词法分析器或词法分析器定义文件内容如何分解为标记。词法分析器是自定义语言插件几乎所有功能的基础,比如基本语法突出显示到高级代码分析功能。由Lexer来定义。IDE在三个主要上下文中调用词法分析器,插件可以根据需要提供不同的词法分析器实现:
- 语法高亮Syntax highlighting:依赖com.intellij.lang.syntaxHighlighterFactory扩展点来实现。
- 构建文件的语法树:依赖com.intellij.lang.parserDefinition扩展点实现,通过调用其.createLexer()方法;
- 构建文件中包含的单词的索引:如果使用基于词法分析器的单词扫描器实现,可以将词法分析器传递给DefaultWordsScanner构造函数。
用于语法高亮显示的词法分析器可以增量调用以仅处理文件的更改部分。相反,在其他上下文中使用的词法分析器总是被调用来处理整个文件或嵌入在不同语言文件中的完整语言结构。
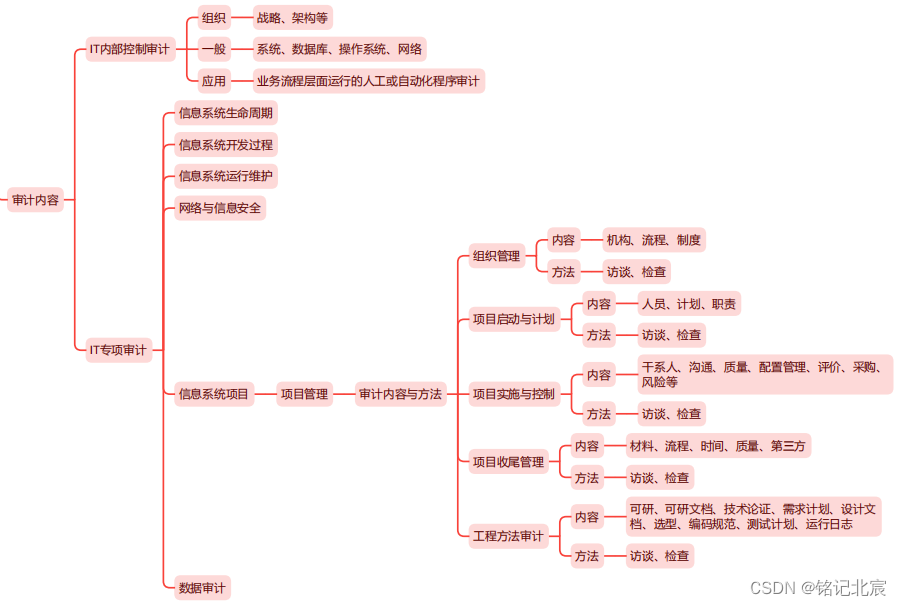
一、Lexer
1、词法分析器状态
使用增量类型的词法分析器(Syntax highlighting)需要返回其实时状态,即应于文件中每个位置的上下文,比如:java记法分析器可以为顶级上下文、注释上下文和字符串文字上下文设置不同的状态。
语法高亮词法分析器的状态是由Lexer.getState()返回的单个整数表示。如果从文件中间恢复词法分析时,该状态将与要处理的片段的起始偏移量一起传递给Lexer.start()方法,其它两类分析器一般只需返回0或Lexer.start()即可。
2、如何实现
使用JFlex是一种简单的为自定义语言插件创建词法分析器方法,可以使用扩展的FlexLexer和FlexAdapter类。另外可以使用 JFlex 的补丁版本和idea-flex.skeleton 集成一起实现FlexAdapter。
开发方法分析器时,可以同时使用 Grammar-Kit plugin 来辅助开发。示例代码
properties.flex
package com.intellij.lang.properties.parsing;
import com.intellij.lexer.FlexLexer;
import com.intellij.psi.tree.IElementType;
%%
%class _PropertiesLexer
%implements FlexLexer
%unicode
%function advance
%type IElementType
CRLF=\R
WHITE_SPACE_CHAR=[\ \n\r\t\f]
VALUE_CHARACTER=[^\n\r\f\\] | "\\"{CRLF} | "\\".
