开源大模型对闭源大模型的冲击,变得非常猛烈。
今年3月,Meta发布了Llama(羊驼),很快成为AI社区内最强大的开源大模型,也是许多模型的基座模型。有人戏称,当前的大模型集群,就是一堆各种花色的“羊驼”。
而就在前些天,Meta又推出了免费可商用版本的“羊驼2号”——Llama2,据说性能比肩GPT-3.5。

这在整个大模型圈都是非常炸裂的。
我们知道,各个互联网、科技公司都在竞相训练、推出自己的大模型,投入了大量的计算资源和成本,如果不能有效的完成商业化,那么这些大模型就很难回收成本,后续的迭代、更新、升级都成问题,不仅研发企业会亏个底掉,更苦恼的大概就是“前功尽弃”的用户了。
而现在有了自由开放强大的开源大模型,谁还愿意给闭源大模型送钱呢?
还真的有。
开源是大势所趋,但闭源大模型依然有其存在意义和商业价值。按照目前的AI产业落地经验来看,用好大模型,还是得靠闭源。
今天我们就来聊聊这个问题,到底是谁,需要闭源大模型?
到产业去,到产业去
大模型的商业化终点是产业,想必已经是不用过多解释的共识了。
前不久,我参加某一个国产大模型的内部沟通会,对方高层就明确表示,自己全部用的是闭源代码,并且坚持走闭源路线,就是考虑到训练大模型与行业伙伴合作,其中很多隐私数据是不方便开源的。
见一斑可窥全豹,至少在短期内,大模型走向产业,落地还是要靠闭源。
模型方面,闭源大模型的质量更高。
就拿目前最能打的Llama 2为例,Meta 将 Llama 2 70B 的结果,与闭源模型进行了比较,结果在 MMLU 和 GSM8K 上接近 GPT-3.5,但在编码基准上,还存在显著差距,不少数据在多样性和质量方面有所欠缺。
当然,开源大模型的优化迭代速度很快。但开源的本质和“有性繁殖”很像,就是通过大量繁殖和变异,如同开篇那张“羊驼集群”一样,面对不确定的未来,借助进化的“优胜劣汰”,让最优质的后代持续涌现。所以,开源软件的分支多,对用户来说,这个选择的成本是很高的,加上开发人员众多,版本控制是一个问题。
安全性方面,闭源大模型的可靠性更高。
开源大模型要遵守开源协议,商业使用需要获得授权,海外开源大模型也要受到属地管辖,github就曾封禁俄罗斯开发者账号。使用海外开源大模型开发产品,供应链的风险,是客观存在的。
那么,使用国产开源大模型呢?安全性得到保障,但从商业角度看,很多客户,如大型政企,也非常看重大模型在业务上的可靠性,采购时往往需要大公司的品牌背书。一方面研发投入更大,口碑更高;另一方面,万一大模型生成不当,导致商业损失或商誉问题,使用闭源大模型可以问责服务商,使用开源大模型总不能找全球开发者算账吧?
比如大模型创业公司Huging Face,为客户提供AI咨询,是开源社区的台柱子,表示有大量客户希望把自己的私有数据/专业数据用来训模型,并不想把这些数据给到 OpenAl。

产业化方面,闭源大模型的长期服务能力更强、更可用。
大模型落地,并不是接入API、塞进数据、调参优化就结束了。作为一种新兴技术,大模型与业务场景的融合,还有非常多挑战。比如大模型需要通过蒸馏压缩,减小模型规模,才能在端侧部署,很多企业根本没有这类专业人才。
再比如,大模型与业务结合,需要产品、运营、测试工程师等多种角色共同参与,这些服务能力是以coder为主的开源团队,所很难提供的。此外,大模型的长期应用,算力、存储、网络等配套都要跟上,开源社区无法帮助用户“一站式”解决这些细节问题。
还有数据隐私顾虑,大模型是不能直接为产业所用的,还要通过专有场景数据进行优化,而这些数据训练完的模型会被开源开放出去,让企业顾虑重重。
我们曾采访过一个智慧医疗研发团队,对方表示,大量医疗数据分布在各大医院、研究机构,又涉及患者隐私,大家对于把数据拿出来共同训练一个行业模型,都存在顾虑。一方面是安全得不到保障,另一方面是自己的数据质量高,但从中得不到恰当的回报,和其他数据质量低的机构一样,很难协调。在开源大模型的共建中,如何得到数据、把握配方、确定各方贡献,还存在很多难题。
开源大模型需要平衡技术创新自由和版权收益之间的冲突,而使用闭源大模型就没有这方面的麻烦,数据和模型的所有权、使用权都很清晰,牢牢掌握在企业自己手里。
可以说,目前开源大模型还无法达到实际的业务需求。而开源大模型使用者和ISV集成商,是需要获得商业回报的,如果开源大模型不可商用、效果不好、很难赚钱,那么即使免费,企业也会慎重考虑要不要投入人来开发。
所以,未来一段时间,闭源依然是大模型落地产业的热门选择。
到群众去,到群众去
可能有人不理解了,开源免费商用,大家都能用上白菜价的大模型了,对开发者和企业用户多友好,你怎么还说闭源好?是不是为一门心思赚钱的大厂站台?
非也。
但凡了解开源,都会支持开源。但凡支持开源,都会关注开源的商业化。
中国科学院梅宏院士曾说过,开源以理想主义为源起,以商业化为蓬勃助力,是开放创新的典范。没有商业化,不可能有开源。
所以,开源也好,闭源也好,谁能更早“可商用”,谁就更有未来。这一点上,闭源大模型可能更占优势,毕竟有底气闭源的厂商,还是有两把刷子和研发家底儿的。
那么,开源大模型的优势在哪里呢?如果说闭源大模型要到产业去,那么开源大模型就要到群众中去,主打一个人多力量大。

