文章目录
- 前言
- 导入模块
- 伪装自己
- 发送请求获取地址列表
- 获取所有背景的地址
- 创建文件夹
- 保存图片文件
- 完整代码
- 运行效果
- 部分图片展示
- 结束语

前言
本文介绍了一个使用Python编写的程序,用于获取指定网页的背景图片并保存到本地。在程序中使用了requests模块发送HTTP请求,lxml模块解析HTML文档,以及os模块操作文件与目录。文章详细介绍了每个模块的作用以及具体的代码实现。
本文主要内容包括:
- 导入所需的模块:介绍了
requests、lxml和os模块的作用,并提供了相应的安装方法。 - 伪装自己:创建了一个字典
headers,用于伪装成浏览器发送请求,以避免被网站识别为脚本发送的请求。 - 发送请求获取地址列表:使用
requests.get()方法发送HTTP GET请求获取指定URL的网页内容,并将返回的响应保存在变量list_resp中,后续用于解析网页内容。 - 获取所有背景的地址:使用
lxml模块解析网页内容,使用XPath表达式选取满足条件的图片地址,并将其存储在两个列表中。 - 创建文件夹:通过
os.path.exists()方法检查是否已存在名为’heng’和’shu’的文件夹,如果不存在则使用os.makedirs()方法创建。 - 保存图片文件:使用循环遍历获取到的图片地址,发送HTTP GET请求获取图片内容,并将内容写入本地文件。
通过阅读本文,你可以了解如何使用Python编写一个简单的程序来获取网页背景图片并保存到本地。希望本文对你有所帮助。
导入模块

# pip install requests 发送请求的模块
import requests
# pip install lxml
from lxml import etree
import os
- 代码中使用了
requests模块发送HTTP请求,判断是否导入该模块,如果没有导入则可以使用pip install requests命令安装。 - 代码中使用了
lxml模块解析HTML文档,判断是否导入该模块,如果没有导入则可以使用pip install lxml命令安装。 - 代码中使用了
os模块操作文件与目录,此模块通常是Python的内置模块,无需额外安装。
伪装自己
# 伪装自己
headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'}
- 创建一个字典
headers,其中包含"User-Agent"字段,用于伪装成浏览器发送请求。 - 通过设置
User-Agent字段,使得HTTP请求看起来像是由浏览器发送的,而不是由脚本发送的。
发送请求获取地址列表
# 发送请求获取地址列表
list_resp = requests.get('http://yys.163.com/media/picture.html',headers=headers)
- 使用
requests.get()方法发送HTTP GET请求,以获取指定URL的网页内容。 - 通过传入之前定义的
headers作为请求头信息,以模拟浏览器发送请求。 - 将返回的响应保存在
list_resp变量中,后续将使用它来解析网页内容。
获取所有背景的地址
# 获取所有背景的地址
e = etree.HTML(list_resp.text)
