1 介绍
雪花算法(Snowflake)是一种生成分布式全局唯一 ID 的算法,生成的 ID 称为 Snowflake IDs 或 snowflakes。这种算法由 Twitter 创建,并用于推文的 ID。目前仓储平台生成 ID 是用的雪花算法修改后的版本。
雪花算法几个特性
-
生成的 ID 分布式唯一和按照时间递增有序,毫秒数在高位,自增序列在低位,整个 ID 都是趋势递增的。
-
不依赖数据库等三方系统,稳定性更高,性能非常高的。
-
可以根据自身业务特性分配 bit 位,非常灵活。
2 其他分布式唯一 ID 生成方案
2.1 数据库生成
以 MySQL 为例,单库单表,给字段设置 auto_increment 来生成全局唯一 ID
优点:
-
非常简单,维护成本比较低
-
ID 唯一,单调递增,可以设置固定步长
缺点:
- 可用性难以保证,每次生成 ID 都需要访问数据库,瓶颈在于单台 MySQL 读写性能上,如果数据库挂掉会造成服务不可用,这是一个致命的问题
2.2 UUID
UUID 是由一组 32 位数的 16 进制数字所构成,故 UUID 理论上的总数为 16^32=2^128,约等于 3.4 x 10^38。也就是说若每纳秒产生 1 兆个 UUID,要花 100 亿年才会将所有 UUID 用完。UUID 的标准型式包含 32 个 16 进制数字,以连字号分为五段,形式为 8-4-4-4-12 的 32 个字符。示例:550e8400-e29b-41d4-a716-446655440000
优点:
-
本地生成 ID,不需要进行远程调用,没有网络耗时
-
基本没有性能上限
缺点:
-
可读性差
-
长度过长,16 字节 128 位,生成的 UUID 通常是 36 位 (包含 -),有些场景可能不适用。如果用作数据库主键,在 MySQL 的 InnoDB 引擎下长度过长,二级索引 (非主键索引) 会占用很大的空间。
-
无法保证趋势递增,在 MySQL 的 InnoDB 引擎下,新插入数据会根据主键来寻找合适位置,会导致频繁的移动、分页增加了很多开销。
3 snowflake 算法实现细节
3.1 拆解 64bit 位
snowflake 生成的 id 通常是一个 64bit 数字,java 中用 long 类型。
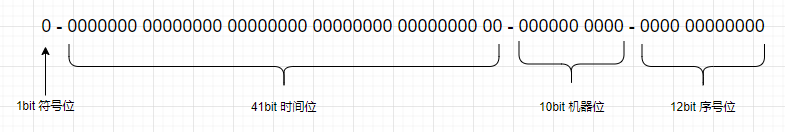
图 1:snowflake 算法中的 64-bit 划分方式
-
1-bit 不用于生成 ID (符号位) long 范围 [-2^(64-1), 2^(64-1) ] , (64-1) 中的 1 代表的就是符号位
-
41-bit 时间戳 (毫秒) 可以表示 1 x 2^41 / (1000 x 3600 x 24 x 365) = 69 年的时间
-
10-bit 可以分别表示 1 x 2^10 = 1024 台机器,范围 [0,1023]
-
12-bit 表示 1ms 内自动递增的序列号,1 x 2^12 = 4096 个 范围 [0,4095]。单机 1ms 可以生成 4096 个不重复的 ID
通过上述方式进行生成 ID,可以保证 1024 台机器在任意 69 年的时间段里不会出现重复的 ID,而且单台机器支持一秒能够生成 409.6 万个 ID。
这种方式可以支撑大部分业务,如果不满足,可以根据自身业务特点来调整不同命名空间占用的 bit 数。如果我们有划分 IDC 的需求,可以将 10-bit 分 5-bit 给 IDC,分 5-bit 给工作机器。这样就可以表示 32 个 IDC,每个 IDC 下可以有 32 台机器。如果我们的机器位比较特殊,数值相对较大,但是对并发要求不高,还可以将时间位调整为秒级,时间位节省出 10-bit 留给机器位。
-
1-bit 符号位
-
31-bit 时间戳 (秒) 1 x 2^31/ (3600 x 24 x 365) = 68 年
-
22-bit 机器位 运维平台给提供的数值 范围 [0,2^22-1]
-
10-bit 序列号 范围 [0, 2^10 - 1] 共 1024 个
通过上述方式进行生成 ID,可以保证 4194303 台机器在任意 68 年的时间段里不会出现重复的 ID,而且单台机器支持一秒能够生成 1024 个 ID。
3.2 Java 实现
public class IdGenerator {
// 起始时间
private final long from = 1422720000000L;
// 机器位所占bit位数
private final long instanceIdBits = 10L;
// 序列号所占bit位数
private final long sequenceBits = 12L;
// 机器位左移长度
private final long instanceIdShift = sequenceBits;
// 时间位左移长度
private final long timestampLeftShift = sequenceBits + instanceIdBits;
// 序号1: 最大机器ID
