这是一篇个人使用前端工程开发项目的思考,希望可以帮助到你。完全是一篇综合概念应该是很多东西,我也不清楚会有多少字,估计会对刚刚开始的人看起来比较迷,但也是没有办法的事情
-
1.前端脚本语言开发的作者我想应该也想不到js会发展到今天这样和后端语言一较高下的时候,这一切的起源我想应该就是各大浏览器的发展,那时候刀耕火种js运行在各种浏览器上面,通过各大公司不同的js引擎,有很多不同的ast规范,各种兼容可谓是百家争鸣,现在的市场流行谷歌浏览器,然后谷歌的v8引擎,和node出现,导致js开启处理文本io流字符串各种功能,实现了与其他后端语言一样的服务。
-
2.node的出现我们从原生的写法创建一个后端项目然后把HTML放入,比如Java的jsp PHP的视图,这些老家伙的书写方法,开始被时代所放弃,出现了基于node的工程化项目。
-
1.工程化的过程出现了低级打包工具 高级打包工具,所谓的低级就是只管字符的处理,不管执行,高级就是基于这些编译后的结果,融入了各种服务然后执行,编译各种写法,比如Babel的出现让我们可以使用最新的语法,只需要引入包,使用各种typescript
js的变体,coffee jsx ts 这些东西的出现,把js的书写和弱项开始弥补,出现了
postcss Autoprefixer
让兼容样式写法变成了工具,使用更加方便我们可谓是站在巨人的肩膀上面。 -
1.通常现在的项目都是起一个所谓的cli脚手架 是一个综合性很强的集成工具包,融入了框架,样式,资源,服务,打包,编译,处理字符,使用node底层,来帮助我们开发。这一系统的融合,得益于一些流行的npm库,node是这个环境的启动者。
-
1.比如我们使用npm run dev所谓自定义的执行脚本命令,也是node读取当前目录或者全局指令注册下的结果,读当前的packagejson文件,然后执行script,如果里面是可执行脚本命令比如node
index.js,node就会帮你,如果是自定义的比如vue-cli这样的自定义的命令,他会去依赖文件里找bin文件夹寻找可执行的命令,使用commander
插件来提高自定义cmd操作,bin文件会注册cmd命令在你安装库的使用,如果是全局安装会自动注册,如果是局部也会自动执行,在node的安装过程中,分环境比如本地和生产,很多包也是这样用做区别,安装插件也分全局或者局部,我们也可以自行注册全局的包别名。 -
1.使用npm run dev 会触发vue-cli serve 综上这自定义库的自定义命令并不是node自带的,但确实node提供插件可创建的东西,所谓的serve 会开启一个基于net
http协议的端口 也会启动一个socket
ws协议,同时在本地客户端生成通信的websocket文件脚本,通常我把cli文件下面的src叫做客户端因为这一部分不会和node有关系,内容是更新于浏览器html内容,除这之外都是服务器node提供操作的地方,但是src里的操作js
资源 图片 服务 import require async 等等所有的东西都基于高级打包工具,比如webpack。 -
1.webpack帮我们处理js vue css img 字体 资源 图片各种 压缩 打包 编译 框架 服务等等,把一切浏览器不认识的东西变成认识的东西,这一切的功能都来自webpack自身的强大,提供了一系统了loader
plugin。入口文件 开始 就把所有资源处理调用对应的loader 在运行过程中使用plugin来拓展功能, -
1.可编译js并不是他的功能,而是babel在webpack什么的拓展,比如babel-loader,这只是遇见js文件的时候就叫给他,比如vue
就给到vue-loader 然后返回js 然后又给到babel-loader
,遇到css就给到css-loader,很多loader我们不一说明,我们重点描述一下Babel。 -
1.交给Babel的js,我们看出一段字符串,一段在非专业人士看起来没有规律的字符串,这一段给到babel。Babel是如何处理的?
1.其实 babel 的工作流程和编译原理中的编译流程相对简单。我们可以归纳如下几个步骤: 词法分析 语法分析 代码转换 代码生成.
