目录
- 消息队列简介
- 消息队列的应用场景
- 异步处理
- 系统解耦
- 流量削峰
- 日志处理
- 消息队列的两种模式
- 点对点模式
- 发布订阅模式
- Kafka简介及应用场景
- Kafka比较其他MQ的优势
- Kafka目录结构
- 搭建Kafka集群
- 编写Kafka一键启动/关闭脚本
- Kafka基础操作
- 创建topic
- 生产消息到Kafka
- 从Kafka消费消息
- 使用 Kafka Tools 操作Kafka
- 带Security连接Kafka Tool
- Java编程操作Kafka
- 同步生产消息到Kafka中:
- 使用同步等待的方式发送消息
- 异步使用带有回调函数方法生产消息
- 从Kafka的topic中消费消息
- Kafka 重要概念
- broker
- Zookeeper
- producer(生产者)
- consumer(消费者)
- consumer group(消费者组)
- 主题(Topic)
- 分区(Partitions)
- 副本(Replicas)
- 偏移量(offset)
- 消费者组
- Kafka生产者幂等性
- 幂等性原理
消息队列简介
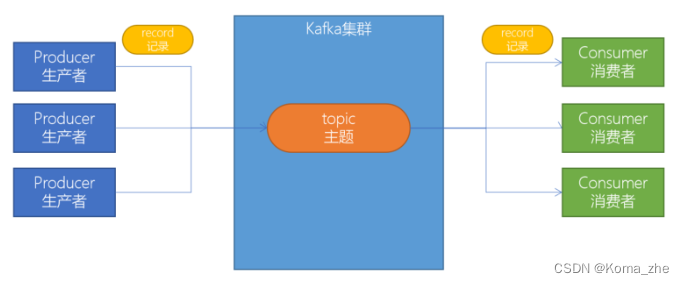
消息队列,经常缩写为MQ。从字面上来理解,消息队列是一种用来存储消息的队列。例如Java中的队列:
// 1. 创建一个保存字符串的队列
Queue<String> stringQueue = new LinkedList<String>();
// 2. 往消息队列中放入消息
stringQueue.offer("message");
// 3. 从消息队列中取出消息并打印
System.out.println(stringQueue.poll());
上述代码,创建了一个队列,先往队列中添加了一个消息,然后又从队列中取出了一个消息。这说明了队列是可以用来存取消息的。我们可以简单理解消息队列就是将需要传输的数据存放在队列中。
消息队列中间件就是用来存储消息的软件(组件)。消息队列有很多,例如:Kafka、RabbitMQ、ActiveMQ、RocketMQ、ZeroMQ 等。
消息队列的应用场景
异步处理
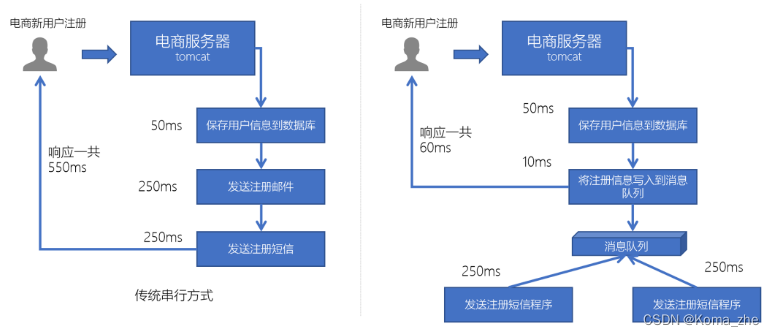
例如在电商网站中,新的用户注册时,需要将用户的信息保存到数据库中,同时还需要额外发送注册的邮件通知、以及短信注册码给用户。
但因为发送邮件、发送注册短信需要连接外部的服务器,需要额外等待一段时间,此时,就可以使用消息队列来进行异步处理,从而实现快速响应。
系统解耦

流量削峰
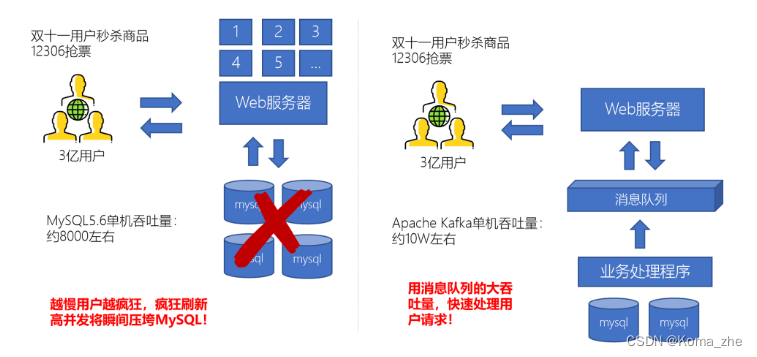
日志处理
大型电商网站(淘宝、京东、国美、苏宁…)、App(抖音、美团、滴滴等)等需要分析用户行为,要根据用户的访问行为来发现用户的喜好以及活跃情况,需要在页面上收集大量的用户访问信息。
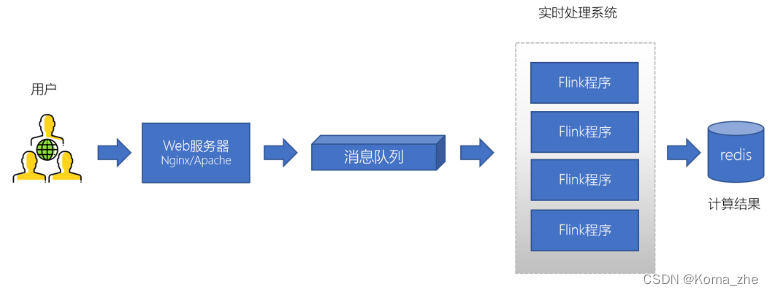
消息队列的两种模式
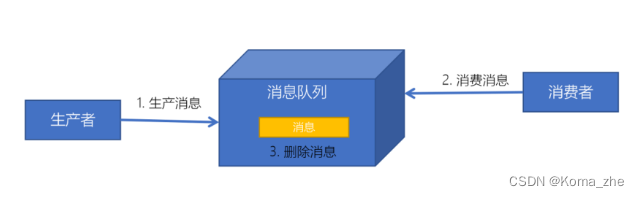
点对点模式
消息发送者生产消息发送到消息队列中,然后消息接收者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息接收者不可能消费到已经被消费的消息。
特点:
- 每个消息只有一个接收者(Consumer)(即一旦被消费,消息就不再在消息队列中)
- 发送者和接收者间没有依赖性,发送者发送消息之后,不管有没有接收者在运行,都不会影响到发送者下次发送消息;
- 接收者在成功接收消息之后需向队列应答成功,以便消息队列删除当前接收的消息;
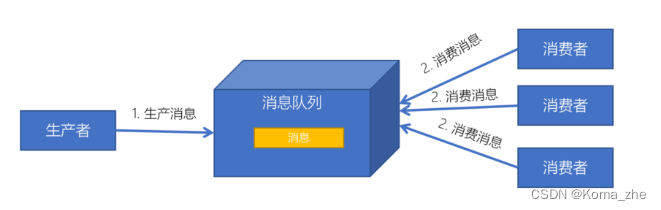
发布订阅模式
特点:
- 每个消息可以有多个订阅者;
- 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。
- 为了消费消息,订阅者需要提前订阅该角色主题,并保持在线运行;
Kafka简介及应用场景
Apache Kafka是一个分布式流平台。一个分布式的流平台应该包含3点关键的能力:
- 发布和订阅流数据流,类似于消息队列或者是企业消息传递系统
- 以容错的持久化方式存储数据流
- 处理数据流
通常将Apache Kafka用在两类程序:
-
建立实时数据管道,以可靠地在系统或应用程序之间获取数据
-
构建实时流应用程序,以转换或响应数据流