END_OF_LINE_COMMENT=("#"|"!")[^\r\n]*
KEY_SEPARATOR=[:=]
KEY_SEPARATOR_SPACE=\ \t
KEY_CHARACTER=[^:=\ \n\r\t\f\\] | "\\"{CRLF} | "\\".
FIRST_VALUE_CHARACTER_BEFORE_SEP={VALUE_CHARACTER}
VALUE_CHARACTERS_BEFORE_SEP=([^:=\ \t\n\r\f\\] | "\\"{CRLF} | "\\".)({VALUE_CHARACTER}*)
VALUE_CHARACTERS_AFTER_SEP=([^\ \t\n\r\f\\] | "\\"{CRLF} | "\\".)({VALUE_CHARACTER}*)
%state IN_VALUE
%state IN_KEY_VALUE_SEPARATOR_HEAD
%state IN_KEY_VALUE_SEPARATOR_TAIL
%%
<YYINITIAL> {END_OF_LINE_COMMENT} { yybegin(YYINITIAL); return PropertiesTokenTypes.END_OF_LINE_COMMENT; }
<YYINITIAL> {KEY_CHARACTER}+ { yybegin(IN_KEY_VALUE_SEPARATOR_HEAD); return PropertiesTokenTypes.KEY_CHARACTERS; }
<IN_KEY_VALUE_SEPARATOR_HEAD> {
{KEY_SEPARATOR_SPACE}+ { yybegin(IN_KEY_VALUE_SEPARATOR_HEAD); return PropertiesTokenTypes.WHITE_SPACE; }
{KEY_SEPARATOR} { yybegin(IN_KEY_VALUE_SEPARATOR_TAIL); return PropertiesTokenTypes.KEY_VALUE_SEPARATOR; }
{VALUE_CHARACTERS_BEFORE_SEP} { yybegin(YYINITIAL); return PropertiesTokenTypes.VALUE_CHARACTERS; }
{CRLF}{WHITE_SPACE_CHAR}* { yybegin(YYINITIAL); return PropertiesTokenTypes.WHITE_SPACE; }
}
<IN_KEY_VALUE_SEPARATOR_TAIL> {
{KEY_SEPARATOR_SPACE}+ { yybegin(IN_KEY_VALUE_SEPARATOR_TAIL); return PropertiesTokenTypes.WHITE_SPACE; }
{VALUE_CHARACTERS_AFTER_SEP} { yybegin(YYINITIAL); return PropertiesTokenTypes.VALUE_CHARACTERS; }
{CRLF}{WHITE_SPACE_CHAR}* { yybegin(YYINITIAL); return PropertiesTokenTypes.WHITE_SPACE; }
}
<IN_VALUE> {VALUE_CHARACTER}+ { yybegin(YYINITIAL); return PropertiesTokenTypes.VALUE_CHARACTERS; }
<IN_VALUE> {CRLF}{WHITE_SPACE_CHAR}* { yybegin(YYINITIAL); return PropertiesTokenTypes.WHITE_SPACE; }
{WHITE_SPACE_CHAR}+ { return PropertiesTokenTypes.WHITE_SPACE; }
[^] { return PropertiesTokenTypes.BAD_CHARACTER; }3、Token类型