2.其中分为词法分析和预发分析两步可以合并成解析(parse)过程
从上图可以看到编译从开始到结束有一个最重要的东西,抽象语法树/AST 的知识,以下简称 AST,babel 编译代码的整个流程都离不开它。
抽象语法树是高级编程语言(Java、JavaScript 等)转换成机器语言的桥梁。解析器会根据 ECMAScript 标准「JavaScript 语言规范」来对代码字符串进行词法分析,拆分成一个个词法单元,再遍历各个词法单元进行语法分析构造出 AST。
词法分析
词法分析阶段是对源代码进行“分词”,它接收一段源代码,然后执行一段 tokenize 函数,把代码分割成被称为 tokens 的东西。tokens 是一个数组,由一些代码的碎片组成,比如数字、标点符号、运算符号等等等等,
词法分析处理网站
在词法分析之后,语法分析会把词法分析得到的 tokens 转化为 AST,有兴趣的可以阅读一下 babel 源码 babel 转化 AST 源码
ast处理网站
@babel/parser 包的 parse 方法传入源代码,进行词法分析合语法分析,最终生成 AST 抽象语法树
@babel/traverse 包 traverse 方法接收 AST 抽象语法树并对其进行遍历(深度遍历),在此过程中对节点进行添加、更新及移除等操作。 这是 Babel 或是其他编译器中最复杂的过程,同时也是插件将要介入工作的地方,插件部分我们后边在讲
@babel/generator 包 generator 方法接收的 AST 抽象语法树转换成字符串形式的代码,同时还会创建源码映射(sourceMap,根据传入的参数控制是否生成 sourceMap)
@babel/traverse 的 traverse 转换过程是深度遍历整颗树对节点进行操作,它会访问树中的所有节点。这时候该方法第二个参数就起到作用了。这个参数是一个对象,对象每个属性是一个钩子函数。这个对象的属性值除了支持 AST 语法树节点的 type 值外,还有 enter,exit;也就是在遍历每个节点的时候会先进入 enter 钩子函数,如果存在该节点对应的钩子函数,还会执行该钩子函数,最后在访问该节点结束的时候执行 exit 钩子函数…
@babel/types,它的作用是创建、修改、删除、查找ast节点。另外从上边知道AST的节点也是分为多种类型,比如ExpressionStatement是表达式、ClassDeclaration是类声明、VariableDeclaration是变量声明等等,同样的这些类型都对应了其创建方法:t.expressionStatement、t.classDeclaration、t.variableDeclaration,也对应了判断方法:t.isExpressionStatement、t.isClassDeclaration、t.isVariableDeclaration。这个插件往往和traverse遍历插件一起使用,因为types只能对单一节点进行操作,一般是在对节点的深度遍历中使用。
babel.types 用做判断深度遍历ast时候处理对应type来提供方便
module.exports = function (babel) {
return {
visitor: {
Identifier(path) {
console.log(path.type, path.node.name);
},
CallExpression(path) {
