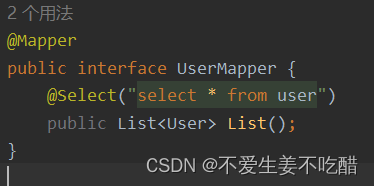
CMU 15-445 -- Concurrency Control Theory - 13
- 引言
- Transactions
- Strawman/Simple System
- Formal Definitions
- Atomicity
- Logging
- Shadow Paging
- Consistency
- Isolation
- Conflicting Operations
- Dependency Graphs(依赖图)
- VIEW SERIALIZABILITY(视图可串行化)
- 小结
- Durability
- 小结
引言
本系列为 CMU 15-445 Fall 2022 Database Systems 数据库系统 [卡内基梅隆] 课程重点知识点摘录,附加个人拙见,同样借助CMU 15-445课程内容来完成MIT 6.830 lab内容。
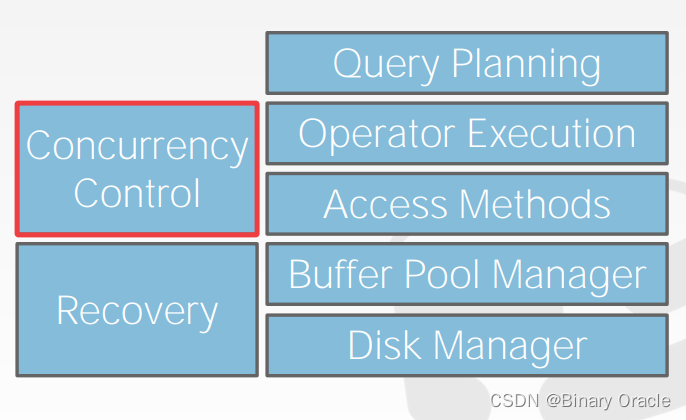
在前面的课程中介绍了 DBMS 的主要模块及架构,自底向上依次是 Disk Manager、Buffer Pool Manager、Access Methods、Operator Execution 及 Query Planning。但数据库要解决的问题并不仅仅停留在功能的实现上,它还需要具备:
- 满足多个用户同时读写数据,即 Concurrency Control,如:
- 两个用户同时写入同一条记录
- 面对故障,如宕机,能恢复到之前的状态,即 Recovery,如:
- 你在银行系统转账时,转到一半忽然停电
Concurrency Control 与 Recovery 都是 DBMSs 的重要特性,它们渗透在 DBMS 的每个主要模块中。而二者的基础都是具备 ACID 特性的 Transactions,因此本节的讨论从 Transactions 开始。
Transactions
用一句白话说,transaction 是 DBMS 状态变化的基本单位,一个 transaction 只能有执行和未执行两个状态,不存在部分执行的状态。
一个典型的 transaction 实例就是:从 A 账户转账 100 元至 B 账户:
- 检查 A 的账户余额是否超过 100 元
- 从 A 账户中扣除 100 元
- 往 B 账户中增加 100 元
Strawman/Simple System
系统中只存在一个线程负责执行 transaction:
-
任何时刻只能有一个 transaction 被执行且每个 transaction 开始执行就必须执行完毕才轮到下一个
-
在 transaction 启动前,将整个 database 数据复制到新文件中,并在新文件上执行改动
- 如果 transaction 执行成功,就用新文件覆盖原文件
- 如果 transaction 执行失败,则删除新文件即可
Strawman System 的缺点很明显,无法利用多核计算能力并行地执行相互独立的多个 transactions,从而提高 CPU 利用率、吞吐量,减少用户的响应时间,但其难度也是显而易见的,获得种种好处的同时必须保证数据库的正确性和 transactions 之间的公平性。 显然我们无法让 transactions 的执行过程在时间线上任意重叠,因为这可能导致数据的永久不一致。于是我们需要一套标准来定义数据的正确性。
Formal Definitions
