎猜的);3)生成gold 实体的同义词;在训练中三部分同时进行,但在推理阶段只应用第一部分来预测实体。
Span Reconstruction and Synonym Generation
Encoder
将句子输入到基于多层transformer的encoder中,得到每个token向量
,枚举在最大长度以内的所有span,每个span的embedding表示为:
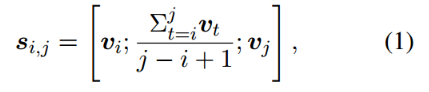
得到的span embedding后再经过两个线性层得到q(z|s) 的分布(利用重参数化技巧,通过潜变量 z 逼近后验分布),
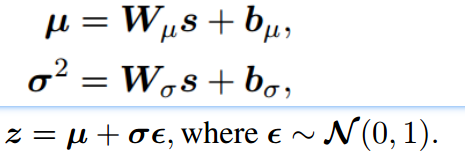
其中 µ 和 σ 是多元高斯参数,代表span的特征空间。由于这里要训练两个任务:span 重构和生成同义词,因此σ1和σ2是两个独立的参数。但为了引导这两个任务分布密切,对µ进行共享。
Decoders
decoder使用LSTM,在encoder给定latent z的情况下,首先使z通过一个线性层变换来初始化decoder的隐藏状态。然后,用teacher forcing策略(可以参考这里)来得到decoder的输入,比如:将z和gold span或者gold 同义词的每个单词进行concat。
Learning
为了训练VAEs,使用重构损失(使用交叉熵损失)和KL散度作为损失函数。
重构span任务的损失函数如下所示:
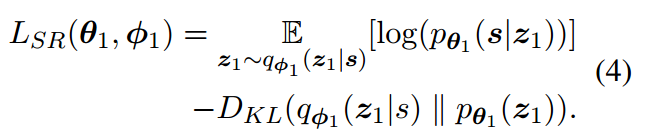
同义词生成的损失函数如下:
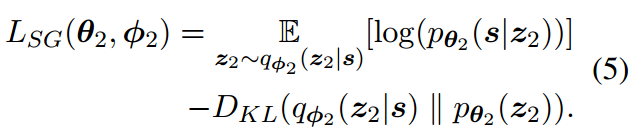
参数中的下标表示该参数属于span重建部分或者同义词生成部分之一。
Entity Classification with Supervised IB
有监督的IB任务主要目标是保留与目标类别中相关的信息,并过滤掉输入中的无关消息。目标损失函数主要包括compression损失和预测损失:
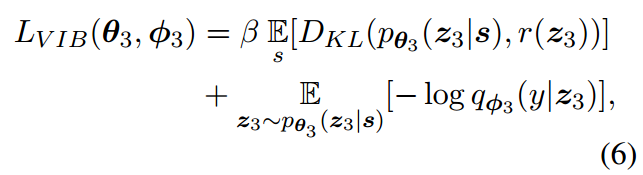
其中是先验概率
的估计。
使用两层的MLP来计算压缩后的span的表征( compressed representation of a span),使用另一个线性层来估计![]() ,并使用一个sigmoid函数来对输入的span进行二分类预测其类别。