词法分析器的标记类型由IElementType来定义,TokenType用来定义语言中的标记类型。对于语言中没有的类型需要创建新的IElementType并与TokenType进行关联。也可以使用TokenSet定义类型组,比如:
public interface PropertiesTokenTypes {
IElementType WHITE_SPACE = TokenType.WHITE_SPACE;
IElementType BAD_CHARACTER = TokenType.BAD_CHARACTER;
IElementType END_OF_LINE_COMMENT = new PropertiesElementType("END_OF_LINE_COMMENT");
IElementType KEY_CHARACTERS = new PropertiesElementType("KEY_CHARACTERS");
IElementType VALUE_CHARACTERS = new PropertiesElementType("VALUE_CHARACTERS");
IElementType KEY_VALUE_SEPARATOR = new PropertiesElementType("KEY_VALUE_SEPARATOR");
TokenSet COMMENTS = TokenSet.create(END_OF_LINE_COMMENT);
TokenSet WHITESPACES = TokenSet.create(WHITE_SPACE);
}public interface GroovyTokenSets {
/**
* http://docs.groovy-lang.org/latest/html/documentation/core-syntax.html#_keywords
*/
TokenSet KEYWORDS = create(
KW_AS, KW_ASSERT, KW_BREAK, KW_CASE,
KW_CATCH, KW_CLASS, /*const,*/ KW_CONTINUE,
KW_DEF, KW_VAR, KW_DEFAULT, KW_DO, KW_ELSE,
KW_ENUM, KW_EXTENDS, KW_FALSE, KW_FINALLY,
KW_FOR, /*goto,*/ KW_IF, KW_IMPLEMENTS,
KW_IMPORT, KW_IN, T_NOT_IN, KW_INSTANCEOF, T_NOT_INSTANCEOF, KW_INTERFACE,
KW_NEW, KW_NULL, KW_PACKAGE, KW_RETURN,
KW_SUPER, KW_SWITCH, KW_THIS, KW_THROW,
KW_THROWS, KW_TRAIT, KW_TRUE, KW_TRY,
KW_WHILE, KW_YIELD
);
TokenSet STRING_LITERALS = create(STRING_SQ, STRING_TSQ, STRING_DQ, STRING_TDQ);
TokenSet LOGICAL_OPERATORS = create(T_LAND, T_LOR);
TokenSet EQUALITY_OPERATORS = create(T_EQ, T_NEQ, T_ID, T_NID);
TokenSet RELATIONAL_OPERATORS = create(T_GT, T_GE, T_LT, T_LE, T_COMPARE);
TokenSet BITWISE_OPERATORS = create(T_BAND, T_BOR, T_XOR);
TokenSet ADDITIVE_OPERATORS = create(T_PLUS, T_MINUS);
TokenSet MULTIPLICATIVE_OPERATORS = create(T_STAR, T_DIV, T_REM);