Database: A fixed set of named data objects (e.g., A, B, C, …) Transaction: A sequence of read and write operations (e.g., R(A), W(B), …)
transaction 的正确性标准称为 ACID:
- Atomicity:“all or nothing”
- Consistency: “it looks correct to me”
- Isolation: “as if alone”
- Durability: “survive failures”
Atomicity
Transaction 执行只有两种结果:
- 在完成所有操作后 Commit
- 在完成部分操作后主动或被动 Abort
DBMS 需要保证 transaction 的原子性,即在使用者的眼里,transaction 的所有操作要么都被执行,要么都未被执行。回到之前的转账问题,如果 A 账户转 100 元到 B 账户的过程中忽然停电,当供电恢复时,A、B 账户的正确状态应当是怎样的?— 回退到转账前的状态。如何保证?
Logging
DBMS 在日志中按顺序记录所有 actions 信息,然后 undo 所有 aborted transactions 已经执行的 actions,出于审计和效率的原因,几乎所有现代系统都使用这种方式。
Shadow Paging
transaction 执行前,DBMS 复制相关 pages,让 transactions 修改这些复制的数据,仅当 transaction Commit 后,这些 pages 才对外部可见。现代系统中采用该方式的不多,包括 CouchDB, LMDB。
Consistency
如果 DBMS 在 transaction 开始之前是 consistent,那么在执行完毕后也应当是 consistent。Transaction consistency 是 DBMS 必须保证的事情。
Isolation
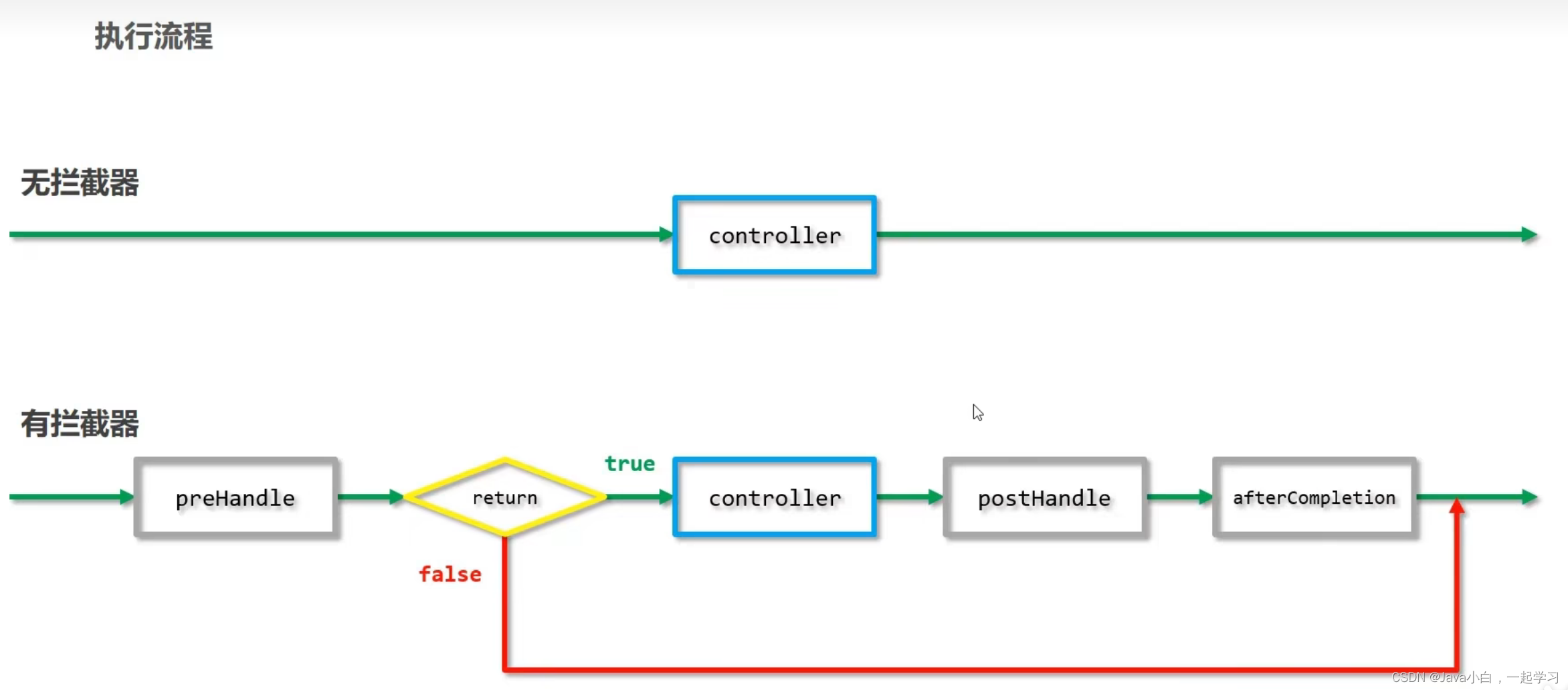
用户提交 transactions,不同 transactions 执行过程应当互相隔离,互不影响,每个 transaction 都认为只有自己在执行。但对于 DBMS 来说,为了提高各方面性能,需要恰如其分地向不同的 transactions 分配计算资源,使得执行又快又正确。这里的 “恰如其分” 的定义用行话来说,就是 concurrency control protocol,即 DBMS 如何认定多个 transactions 的重叠执行方式是正确的。总体上看,有两种 protocols:
- Pessimistic:不让问题出现,将问题扼杀在摇篮之中
- Optimistic:假设问题很罕见,一旦问题出现了再行处理
举例如下:假设 A, B 账户各有 1000 元,当下有两个 transactions:
- T1:从 A 账户转账 100 元到 B 账户
- T2:给 A、B 账户存款增加 6% 的利息
// T1
BEGIN
A = A - 100
B = B + 100
COMMIT
BEGIN
A = A * 1.06
B = B * 1.06
COMMIT
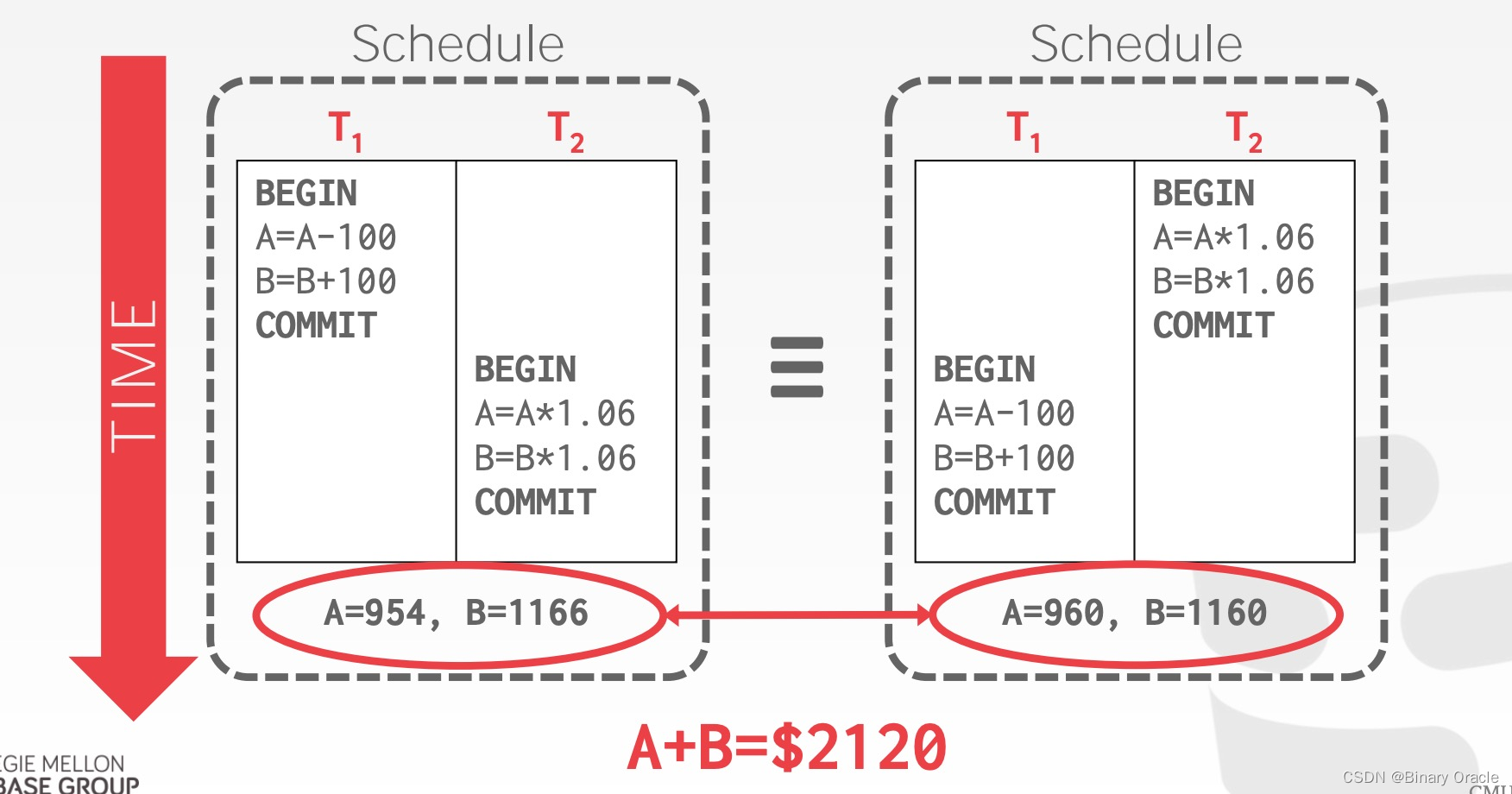
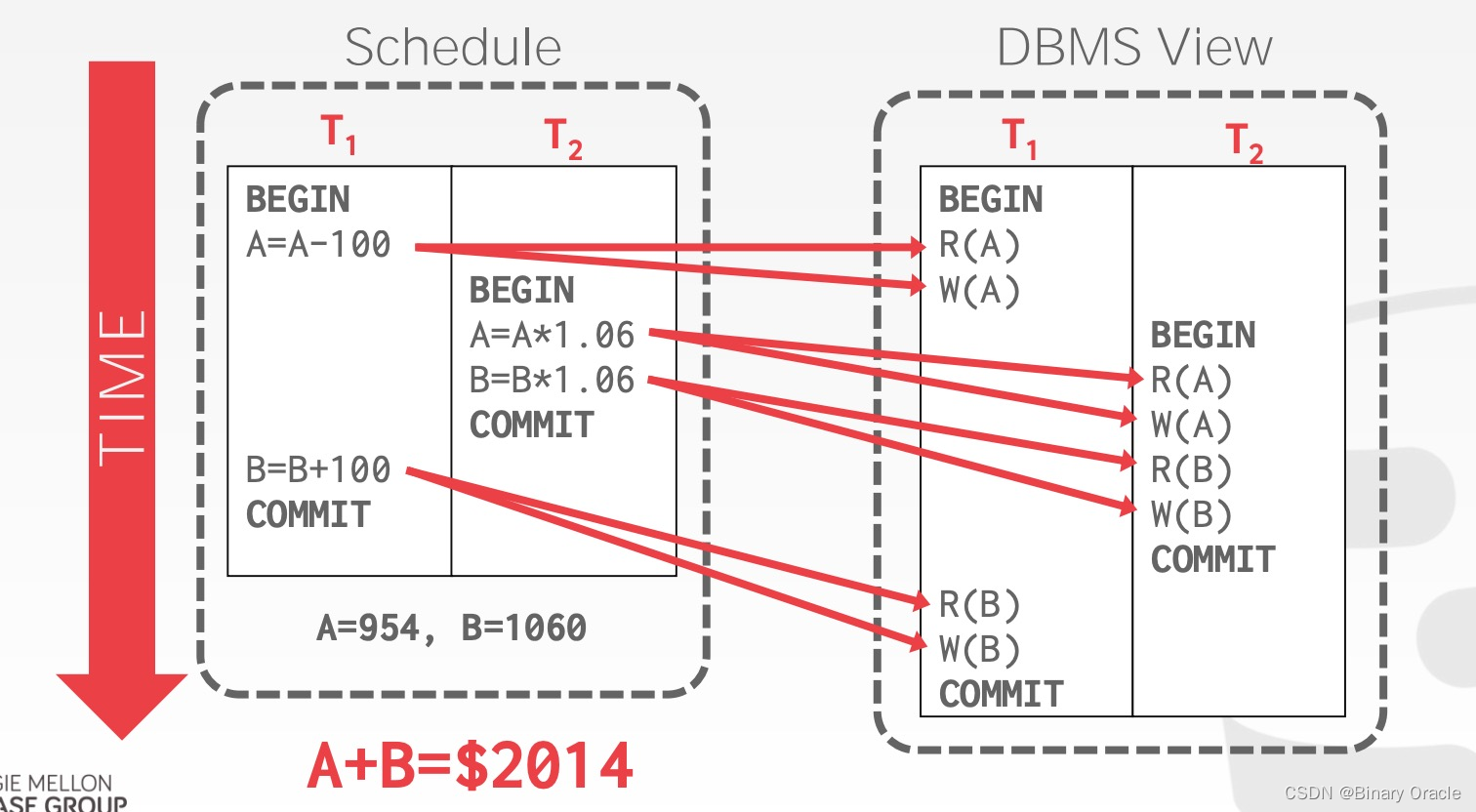
那么 T1、T2 发生后,可能的合理结果应该是怎样的?