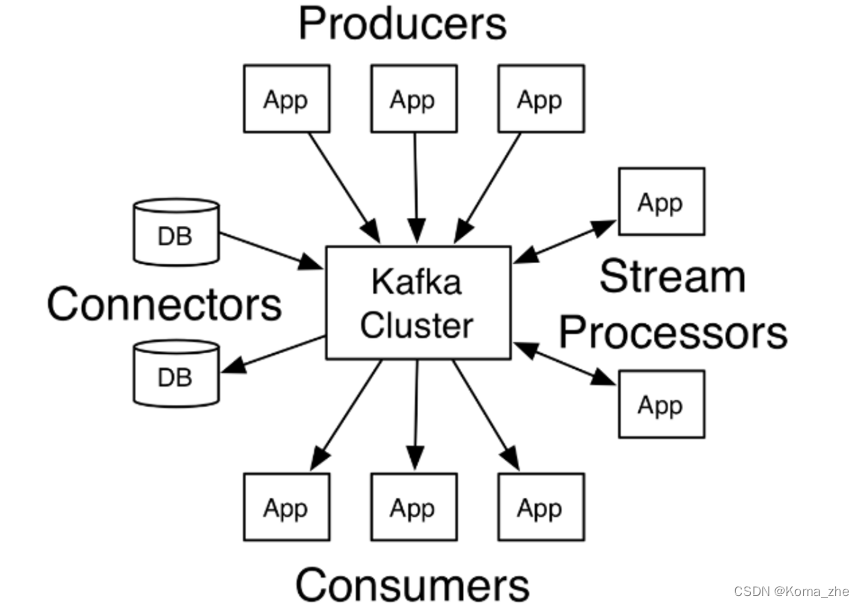
Producers:可以有很多的应用程序,将消息数据放入到Kafka集群中。
Consumers:可以有很多的应用程序,将消息数据从Kafka集群中拉取出来。
Connectors:Kafka的连接器可以将数据库中的数据导入到Kafka,也可以将Kafka的数据导出到数据库中。
Stream Processors:流处理器可以Kafka中拉取数据,也可以将数据写入到Kafka中。
Kafka比较其他MQ的优势
| 特性 | ActiveMQ | RabbitMQ | Kafka | RocketMQ |
|---|---|---|---|---|
| 所属社区/公司 | Apache | Mozilla Public License | Apache | Apache/Ali |
| 成熟度 | 成熟 | 成熟 | 成熟 | 比较成熟 |
| 生产者-消费者模式 | 支持 | 支持 | 支持 | 支持 |
| 发布-订阅 | 支持 | 支持 | 支持 | 支持 |
| REQUEST-REPLY | 支持 | 支持 | - | 支持 |
| API完备性 | 高 | 高 | 高 | 低(静态配置) |
| 多语言支持 | 支持JAVA优先 | 语言无关 | 支持,JAVA优先 | 支持 |
| 单机呑吐量 | 万级(最差) | 万级 | 十万级 | 十万级(最高) |
| 消息延迟 | - | 微秒级 | 毫秒级 | - |
| 可用性 | 高(主从) | 高(主从) | 非常高(分布式) | 高 |
| 消息丢失 | - | 低 | 理论上不会丢失 | - |
| 消息重复 | - | 可控制 | 理论上会有重复 | - |
| 事务 | 支持 | 不支持 | 支持 | 支持 |
| 文档的完备性 | 高 | 高 | 高 | 中 |
| 提供快速入门 | 有 | 有 | 有 | 无 |
| 首次部署难度 | - | 低 | 中 | 高 |
Kafka目录结构
使用的Kafka版本为2.4.1。
| 目录名称 | 说明 |
|---|---|
| bin | Kafka的所有执行脚本都在这里。例如:启动Kafka服务器、创建Topic、生产者、消费者程序等等 |
| config | Kafka的所有配置文件 |
| libs | 运行Kafka所需要的所有JAR包 |
| logs | Kafka的所有日志文件,如果Kafka出现一些问题,需要到该目录中去查看异常信息 |
| site-docs | Kafka的网站帮助文件 |
搭建Kafka集群
使用的Kafka版本为2.4.1,是2020年3月12日发布的版本。
注:Kafka 的版本号为:kafka_2.12-2.4.1,因为Kafka 主要是使用scala语言开发的,2.12为scala 的版本号。
创建并解压:
sudo mkdir export
cd /export
sudo mkdir server
sudo mkdir software
sudo chmod 777 software/
sudo chmod 777 server/
cd /export/software/
tar -xvzf kafka_2.12-2.4.1.tgz -C ../server/
修改 server.properties:
# 创建Kafka数据的位置
mkdir /export/server/kafka_2.12-2.4.1/data
vim /export/server/kafka_2.12-2.4.1/config/server.properties
# 指定broker的id
broker.id=0
# 指定Kafka数据的位置
log.dirs=/export/server/kafka_2.12-2.4.1/data
# 配置zk的三个节点
zookeeper.connect=10.211.55.8:2181,10.211.55.9:2181,10.211.55.7:2181
其余两台服务器重复以上步骤,仅修改 broker.id 为不同。
配置KAFKA_HOME环境变量:
sudo su
vim /etc/profile
export KAFKA_HOME=/export/server/kafka_2.12-2.4.1
export PATH=:$PATH:${KAFKA_HOME}
#源文件无下面这条需手动添加
export PATH
每个节点加载环境变量
source /etc/profile
启动服务器:
# 启动ZooKeeper
# 启动Kafka,需要在kafka根目录下启动
cd /export/server/kafka_2.12-2.4.1