imgs1 =[url[:url.rindex('/')]+'/2732x2048.jpg' for url in e.xpath('//div[@class="tab-cont"][1]/div/div/img/@data-src')]
imgs2 =[url[:url.rindex('/')]+'/2732x2048.jpg' for url in e.xpath('//div[@class="tab-cont"][2]/div/div/img/@data-src')]
- 使用
etree.HTML()方法将list_resp.text(即网页内容)转换为可以进行XPath解析的对象。 - 使用XPath表达式选取满足条件的图片地址,并存储在两个列表
imgs1和imgs2中。这些地址是满足特定条件的背景图片的URL。 - 使用列表推导式从每个图片地址中提取出图片名称部分,并加上固定的路径片段,形成完整的图片URL。
创建文件夹
if not os.path.exists('heng'):
os.makedirs('heng')
if not os.path.exists('shu'):
os.makedirs('shu')
- 通过
os.path.exists()方法检查当前目录下是否已存在名为’heng’和’shu’的文件夹。 - 如果不存在对应的文件夹,则使用
os.makedirs()方法分别创建’heng’和’shu’文件夹。
保存图片文件
for url in imgs1:
resp = requests.get(url,headers=headers)
file_name = url[url.rindex('picture'):url.rindex('/')].replace('/','_')+'.jpg'
print('正在保存:'+file_name+'壁纸')
with open(f'heng/{file_name}','wb') as f:
f.write(resp.content)
- 使用
for循环遍历imgs1列表中的每个图片地址。 - 使用
requests.get()方法发送HTTP GET请求,获取每个图片的内容。 - 根据图片地址生成保存图片的文件名。通过截取URL中的一部分作为文件名,并将其中的
/替换为_。 - 使用
open()函数以二进制写入模式打开文件,并将图片内容写入文件。 - 输出每个保存的图片的信息,包括文件名和壁纸名称。提示用户正在保存哪个壁纸。
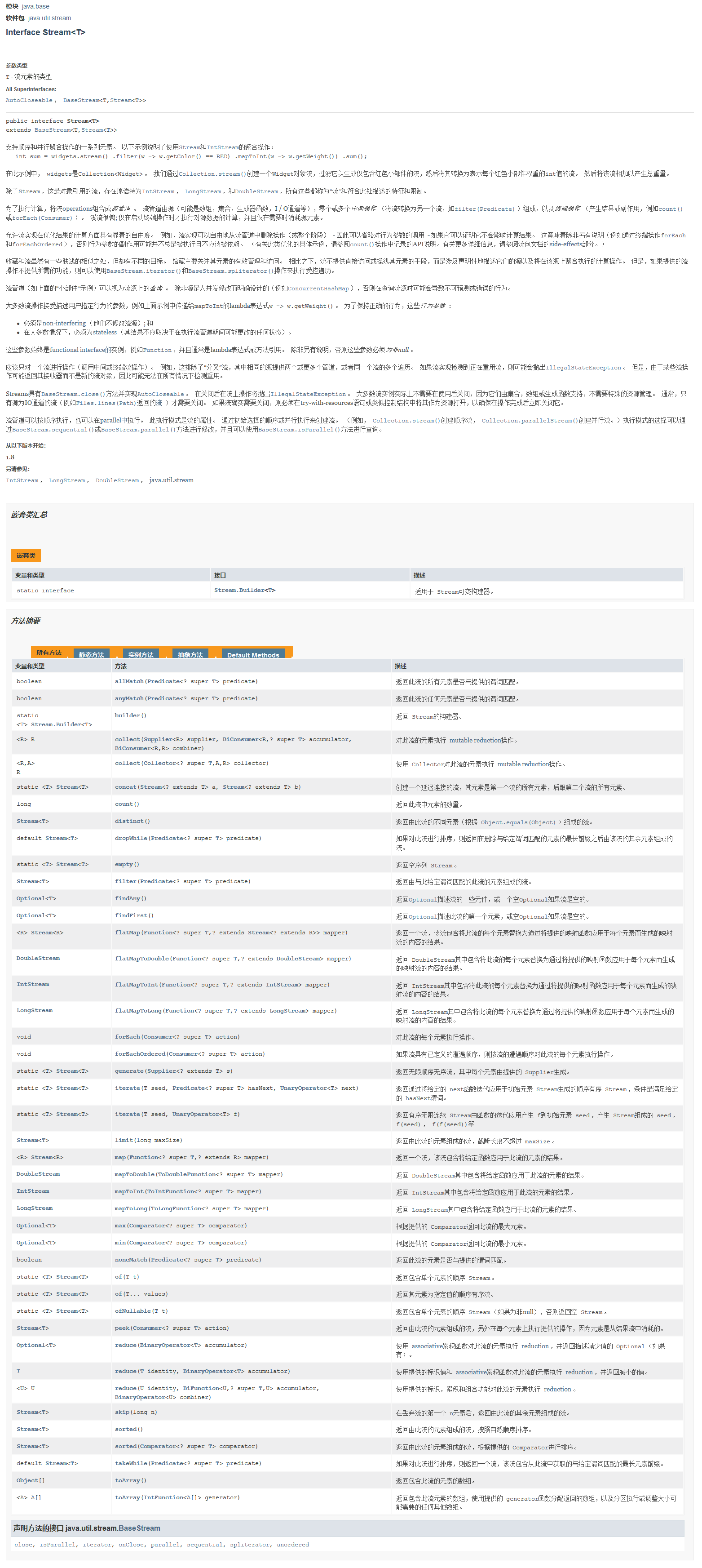
完整代码
# 导入所需的模块
import requests # 导入requests模块,用于发送HTTP请求
from lxml import etree # 导入lxml模块,用于解析HTML文档
import os # 导入os模块,用于操作文件和目录
# 伪装自己
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
} # 创建一个字典headers,包含"User-Agent"字段,用于伪装成浏览器发送请求。
# 发送请求获取地址列表
list_resp = requests.get('http://yys.163.com/media/picture.html', headers=headers) # 发送HTTP GET请求,获取指定URL的网页内容。