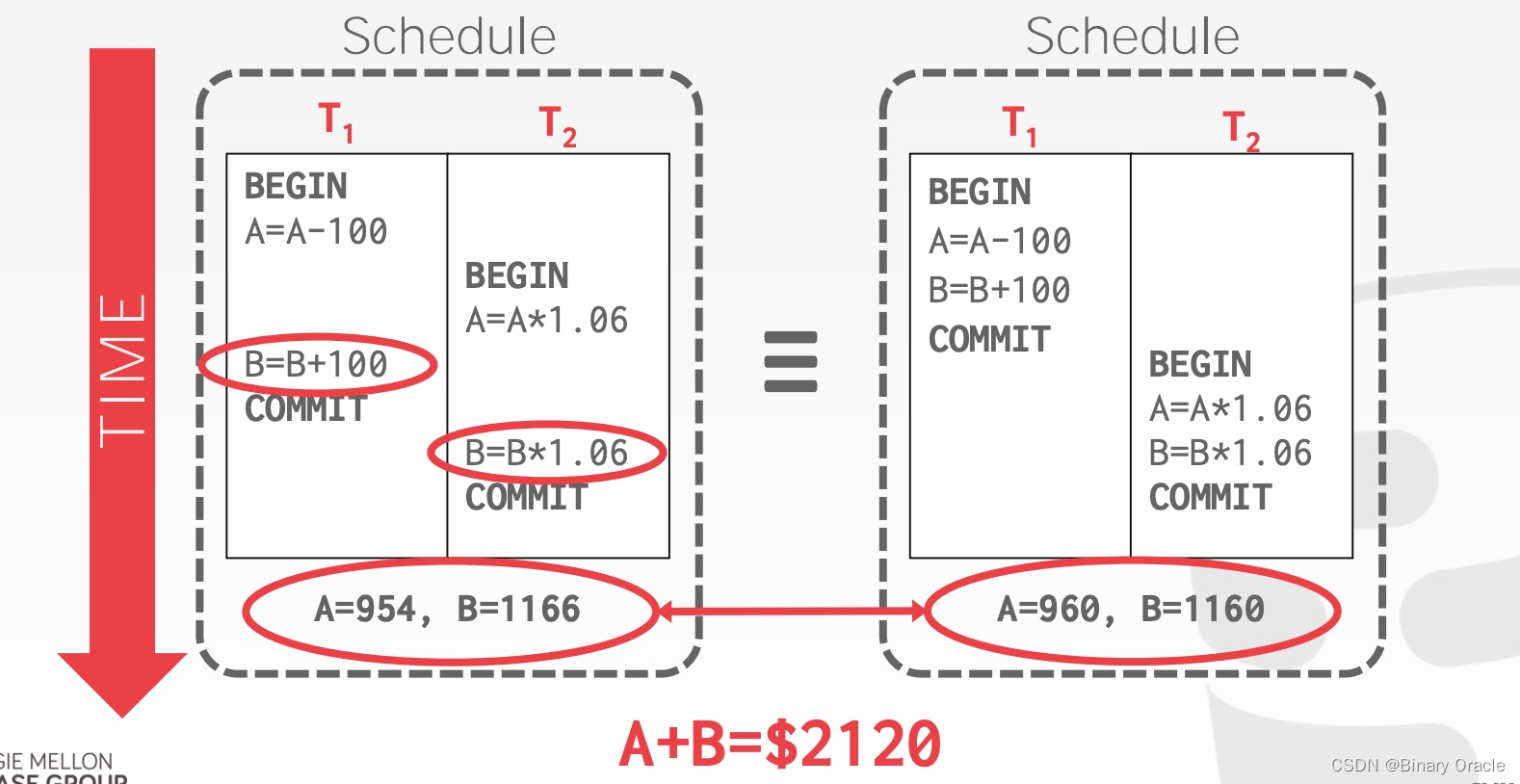
尽管有很多种可能,但 T1、T2 发生后,A + B 的和应为 2000 * 1.06 = 2120 元。DBMS 无需保证 T1 与 T2 执行的先后顺序,如果二者同时被提交,那么谁先被执行都是有可能的,但执行后的净结果应当与二者按任意顺序分别执行的结果一致,如:
- 先 T1 后 T2:A = 954, B = 1166 => A+B = 2120
- 先 T2 后 T1:A = 960, B = 1160 => A+B = 2120
执行过程如下图所示:
当一个 transaction 在等待资源 (page fault、disk/network I/O) 时,或者当 CPU 存在其它空闲的 Core 时,其它 transaction 可以继续执行,因此我们需要将 transactions 的执行重叠 (interleave) 起来。
Example 1 (Good)
Example 2 (Bad)
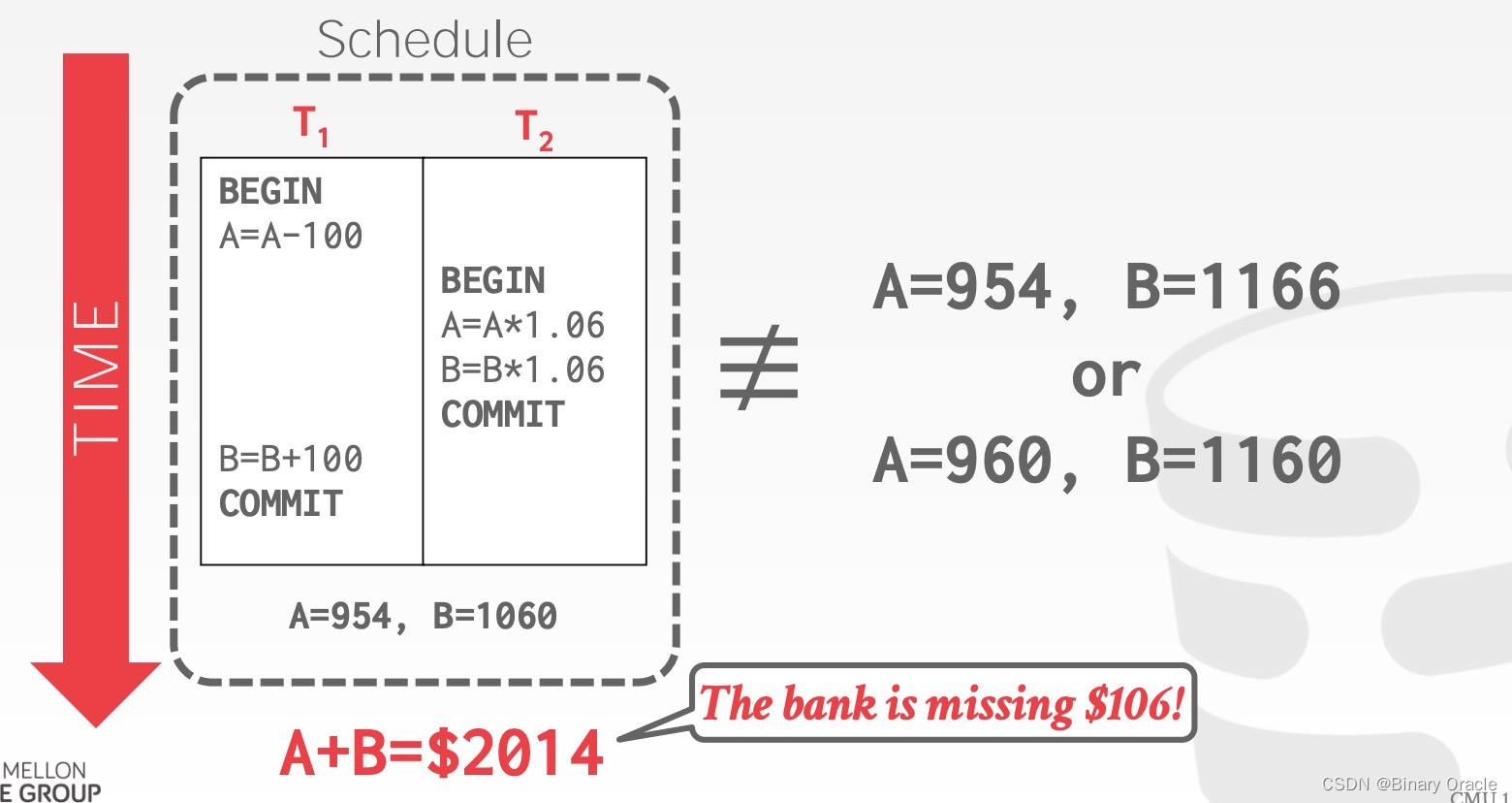
从 DBMS 的角度分析第二个例子:
- A = A - 100 => R(A), W(A)
- …
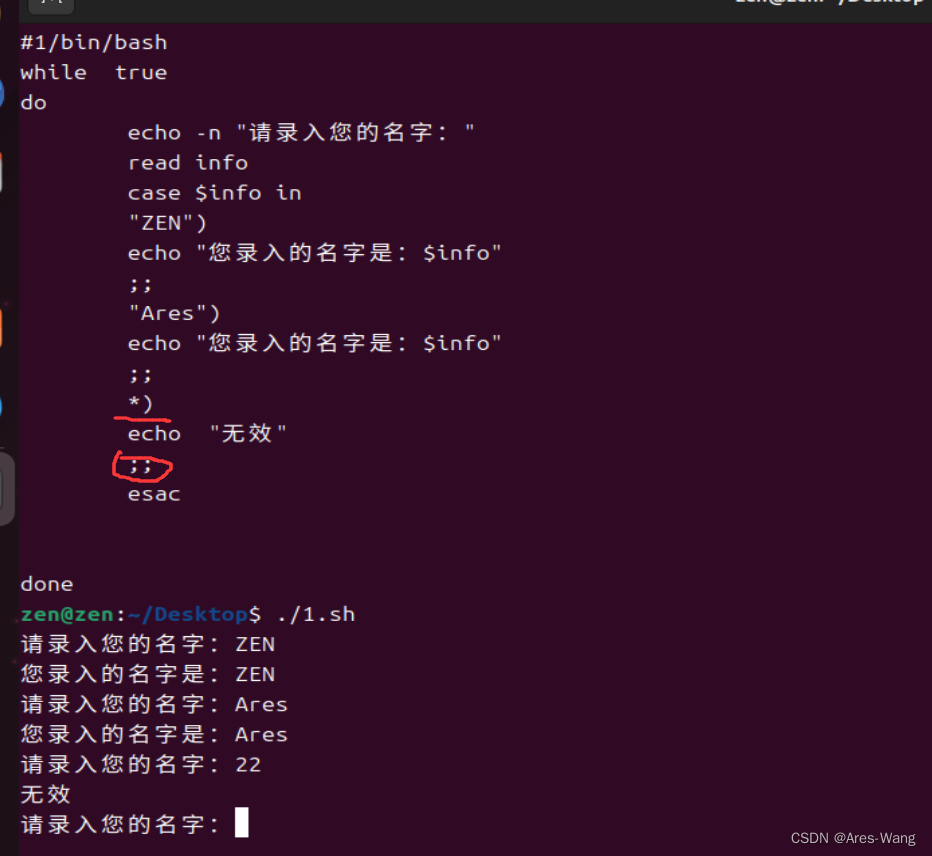
如何判断一种重叠的 schdule 是正确的?
If the schedule is equivalent to some serial execution
这里明确几个概念:
- Serial Schedule(串行调度):在数据库中,Serial Schedule 是指所有事务之间没有时间重叠的调度。每个事务都会依次执行,直到完成,然后才轮到下一个事务执行。因此,Serial Schedule 保证了事务的顺序执行,不会发生并发冲突。
- Equivalent Schedules(等价调度):对于任意数据库的初始状态,如果两个调度分别执行后所达到的数据库状态完全相同,那么称这两个调度是等价的。换句话说,无论执行哪个等价调度,最终的数据库状态都是一样的。
- Serializable Schedule(可串行化调度):如果一个调度的效果与某种串行执行(Serial Execution)的效果相同,那么称该调度是可串行化的。在可串行化调度中,虽然事务可能会有时间重叠,但它们的执行顺序和结果与某个串行调度的执行结果相同。可串行化调度保持了事务之间的并发一致性,避免了并发执行可能导致的问题。