nohup bin/kafka-server-start.sh config/server.properties &
# 测试Kafka集群是否启动成功
bin/kafka-topics.sh --bootstrap-server 10.211.55.8:9092 --list
# 无报错,打印为空
编写Kafka一键启动/关闭脚本
为了方便将来进行一键启动、关闭Kafka,可以编写一个shell脚本来操作,只要执行一次该脚本就可以快速启动或关闭Kafka。
准备 slave 配置文件,用于保存要启动哪几个节点上的kafka:
# 创建 /export/onekey 目录
sudo mkdir onekey
cd /export/onekey
sudo su
#新建slave文件
touch slave
#slave中写入以下内容
10.211.55.8
10.211.55.9
10.211.55.7
编写start-kafka.sh脚本:
vim start-kafka.sh
cat /export/onekey/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;export JMX_PORT=9988;nohup ${KAFKA_HOME}/bin/kafka-server-start.sh ${KAFKA_HOME}/config/server.properties >/dev/nul* 2>&1 & "
wait
}&
done
编写stop-kafka.sh脚本:
vim stop-kafka.sh
cat /export/onekey/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;jps |grep Kafka |cut -d' ' -f1 |xargs kill -s 9"
wait
}&
done
给start-kafka.sh、stop-kafka.sh配置执行权限:
chmod u+x start-kafka.sh
chmod u+x stop-kafka.sh
# 执行一键启动、一键关闭,注:执行shell脚本需实现服务器间ssh免密登录
./start-kafka.sh
./stop-kafka.sh
# 当查看日志发生Error connecting to node ubuntu2:9092错误时需在三台服务器上配置如下命令,以ubuntu2为例,另外两台同样的规则配置
# sudo vim /etc/hosts
# 10.211.55.8 ubuntu1
# 10.211.55.7 ubuntu3
Kafka基础操作
创建topic
创建一个topic(主题)。Kafka中所有的消息都是保存在主题中,要生产消息到Kafka,首先必须要有一个确定的主题。
# 创建名为test的主题
bin/kafka-topics.sh --create --bootstrap-server 10.211.55.8:9092 --topic test
# 查看目前Kafka中的主题
bin/kafka-topics.sh --list --bootstrap-server 10.211.55.8:9092
# 成功打印出 test
生产消息到Kafka
使用Kafka内置的测试程序,生产一些消息到Kafka的test主题中。
bin/kafka-console-producer.sh --broker-list 10.211.55.8:9092 --topic test
# “>”表示等待输入
从Kafka消费消息
再开一个窗口:
# 使用消费 test 主题中的消息。
bin/kafka-console-consumer.sh --bootstrap-server 10.211.55.8:9092 --topic test --from-beginning
# 实现了生产者发送消息,消费者接受消息
使用 Kafka Tools 操作Kafka
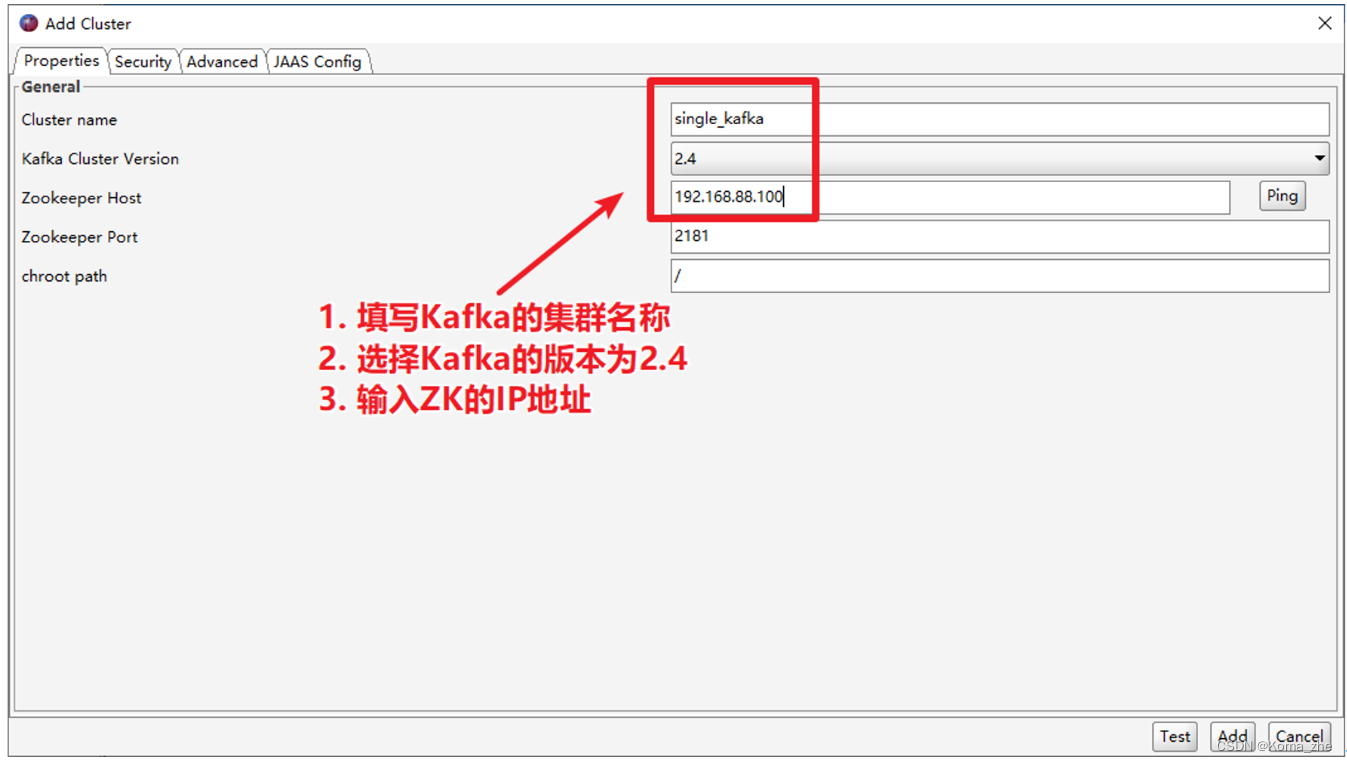

带Security连接Kafka Tool
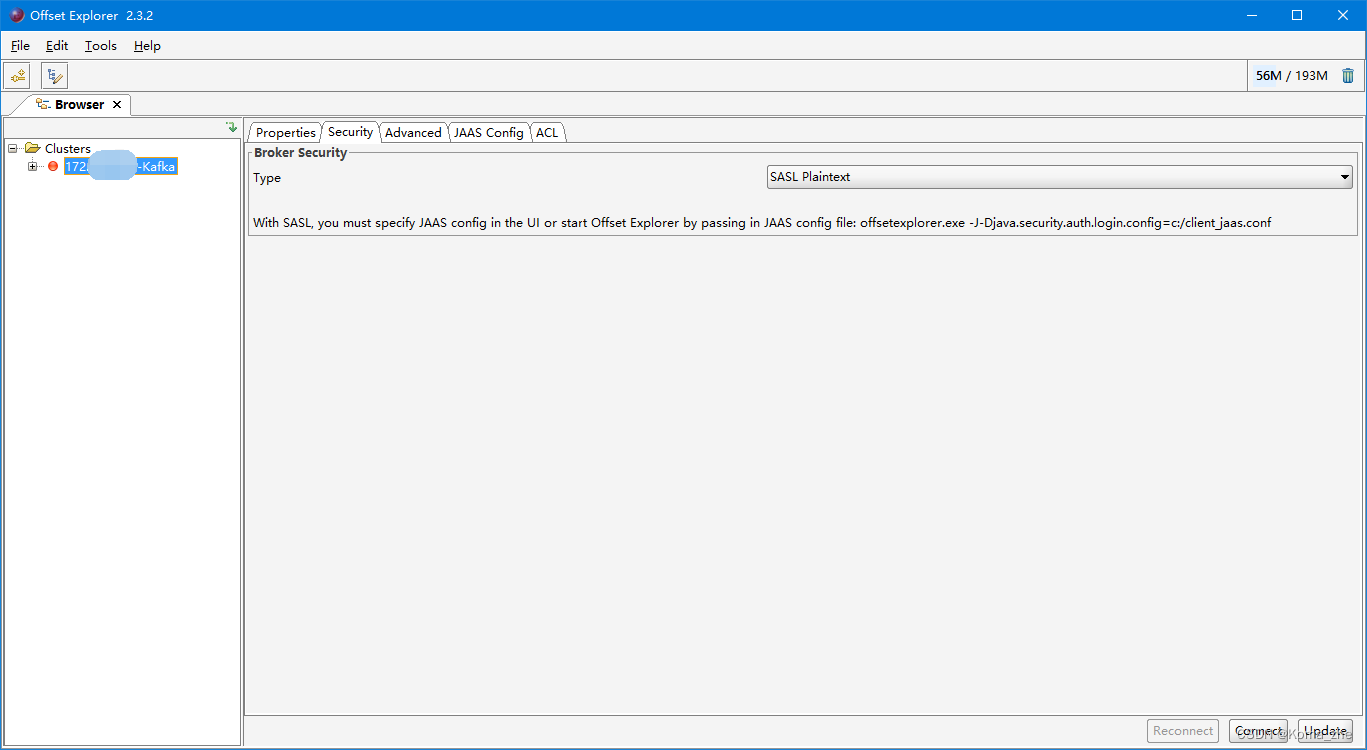
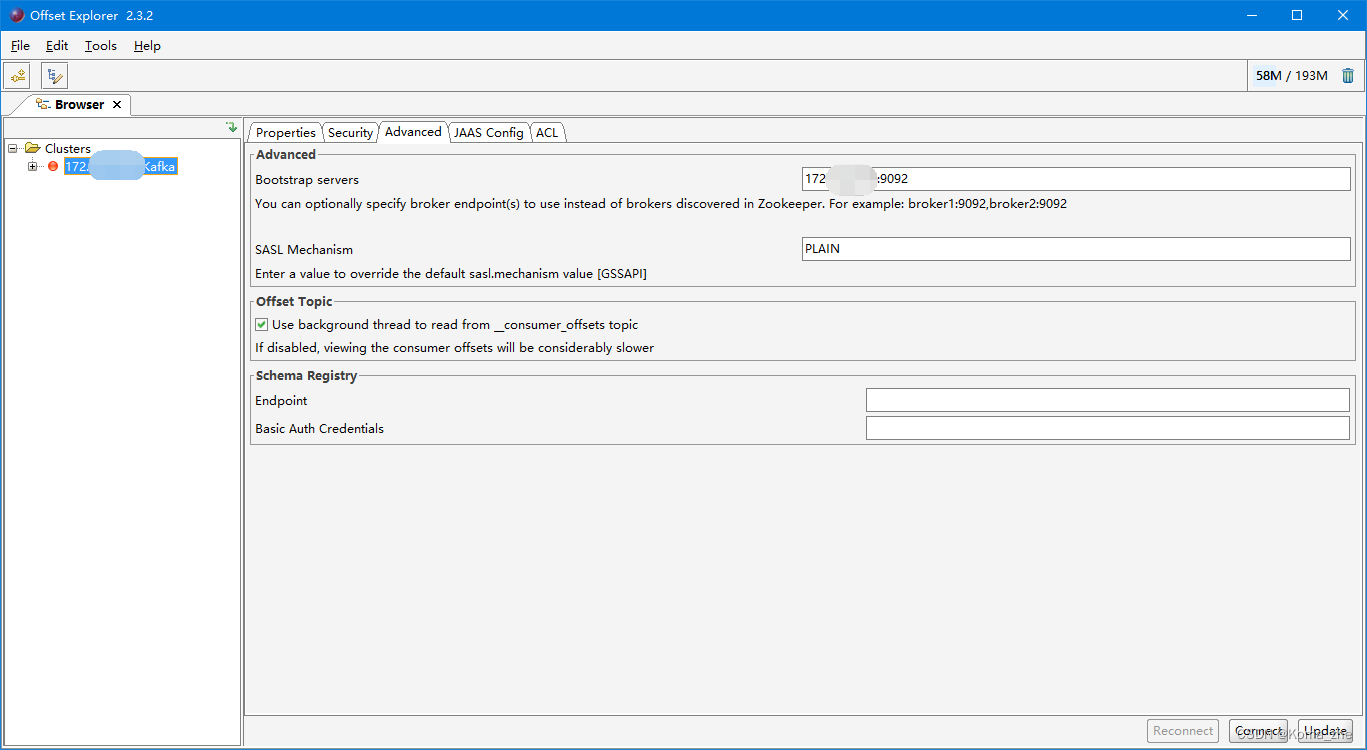
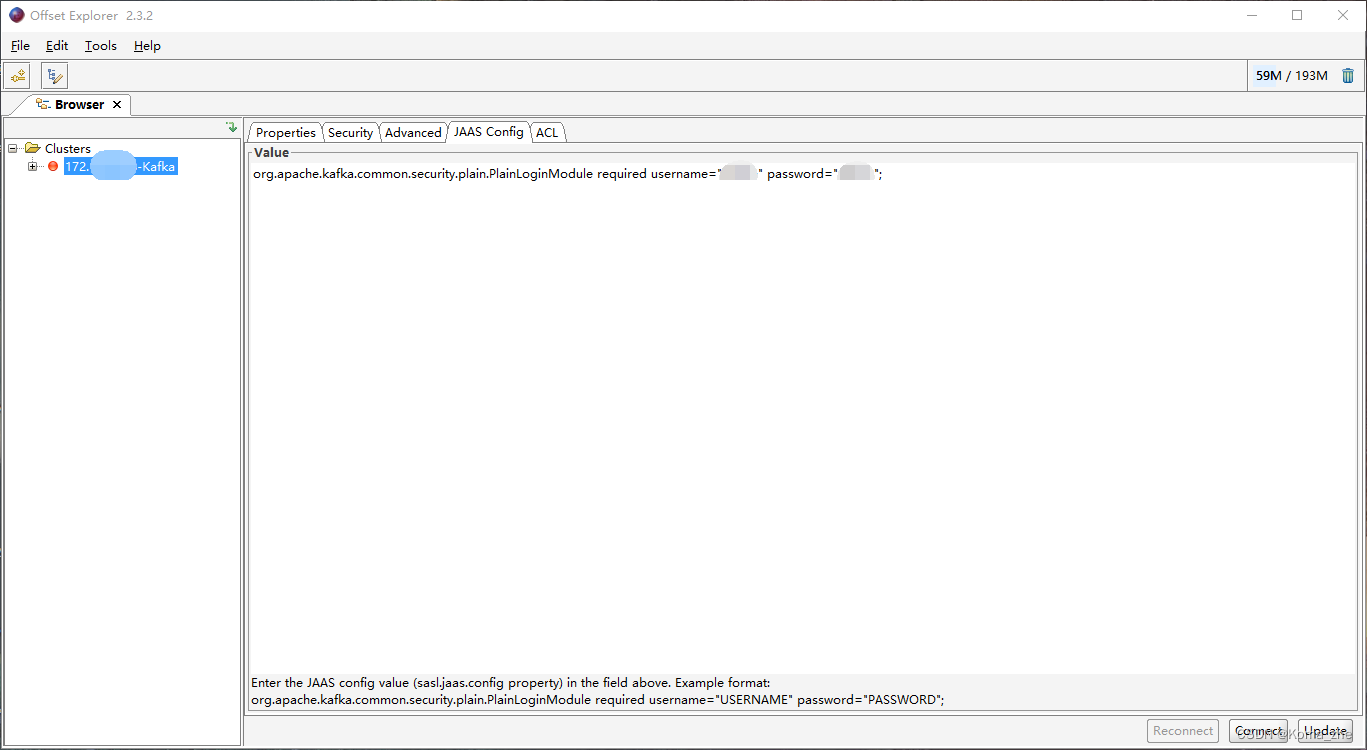
Java编程操作Kafka
导入Maven Kafka pom.xml 依赖:
<repositories><!-- 代码库 -->
