梳理一下之前理解不太清楚的知识点,重点内容可能会再拆出来单独研究。
原书链接:Index of /
一、 数据组织
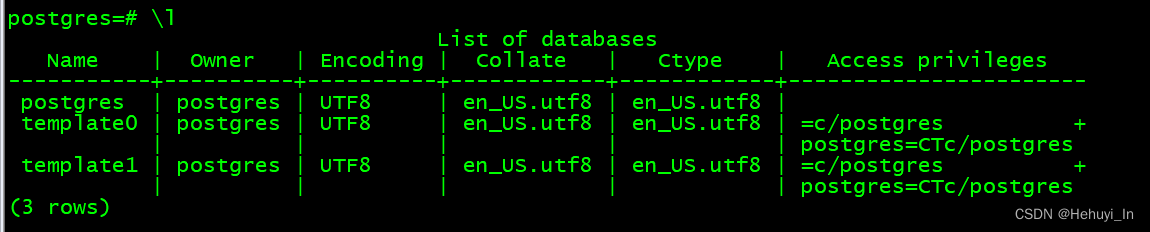
1. pg系统库
- template0:用于从逻辑备份还原,或创建不同字符集的数据库,不可以修改
- template1:真正的模板库,修改之后创建其他业务库时会以其为模板
- postgres:常规db,可以自行决定是否用作业务库(一般不用)
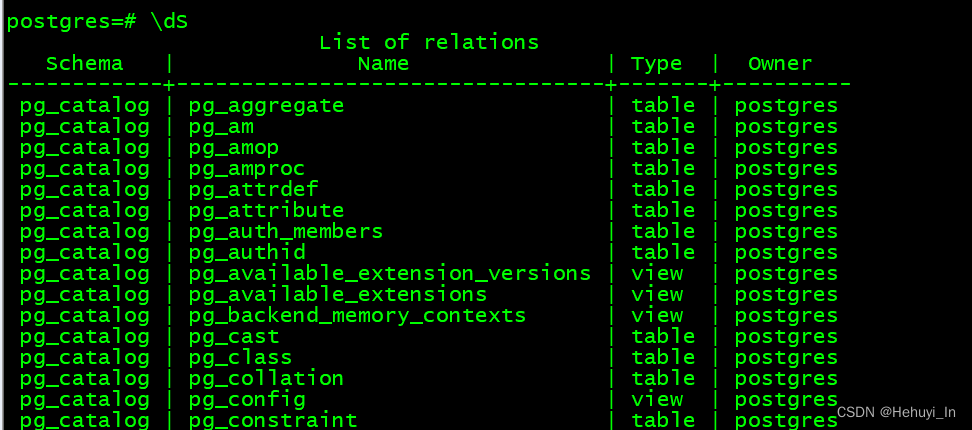
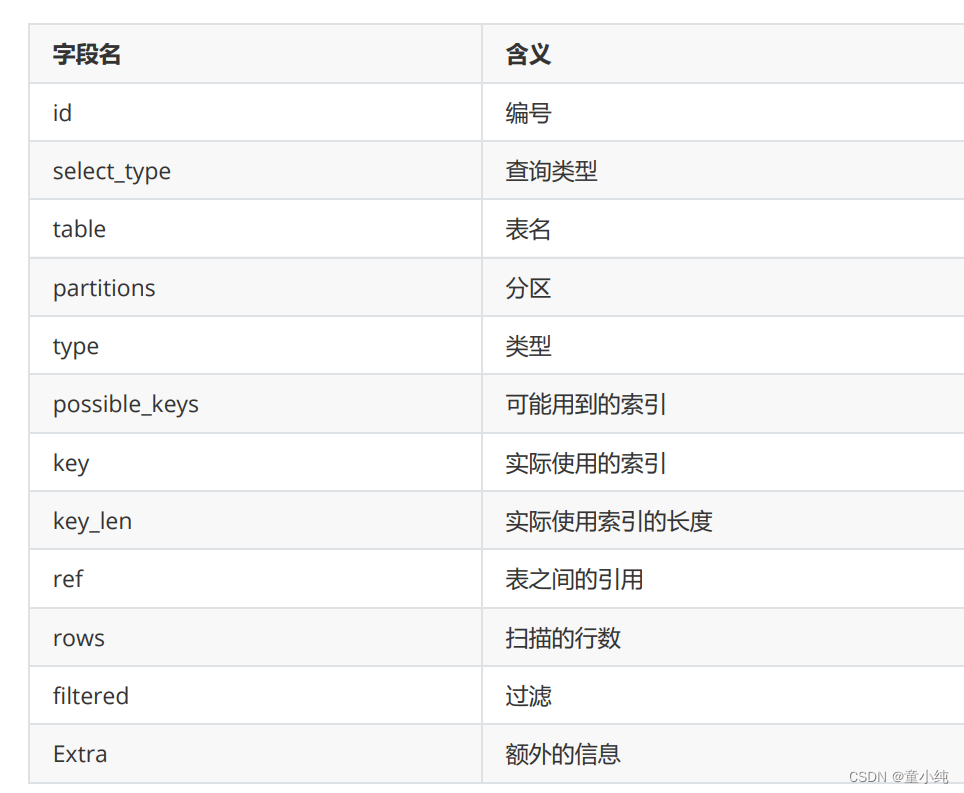
2. 系统表(system catalog)
- 均以pg_开头
- 部分系统表不属于任何数据库,但所有数据库均可访问它们
3. Schema
命名空间,在逻辑上相当于DB中的一个目录。
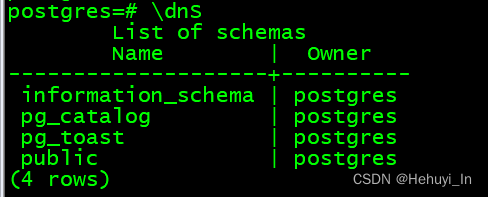
pg自带以下schema:
- public:若无特殊设置,则为用户对象默认schema
- pg_catalog:系统表的schema
- information_schema:系统表的替代视图
- pg_toast:用于toast对象
- pg_temp:用于临时表
search_path变量用于设置搜索路径,pg_catalog和pg_temp 这两个schema总是包含在其中(因此所有库中都能查到系统表和临时表),但默认不显示。
4. 表空间
如果说schema是逻辑上的目录,表空间则是物理上一个真正的目录,它与DB可以是多对多的关系。主要用于冷热数据分层,可以将旧数据放在单独表空间并移到低性能磁盘。
- pg_default:默认表空间,位于$PGDATA/base目录
- pg_global:存储共享系统表(system catalog)的表空间,位于$PGDATA/global目录
- 当用户创建表空间时,pg会自动在$PGDATA下创建同名目录,可以移到其他位置。