Conflicting Operations
在对 schedules 作等价分析前,需要了解 conflicting operations。当两个 operations 满足以下条件时,我们认为它们是 conflicting operations:
- 来自不同的 transactions
- 对同一个对象操作
- 两个 operations 至少有一个是 write 操作
可以穷举出这几种情况:
- Read-Write Conflicts (R-W)
- Write-Read Conflicts (W-R)
- Write-Write Conflicts (W-W)
Read-Write Conflicts/Unrepeatable Reads
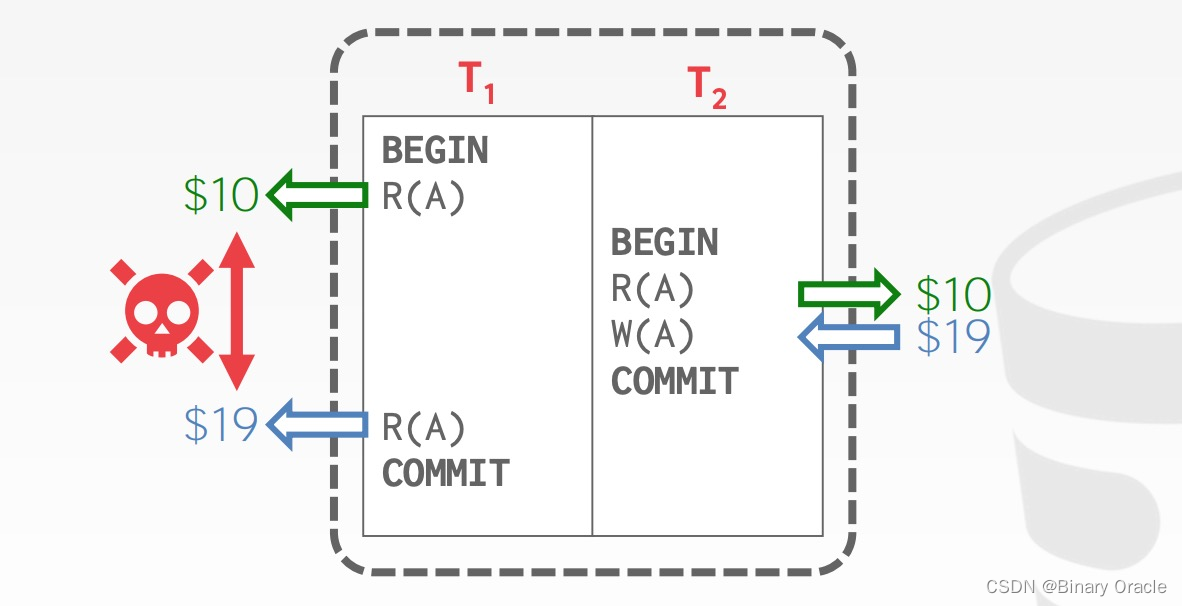
Write-Read Conflicts/Reading Uncommitted Data/Dirty Reads
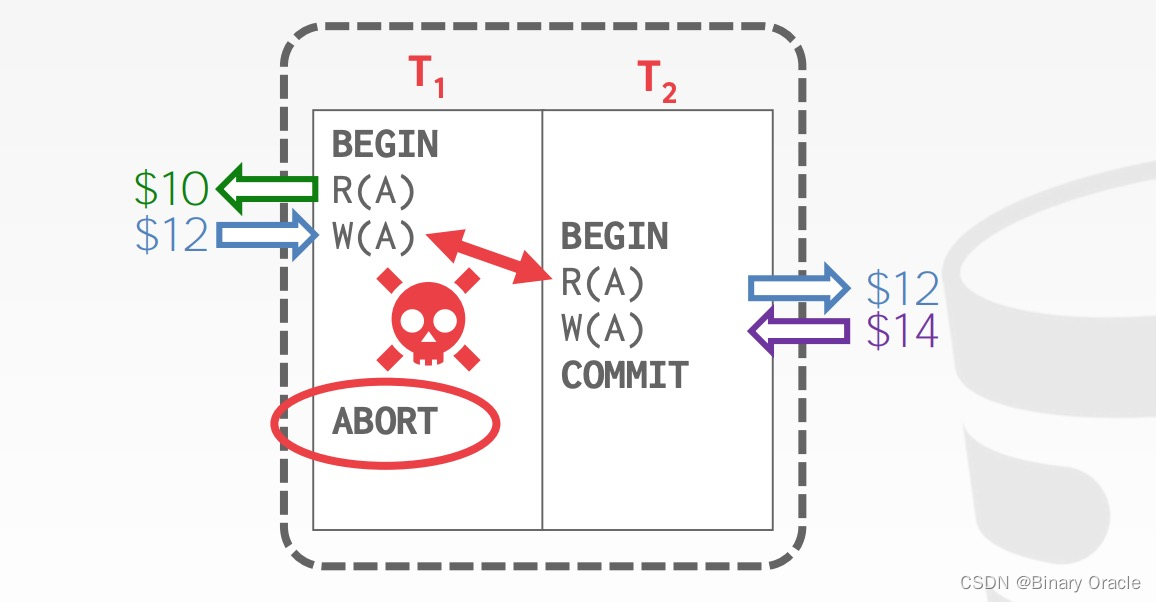
Write-Write Conflicts/Overwriting Uncommitted Data
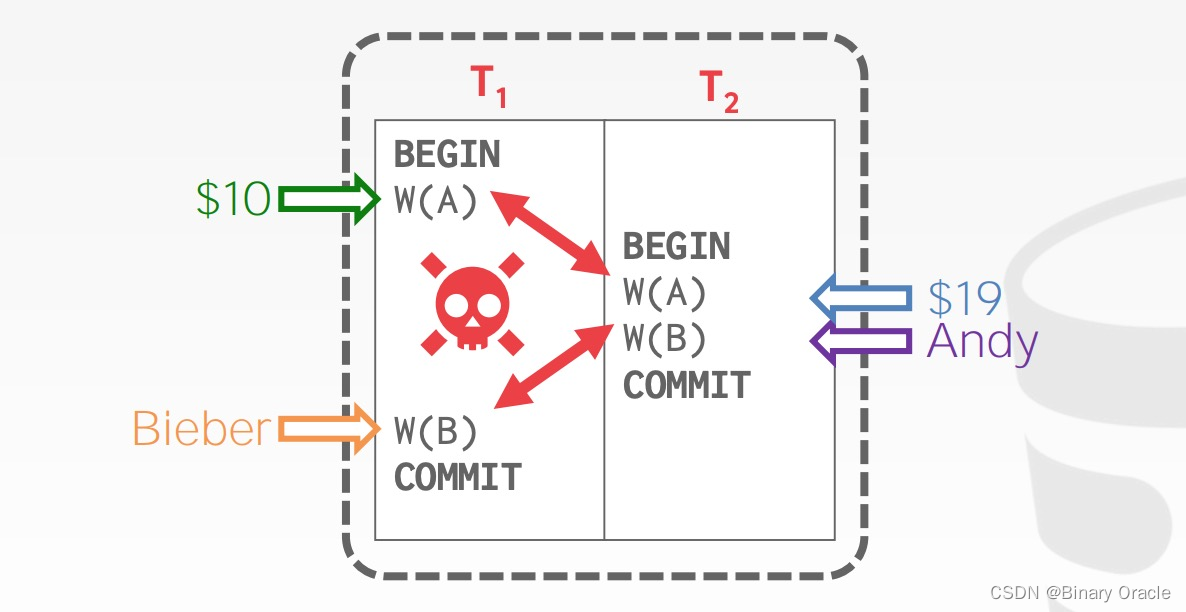
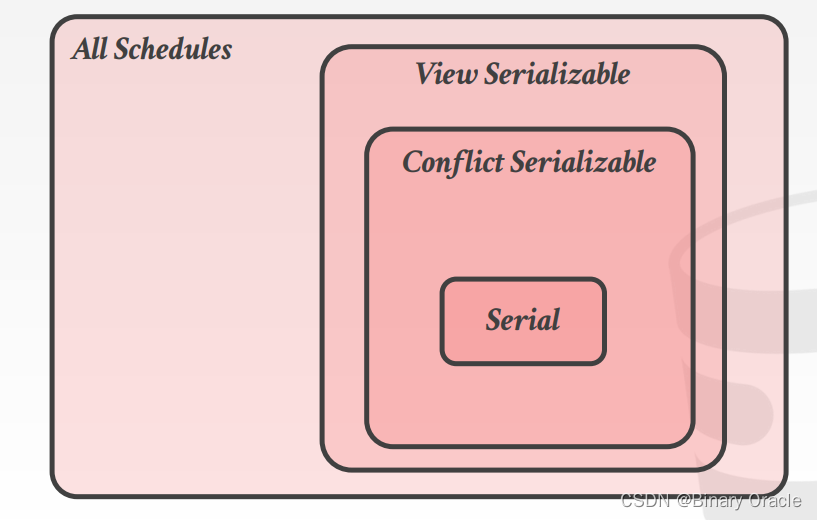
从以上例子可以理解 serializability 对一个 schedule 意味着这个 schedule 是否正确。serializability 有两个不同的级别:
- Conflict Serializability (Most DBMSs try to support this):
- 两个 schedules 在 transactions 中有相同的 actions,且每组 conflicting actions 按照相同顺序排列,则称它们为 conflict equivalent
- 一个 schedule S 如果与某个 serial schedule 是 conflict equivalent,则称 S 是 conflict serializable