<repository>
<id>central</id>
<url>http://maven.aliyun.com/nexus/content/groups/public//</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
<checksumPolicy>fail</checksumPolicy>
</snapshots>
</repository>
</repositories>
<dependencies>
<!-- kafka客户端工具 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
<!-- 工具类 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-io</artifactId>
<version>1.3.2</version>
</dependency>
<!-- SLF桥接LOG4J日志 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.6</version>
</dependency>
<!-- SLOG4J日志 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.16</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
log4j.properties:(放入到resources文件夹中)
log4j.rootLogger=INFO,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n
同步生产消息到Kafka中:
- 创建用于连接Kafka的Properties配置
Properties props = new Properties();
//这个配置是 Kafka 生产者和消费者必须要指定的一个配置项,它用于指定 Kafka 集群中的一个或多个 broker 地址,生产者和消费者将使用这些地址与 Kafka 集群建立连接。
props.put("bootstrap.servers", "192.168.88.100:9092");
//这行代码将 acks 配置设置为 all。acks 配置用于指定消息确认的级别。在此配置下,生产者将等待所有副本都成功写入后才会认为消息发送成功。这种配置级别可以确保数据不会丢失,但可能会影响性能。
props.put("acks", "all");
//这行代码将键(key)序列化器的类名设置为 org.apache.kafka.common.serialization.StringSerializer。键和值都需要被序列化以便于在网络上传输。这里使用的是一个字符串序列化器,它将字符串序列化为字节数组以便于发送到 Kafka 集群。
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//这行代码将值(value)序列化器的类名设置为 org.apache.kafka.common.serialization.StringSerializer。这里同样使用的是一个字符串序列化器,它将字符串序列化为字节数组以便于发送到 Kafka 集群。
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
- 创建一个生产者对象 KafkaProducer
- 调用 send 发送1-100消息到指定Topic test,并获取返回值Future,该对象封装了返回值
- 再调用一个Future.get() 方法等待响应
- 关闭生产者
使用同步等待的方式发送消息
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
/**
* Kafka的生产者程序,会将消息创建出来,并发送到Kafka集群中
* 1. 创建用于连接Kafka的Properties配置
* 2. 创建一个生产者对象KafkaProducer
* 3. 调用send发送1-100消息到指定Topic test,并获取返回值Future,该对象封装了返回值
* 4. 再调用一个Future.get()方法等待响应
* 5. 关闭生产者
*/
public class KafkaProducerTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 创建用于连接Kafka的Properties配置
