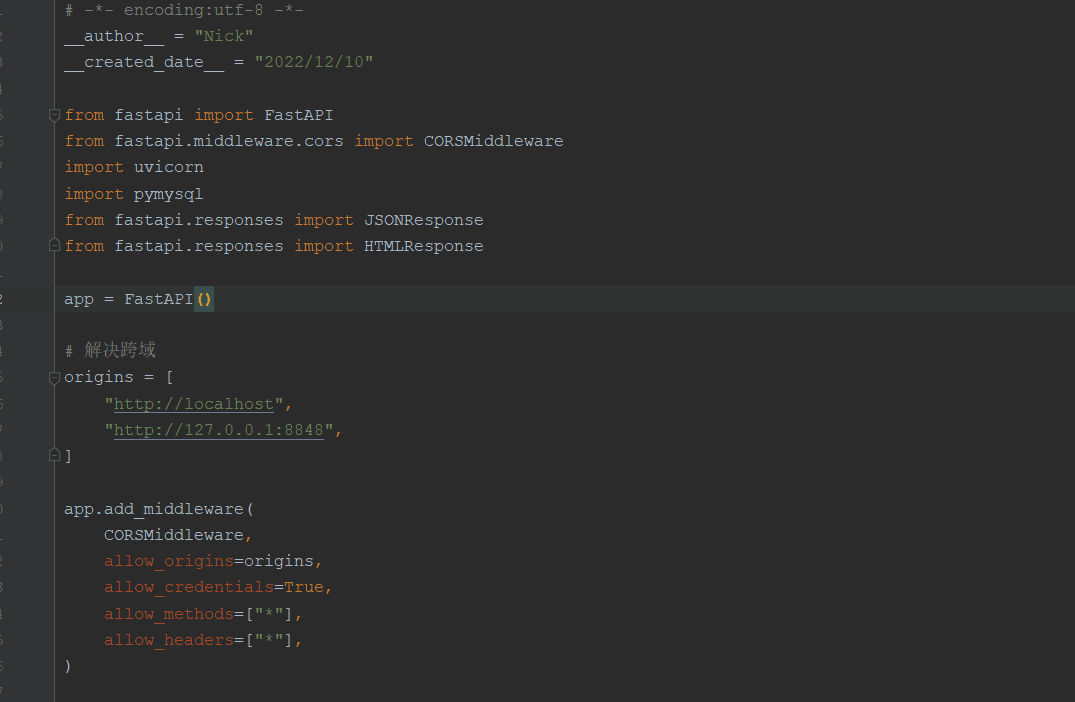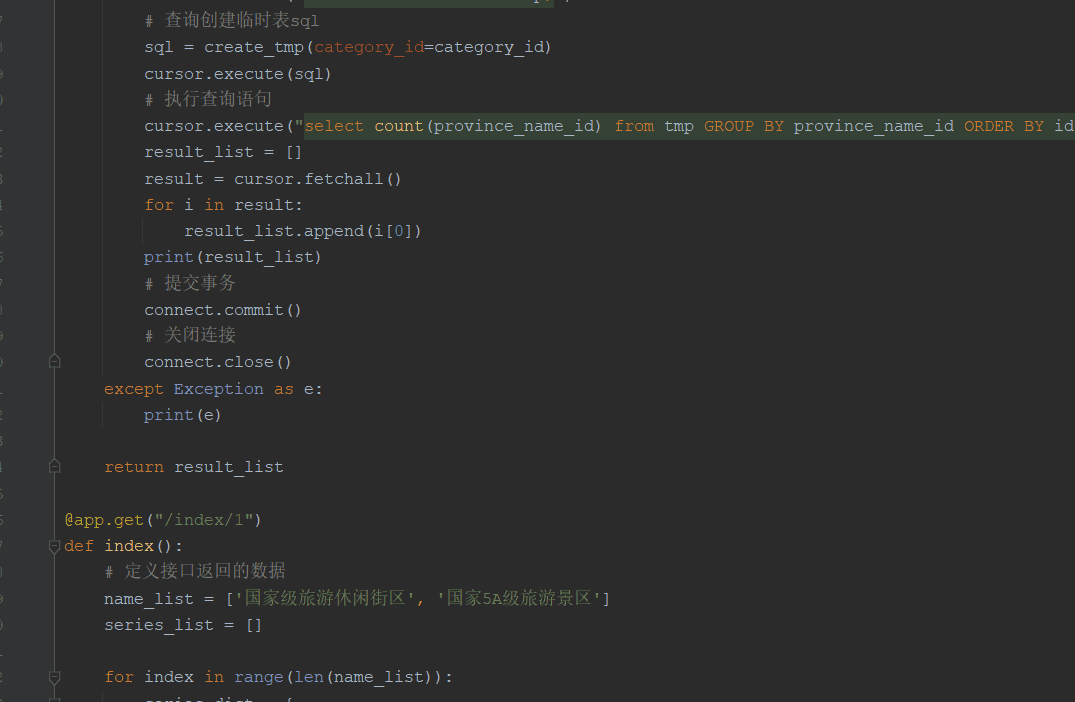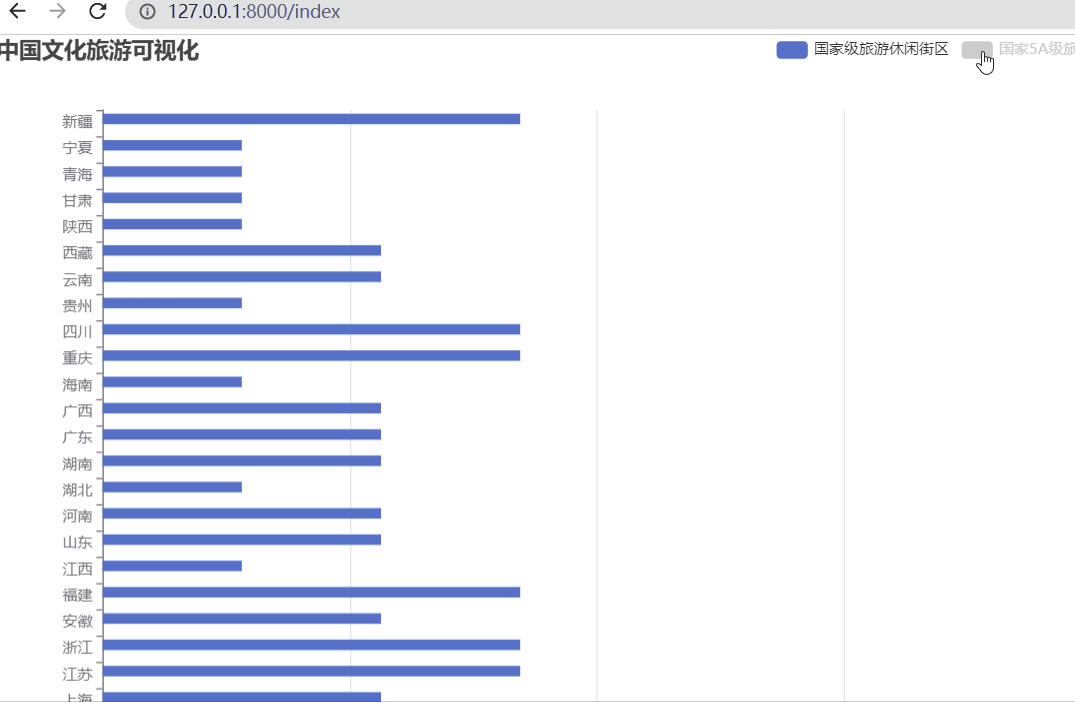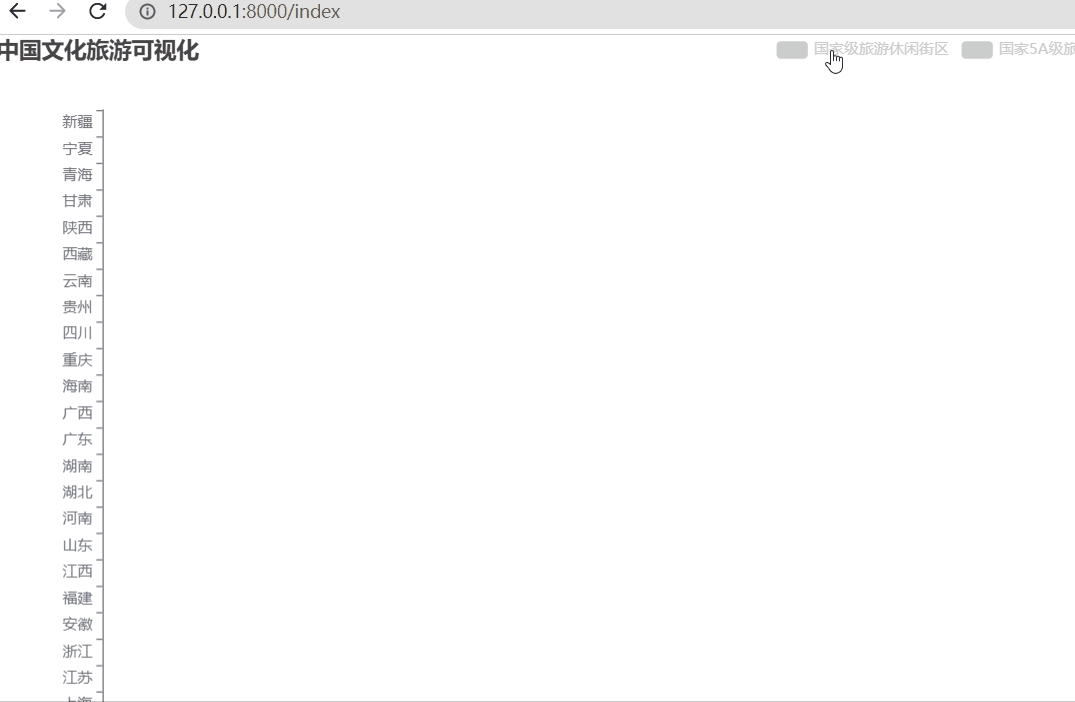
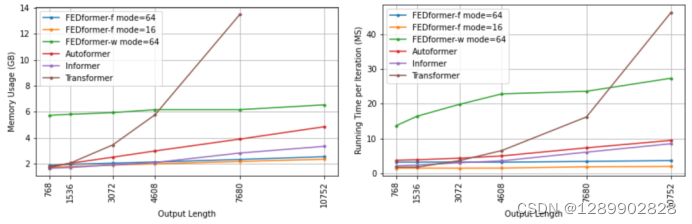
为什么需要写时拷贝呢?
当 shell执行指令的时候会 fork(),而这个 fork()出来的进程首先会调用的就是 exec来执行对应的命令,如果我们将 fork()创建的进程对地址空间进行了完整的拷贝,那将是一个巨大的消耗
因为在实际应用中,fork()拷贝的大部分内存都是不会用到的,最典型的就是在UNIX系统中,通常调用 fork()后便会调用 exec(),而 exec()做的第一件事就是把原来的地址空间给舍弃掉,那么原来拷贝过来的数据就全没用了
所以这个时候就需要copy-on-write机制
- 这是一个系统级别的优化
- 对于从
fork()->exec()的执行模式是一个很好的优化- 避免
fork()会把父进程的进程地址空间进行完全的拷贝 - 解决因为
exec()把拷贝完的地址空间给舍弃,而造成我们无效的操作
- 避免
- 可以极大的减少拷贝
- 对于特定的页使用极少的内存就可以维护
page fault的执行流程
page fault的执行流程和系统调用类似,同样是需要从用户态进入到内核态,并在usertrap中判断是什么原因导致的进入内核,
后执行对应的page fault处理方法,执行完再返回回到用户态,继续原来的操作
我们可以通过scause的值来判断是否为page fault导致的
从图中可知,scause=12,13,15的时候分别是instruction page fault,load page fault,store page fault
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xsULkO3b-1670655836900)(https://cdn.jsdelivr.net/gh/zevin02/picb@master/imgss/20221209190124.png)]](https://img-blog.csdnimg.cn/3f5070a60f4c48b99b920f7738889b96.png)
Copy-On-Write处理方法
- fork之后,让子进程和父进程共享物理内存page,同时将对应的page设置为COW page
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XzgtMaqw-1670655836901)(https://cdn.jsdelivr.net/gh/zevin02/picb@master/imgss/20221210145755.png)]](https://img-blog.csdnimg.cn/3b7b1cf922934decbd87f4a751904492.png)
- 当我们需要修改某个进程对应的内存的时候,就会触发page fault
- page fault 处理方法
- 对于由于COW而导致的page fault的page 需要为其分配一个新的物理page
- 将其和父进程共享的page内容拷贝到新的page中
- 把新page的PTE标记为RW,取消COW
