基于论文摘要的文本分类与关键词抽取(一)
- 赛题介绍
- Baseline
- 思路
- 安装库并导入
- 数据集下载并处理
- 选择模型并训练
- 提交结果
赛题介绍
基于论文摘要的文本分类与关键词抽取挑战赛
本任务分为两个子任务:
1.机器通过对论文摘要等信息的理解,判断该论文是否属于医学领域的文献。
2. 提取出该论文关键词。
DataWhale 制作全流程基础演示:NLP实践全流程基础演示
Baseline
参考Datawhale手把手打一场NLP赛事
思路
这两个子任务可以分别使用文本分类和关键词抽取技术来实现。
对于第一个子任务,可以使用文本分类模型(如朴素贝叶斯、支持向量机等)对论文摘要进行训练和预测,从而判断该论文是否属于医学领域的文献。在训练数据中,需要标注每篇论文所属的领域(如医学、生物、化学等),并将摘要作为输入特征。在预测阶段,将待测论文摘要输入到训练好的文本分类模型中,得到该论文所属的领域标签。
对于第二个子任务,可以使用关键词抽取技术来提取出论文中的关键词。常用的关键词抽取方法有TF-IDF、TextRank等。其中,TF-IDF是一种基于词频和逆文档频率的方法,可以将文本转化为向量表示,并计算出每个词在该向量中的权重;TextRank则是一种基于图论的算法,可以将文本中的每个词看作一个节点,通过计算节点之间的相似度构建出一个图,最后根据节点的重要性排序得到关键词列表。
数据集解析
训练集与测试集数据为CSV格式文件,各字段分别是标题、作者和摘要。Keywords为任务2的标签,label为任务1的标签。训练集和测试集都可以通过pandas读取。

安装库并导入
pip install nltk
python -m pip install paddlepaddle-gpu==2.5.0.post102 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html
导入所需包
# 导入pandas用于读取表格数据
import pandas as pd
# 导入BOW(词袋模型),可以选择将CountVectorizer替换为TfidfVectorizer(TF-IDF(词频-逆文档频率)),注意上下文要同时修改,亲测后者效果更佳
from sklearn.feature_extraction.text import CountVectorizer
# 导入LogisticRegression回归模型
from sklearn.linear_model import LogisticRegression
# 过滤警告消息
from warnings import simplefilter
from sklearn.exceptions import ConvergenceWarning
simplefilter("ignore", category=ConvergenceWarning)
数据集下载并处理
# 读取数据集
train = pd.read_csv('train.csv')
train['title'] = train['title'].fillna('')
train['abstract'] = train['abstract'].fillna('')
test = pd.read_csv('test.csv')
test['title'] = test['title'].fillna('')
test['abstract'] = test['abstract'].fillna('')
# 提取文本特征,生成训练集与测试集
train['text'] = train['title'].fillna('') + ' ' + train['author'].fillna('') + ' ' + train['abstract'].fillna('')+ ' ' + train['Keywords'].fillna('')
test['text'] = test['title'].fillna('') + ' ' + test['author'].fillna('') + ' ' + test['abstract'].fillna('')+ ' ' + train['Keywords'].fillna('')
vector = CountVectorizer().fit(train['text'])
train_vector = vector.transform(train['text'])
test_vector = vector.transform(test['text'])
选择模型并训练
# 引入模型
model = LogisticRegression()
# 开始训练,这里可以考虑修改默认的batch_size与epoch来取得更好的效果
model.fit(train_vector, train['label'])
# 利用模型对测试集label标签进行预测
test['label'] = model.predict(test_vector)
# 生成任务一推测结果
test[['uuid', 'Keywords', 'label']].to_csv('submit_task1.csv', index=None)
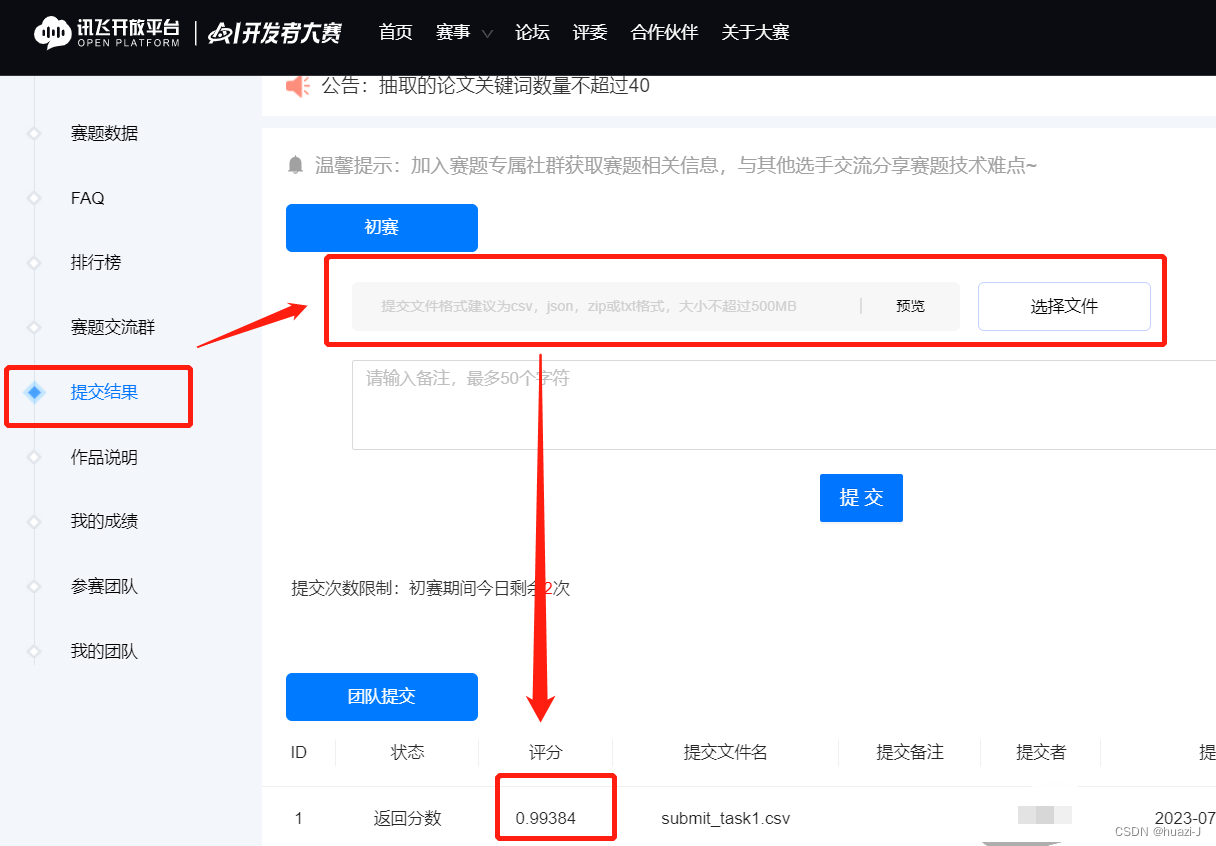
提交结果





![[Ubuntu 22.04] 安装Harbor](https://img-blog.csdnimg.cn/dff15db881304db994b5ee7334112fef.png)