Properties props = new Properties();
props.put("bootstrap.servers", "172.xx.xx.1x8:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("security.protocol", "SASL_PLAINTEXT");
props.put("sasl.mechanism", "PLAIN");
props.put("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"xxxx\" password=\"xxxx\";");
// 实现生产者的幂等性
props.put("enable.idempotence",true);
// 创建一个生产者对象KafkaProducer
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(props);
// 发送1-100的消息到指定的topic中
for (int i = 0; i < 100; ++i) {
// 一、使用同步等待的方式发送消息
// 构建一条消息,直接new ProducerRecord
//"test":这个参数是指定 Kafka 主题(topic)的名称,表示这条记录将被发送到哪个主题中。
// null:这个参数表示记录的键(key)。在 Kafka 中,每条消息都可以有一个键值对,键是一个可选参数,如果没有设置,则为 null。
//i + "":这个参数表示记录的值(value)。这里的 i 是一个整数,通过将它转换为字符串来设置记录的值。这个值将被序列化为字节数组并被发送到 Kafka 集群。
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("test", null, i + "");
Future<RecordMetadata> future = kafkaProducer.send(producerRecord);
// 调用Future的get方法等待响应
future.get();
System.out.println("第" + i + "条消息写入成功!");
}
// 关闭生产者
kafkaProducer.close();
}
}
异步使用带有回调函数方法生产消息
如果想获取生产者消息是否成功,或者成功生产消息到 Kafka 中后,执行一些其他动作。此时,可以很方便地使用带有回调函数来发送消息。
- 在发送消息出现异常时,能够及时打印出异常信息
- 在发送消息成功时,打印 Kafka 的 topic 名字、分区id、offset
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
/**
* Kafka的生产者程序,会将消息创建出来,并发送到Kafka集群中
* 1. 创建用于连接Kafka的Properties配置
* 2. 创建一个生产者对象KafkaProducer
* 3. 调用send发送1-100消息到指定Topic test,并获取返回值Future,该对象封装了返回值
* 4. 再调用一个Future.get()方法等待响应
* 5. 关闭生产者
*/
public class KafkaProducerTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 创建用于连接Kafka的Properties配置
Properties props = new Properties();
props.put("bootstrap.servers", "172.16.4.158:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("security.protocol", "SASL_PLAINTEXT");
props.put("sasl.mechanism", "PLAIN");
props.put("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"admin\" password=\"admin\";");
//实现生产者的幂等性
props.put("enable.idempotence",true);
// 创建一个生产者对象KafkaProducer
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(props);
