柔性调度问题代码,DDQN求解FJSP问题
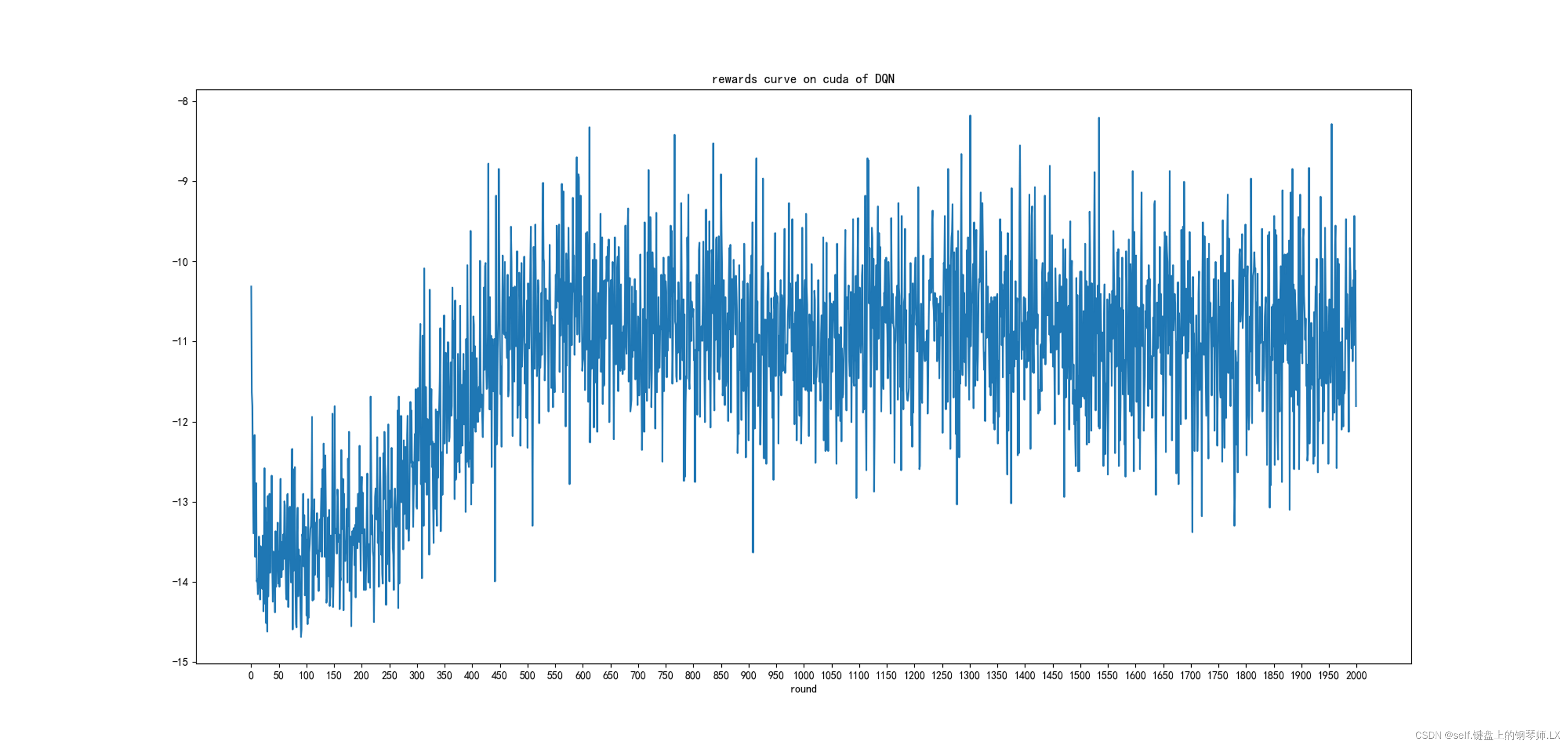
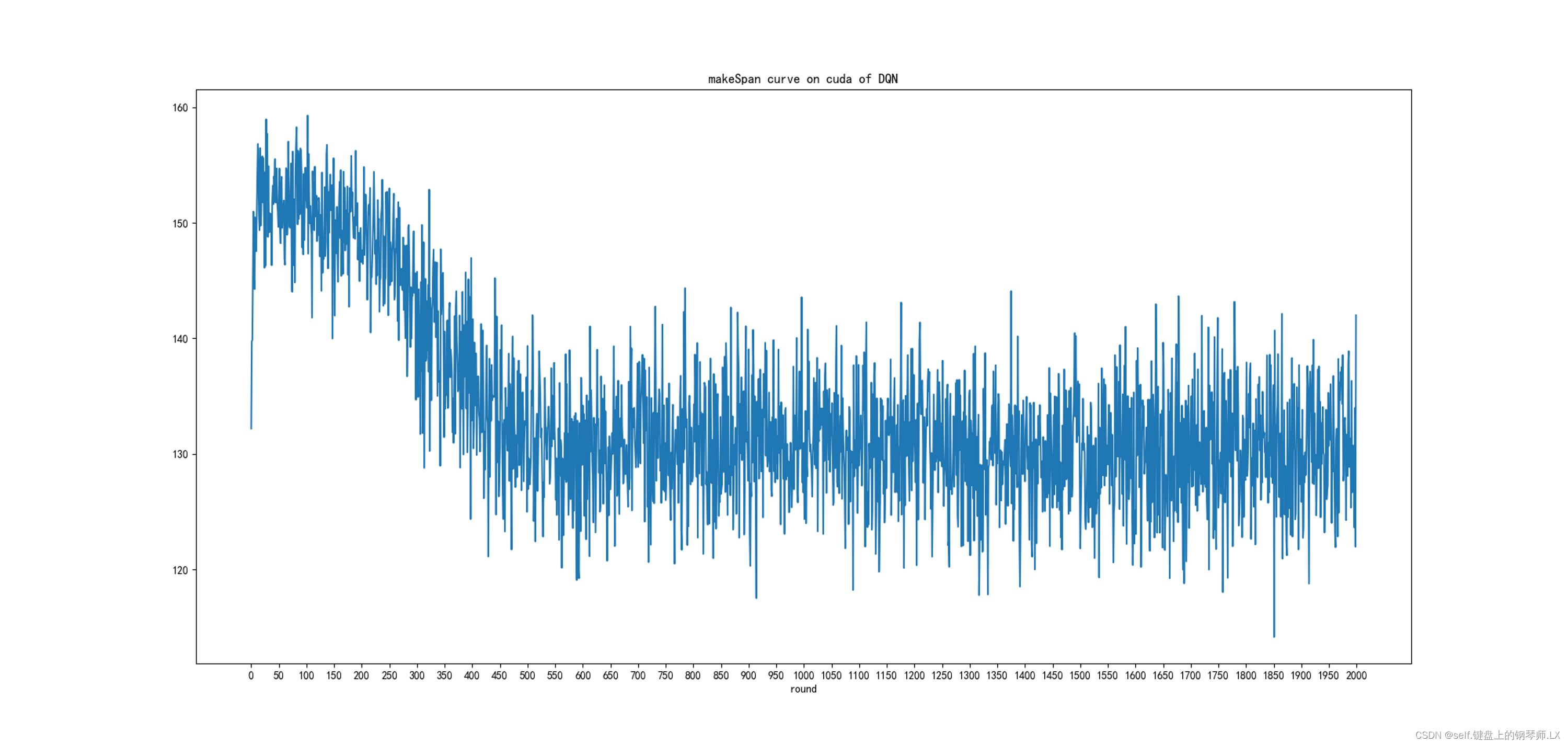
迭代曲线图
奖励函数迭代曲线
makespan迭代曲线
代码!!
全部见我的git仓库: DFJSP_Share
DDQN算法主体
import csv
import os
from environment2.Environment import Environment
import torch
from environment1.CompositeDispatchingRules import Composite_rules
from collections import namedtuple
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
from Gantt.gantt import Gantt2
from data.InstanceGenerator import Instance_Generator
import pandas as pd
import copy
import random
import numpy as np
from Drawline.draw import drawLine
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
NUM_EPISODES = 100
Transition = namedtuple('Transition', ('state', 'action', 'next_state', 'reward'))
np.random.seed(0)
torch.manual_seed(0)
torch.cuda.manual_seed_all(0)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
class ReplayMemory:
def __init__(self, CAPACITY):
self.capacity = CAPACITY
self.memory = []
self.index = 0
def push(self, state, action, state_next, reward):
'''transition = (state, action, state_next, reward)'''
if len(self.memory) < self.capacity:
self.memory.append(None)
self.memory[self.index] = Transition(state, action, state_next, reward)
self.index = (self.index + 1) % self.capacity
def sample(self, batch_size):
'''batch_size'''
return random.sample(self.memory, batch_size)
def __len__(self):
'''???memory?????'''