if (
path.node.callee &&
babel.types.isIdentifier(path.node.callee.object, { name: "console" })
) {
path.remove();
}
},
},
};
};
如图的babel.type是核心插件@babel/core提供的,他会把 @babel/parser @babel/traverse @babel/generator @babel/types 集成在一起
依赖如下
"dependencies": {
"@ampproject/remapping": "^2.1.0",
"@babel/code-frame": "^7.18.6",
"@babel/generator": "^7.20.5",
"@babel/helper-compilation-targets": "^7.20.0",
"@babel/helper-module-transforms": "^7.20.2",
"@babel/helpers": "^7.20.5",
"@babel/parser": "^7.20.5",
"@babel/template": "^7.18.10",
"@babel/traverse": "^7.20.5",
"@babel/types": "^7.20.5",
"convert-source-map": "^1.7.0",
"debug": "^4.1.0",
"gensync": "^1.0.0-beta.2",
"json5": "^2.2.1",
"semver": "^6.3.0"
},
"deprecated": false,
"description": "Babel compiler core.",
"devDependencies": {
"@babel/helper-transform-fixture-test-runner": "^7.19.4",
"@babel/plugin-syntax-flow": "^7.18.6",
"@babel/plugin-transform-flow-strip-types": "^7.19.0",
"@babel/plugin-transform-modules-commonjs": "^7.19.6",
"@babel/preset-env": "^7.20.2",
"@jridgewell/trace-mapping": "^0.3.8",
"@types/convert-source-map": "^1.5.1",
"@types/debug": "^4.1.0",
"@types/gensync": "^1.0.0",
"@types/resolve": "^1.3.2",
"@types/semver": "^5.4.0",
"rimraf": "^3.0.0"
},
现在流行的vite 或者说 很多cli 都是基于Babel Babel 基于webpack 或者 rollup 提供了自己的拓展,方便他们使用,然后这个核心插件会默认开启读取.babelrc文件里的presets plugins
.babelrc文件内容如下
{
"presets": ["@babel/preset-env"],
"plugins": ["./my-babel-plugin/index.js", "./my-babel-plugin/console.js"]