// 发送1-100的消息到指定的topic中
for (int i = 0; i < 100; ++i) {
// 二、使用异步回调的方式发送消息
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("test", null, i + "");
//使用匿名内部类实现Callback接口,该接口中表示Kafka服务器响应给客户端,会自动调用onCompletion方法
//metadata:消息的元数据(属于哪个topic、属于哪个partition、对应的offset是什么)
//exception:这个对象Kafka生产消息封装了出现的异常,如果为null,表示发送成功,如果不为null,表示出现异常。
kafkaProducer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
// 1. 判断发送消息是否成功
if(exception == null) {
// 发送成功
// 主题
String topic = metadata.topic();
// 分区id
int partition = metadata.partition();
// 偏移量
long offset = metadata.offset();
System.out.println("topic:" + topic + " 分区id:" + partition + " 偏移量:" + offset);
}
else {
// 发送出现错误
System.out.println("生产消息出现异常!");
// 打印异常消息
System.out.println(exception.getMessage());
// 打印调用栈
System.out.println(exception.getStackTrace());
}
}
});
}
// 4.关闭生产者
kafkaProducer.close();
}
}
从Kafka的topic中消费消息
从 test topic中,将消息都消费,并将记录的offset、key、value打印出来。
- 创建Kafka消费者配置
Properties props = new Properties();
//这一行将属性"bootstrap.servers"的值设置为"node1.itcast.cn:9092"。这是Kafka生产者和消费者所需的Kafka集群地址和端口号。
props.setProperty("bootstrap.servers", "node1.itcast.cn:9092");
//这一行将属性"group.id"的值设置为"test"。这是消费者组的唯一标识符。所有属于同一组的消费者将共享一个消费者组ID。
props.setProperty("group.id", "test");
//这一行将属性"enable.auto.commit"的值设置为"true"。这表示消费者是否应该自动提交偏移量。
props.setProperty("enable.auto.commit", "true");
//这一行将属性"auto.commit.interval.ms"的值设置为"1000"。这是消费者自动提交偏移量的时间间隔,以毫秒为单位。
props.setProperty("auto.commit.interval.ms", "1000");
//这两行将属性"key.deserializer"和"value.deserializer"的值都设置为"org.apache.kafka.common.serialization.StringDeserializer"。这是用于反序列化Kafka消息的Java类的名称。在这种情况下,消息的键和值都是字符串类型,因此使用了StringDeserializer类来反序列化它们。
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
- 创建Kafka消费者
- 订阅要消费的主题
- 使用一个while循环,不断从Kafka的topic中拉取消息
- 将将记录(record)的offset、key、value都打印出来
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
/**
* 消费者程序
* 1.创建Kafka消费者配置
* 2.创建Kafka消费者
* 3.订阅要消费的主题
* 4.使用一个while循环,不断从Kafka的topic中拉取消息
* 5.将将记录(record)的offset、key、value都打印出来
