大家好,我是微学AI,今天给大家介绍一下自然语言处理14-基于文本向量和欧氏距离相似度的文本匹配,用于找到与查询语句最相似的文本。NLP中的文本匹配是指通过计算文本之间的相似度来找到与查询语句最相似的文本。其中一种常用的方法是基于文本向量和欧氏距离相似度。将待匹配的文本和查询语句都转换为向量表示。可以使用词袋模型、tf-idf等方法将文本转换为向量。词袋模型将文本表示为每个词汇在文本中的出现次数,tf-idf则考虑了词汇在整个语料库中的重要性。 计算文本向量之间的欧氏距离。欧氏距离是一种常用的衡量向量相似度的方法,它表示两个向量之间的几何距离。 选择与查询语句具有最小欧氏距离的文本作为匹配结果。距离越小,表示两个文本越相似。
项目背景
基于文本向量和欧氏距离相似度进行文本匹配。通过将文本表示为向量,可以计算两个文本之间的欧氏距离相似度来衡量它们的语义相似程度。这种相似度匹配方法可以应用于各种文本相关的任务,如信息检索、句子匹配、推荐系统等。
该项目解决了文本匹配中的一个痛点,即如何找到与查询语句最相似的文本。在大规模的文本数据中,快速准确地找到与用户输入查询语句相关的文本对于提供高效的信息检索和推荐非常重要。传统的基于关键词匹配的方法往往无法处理语义相似度,而基于文本向量和欧氏距离相似度的方法可以更好地捕捉文本之间的语义关系,提高匹配的准确性。
通过该项目,可以实现快速地搜索和匹配与查询语句最相关的文本,从而提供更准确的搜索结果和个性化推荐,大大提高用户体验。同时,该方法还可以应用于其他领域,如自然语言处理、文本挖掘等,有着广泛的应用前景。
数学原理
基于文本向量和欧式距离相似度的文本相似度匹配是通过计算文本之间的向量表示之间的欧式距离来确定它们的相似程度。下面是相关的数学原理:
-
文本向量表示:将文本转化为向量表示通常使用词袋模型(Bag-of-Words)或者词嵌入(Word Embedding)、TF-IDF技术。在词袋模型中,文本被表示为一个向量,其中每个维度对应于一个单词或特征。词嵌入则通过将每个单词映射到一个低维连续向量空间中的向量来表示文本。
-
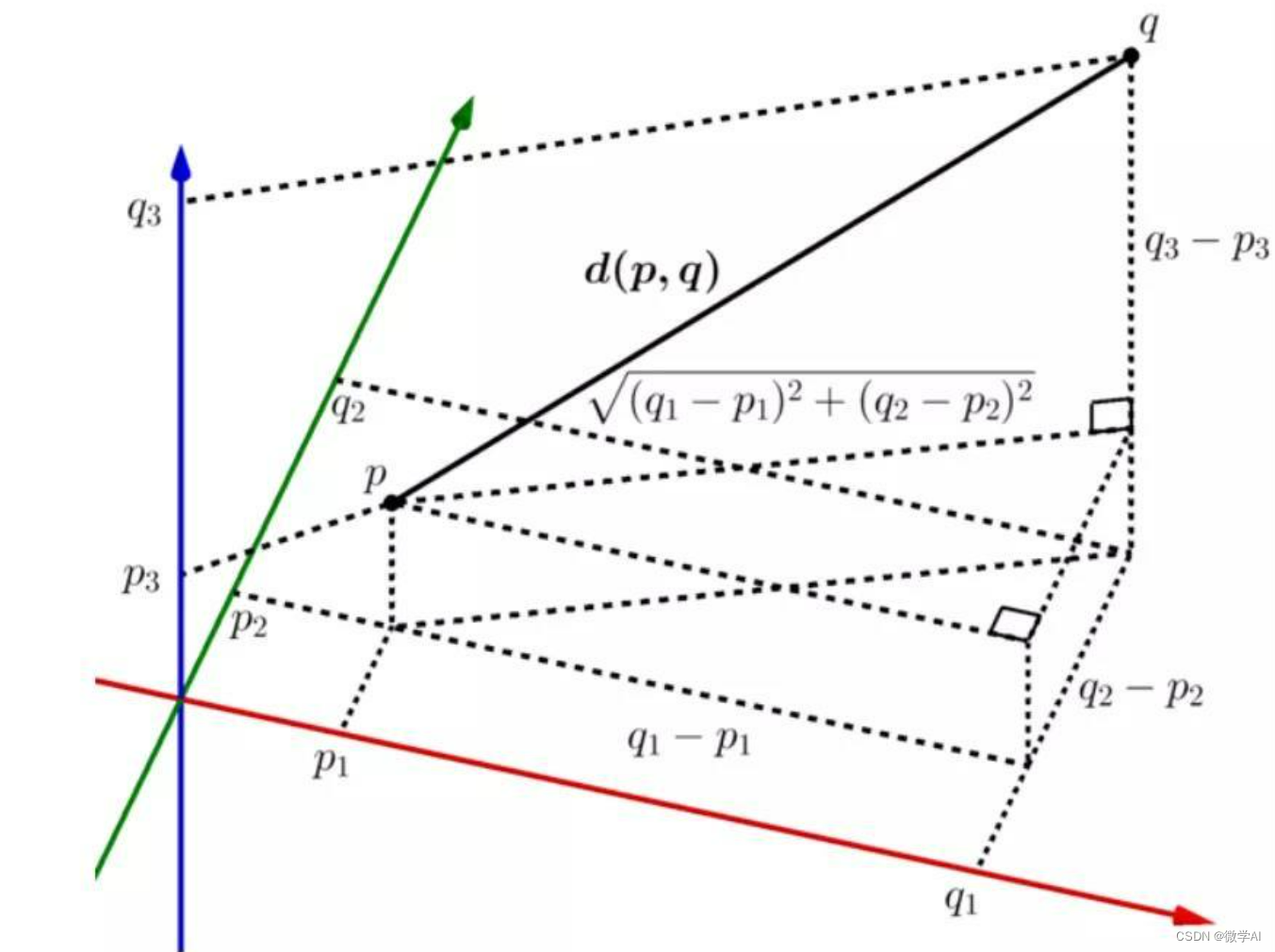
欧式距离:欧式距离是用来衡量两个向量直接的距离。对于两个向量x和y,其欧式距离可以通过以下公式计算:
d ( x , y ) = ∑ i = 1 n ( x i − y i ) 2 d(x, y) = \sqrt{\sum_{i=1}^{n}(x_i - y_i)^2} d(x,y)=i=1∑n(xi−yi)2
其中, n n n是向量的维度, x i x_i xi 和 y i y_i yi 分别表示向量 x x x 和 y y y 在第 i i i个维度上的取值。
-
相似度计算:根据欧式距离,我们可以计算文本之间的相似度得分。相似度计算方法通常是将欧式距离映射到一个相似度范围内,例如使用归一化公式:
s i m i l a r i t y = 1 1 + d similarity = \frac{1}{1 + d} similarity=1+d1
其中, d d d是欧式距离。
通过计算查询语句与其他文本之间的欧式距离,并根据相似度计算公式计算相似度得分,可以找到与查询语句最相似的文本。相似度得分越高,表示两个文本越相似。
实现步骤:
1.将样例数据存储在documents列表中,每个元素代表一个文本。
2.使用分词工具jieba对文本进行分词处理,生成分词后的文本列表documents_tokenized。
3.构建词汇表,使用TfidfVectorizer类来计算TF-IDF矩阵。TF-IDF是一种文本特征表示方法,它考虑了词频和逆文档频率,可以反映出词在文本中的重要程度。