private final long maxInstanceId = -1L ^ (-1L << instanceIdBits);
// 最大序列号
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
private long instanceId;
private long sequence = 0L;
private long lastTimestamp = -1L;
public IdGenerator(long instanceId) {
if (instanceId > maxInstanceId || instanceId < 0) {
throw new IllegalArgumentException(String.format("instance Id can't be greater than %d or less than 0", maxInstanceId));
}
this.instanceId = instanceId;
}
// 序号2:
public synchronized long nextId() {
long timestamp = timeGen();
// 序号3:
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
// 序号4:
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextSecs(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
// 序号5:
return ((timestamp - from) << timestampLeftShift) // (当前时间 - 起始时间) 向左移位
| (instanceId << instanceIdShift) // 机器位 向左移位
| sequence; // 序列位
}
private long tilNextSecs(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
}
3.3 一些疑问
3.3.1 为什么 bit 位置只利用了 63 位?
因为 long 在 java 中占 8 字节,每字节 8bit,一共 64bit,其中有 1 个 bit 位是符号位不能用做生成 ID,如果符号位也用来做 ID 中的 1 个 bit 为会导致 ID 出现负数,影响趋势递增特性。
3.3.2 计算最大机器 ID
见代码中注释 序号 1
maxInstanceId = -1L ^ (-1L<<instanceIdBits)
等价于 maxInstanceId = -1 ^(-1<<10)
① -1 二进制
1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111
② -1 左移 10 位 -1<<10 二进制
1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1100 0000 0000
①与②进行异或运算 异或运算:同为假,异为真,所以最终结果应该为
0000 0000 0000 0000 0000 0000 0000 00000000 0000 0000 0000 0000 0011 1111 1111
最后:maxInstanceId = 2^10 - 1 = 1023
sequenceMask 计算方法相同,结果为 2^12 - 1 = 4095
3.3.3 计算序列号位
见代码中注释 序号 4
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextSecs(lastTimestamp);
}
} else {
sequence = 0L;
}
其中这段代码的是计算序列号的代码主要逻辑是,如果上个生成 ID 的时间位与当前 ID 的时间位冲突,则会生成一个序列号进行区分,如果序列号用尽,则等待下一个时间点再生成。如果上个生成 ID 的时间位与当前 ID 的时间位不冲突,则将序列号设置成 0。
sequence = (sequence + 1) & sequenceMask,序列号最大值 sequenceMask 为 4095,等价于如下这种写法。
sequence = (sequence + 1);
if(sequence == 4095){
sequence = 0;
}
其实这两种写法的结果是一致的,就是对 (sequence + 1) 进行取余。
这里有个位运算知识点 k % m = k & (m - 1),m 需要满足 m = 2^n,sequenceMask = 2^12 - 1。所以刚好可以用与运算进行取余操作,效率杠杠滴。
3.3.4 生成 ID
见代码中注释 序号 5:
此时我们拿到了时间位 (timestamp - from)、机器位 (instanceId )、序列号位 (sequence), 所以就可以计算最终的 ID 了。