# 获取所有背景的地址
e = etree.HTML(list_resp.text) # 将list_resp.text(网页内容)转换为可以进行XPath解析的对象。
imgs1 = [url[:url.rindex('/')]+'/2732x2048.jpg' for url in e.xpath('//div[@class="tab-cont"][1]/div/div/img/@data-src')]
# 使用XPath表达式选取满足条件的图片地址,并存储在imgs1列表中。这些地址是满足特定条件的背景图片的URL。
imgs2 = [url[:url.rindex('/')]+'/2732x2048.jpg' for url in e.xpath('//div[@class="tab-cont"][2]/div/div/img/@data-src')]
# 创建文件夹
if not os.path.exists('heng'): # 检查当前目录下是否已存在名为'heng'的文件夹。
os.makedirs('heng') # 如果不存在'heng'文件夹,则使用os.makedirs()方法创建'heng'文件夹。
if not os.path.exists('shu'): # 检查当前目录下是否已存在名为'shu'的文件夹。
os.makedirs('shu') # 如果不存在'shu'文件夹,则使用os.makedirs()方法创建'shu'文件夹。
# 保存图片文件
for url in imgs1: # 使用循环遍历imgs1列表中的每个图片地址。
resp = requests.get(url, headers=headers) # 发送HTTP GET请求,获取每个图片的内容。
file_name = url[url.rindex('picture'):url.rindex('/')].replace('/', '_') + '.jpg'
# 根据图片地址生成保存图片的文件名。通过截取URL中的一部分作为文件名,并将其中的/替换为_。
print('正在保存:' + file_name + '壁纸') # 输出每个保存的图片的信息,包括文件名和壁纸名称。
with open(f'heng/{file_name}', 'wb') as f: # 以二进制写入模式打开文件,并将图片内容写入文件。
f.write(resp.content)
运行效果
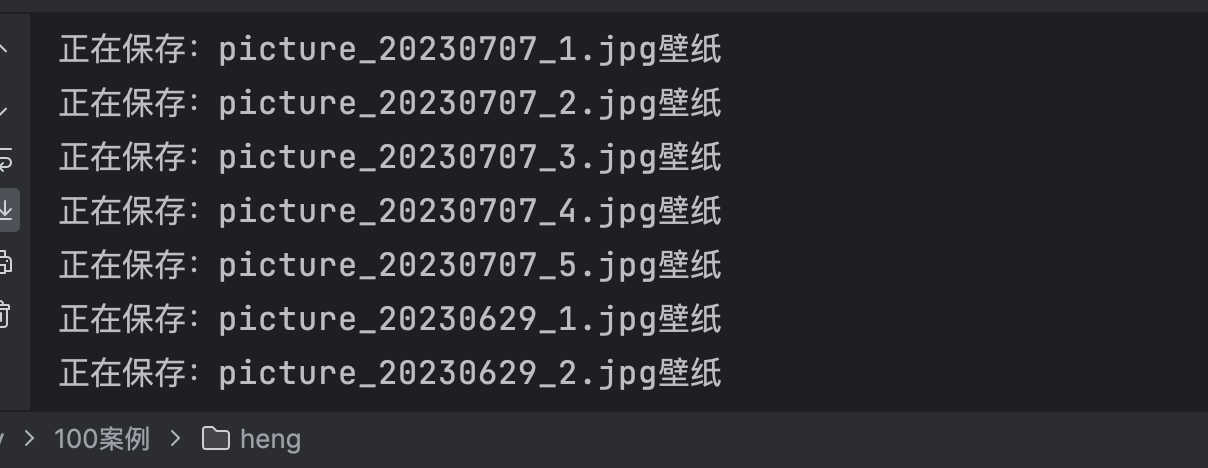
部分图片展示



结束语
本文介绍了一个基于Python的程序,用于获取指定网页的背景图片并保存到本地。通过使用requests模块发送HTTP请求、lxml模块解析HTML文档以及os模块操作文件与目录,我们可以轻松地实现这个功能。
无论是获取图片地址列表,还是创建文件夹和保存图片文件,本文都详细介绍了每一步的代码实现,同时还提供了运行效果和部分图片展示,帮助读者更好地理解和掌握这个程序。
希望本文能够对你有所帮助,如果你有任何疑问或者更好的建议,欢迎在评论区留言。谢谢阅读!









![[详细教程+渠道对接+实战陪跑社区]抖音超火小说推文新玩法](https://img-blog.csdnimg.cn/img_convert/6365cdb008e4ceee328785daa7fe3614.jpeg)