}
index.js内容如下
module.exports = function (babel) {
return {
visitor: {
Identifier(path) {
console.log(path.type, path.node.name);
},
},
};
};
babel处理ast的过程中我们可以使用它规定的插件规范,提供一些自定义的功能,来使用。
babel插件的规范,
如下所示
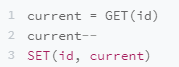
const obj = babel.transformFileSync(file, {
// babelrc: true,
plugins: [
function MyPlugin(babel) {
return {
visitor: {
Identifier(path) {
console.log(path.type, path.node.name);
},
},
};
},
],
presets: [function text() {}],
});
babel形参是babel-type提供的 path的在读取到对应ast时候触发的函数 path会获取到对应的当前代码内容对象,然后结合babel-type来验证ast类型 就可以改变当前代码的内容从而变成自己需要的返回结果。
可以创建vscode调试文件 来debug结果内容 方便我们开发独立的插件,
babel还提供了插件单元测试 这个可以自行了解。
基于Babel部分的使用是完全融入了webpack你到处可以看见他的身影,就不过多讨论。
webpack 构建 了cli
vite又是怎么构建的 集成了rollup rollup使用了Babel版的rollup 然后还有esbuild 字符串级别操作打包依赖工具,服务还是node。
rollup是用来发布工具库使用的,比如某一个插件js,然后打包各种兼容版本的脚本,比如umd 形式。
可以运行于import 浏览器 引入,如果注意区别了 node环境 那也可以使用 ,因为node目前支持了import。
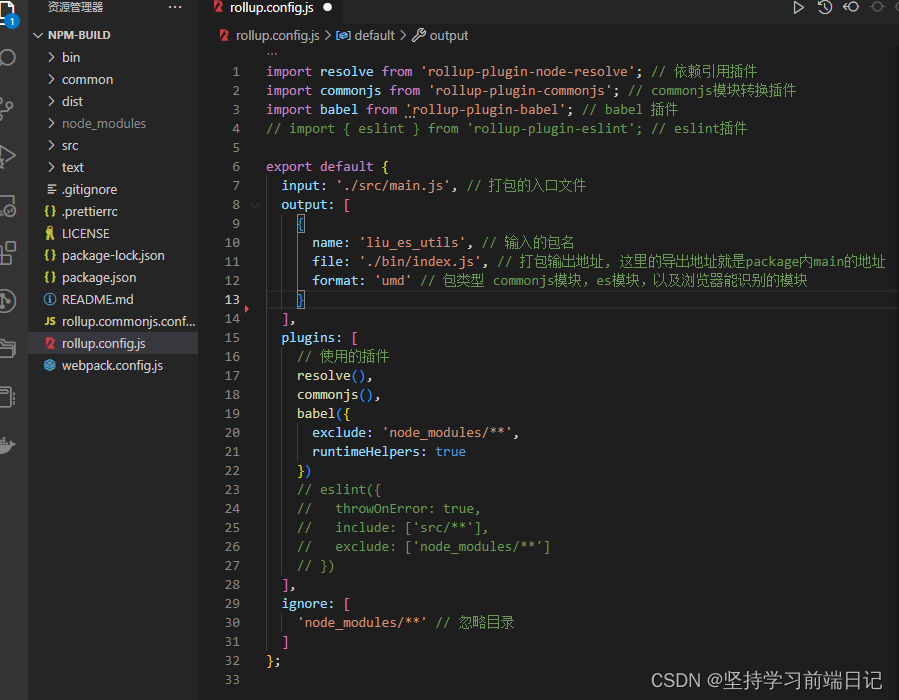
webpack其实也可以完成如上打包发布更加可以使用babel来兼容es5,
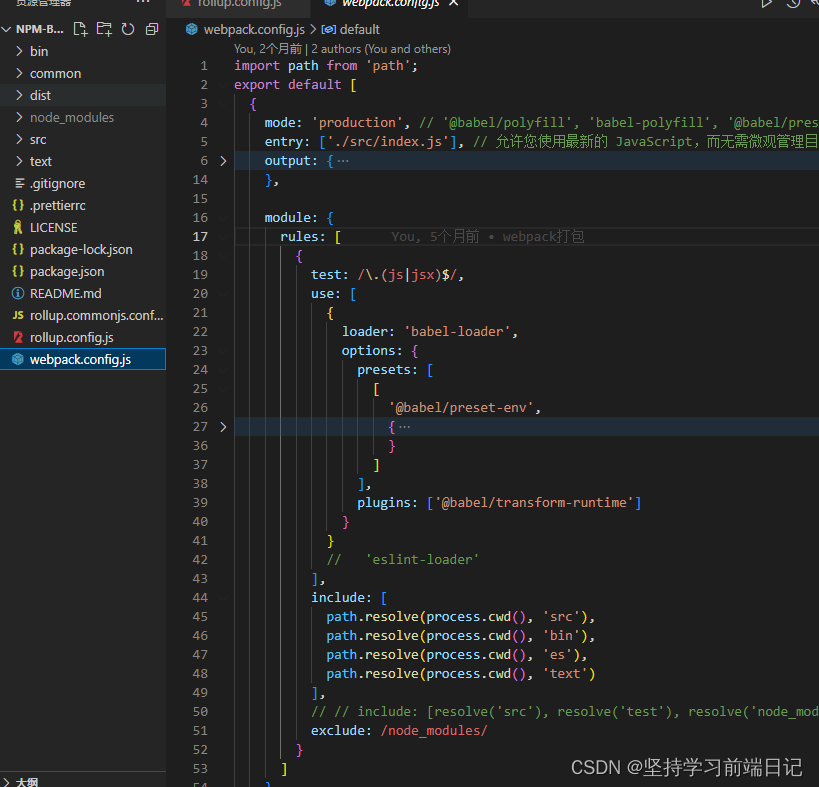
两种操作如上图。
处理了js写法,之后启动的服务和public资源用是怎么回事了?
关于cli启动服务和资源运行
在使用的过程中,我们不知道有没有关注执行了vue-cli serve 端口就起了 然后页面也有了,
然后热更新也存在了。
让我们一步步来解释,
基于webpack的配置 首先我们肯定知道 要让命令生效 肯定是离不开node 所谓一个命令必然是执行的一个文件。
- vite里是起了一个net http 端口 然后结合请求与资源响应
来生成页面,比如默认很快就起来了,因为他是通过请求发送再解析文件,比如 xxx/ 根地址输入 会处理对应的路径 然后使用HTML模板
把入口文件的js执行 然后触发各种请求 然后返回js脚本 来形成单页面内容,也就是后端的node
有一个机制,对应模块变成了对应请求,各种小模块变成了整合大模块的依赖,比如lodash
依靠esbuild预编译处理打包依赖,方便后续使用直接读取,也为了保证路径的正确,重写了资源路径 设置了node module的别名。