4.将TF-IDF矩阵转换为DataFrame,其中行代表每个文本,列代表每个词汇。
5.定义查询语句并将其分词处理得到查询向量。
6.计算查询向量与库中各文本向量的余弦相似度,得到一个相似度矩阵。
7.找到相似度矩阵中相似度最高的文本索引,即为与查询语句最相似的文本。
8.最后,输出查询语句和最相似文本。
实现代码
现在用最清晰的代码实现文本相似度查找的功能:
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import jieba
# 样例数据
documents = ['北京的天气挺好',
'我要去北京玩',
'我来自中国',
"北京是比较好玩的地方",
"北京有故宫这个景点",
"这个假期去福州玩,感觉不错",
'上海的天气很热',
'我打算去上海旅游',
'上海是一个现代化城市',
'上海有很多高楼大厦',
'上海的夜景非常美丽',
'这个周末我要去上海参加活动',
'广州的气温很高',
'我喜欢广州的美食',
'广州是一个繁华的城市',
'广州有很多著名的旅游景点']
# 分词处理
tokenizer = lambda x: jieba.cut(x)
# 将文本进行分解
documents_tokenized = [" ".join(tokenizer(doc)) for doc in documents]
# 构建词汇表
vectorizer = TfidfVectorizer()
vectorizer.fit(documents_tokenized)
vocabulary = vectorizer.get_feature_names()
# 计算TF-IDF矩阵
tfidf_matrix = vectorizer.transform(documents_tokenized)
# 存储文本向量
df = pd.DataFrame(tfidf_matrix.toarray(), columns=vocabulary)
if __name__ == "__main__":
# 查询相似度
query = "你知道假期去福州,有什么景点推荐的"
query_tokenized = " ".join(tokenizer(query))
query_vector = vectorizer.transform([query_tokenized])
# 计算查询向量与库中向量的相似度
similarity_scores = cosine_similarity(query_vector, tfidf_matrix)
print(similarity_scores)
# 找到相似度最高的文本
most_similar_index = similarity_scores.argmax()
most_similar_text = documents[most_similar_index]
print("查询语句:", query)
print("最相似文本:", most_similar_text)
运行结果:
[[0. 0. 0. 0. 0.3319871 0.5341931]]
查询语句: 你知道假期去福州,有什么景点推荐的
最相似文本: 这个假期去福州玩,感觉不错
总结
本文介绍了一种基于文本向量和欧氏距离相似度的文本匹配方法,用于找到与查询语句最相似的文本。首先,通过将文本和查询语句转换为向量表示,使用词袋模型或tf-idf等方法进行向量化。然后,计算文本向量之间的欧氏距离,衡量它们之间的相似度。最后,选择具有最小欧氏距离的文本作为匹配结果。该方法强调了文本的语义信息,但忽略了上下文信息。在实际应用中,可以结合其他技术和算法以提高准确性。