(LeCun认为Llama-v2会改变LLM的市场格局)
开源大模型不同于传统开源软件,把源代码放上去,然后全球开发者来贡献代码就完了。大模型的协同共建,更多体现在社区繁荣,大家一起把模型做优化、数据做丰富、工具做完善、应用做全面……
这时候,开源模式能够带来几个好处:
1.技术创新。开源社区可以汇聚广大科技企业、研究机构和开发者,对模型进行优化、改进、加速迭代,让模型技术和配套数据集、应用工具等,变得丰富、高质,从而保持领先。
2.人才争夺。大模型作为新兴技术,人才紧缺,通过开源社区吸引全球优秀人才做贡献,加速大模型升级,能够拉开差距。有竞争才有压力,所以LLama 2发布之后,很快传出OpenAI也开始考虑半年内开源GPT-3.5的消息,开发者们有福了。
3.生态合拢。目前各行各业的IT解决方案和数字化转型,大量使用开源技术和应用,建设大模型开源生态,让IT人才和企业使用相关技术,对于后期的商业化非常有帮助。比如OpenAI 的合作伙伴/投资方微软,这次也选择成为Llama 2 的首要合作伙伴,支持个人开发者和中小公司以最低成本调用Llama 2,这对azure无疑是一大利好。
不是所有开源大模型都能成功,生态是关键的护城河。
夹心饼干,向何处去?
就像手机操作系统的 iOS 与 Andriod,开源与闭源的竞争,并不是某一个领域打的“你死我活”,而是各自走出一条差异化的道路,迎来自己的天地。大模型也是如此。
闭源大模型开门迎客,开源大模型红红火火,大家都有光明的未来。
既然如此,为什么还有专家认为,Llama 2开源对开源来说是一个巨大的飞跃,但对闭源的大模型公司是一个巨大打击?
究竟打击了谁?
答案应该是,既不甘心只做应用层、又没能力卷过大厂的基础大模型厂商。
谷歌研究人员曾发文说,因为有开源社区,我们(Google和OpenAI)没有护城河。但是,OpenAI还有GPT-4这样的闭源大模型作为杀手锏,只有被开源逼急了的情况下,才考虑把GPT-3.5开源,这里面是有技术代差的。而且GPT-3.5开源只透露了口风,具体进展还是未知数。
所以,这类头部科技厂商和云巨头,如海外的谷歌、OpenAI,国内的BATH,卡、钱、人才、数据、市场认知度、客户基础都有优势,走闭源路线来完成大模型商业化、产业化是有一定先发优势和壁垒的。
这就苦了那些一心想训基础通用大模型的二三线厂商了。
此前,全球大小科技公司和各类科研机构,一拥而上训基础大模型,比如某些机器视觉AI独角兽,不小心就成了基础层和应用层之间的“夹心饼干”。
实力上打不过GPT,成本上打不过Llama,训出来的基础通用大模型,还没等到正式开放商用,就已经过时了,注定是明日黄花。市场上拼不过巨头,开放度不如开源社区,几乎不可能收回高昂的开发成本。
趁早放弃死磕大模型,或许才是明智选择。
比如国内某AI公司的大模型,此前私有化报价是一年30万,随后就宣布对学术研究完全开放,获得授权可免费商用。做大模型开源社区,也有商业化的可能(如Linux/ Android/红帽),同时也能避免跟头部的通用大模型的“硬碰硬”。
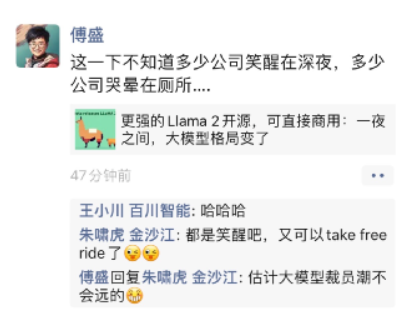
(知名投资人关于Llama2开源的讨论截图/来自网络)
对于应用层开发者和ISV集成商企业来说,用好产业接受度高的闭源大模型,可以更快让客户接受,更适合私有化定制部署的业务需求,更快完成商业落地和收入增长。
对于AI创业公司来说,开源直接就能用,避免重复造轮子,可能是更理想、低成本试错的商业化手段,“报团取暖”贡献大模型开源项目,推动大模型开源社区的发展,也会获得社区回馈和商业回馈。
中国大模型发展到高水平,既要有全球领先的闭源大模型打头阵,也要有具备世界影响力的大模型开源社区。
道阻且长,行则将至。不妨用建设性心态,来看待开源闭源之争,给国产闭源大模型一些信心,也给国內开源社区一些鼓励和支持。