TokenSet SHIFT_OPERATORS = create(LEFT_SHIFT_SIGN, RIGHT_SHIFT_SIGN, RIGHT_SHIFT_UNSIGNED_SIGN);
TokenSet REGEX_OPERATORS = create(T_REGEX_FIND, T_REGEX_MATCH);
TokenSet RANGES = create(T_RANGE, T_RANGE_BOTH_OPEN, T_RANGE_LEFT_OPEN, T_RANGE_RIGHT_OPEN);
TokenSet OTHER_OPERATORS = create(KW_AS, KW_IN, T_NOT_IN, T_POW, KW_INSTANCEOF, T_NOT_INSTANCEOF);
TokenSet BINARY_OPERATORS = orSet(
LOGICAL_OPERATORS,
EQUALITY_OPERATORS,
RELATIONAL_OPERATORS,
BITWISE_OPERATORS,
ADDITIVE_OPERATORS,
MULTIPLICATIVE_OPERATORS,
SHIFT_OPERATORS,
REGEX_OPERATORS,
RANGES,
OTHER_OPERATORS
);
TokenSet OPERATOR_ASSIGNMENTS = create(
T_POW_ASSIGN,
T_STAR_ASSIGN,
T_DIV_ASSIGN,
T_REM_ASSIGN,
T_PLUS_ASSIGN,
T_MINUS_ASSIGN,
T_LSH_ASSIGN,
T_RSH_ASSIGN,
T_RSHU_ASSIGN,
T_BAND_ASSIGN,
T_XOR_ASSIGN,
T_BOR_ASSIGN
);
TokenSet ASSIGNMENTS = orSet(
create(T_ASSIGN, T_ELVIS_ASSIGN),
OPERATOR_ASSIGNMENTS
);
TokenSet REFERENCE_DOTS = create(T_DOT, T_SAFE_DOT, T_SAFE_CHAIN_DOT, T_SPREAD_DOT);
TokenSet METHOD_REFERENCE_DOTS = create(T_METHOD_CLOSURE, T_METHOD_REFERENCE);
TokenSet SAFE_DOTS = create(T_SAFE_DOT, T_SAFE_CHAIN_DOT);
TokenSet DOTS = orSet(REFERENCE_DOTS, METHOD_REFERENCE_DOTS);
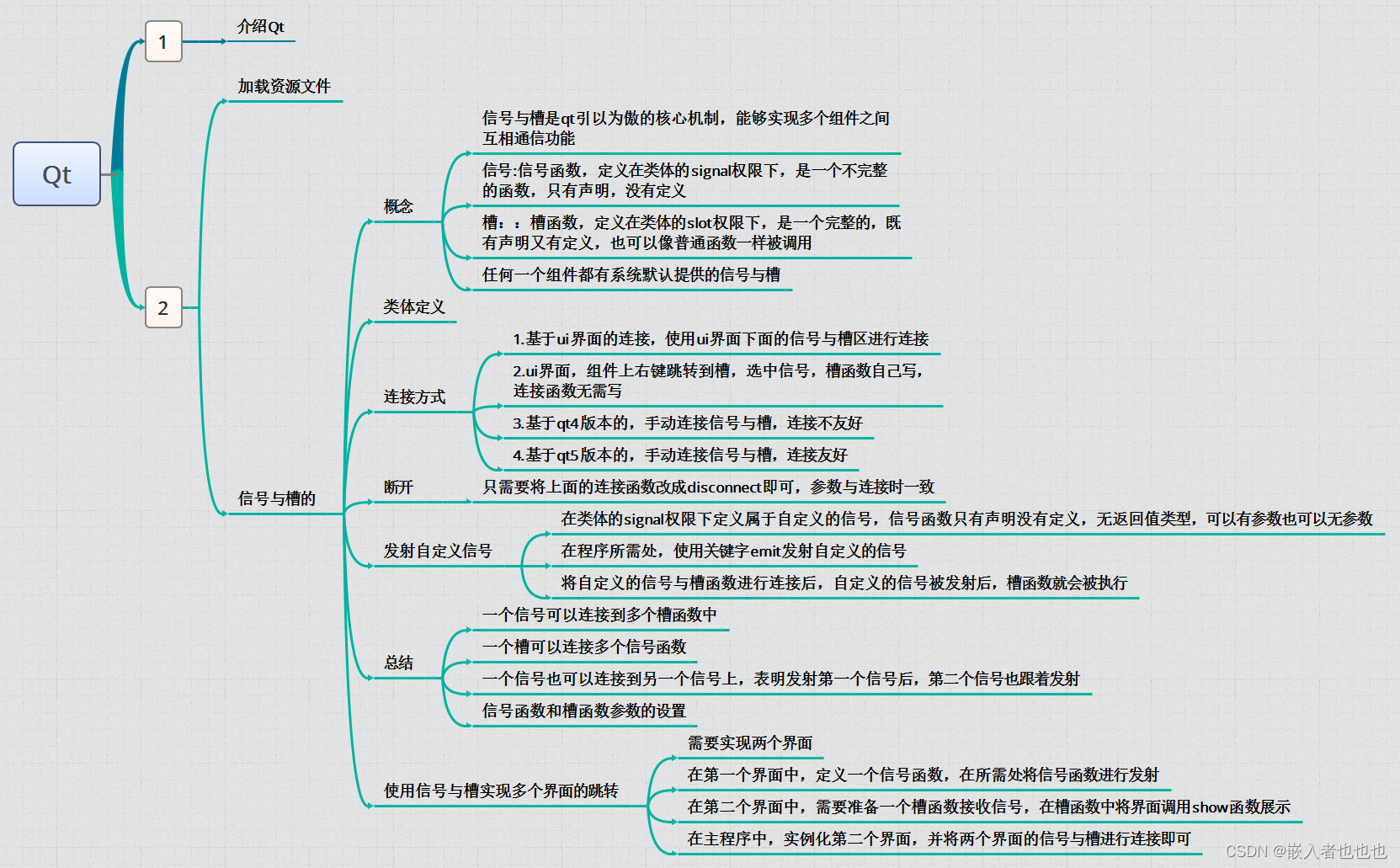
}4、嵌入式语言
编程语言的另外一个高级特性就是可以混合其它语言一起使用。例如在某些模板语言中嵌入 Java 代码片段,这种情况中需要为可以嵌入的不同类型的片段定义chameleon类型的令牌,从ILazyParseableElementType接口实现,在解析时整个嵌入式代码片断会做过一个整体交给ILazyParseableElementType.parseContents()来进行处理。
二、实现示例
1、定义Lexer
这个文件也不需要生动编写,使用Gramme KIT插件从.bnf文件生成即可,Simple.flex:
package org.intellij.sdk.language;
import com.intellij.lexer.FlexLexer;
import com.intellij.psi.tree.IElementType;
import org.intellij.sdk.language.psi.SimpleTypes;
import com.intellij.psi.TokenType;
%%
%class SimpleLexer
%implements FlexLexer
%unicode