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p3cnstsA-1670655836902)(https://cdn.jsdelivr.net/gh/zevin02/picb@master/imgss/20221210145847.png)]](https://img-blog.csdnimg.cn/3a721dc74439454cac5cf67f26f31722.png)
PTE
在RISC-V中的PTE,第8,9位是给supervisor保留的,按需自由设置,所以我们可以选取其中的一个位设置为COW的标志位
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kxNNIHV6-1670655836902)(https://cdn.jsdelivr.net/gh/zevin02/picb@master/imgss/20221210145939.png)]](https://img-blog.csdnimg.cn/c2bceea76d894e4b84cd890c35c34fcc.png)
我们可以使用PTE中的RSW bit来标记PTE为COW page
我们可以定义PTE_COW=1<<8
引用计数
Copy-On-Write是推迟为子进程开辟物理内存,最大程度减少拷贝的一个机制
一个物理页可能被多个进程所引用,为了能够使某个物理内存能够被释放,就需要对每个物理页都添加一个引用计数,表示有多少个进程引用了该物理页,直到该物理页的引用计数为0的时候,该物理页才能够被释放
在开辟物理页的时候,将其引用计数设置为1,当 fork()子进程的时候,增加引用计数,触发 page fault将对应的引用计数减1
虚拟地址空间
进程地址空间
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TXB7578T-1670655836903)(https://cdn.jsdelivr.net/gh/zevin02/picb@master/imgss/20221210150015.png)]](https://img-blog.csdnimg.cn/f556dfe7567b491ca2112f312f877069.png)
子进程拷贝完父进程的页表之后,将每个页的PTE都设置清空 PTE_W,设置 PTE_COW
而对于上述的操作,会影响text
区,这一段也并没有 PTE_W,如果我们对其进行 COW操作就会出现问题
因为用户虚拟地址中的 text区是保存存储代码的,这块的虚拟地址不能发生COW,所以对于 va<PGSIZE,我们就需要直接拦截
核心代码
设置COW 标志位
#define PTE_V (1L << 0) // valid
#define PTE_R (1L << 1)
#define PTE_W (1L << 2)
#define PTE_X (1L << 3)
#define PTE_U (1L << 4) // user can access
#define PTE_COW (1L << 8) //判断COW page
修改fork的处理机制,修改 uvmcopy,使得fork的子进程印射到父进程的地址空间
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)//将两个pagetable进行复制,两个不同的进程虚拟地址相同映射到页表的相同位置
{
pte_t *pte;
uint64 pa, i;
uint flags;
// char *mem;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
*pte&=(~PTE_W);//把w权限给取消掉