至于他的热更新,也是自己通过实现自己的socket与页面通信脚本,每次更新就有一个新的hash产生然后响应给到浏览器页面
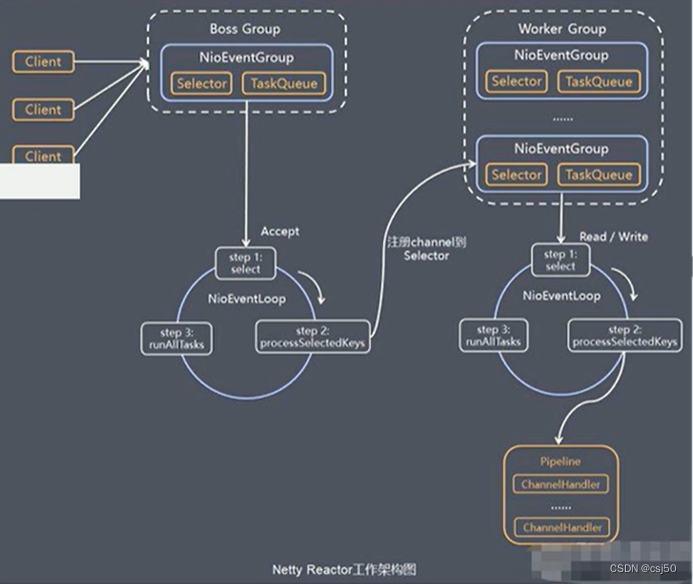
重新响应注入脚本; - webpack是使用node服务一样的 你可以选择使用net http 也可以使用成熟的koa express 来处理资源,
因为单页面的路由处理需要变成了 history的时候就需要这些服务框架来配合,
使用不同的综合性工具开发思路与注意的地方是不同的,比如个性化都会提供一些内置的操作和指令来帮助我们使用。
比如webpack的插件和预编译是自己提供的 根据自己内置的taptable来发出钩子函数来运行。
vite是集成了rollup插件然后融入了自己的一部分,父类是继承rollup 所以学vite
必了解rollup,至于esbuild只在启动的时候发挥作用,打包部署运行编译还是rollup提高。 - 很多框架不同文件后缀都是得益于操作各种文件里的字符串。使用各种手段来完成对应的转化js植入。
这是工程化发展到今天我们要做的思考和准备,这一切的根据是node与ast规范 做为根本,这些东西涉及了js引擎 比如v8
执行的过程,是如何把js处理成ast树,如何通过把ast树编译成最终机器语言认识的东西,在编译的过程里,为了符合规范,提出了各种概念,比如原型,全局变量,作用域,函数,变量类型,各种操作符,这些都是v8处理后
为了我们方便书写
提出了概念,所以深入的走下去,热爱的人必然会揭开它的神秘面纱,从而使js更进一步,在各种字符串的处理中,为了方便我们需要学各种正则,如何存的更优雅,需要具备完善的数据结构知识,学习算法来帮助我们更加了解前人之伟大。
大家输写的变量如何存如何回收,如何处理,如何让函数执行提升,如何让请求发送,如何渲染页面,如何使动画更优化,如何让加载更快,如何让缓存利用起来,如何让我们的项目成为自己的艺术品,如何将js的生态和前沿的东西使用到项目里,这些思考我想回填满作为年轻人的努力青春吧,
付出多少获取多少,代码就是这样,大家分享这些。
前端未来会怎么样
大家目前涉及了pc端网页 移动端网页 客户端应用 手机app 甚至还有一些web3的技术比如区块,数字孪生,虚拟现实,3D地球,二维地图,三维地图,甚至现在的各种动画三D引擎,webgl,可以说方向众多,但我们的精力是有限的,公司是有业务范围的,所以在熟悉公司开发项目的任务,空闲时间可以学一些其他方向 给自己未来提前打好基础,比如混迹各种群来帮助你我认识流行社区的大佬。
有人说前端是不是要学后端,我只能说curd的操作你用不了一年两年就熟练,但人生有几十年,所以不能将一两年的东西使用好多年吧,在这些时间里必然要为了未知做出探索,涉及后端数据库,安全,服务器,客户端,应用,有人会问这些学的玩吗,我说肯定学不完,那为啥要卷,因为为了填满年轻时候空闲的时间,顺手学点东西,然后提高自己的见识,毕竟如此人生,学也是一辈子,不学也是一辈子,有人忙忙碌碌,就活了前二十年,有人一直坚持学习,活了后面几十年,发光发热,所以我们必然要努力的前进。








![[附源码]Node.js计算机毕业设计出版社样书申请管理系统Express](https://img-blog.csdnimg.cn/b2c20e3b49834374bc52d22ec65035ee.png)