,并使用一个sigmoid函数来对输入的span进行二分类预测其类别。
Training Objective
总的训练损失如下所示:
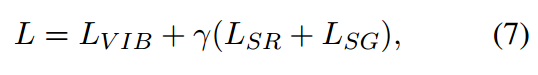
r是值为0-1之间的超参数,在训练期间,在所有的span上进行计算,而
和
只在gold span上进行计算。
实验
对比实验
在所有语料库中,将本文提出的jointly模型和使用sciBert并基于span的模型进行了比较,实验结果如下所示:
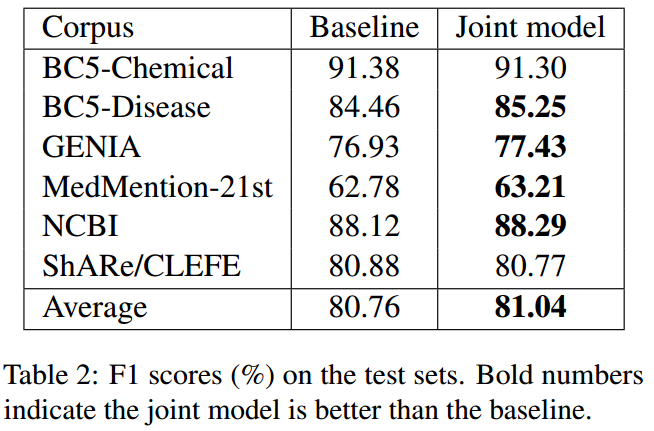
在BC5数据集上的效果没有baseline好,作者认为是因为对该数据集中的span进行重构和找到正确的同义词比较复杂。
在GENIA数据集上的结果如下所示:
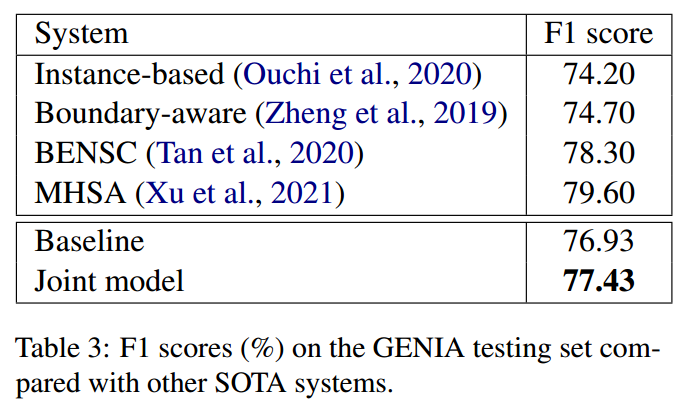
可以看出作者提出的模型虽然比基于实例和边界敏感的模型效果要好,但是却没有BENSC和MHSA的效果好,作者认为这是因为这两个模型是专门解决嵌套ner的,但我们的模型并没有对嵌套ner做任何特俗的处理。另外,作者强调他们的目标不是提高SOTA,而是研究NER的联合模型,并且作者提出的模型是可以纳入SOTA中的。
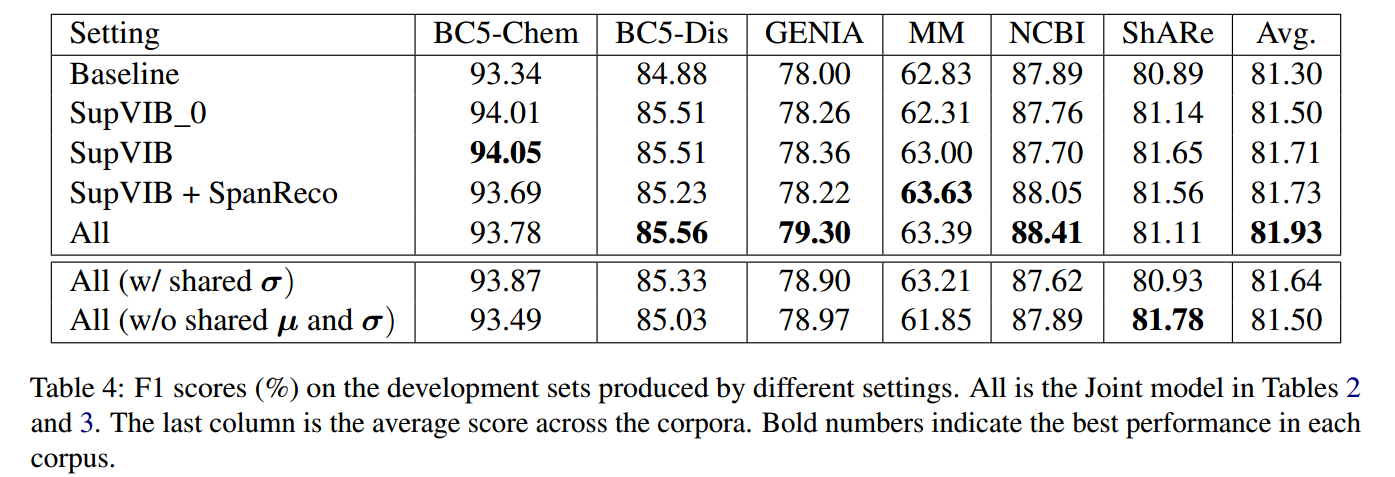
消融实验
作者对模型的重要模块进行了消融实验,结果如下所示:
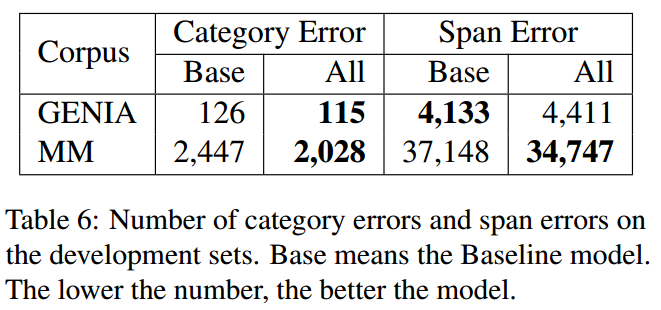
将验证集中预测错误的span数量进行统计,如下所示:

GENIA和MM数据集中类别预测错误和span预测错误的统计结果如下:
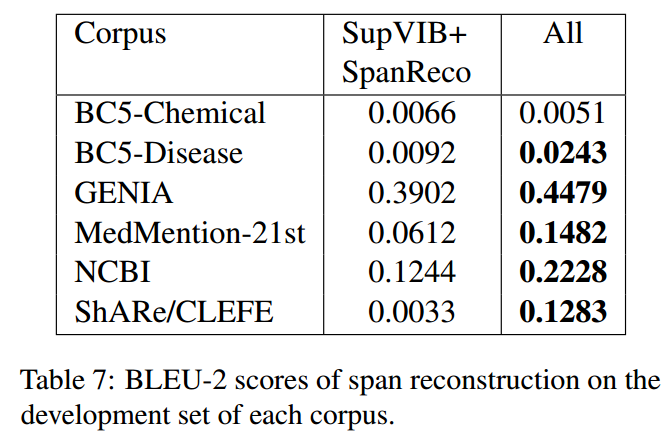
计算了在每个语料库的验证集上重建的gold entity的 BLEU-2 分数:
总结
这篇论文没有看得很明白,文中作者还做了很多实验,由于看不太懂,就没有细究放上来。最开始还以为是一个two-stage的结构(先训练VAE那两部分的任务,再来训练实体的分类) ,但是文中提到只是提前几个epoch训练VAE中两个任务,再联合实体分类进行训练。不过还是没看懂这里VAEs的目的是什么?文中说是用于update span的表征,还是不太明白怎么去update的,
参考:
直观理解 VAE(译文) - 简书
Information Bottleneck 信息瓶颈_whatever?picky?的博客-CSDN博客