- 如果通过交换不同 transactions 中连续的 non-conflicting operations 可以将 S 转化成 serial schedule,则称 S 是 conflict serializable
冲突可串行化(Conflict Serializability):这是一种较为宽松的可串行化概念。如果我们有两个调度,它们包含相同的操作(同样的事务)并且这些操作之间可能发生冲突(比如一个事务读取了另一个事务写入的数据),但它们的操作顺序是一样的,那么我们称它们是冲突等价的。如果一个调度与某个串行调度的操作顺序冲突等价,那么我们说这个调度是冲突可串行化的。
- View Serializability (No DBMS can do this)
视图可串行化(View Serializability):这是一种较为严格的可串行化概念。如果一个调度不仅与某个串行调度的操作顺序冲突等价,还要保持事务读写操作的顺序和数据库初始状态到最终状态的读写结果一样,那么我们称它是视图可串行化的。
例 1:将 conflict serializable schedule S 转化为 serial schedule
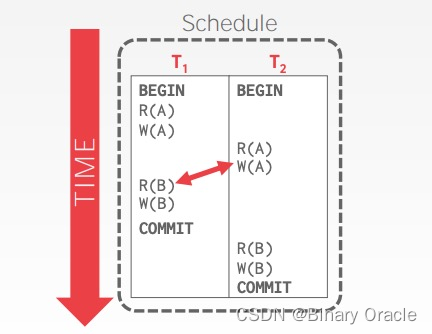
R(B) 与 W(A) 不矛盾,是 non-conflicting operations,可以交换它们
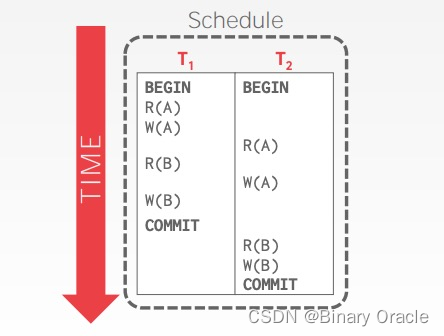
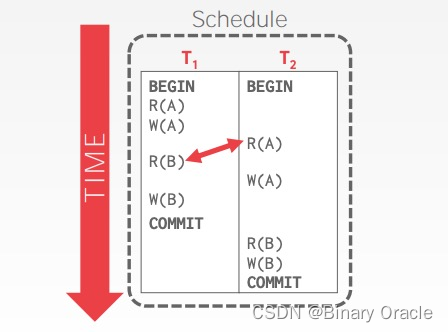
R(B) 与 R(A) 是 non-conflicting operations,交换它们
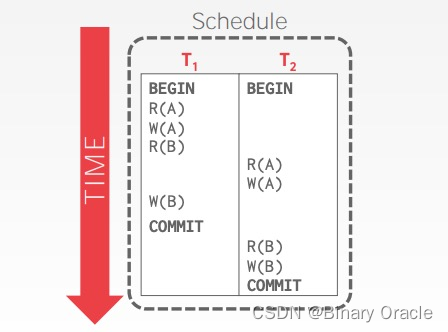
依次类推,分别交换 W(B) 与 W(A),W(B) 与 R(A) 就能得到:
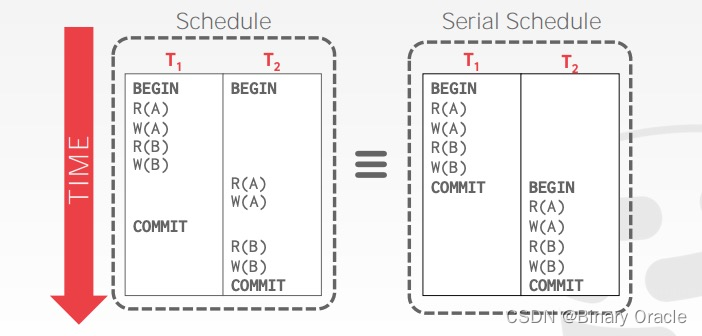
因此 S 为 conflict serializable。
例 2:S 无法转化成 serial schedule

由于两个 W(A) 之间是矛盾的,无法交换,因此 S 无法转化成 serial schedule。
上文所述的交换法在检测两个 transactions 构成的 schedule 很容易,但要检测多个 transactions 构成的 schedule 是否 serializable 则显得别扭。有没有更快的算法来完成这个工作?