((timestamp - from) << timestampLeftShift) // (当前时间 - 起始时间) 向左移位
| (instanceId << instanceIdShift) // 机器位 向左移位
| sequence; // 序列位
①((timestamp - from) << timestampLeftShift) 计算时间位
from 是固定的 1422720000000, timestampLeftShift = 12 + 10. 我们假设 timestamp = 1422720000001。也就是 from 刚刚过去 1 毫秒。1 毫秒也是我们时间位倒数第二小的值,因为 0 是最小值。时间位取值范围 [0, 2^41 - 1], 从这也可以看出上边描述时间位时为什么把时间段特意标注了,因为时间位存的不是具体时间,而是以 from 为起始来算的过去了多少时间。
来看下 1<<22 结果
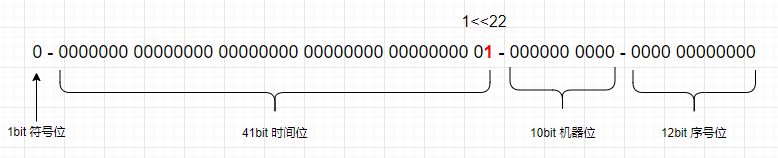
图 2: 时间位移位结果
图 2 可以看出,时间位向左移位 22,位置正好到第一个时间位。
②(instanceId << instanceIdShift) 计算机器位
为了方便计算,这里我们假设 instanceId 等于 1, 机器位取值范围 [0,-1]。
那么机器位就是 1 << 12
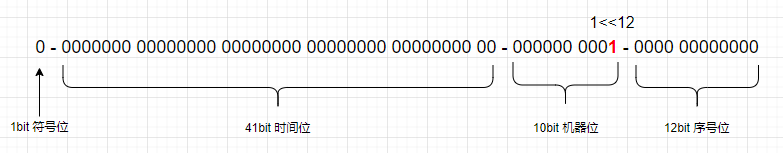
图 3: 机器位移位结果
图 3 可以看出,机器位左移 12 位,位置正好到第一个机器位。
③按照 ① | ② | sequence 进行或运算进行生成 ID
现在我们有了时间位的值,机器位的值,就只差序列号位的值,序列号是上面 3 描述代码生成的,范围是 [0, 2^12-1]。为了方便计算,我们假设 sequence = 1
那么 ID = ① | ② | 1。进行或运算

图 4: ID = ① | ② | 1
下图是按照上面逻辑生成的 ID

图 5: 程序生成结果
3.3.5 注意:雪花算法需要用单例方式生成 ID
因为雪花算法会依赖上一次生成的 ID 的时间来判断是否需要对序列号进行增加的操作,如果不是单例,两个业务用两个对象同时获取 ID,则可能会生成相同的 ID
4 关于雪花算法的一些思考
机器位怎么取值
-
主机唯一标识 如果运维平台有机器唯一标识,可以在运维平台取。不过需要考虑机器位能否容纳下唯一标识,可能会过长,也需要考虑运维平台的唯一标识未来变化。
-
可根据 ip 进行计算 如果能保证不同机房的机器 ip 不重复,可以利用 ip 来计算机器位,IP 最大 255.255.255.255。而(255+255+255+255) < 1024,因此采用 IP 段数值相加即可生成机器位,不受 IP 位限制。不过这种方式也不是绝对 ok,要根据自身情况在选择,比如 10.0.5.2 与 10.0.2.5 计算出来也是相同的。使用这种 IP 生成机器位的方法,必须保证 IP 段相加不能重复
-
通过数据库 /redis/zk 等进行协调,在应用启动的时候给每个机器分配不会重复的机器位 id。
时钟回拨问题
雪花算法强依赖时间,如果时间发生回拨,有可能会生成重复的 ID,在我们上面的 nextId 中我们用当前时间和上一次的时间进行判断,如果当前时间小于上一次的时间那么肯定是发生了回拨,雪花算法的做法是简单的抛出了一个异常。
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
如果业务的异常容忍度低,这里我们可以对其进行优化,如果时间回拨时间较短,比如配置 5ms 以内,那么可以直接等待一定的时间,让机器的时间追上来。也可以利用扩展位,将 64-bit 的机器位或者序列号位预留出 2-bit 的防止时钟回滚的扩展位。
5 ID 逆运算
如果线上出现 ID 重复,如何进行问题定位?对 ID 进行逆运算拿到 ID 的时间位、机器位、序号位。就可以进行下一步分析了。以上述生成的 4198401 为例
5.1 时间
时间位 = ID / 2^(机器位 + 序列号位) + from
时间位 = 4198401 / 2^(12 + 10) + 1422720000000 = 1422720000001
与上述生成 ID 时用时间位相符
注意:ID / 2^(机器位 + 序列号位) 是整数
5.2 机器
机器位 = (ID / 2^ 序列号位) % 2^(机器位)
机器位 = (4198401 / 2^12) % 2^10= (1025) % 1024 = 1
与上述生成 ID 时用机器位数值相符
5.3 序列号
ID % 2^ 序列号位
序列号 = 4198401 % = 4198401 % 1024 = 1
与上述生成 ID 时用的序列号数值相符
6 资料
开源代码 scala 版本:https://github.com/twitter-archive/snowflake
作者:京东物流 马红岩
来源:京东云开发者社区 自猿其说 Tech