*pte|=PTE_COW;//设置为cow页,这个操作并不会影响其父进程
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
// if((mem = kalloc()) == 0)
// goto err;
// memmove(mem, (char*)pa, PGSIZE);
if(mappages(new, i, PGSIZE, pa, flags) != 0){
// kfree((void*)pa);//减少引用计数
goto err;
}
else
{
refadd(pa);//添加引用计数
}
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}
修改 usertrap对 page fault进行识别与处理
void usertrap(void)
{
int which_dev = 0;
if ((r_sstatus() & SSTATUS_SPP) != 0)
panic("usertrap: not from user mode");
// send interrupts and exceptions to kerneltrap(),
// since we're now in the kernel.
w_stvec((uint64)kernelvec);
struct proc *p = myproc();
// save user program counter.
p->trapframe->epc = r_sepc();
……………//省略
//-------->begin
else if (r_scause() == 15 || r_scause() == 13||r_scause()==12))
{
uint64 va = r_stval(); // 获得错误的虚拟地址
if (va < PGSIZE)//解决segment fault,这些va小于pgsize都是在text区
{
p->killed = 1;
}
else
{
// va=PGROUNDDOWN(va);//16进制向下取整
if (va < p->sz && iscow(p->pagetable, va)) // 是因为cow引起的page fault
{
if (cowalloc(p->pagetable, PGROUNDDOWN(va)) == 0) // 为新的页表分配内存
{
p->killed = 1;
}
}
else
{
p->killed = 1;
}
}
}
//------->end
…………//省略
usertrapret();
}
标识COW page
int iscow(pagetable_t pagetable, uint64 va)
{
if (va >= MAXVA)
return 0;
pte_t *pte = walk(pagetable, va, 0);
if (pte == 0)
return 0;
if ((*pte & PTE_V) == 0)
return 0;
if ((*pte & PTE_U) == 0)
return 0;
if (*pte & PTE_COW)
return 1;
else
return 0;
}
对产生 page fault的 va进行分配物理页
int cowalloc(pagetable_t pagetable, uint64 va) //为page fault的虚拟地址进行拷贝新的物理地址,内容从父进程里面全部拷贝过来
{
if (va >= MAXVA)
return 0;