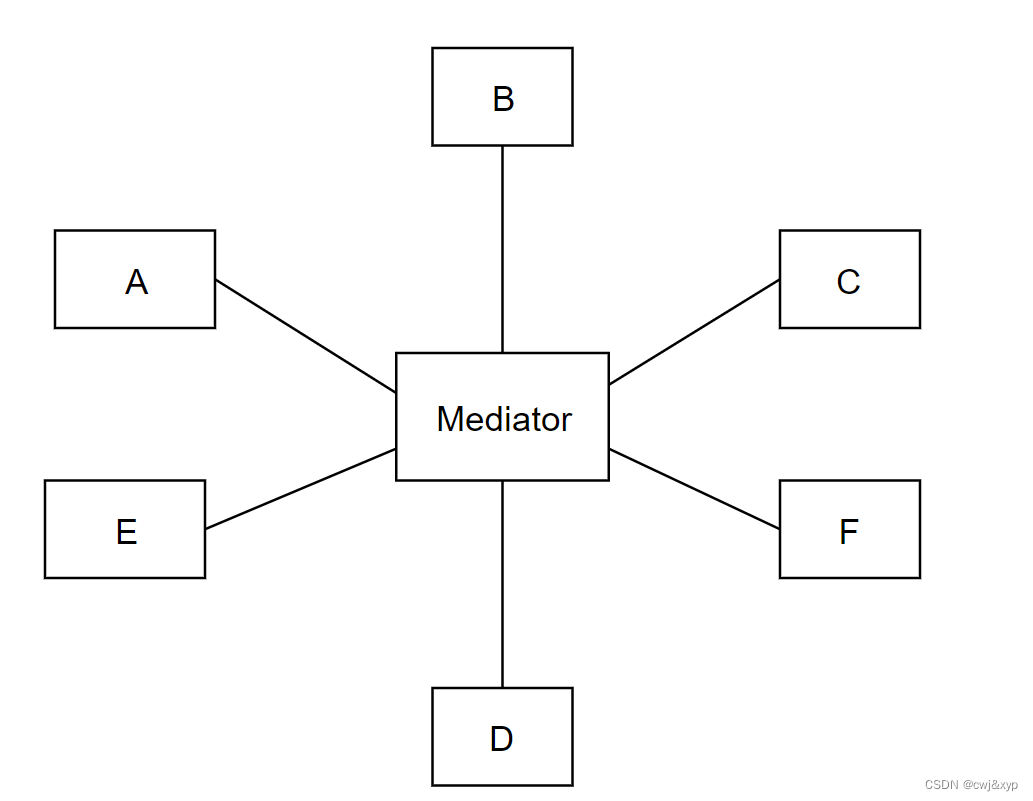
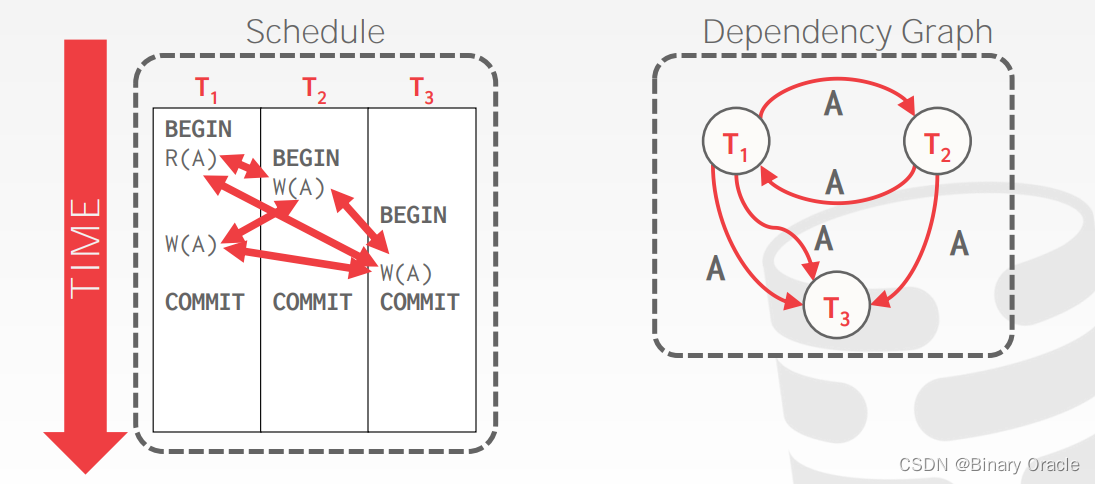
Dependency Graphs(依赖图)
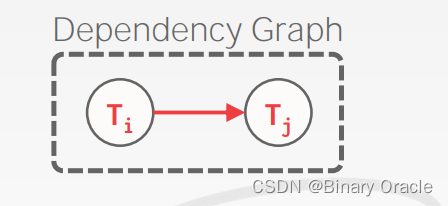
“Dependency Graph” 或称为 “Precedence Graph”(前序图),是用于判断调度是否具有冲突可串行化特性的一种图形表示方法。
简要解释如下:
-
每个图中的节点表示一个事务(Ti 代表事务 i)。
-
如果事务 Ti 中的某个操作 Oi 与事务 Tj 中的某个操作 Oj 冲突,并且 Oi 在调度中出现在 Oj 之前,那么就在图中从 Ti 指向 Tj 画一条边。操作之间的冲突是指它们涉及相同的数据项,并且至少其中一个是写操作。
-
这个图是有向无环图(DAG),即不包含任何环路。
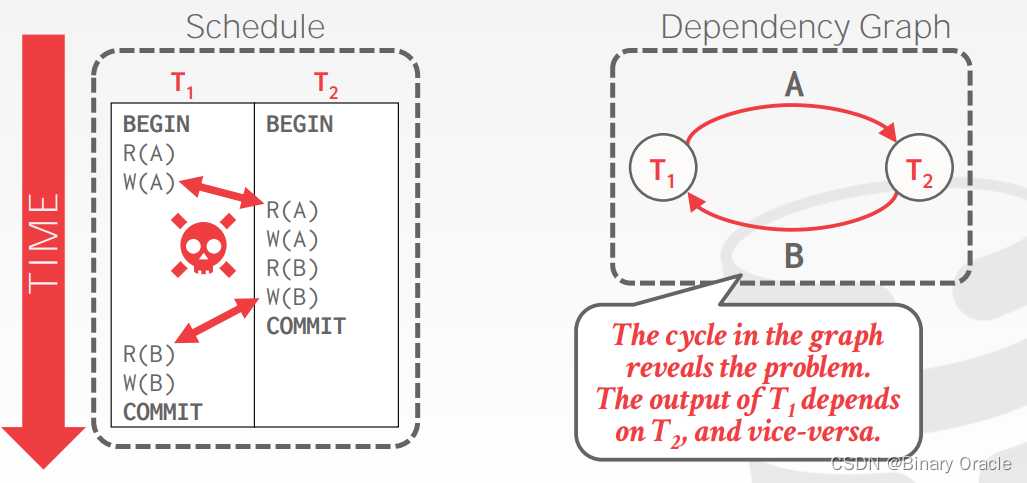
通过构建依赖图,我们可以更清楚地看到事务之间的依赖关系,进而判断调度是否满足冲突可串行化特性。如果依赖图是一个有向无环图,那么这个调度是冲突可串行化的,因为它可以被转换成一个等价的串行调度。如果依赖图中存在环路,那么这个调度是不可串行化的,意味着存在冲突或竞争条件,可能会导致并发执行问题。
在实际的数据库系统中,依赖图可以用于选择合适的并发控制策略,例如基于锁(Lock-based)或时间戳(Timestamp-based)的并发控制方法。这些方法可以帮助确保事务之间的依赖关系得到正确处理,从而保证数据库的一致性和可靠性。当依赖图是有向无环图时,这个调度是冲突可串行化的,也就是满足并发控制的要求。
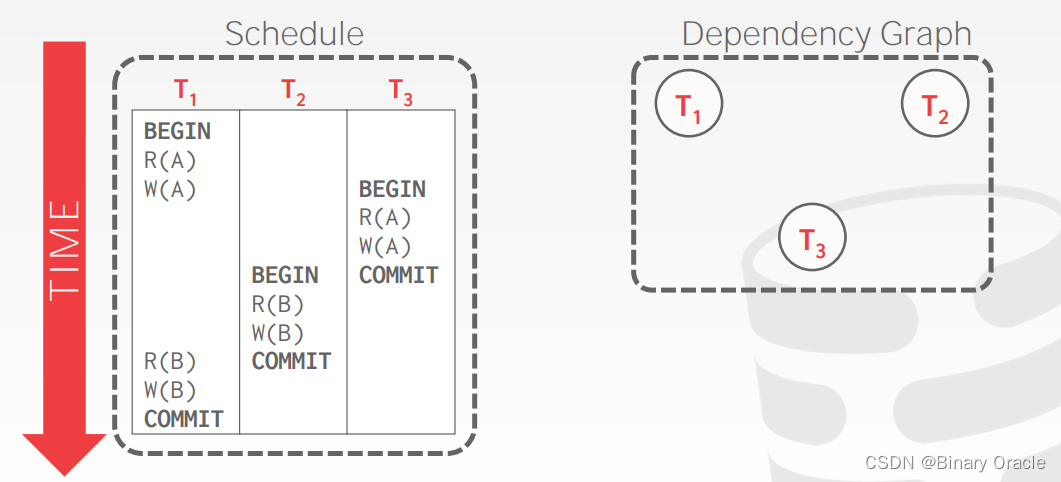
例子一: 两个事务
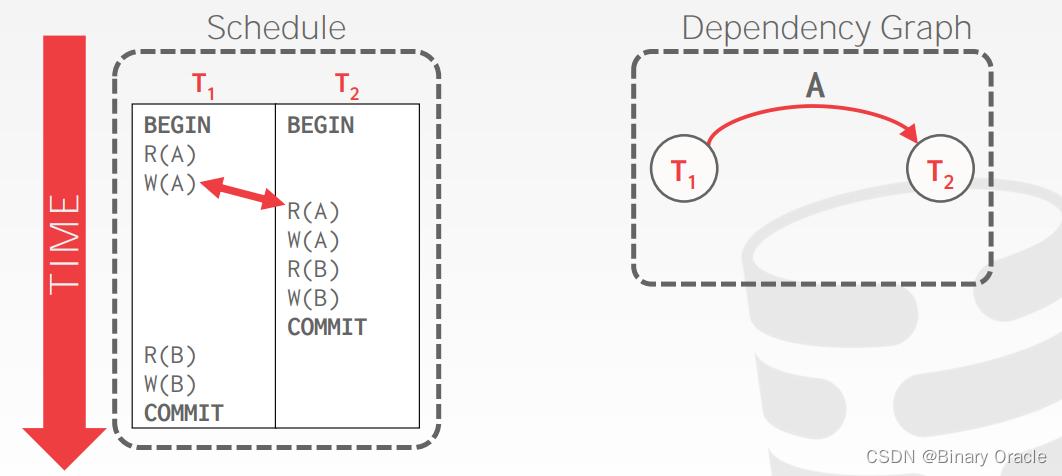
例子二: 多个事务
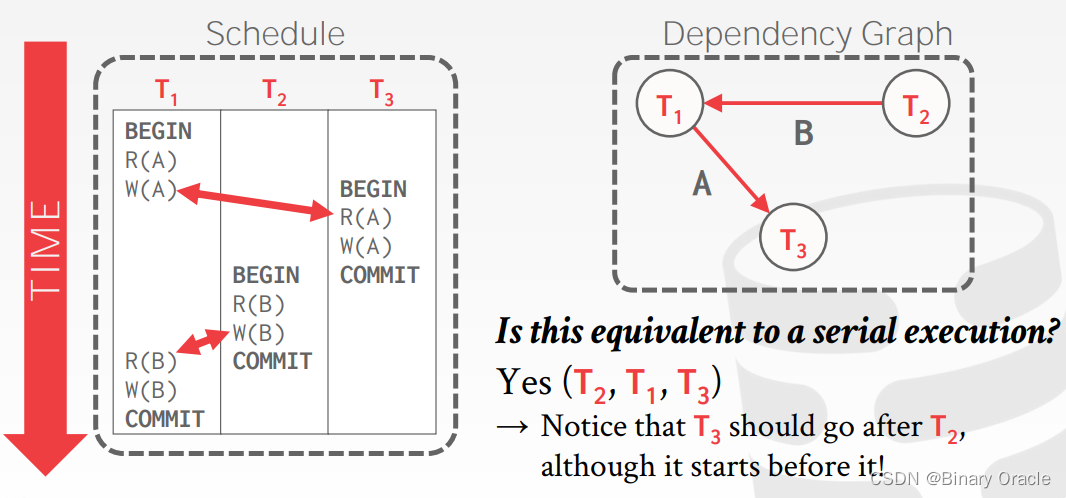
例子三: 不一致性分析
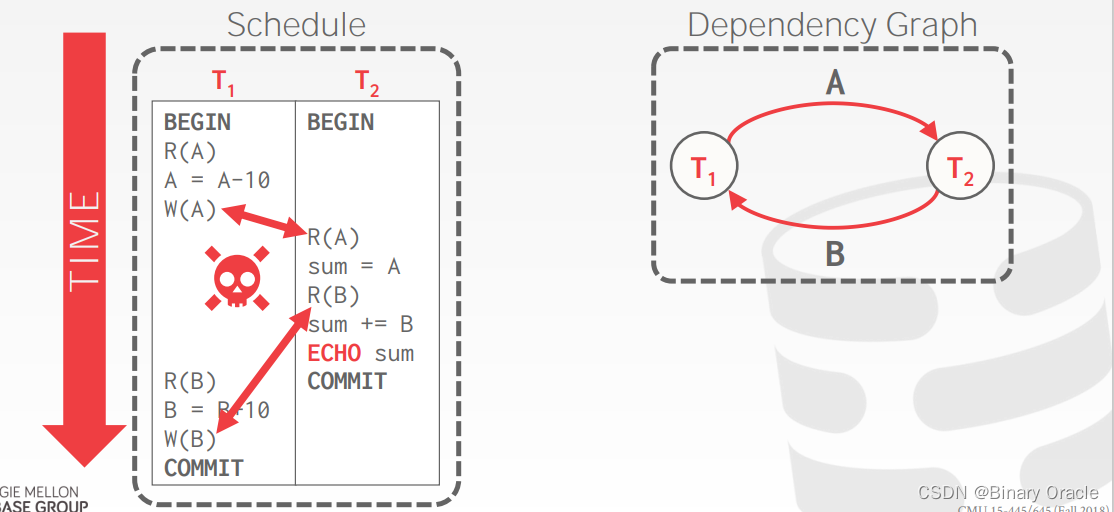
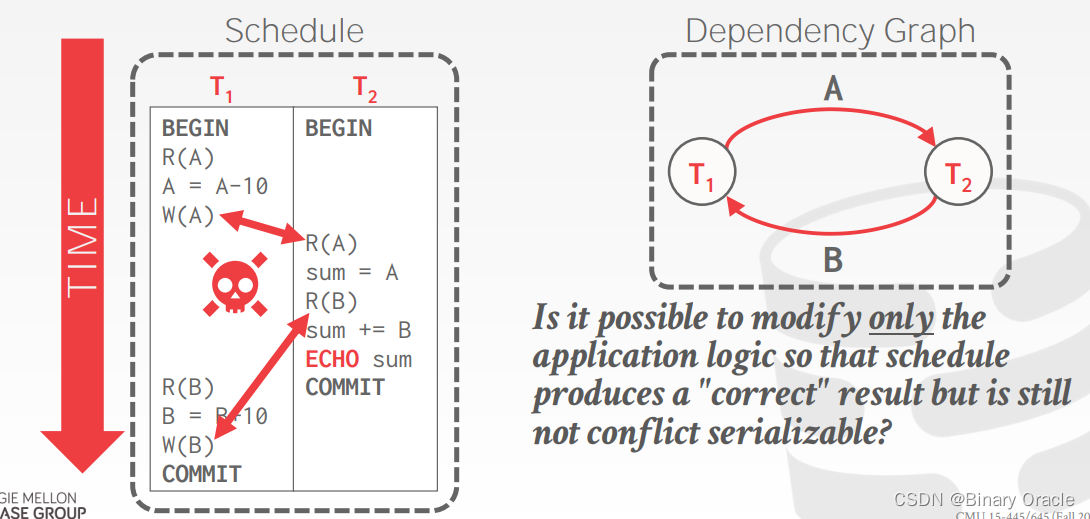
VIEW SERIALIZABILITY(视图可串行化)
视图可串行化是一种较为宽松的串行化概念,用于判断两个调度是否具有相同的视图,从而决定它们是否是等价的。两个调度 S1 和 S2 视图等价,当且仅当它们满足以下条件:
- 如果事务 T1 在调度 S1 中读取了数据项 A 的初始值,那么在调度 S2 中,T1 也必须读取数据项 A 的初始值。
- 如果事务 T1 在调度 S1 中读取了由事务 T2 写入的数据项 A 的值,那么在调度 S2 中,T1 也必须读取由事务 T2 写入的数据项 A 的值。
- 如果事务 T1 在调度 S1 中写入了数据项 A 的最终值,那么在调度 S2 中,T1 也必须写入数据项 A 的最终值。
简而言之,视图可串行化要求两个调度对于每个数据项的读取和写入操作都是一致的,即它们具有相同的“视图”。如果两个调度是视图等价的,那么它们在数据的读取和写入方面产生的结果是相同的。
与冲突可串行化相比,视图可串行化更加宽松,因为它只考虑了对数据项读写结果的一致性,而没有涉及到冲突关系。在实际数据库管理系统中,视图可串行化通常较为容易实现,但可能导致更多的并发冲突。因此,在选择并发控制方法时,需要根据具体的应用场景来权衡决策。
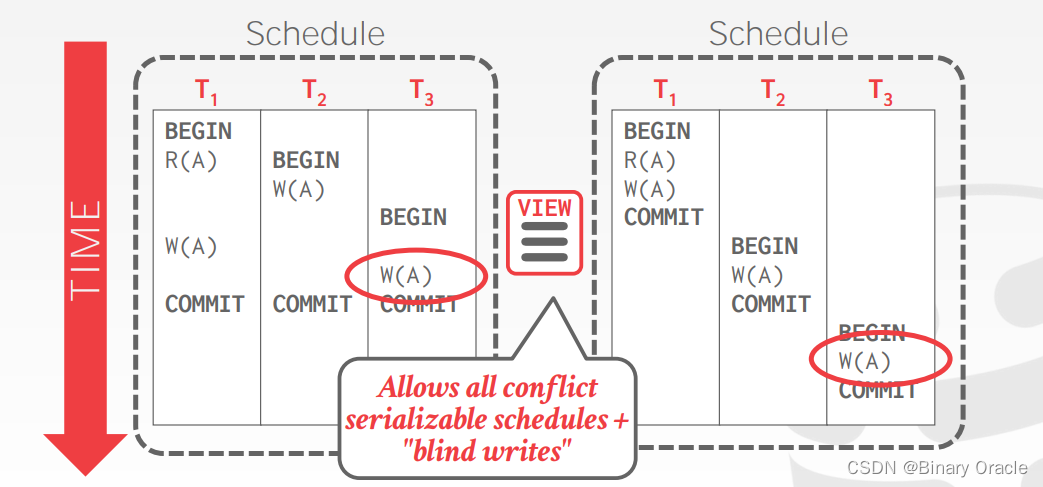
视图可串行化允许所有冲突可串行化的调度,并且还允许一种特殊情况下的“盲目写入”(Blind Writes)。
在视图可串行化中,"盲目写入"是指在一个事务中进行写操作,而不考虑该数据项之前的值或者是否与其他事务的写操作冲突。这种写操作可能会覆盖其他事务的写入结果,导致数据的不一致性。
在某些情况下,视图可串行化可能允许这样的“盲目写入”情况发生,因为它主要关注事务对于数据读写结果的一致性,而不过多考虑冲突关系。但这种情况下需要注意,盲目写入可能导致数据丢失或错误,并且可能会影响应用程序的正确性。
视图可串行化比冲突可串行化允许更多的调度。但是,视图可串行化很难高效地强制执行。两种定义都不能包含您认为“可串行化”的所有调度。这是因为它们不理解操作或数据的含义。
小结
在实践中,数据库管理系统通常支持冲突可串行化,因为它可以高效地实现。冲突可串行化是一种较为严格的串行化概念,它确保了数据库操作的正确性和一致性,同时具有较高的性能和并发能力。
Durability
持久性是指一旦事务提交,其所做的更改应该是永久性的,即在数据库中得到持久保存。没有发生"torn updates"(部分写入)或来自失败事务的更改。
“torn updates” 指的是当两个或多个事务同时尝试写入同一数据项的时候,可能会导致数据丢失或损坏的情况。持久性保证了在并发写入的情况下,数据库系统会正确处理事务的提交,以避免这种问题。