return len(self.memory)
class Net(nn.Module):
def __init__(self, input_dims, num_actions):
super(Net, self).__init__()
# self.chkpt_dir = chkpt_dir
# self.checkpoint_file = os.path.join(self.chkpt_dir, name)
self.fc1 = nn.Linear(input_dims, 30)
self.fc2 = nn.Linear(30, 30)
self.fc3 = nn.Linear(30, 30)
self.fc4 = nn.Linear(30, 30)
self.fc5 = nn.Linear(30, 30)
self.fc6 = nn.Linear(30, num_actions)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = F.relu(self.fc4(x))
x = F.relu(self.fc5(x))
output = self.fc6(x)
return output
class Brain:
def __init__(self, inputdims, num_actions, CAPACITY, learing_rate, BATCH_SIZE, GAMMA, e_greedy_increment):
self.num_actions = num_actions
self.memory = ReplayMemory(CAPACITY)
self.main_q_network = Net(inputdims, self.num_actions).to(device)
self.target_q_network = Net(inputdims, self.num_actions).to(device)
# print(self.main_q_network)
self.optimizer = optim.Adagrad(self.main_q_network.parameters(), lr=learing_rate)
self.loss_history = []
self.BatchSize = BATCH_SIZE
self.gamma = GAMMA
self.epsilon = 0.5 if e_greedy_increment is not None else 0.1
self.e_greedy_increment = e_greedy_increment
def replay(self, step):
'''Experience Replay'''
if len(self.memory) < self.BatchSize:
return
self.batch, self.state_batch, self.action_batch, self.reward_batch, self.non_final_next_states = self.make_minibatch()
self.expected_state_action_values = self.get_expected_state_action_values()
self.update_main_q_network()
if step % 500:
self.update_target_q_network()
def decide_action(self, state):
# epsilon = 0.5 * (1 / (episode + 1))
# epsilon = (1 / episode) if episode > 0.1 else 0.1
self.epsilon = self.epsilon - self.e_greedy_increment if self.epsilon > 0.1 else 0.1
if self.epsilon <= np.random.uniform(0, 1):
self.main_q_network.eval().to(device)
# with torch.no_grad():
action = self.main_q_network(state).max(1)[1].view(1, 1).to(device)
else:
action = torch.LongTensor([[random.randrange(self.num_actions)]]).to(device)
return action
def make_minibatch(self):
transitions = self.memory.sample(self.BatchSize)
batch = Transition(*zip(*transitions))
state_batch = torch.cat(batch.state)
action_batch = torch.cat(batch.action)
reward_batch = torch.cat(batch.reward)
non_final_next_states = torch.cat([s for s in batch.next_state
if s is not None])
return batch, state_batch, action_batch, reward_batch, non_final_next_states
def get_expected_state_action_values(self):
self.main_q_network.eval()
self.target_q_network.eval()
self.state_action_values = self.main_q_network(self.state_batch).gather(1, self.action_batch)
non_final_mask = torch.ByteTensor(tuple(map(lambda s: s is not None, self.batch.next_state))).bool().to(device)
next_state_values = torch.zeros(self.BatchSize).to(device)
a_m = torch.zeros(self.BatchSize).type(torch.LongTensor).to(device)
a_m[non_final_mask] = self.main_q_network(self.non_final_next_states).detach().max(1)[1]
a_m_non_final_next_states = a_m[non_final_mask].view(-1, 1)
next_state_values[non_final_mask] = self.target_q_network(self.non_final_next_states).gather(1, a_m_non_final_next_states).detach().squeeze()
expected_state_action_values = self.reward_batch + self.gamma * next_state_values
return expected_state_action_values
def update_main_q_network(self):
self.main_q_network.train()
loss = F.mse_loss(self.state_action_values.float(), self.expected_state_action_values.unsqueeze(1).float())
self.loss_history.append(loss.item())
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def update_target_q_network(self):
'''Target Q-Network??Main???'''