%function advance
%type IElementType
%eof{ return;
%eof}
CRLF=\R
WHITE_SPACE=[\ \n\t\f]
FIRST_VALUE_CHARACTER=[^ \n\f\\] | "\\"{CRLF} | "\\".
VALUE_CHARACTER=[^\n\f\\] | "\\"{CRLF} | "\\".
END_OF_LINE_COMMENT=("#"|"!")[^\r\n]*
SEPARATOR=[:=]
KEY_CHARACTER=[^:=\ \n\t\f\\] | "\\ "
%state WAITING_VALUE
%%
<YYINITIAL> {END_OF_LINE_COMMENT} { yybegin(YYINITIAL); return SimpleTypes.COMMENT; }
<YYINITIAL> {KEY_CHARACTER}+ { yybegin(YYINITIAL); return SimpleTypes.KEY; }
<YYINITIAL> {SEPARATOR} { yybegin(WAITING_VALUE); return SimpleTypes.SEPARATOR; }
<WAITING_VALUE> {CRLF}({CRLF}|{WHITE_SPACE})+ { yybegin(YYINITIAL); return TokenType.WHITE_SPACE; }
<WAITING_VALUE> {WHITE_SPACE}+ { yybegin(WAITING_VALUE); return TokenType.WHITE_SPACE; }
<WAITING_VALUE> {FIRST_VALUE_CHARACTER}{VALUE_CHARACTER}* { yybegin(YYINITIAL); return SimpleTypes.VALUE; }
({CRLF}|{WHITE_SPACE})+ { yybegin(YYINITIAL); return TokenType.WHITE_SPACE; }
[^] { return TokenType.BAD_CHARACTER; }2、生成一个 Lexer Class
这也不需要手动编码,选择上面的Simple.flex文件,然后右键【Run JFlex Generator】,IDE 会在gen目录下生成词法分析器,例如/src /main /gen /org /intellij /sdk /language /SimpleLexer.java。

3、定义Lexer Adapter
定义这个类的主要目的是为了适配IntelliJ Platform Lexer API。
public class SimpleLexerAdapter extends FlexAdapter {
public SimpleLexerAdapter() {
super(new SimpleLexer(null));
}
}4、定义Root File
实现Simple语言树的顶级节点
public class SimpleFile extends PsiFileBase {
public SimpleFile(@NotNull FileViewProvider viewProvider) {
super(viewProvider, SimpleLanguage.INSTANCE);
}
@NotNull
@Override
public FileType getFileType() {
return SimpleFileType.INSTANCE;
}
@Override
public String toString() {
return "Simple File";
}
}5、定义TokenSets
public interface SimpleTokenSets {
TokenSet IDENTIFIERS = TokenSet.create(SimpleTypes.KEY);