此外,持久性还确保了来自已经失败的事务的更改不会永久保存到数据库中。如果一个事务执行过程中出现了错误或失败,它的所有更改应该被撤销,不应该对数据库的状态产生影响。
为了实现持久性,数据库管理系统(DBMS)可以使用两种主要技术:日志记录(Logging)和影子页(Shadow Paging)。
-
日志记录:在日志记录中,DBMS会将事务执行过程中的所有更改操作写入日志文件。只有当事务成功提交后,DBMS才会将这些更改应用到数据库的实际数据文件中。如果发生故障或失败,DBMS可以根据日志进行恢复,确保数据库的一致性。
-
影子页:在影子页技术中,数据库会为每个事务维护一个副本(影子页)的数据库。事务执行期间,所有更改操作都在影子页上进行。只有当事务成功提交后,影子页的内容才会被拷贝到实际的数据库页上,从而实现持久性。
这些技术确保数据库系统具有可靠的事务处理和数据持久性,从而保证了数据的完整性和一致性。
小结
- 原子性(Atomicity):原子性确保事务的所有操作要么全部发生,要么全部不发生。
- 一致性(Consistency):一致性指的是在数据库开始时,如果每个事务都是一致的(遵守预设的业务规则和约束),那么在所有事务执行结束后,数据库将保持一致状态。
- 隔离性(Isolation):隔离性确保事务的执行在并发情况下是相互隔离的,一个事务的执行不会影响其他事务的执行。
- 持久性(Durability):持久性确保一旦事务提交成功,其效果将是永久性的,不会因为系统故障或崩溃而丢失。
并发控制是用于管理多个事务在多用户数据库环境中并发执行的关键机制。它确保事务可以并行执行而不相互干扰,同时保持数据的一致性和完整性。
关于并发控制的一些关键点:
-
自动管理:DBMS中的并发控制是自动的。系统会自动处理锁定和解锁请求,并安排不同事务的操作,以防止冲突并确保正确的执行顺序。
-
锁定机制:常见的并发控制方法之一是使用锁定机制,在执行读取或写入操作之前,事务会请求并获得数据项的锁定。这些锁定阻止其他事务同时访问相同的数据,从而避免数据不一致和冲突。
-
可串行化:并发控制确保事务的最终执行结果等效于按某种顺序依次执行它们,称为可串行化。这意味着数据库的最终状态与事务按照一定的顺序串行执行的结果是相同的,尽管它们可能已经并发执行。
恢复则是在面对系统崩溃或硬件故障等故障时,确保数据的持久性和一致性。恢复机制保证即使出现故障,数据库也可以恢复到一致的状态,使用日志记录或影子页等技术。
并发控制和恢复共同确保数据库系统的正确性、可靠性和健壮性,尤其在高并发和关键性环境下,多个用户同时访问数据库时尤为重要。
本节对应教材PDF