self.target_q_network.load_state_dict(self.main_q_network.state_dict()) # 这种方式的加载模型是不需要存储模型的
# self.target_q_network.load_checkpoint()
class Agent:
def __init__(self, inputdims, num_actions, CAPACITY, learing_rate, BATCH_SIZE, GAMMA, e_greedy_increment):
self.brain = Brain(inputdims, num_actions, CAPACITY, learing_rate, BATCH_SIZE, GAMMA, e_greedy_increment)
def update_q_function(self, step):
self.brain.replay(step)
def get_action(self, state, episode):
action = self.brain.decide_action(state)
return action
def memorize(self, state, action, state_next, reward):
self.brain.memory.push(state, action, state_next, reward)
def update_target_q_function(self):
self.brain.update_target_q_network()
class DDQN_main:
def __init__(self, Capacity, Learning_rate, Batch_size, GAMMA, e_greedy_increment=0.0001, input_dims=7, num_actions=6):
ProcessTime, A1, D1, M_num, Oij_list, Oij_dict, O_num, J_num = Instance_Generator(Initial_Job_num=2, M_num=4,
E_ave=50, New_inset=3, DDT=0.5)
self.env = Environment(J_num, M_num, O_num, ProcessTime, Oij_list, Oij_dict, D1, A1)
self.num_actions = num_actions
self.NUM_EPISODES = NUM_EPISODES
self.Capacity = Capacity
self.Batch_size = Batch_size
self.GAMMA = GAMMA
self.Learning_rate = Learning_rate
self.input_dims = input_dims
self.agent = Agent(inputdims=self.input_dims, num_actions=self.num_actions, learing_rate=self.Learning_rate,
CAPACITY=self.Capacity, BATCH_SIZE=self.Batch_size, GAMMA=self.GAMMA, e_greedy_increment=e_greedy_increment)
def run(self, times=0):
step = 0
episode_reward, makespan_history = [], []
save_param = float('inf')
for episode in range(NUM_EPISODES):
ProcessTime, A1, D1, M_num, Oij_list, Oij_dict, O_num, J_num = Instance_Generator(Initial_Job_num=2,
M_num=4,
E_ave=50,
New_inset=3,
DDT=0.5)
self.env = Environment(J_num, M_num, O_num, ProcessTime, Oij_list, Oij_dict, D1, A1)
time_collect = []
state, done = self.env.reset()
state = torch.from_numpy(state).type(torch.FloatTensor).to(device)
state = torch.unsqueeze(state, 0).to(device)
reward_sum = 0
done_collect, a_collect, start_end_collect = [], [], []
while not done:
action = self.agent.get_action(state, episode)
# for a in action:
a = Composite_rules(action.item(), self.env)
state_next, reward, done, start_to_end_list = self.env.step(a)
reward_sum += reward
state_next = torch.from_numpy(state_next).type(torch.FloatTensor).to(device)
state_next = torch.unsqueeze(state_next, 0).to(device)
# reward = torch.FloatTensor([0.0]).to(device)
reward = torch.as_tensor(reward)
reward = torch.unsqueeze(reward, 0).to(device)
# state, action, state_next, reward
self.agent.memorize(state, action, state_next, reward)
# Experience Replay
self.agent.update_q_function(step)
# if step % 100: # 每500步更新target网络
# self.agent.update_target_q_function()
state = state_next
step += 1
done_collect.append(done)
a_collect.append(a)
start_end_collect.append(start_to_end_list)
time_collect.append(start_to_end_list[1])
if done:
episode_reward.append(reward_sum)
makespan_history.append(np.max(time_collect))
if episode % 100 == 0:
print('episode', episode, 'makespan %.1f' % np.max(time_collect), 'reward', reward_sum)
a = np.max(time_collect)
if save_param > a:
save_param = np.max(time_collect)
Gantt2(done_collect, a_collect, start_end_collect, self.env.Job_num, self.env.Machine_num,
save_param, f'../gattePicture/{times}.png')
# 画图
drawLine(makespan_history, episode_reward, self.agent.brain.loss_history, f'../PictureSaver/{self.Capacity,self.Batch_size,self.GAMMA,self.Learning_rate, times}.png')
return makespan_history, episode_reward, self.agent.brain.loss_history
if __name__ == '__main__':
# D = DDQN_main(15261, 0.000000015, 521, 0.85)
D = DDQN_main(Capacity=3000, Learning_rate=0.000001, Batch_size=32, GAMMA=0.75)
D.run()
# D.run()