pte_t *pte = walk(pagetable, va, 0);
if (pte == 0)
return 0;
if ((*pte & PTE_V) == 0)
return 0;
if ((*pte & PTE_U) == 0)
return 0;
//这个函数就是用来进行分配物理空间的
uint64 pa = PTE2PA(*pte);
if (((uint64)pa % PGSIZE) != 0 || (char *)pa < end || (uint64)pa >= PHYSTOP) //所有的物理地址大小都是4096字节,对齐,end是内核物理地址的最底段,PHYSTOP是内核物理地址的最顶端
panic("cowalloc");
if (ref.refcnt[(uint64)pa / PGSIZE] == 1)//引用计数为1的话,就说明已经没有人使用该page了,就可以直接使用了
{
*pte |= PTE_W;
*pte &= ~PTE_COW;
return 1;
}
else
{
uint64 ka = (uint64)kalloc(); //引用计数初始化
if (ka == 0) //物理内存已经满了,这里我们采取简单的方法,直接将这个进程给杀掉,但是实际上在课上讲过,可以使用LRU的方法,把最近一直没有使用的页表给释放出来,然后新的进程去使用这个页表,可以提高效率
{
return 0;
}
memmove((void *)ka, (void *)pa, PGSIZE); //把他原来对应物理内存的地址进行拷贝过来,都是4096字节
*pte &= (~PTE_COW); //取消他的cow标志位
*pte |= PTE_W; //添加写权限
*pte&=(~PTE_V);
uint flag = PTE_FLAGS(*pte);
// uvmunmap(pagetable, va, 1, 1); //这个地方因为是取消映射,也就是之前映射对应的物理地址对应的引用计数要减1
if (mappages(pagetable, va, PGSIZE, ka, flag) != 0) //进行新的映射
{
//映射失败,同时页需要减少引用计数
kfree((void *)ka);
*pte|=(PTE_V);//添加这个有效的标志位
// uvmunmap(pagetable, va, 1, 1);
return 0;
}
kfree((void*)PGROUNDDOWN(pa));
return 1;
}
修改 copyout,有些COW页操作不是来自用户空间而是来自内核空间,因为 copyout是从内核态拷贝到用户态,是会对用户页产生写操作,而内核进程不会触发 usertrap,所以我们需要进行对其进行处理
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
while(len > 0){
va0 = PGROUNDDOWN(dstva);
if(iscow(pagetable,va0))//每次都需要对这个va进行判断是否为cow page
{
if(cowalloc(pagetable,va0)==0)
{
return -1;
}
}
...//省略
}
return 0;
}
添加引用计数的结构体
每个页的起始地址都是4096对齐,所以都是可以被4096整除
这里的 KERNBASE和 PHYSTOP代表这内存物理地址的起始和结束,而 end是 Free memory的起始地址,这个 end是动态变化的,内核自己的代码和数据都是存在 kernel text和 kernel data中,所以这个结构体是存在 kernel data中