*/
public class KafkaConsumerTest {
public static void main(String[] args) throws InterruptedException {
// 创建Kafka消费者配置
Properties props = new Properties();
props.setProperty("bootstrap.servers", "172.16.4.158:9092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("security.protocol", "SASL_PLAINTEXT");
props.put("sasl.mechanism", "PLAIN");
props.put("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"xxxx\" password=\"xxxx\";");
// 创建Kafka消费者
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(props);
// 订阅要消费的主题
// 指定消费者从哪个topic中拉取数据
kafkaConsumer.subscribe(Arrays.asList("test"));
// 使用一个while循环,不断从Kafka的topic中拉取消息
while(true) {
// Kafka的消费者一次拉取一批的数据
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(5));
// 将将记录(record)的offset、key、value都打印出来
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
// 主题
String topic = consumerRecord.topic();
// offset:这条消息处于Kafka分区中的哪个位置
long offset = consumerRecord.offset();
// key和value
String key = consumerRecord.key();
String value = consumerRecord.value();
System.out.println("topic: " + topic + " offset:" + offset + " key:" + key + " value:" + value);
}
}
}
}
Kafka 重要概念
broker
一个Kafka的集群通常由多个broker组成,这样才能实现负载均衡、以及容错。broker是无状态(Sateless)的,它们是通过ZooKeeper来维护集群状态。一个Kafka的broker每秒可以处理数十万次读写,每个broker都可以处理TB消息而不影响性能。
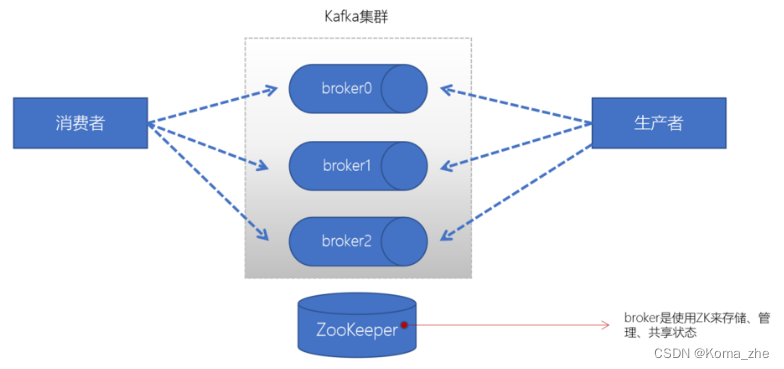
Zookeeper
ZK 用来管理和协调 broker,并且存储了 Kafka 的元数据(例如:有多少topic、partition、consumer)。ZK 服务主要用于通知生产者和消费者 Kafka 集群中有新的 broker 加入、或者 Kafka 集群中出现故障的 broker。
注:Kafka正在逐步想办法将 ZooKeeper 剥离,维护两套集群成本较高,社区提出KIP-500就是要替换掉ZooKeeper的依赖。“Kafka on Kafka”——Kafka自己来管理自己的元数据。
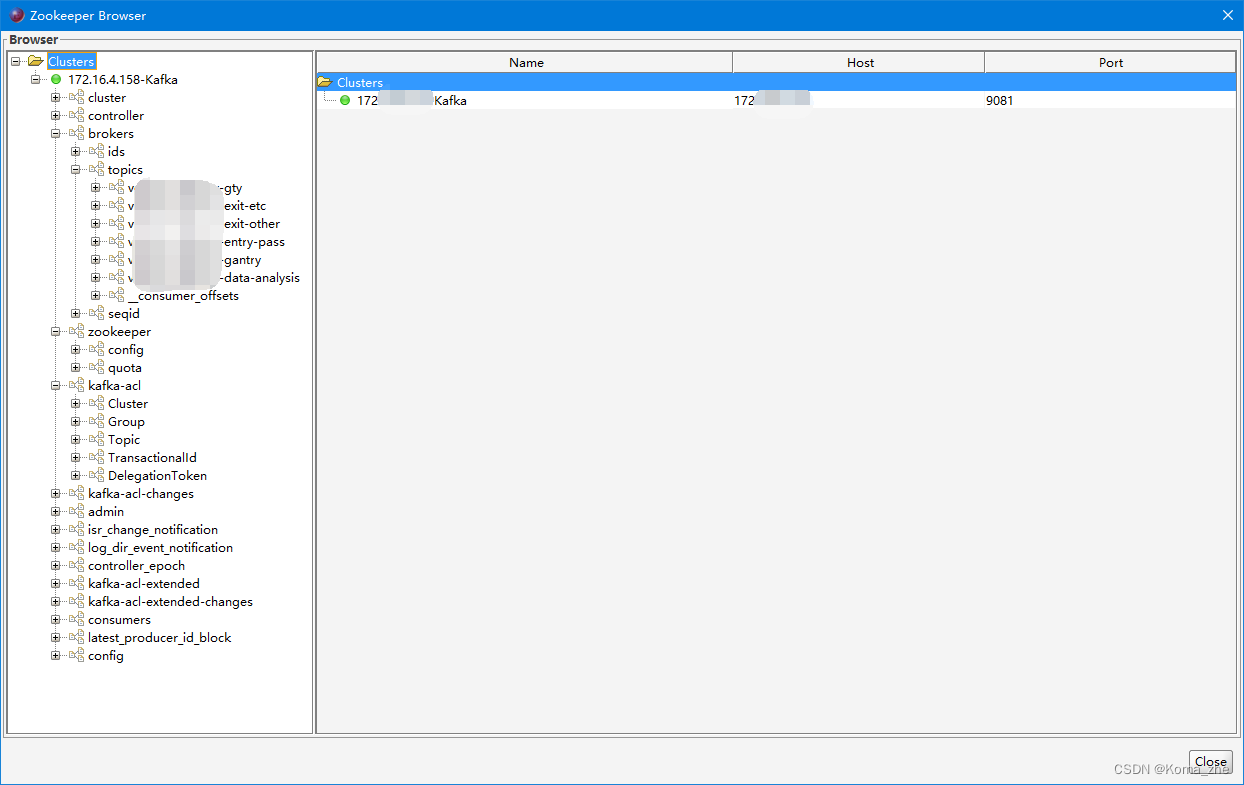
Kafka Tool 可以查看ZooKeeper配置
producer(生产者)
生产者负责将数据推送给broker的 topic
consumer(消费者)
消费者负责从broker的 topic 中拉取数据,并自己进行处理
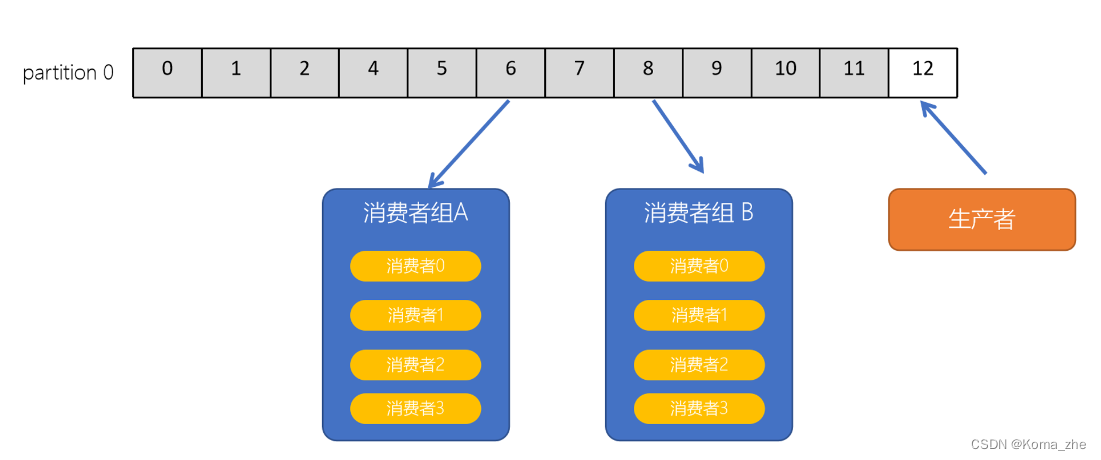
consumer group(消费者组)
consumer group是 Kafka 提供的可扩展且具有容错性的消费者机制。一个消费者组可以包含多个消费者。一个消费者组有一个唯一的ID(group Id)。组内的消费者一起消费主题的所有分区数据。
主题(Topic)
主题是一个逻辑概念,用于生产者发布数据,消费者拉取数据。Kafka 中的主题必须要有标识符,而且是唯一的,Kafka中可以有任意数量的主题,没有数量上的限制。在主题中的消息是有结构的,一般一个主题包含某一类消息。一旦生产者发送消息到主题中,这些消息就不能被更新(更改)