TokenSet COMMENTS = TokenSet.create(SimpleTypes.COMMENT);
}6、定义Parser
为避免在初始化扩展点实现时进行不必要的类加载,所有TokenSet返回值都应使用专用$Language$TokenSets类中的常量。
public class SimpleParserDefinition implements ParserDefinition {
public static final IFileElementType FILE = new IFileElementType(SimpleLanguage.INSTANCE);
@NotNull
@Override
public Lexer createLexer(Project project) {
return new SimpleLexerAdapter();
}
@NotNull
@Override
public TokenSet getCommentTokens() {
return SimpleTokenSets.COMMENTS;
}
@NotNull
@Override
public TokenSet getStringLiteralElements() {
return TokenSet.EMPTY;
}
@NotNull
@Override
public PsiParser createParser(final Project project) {
return new SimpleParser();
}
@NotNull
@Override
public IFileElementType getFileNodeType() {
return FILE;
}
@NotNull
@Override
public PsiFile createFile(@NotNull FileViewProvider viewProvider) {
return new SimpleFile(viewProvider);
}
@NotNull
@Override
public PsiElement createElement(ASTNode node) {
return SimpleTypes.Factory.createElement(node);
}
}6、注册解析器
<extensions defaultExtensionNs="com.intellij">
<lang.parserDefinition
language="Simple"
implementationClass="org.intellij.sdk.language.SimpleParserDefinition"/>
</extensions>7、测试运行
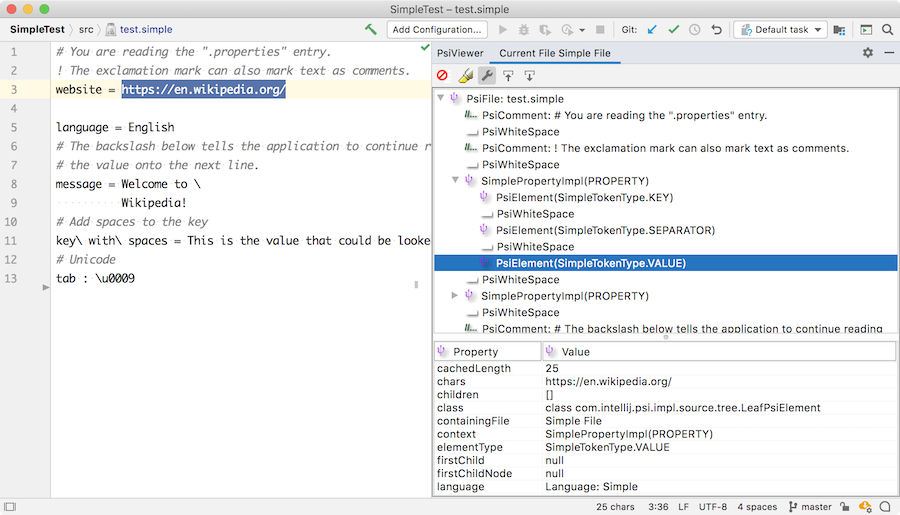
创建一个包含以下内容的test.simple文件
# You are reading the ".properties" entry.
! The exclamation mark can also mark text as comments.
website = https://en.wikipedia.org/
language = English
# The backslash below tells the application to continue reading
# the value onto the next line.
message = Welcome to \
Wikipedia!
# Add spaces to the key
key\ with\ spaces = This is the value that could be looked up with the key "key with spaces".
# Unicode
tab : \u0009现在打开PsiViewer工具窗口并检查词法分析器如何将文件内容分解为标记,以及解析器如何将标记转换为 PSI 元素。