struct
{
struct spinlock lock;
int refcnt[PHYSTOP / PGSIZE];//每个物理地址都是PGSIZE对齐
} ref;
修改 kinit,初始化ref结构体,kalloc只会分配 end~PHYSTOP间的内存,所以我们使用的物理内存都在这个范围内
void kinit()
{
initlock(&kmem.lock, "kmem");
initlock(&ref.lock, "ref");
freerange(end, (void *)PHYSTOP);
}
修改 freerange,初始化空闲内存
void freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char *)PGROUNDUP((uint64)pa_start);
for (; p + PGSIZE <= (char *)pa_end; p += PGSIZE)
{
ref.refcnt[(uint64)p / PGSIZE] = 1; //因为下面调用kfree要把每个物理地址上的引用计数都减少1,为0才能够释放空间,所以这里我们先给每个初始化成1,保证能够释放空间成功
kfree(p);
}
}
修改 kalloc,初始化引用计数
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if (r)
{
kmem.freelist = r->next;
acquire(&ref.lock);
ref.refcnt[(uint64)r / PGSIZE] = 1;
release(&ref.lock);
}
release(&kmem.lock);
if (r)
memset((char *)r, 5, PGSIZE); // fill with junk
return (void *)r;
}
修改 kfree,减少引用计数,直到引用计数为0时,才能把该物理页释放
void kfree(void *pa)
{
if (((uint64)pa % PGSIZE) != 0 || (char *)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
struct run *r;
acquire(&ref.lock);
--ref.refcnt[(uint64)pa / PGSIZE];
// release(&ref.lock);
// Fill with junk to catch dangling refs.
if (ref.refcnt[(uint64)pa / PGSIZE] == 0)
{
release(&ref.lock);
memset(pa, 1, PGSIZE); //当引用计数为0的时候,才把这个空间释放,同时添加到空闲链表里面
r = (struct run *)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
else
{
release(&ref.lock);
}
}
增加引用计数
void refadd(uint64 pa) //添加引用计数
{
if (((uint64)pa % PGSIZE) != 0 || (char *)pa < end || (uint64)pa >= PHYSTOP)
panic("refadd");
acquire(&ref.lock); //添加的时候要上锁,避免出现多线程同时操作同一个数的情况
ref.refcnt[pa / PGSIZE]++;
release(&ref.lock);
}