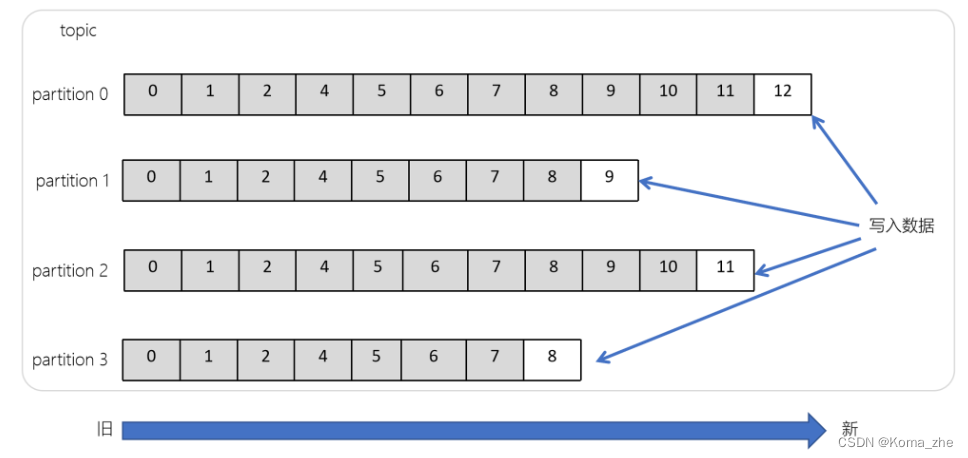
分区(Partitions)
在Kafka集群中,主题被分为多个分区。在 Kafka 中,同一个 topic 的消息可以被分配到不同的分区中,具体分配规则取决于 partitioner。
Kafka 提供了默认的 partitioner 实现,称为 DefaultPartitioner,其将消息的 key(如果存在)进行哈希,然后根据哈希值确定该消息应该被分配到哪个分区。如果消息没有 key,则采用轮询的方式将消息分配到不同的分区中。
除了默认的 partitioner,用户还可以自定义 partitioner 实现,以满足不同的需求。自定义 partitioner 实现需要实现 Kafka 提供的 Partitioner 接口,并在生产者配置中指定使用该 partitioner。
无论是使用默认的 partitioner 还是自定义 partitioner,都需要遵循以下规则:
- 对于同一个 key,始终分配到同一个分区中。
- 对于没有 key 的消息,应该采用随机或轮询的方式将消息分配到不同的分区中。
需要注意的是,分区数的变化也可能导致消息分配到不同的分区中。例如,当某个 topic 的分区数发生变化时,之前已经写入的消息可能会被重新分配到不同的分区中。因此,在生产者代码中应该谨慎处理分区数的变化,以避免数据丢失或重复。

副本(Replicas)
副本可以确保某个服务器出现故障时,确保数据依然可用。在Kafka中,一般都会设计副本的个数>1。
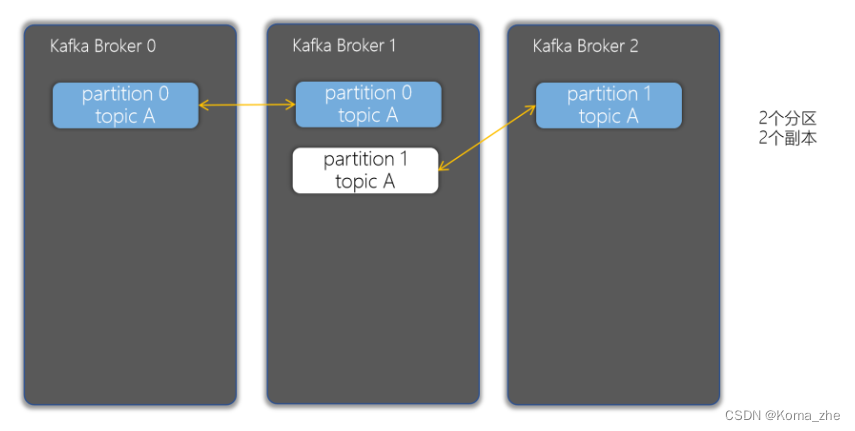
偏移量(offset)
offset 记录着下一条将要发送给 Consumer 的消息的序号。默认 Kafka 将 offset 存储在ZooKeeper 中。在一个分区中,消息是有顺序的方式存储着,每个在分区的消费都是有一个递增的id。这个就是偏移量offset。偏移量在分区中才是有意义的。在分区之间,offset 是没有任何意义的。
消费者组
Kafka 支持有多个消费者同时消费一个主题中的数据。启动两个消费者共同来消费 test 主题的数据。
修改生产者程序,让生产者不停地每3秒生产1-100个数字:
// 发送1-100数字到Kafka的test主题中
while(true) {
for (int i = 1; i <= 100; ++i) {
// 注意:send方法是一个异步方法,它会将要发送的数据放入到一个buffer中,然后立即返回
// 这样可以让消息发送变得更高效
producer.send(new ProducerRecord<>("test", i + ""));
}
Thread.sleep(3000);
}
同时运行两个消费者:
可以发现,只有一个消费者程序能够拉取到消息。想要让两个消费者同时消费消息,必须要给 test 主题,添加一个分区。
# 设置 test topic为2个分区
bin/kafka-topics.sh --zookeeper 10.211.55.8:2181 -alter --partitions 2 --topic test
重新运行生产者、两个消费者程序,就可以看到两个消费者都可以消费Kafka Topic的数据了。
Kafka生产者幂等性
拿http举例来说,一次或多次请求,得到地响应是一致的(网络超时等问题除外),换句话说,就是执行多次操作与执行一次操作的影响是一样的。如果,某个系统是不具备幂等性的,如果用户重复提交了某个表格,就可能会造成不良影响。例如:用户在浏览器上点击了多次提交订单按钮,会在后台生成多个一模一样的订单。
Kafka生产者幂等性:在生产者生产消息时,如果出现 retry 时,有可能会一条消息被发送了多次,如果 Kafka 不具备幂等性的,就有可能会在 partition 中保存多条一模一样的消息。
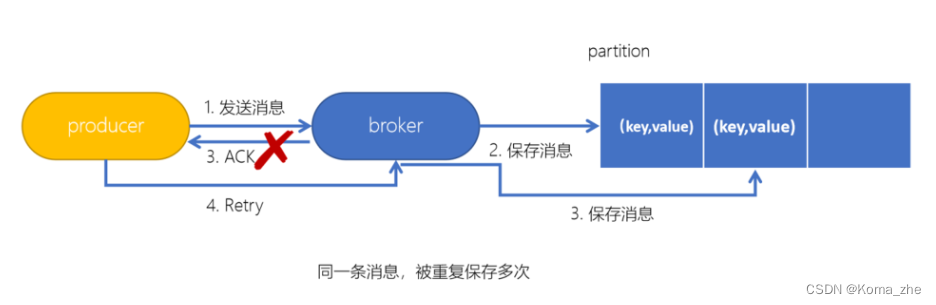
//配置幂等性
props.put("enable.idempotence",true);
幂等性原理
为了实现生产者的幂等性,Kafka引入了 Producer ID(PID)和 Sequence Number的概念。
- PID:每个Producer在初始化时,都会分配一个唯一的PID,这个PID对用户来说,是透明的。
- Sequence Number:针对每个生产者(对应PID)发送到指定主题分区的消息都对应一个从0开始递增的 Sequence Number。