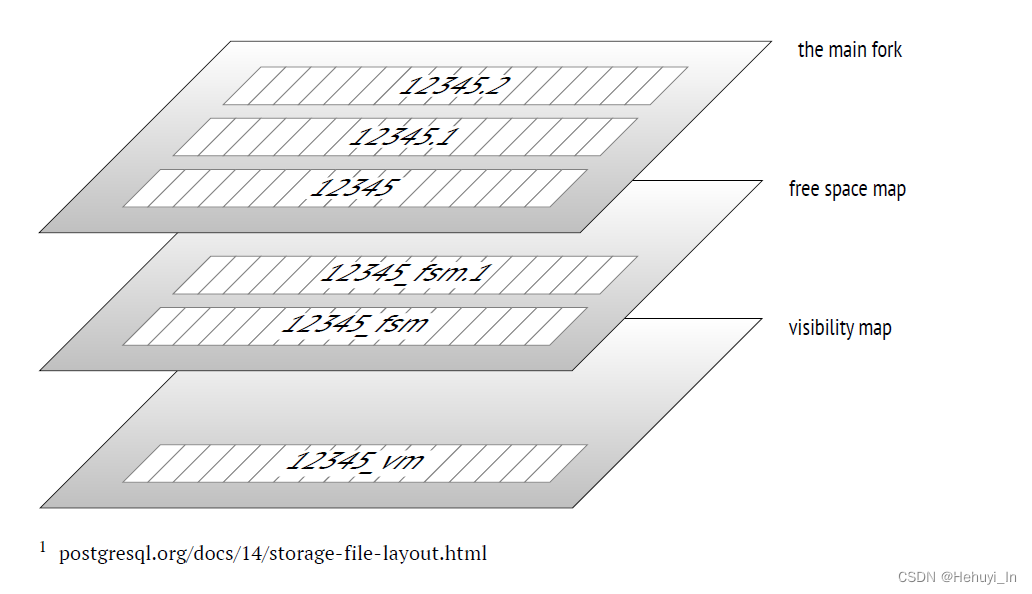
5. 数据文件与分支
- 主文件:存储实际数据,以一串数字为文件名(对应pg_class. relfilenode字段,注意不一定是oid),默认如果超过1G,则为扩展出xxx.1,xxx.2这种文件
- 空闲空间映射文件:fsm文件,保存页中可用空间的映射,在新数据插入时快速定位可用位置。既用于表也用于索引。
- 可见性映射文件:vm文件,如果一个页中的所有元组都是可见的(或者均已冻结),vm文件中会将两个对应标志位设为1。后续可以跳过对这些页的vacuum,freeze操作,提升性能,另外在执行计划中也可以使用 index-only scans,更加高效。只用于表不用于索引。
- 初始文件:init文件,仅对unlogged table可用
测试创建unlogged table
CREATE UNLOGGED TABLE t(a int);
INSERT INTO t VALUES (1);
SELECT pg_relation_filepath('t');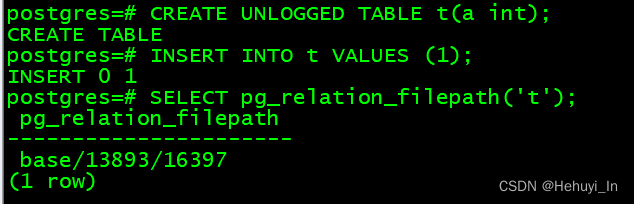
二、 地平线
1. Transaction Horizon
各进程快照中的xmin(在快照创建时,最旧的未提交事务id)。
作用:所有比它更早的事务(xid<xmin),要么已提交要么已回滚,因此均可见(就是快照xmin的定义)。
如果事务中没有活跃快照(例如已提交读,在各语句执行间隔时),horizon会被定义成它自己的事务id(如果有分配)。
查询方法
可以根据pid查询各进程的backend_xmin
SELECT backend_xmin FROM pg_stat_activity where pid= pg_backend_pid();
2. Database Horizon
自然,就是所有Transaction Horizon中最小的。
作用:所有比它更早的事务(xid<xmin),要么已提交要么已回滚,因此均可见,可以vacuum。
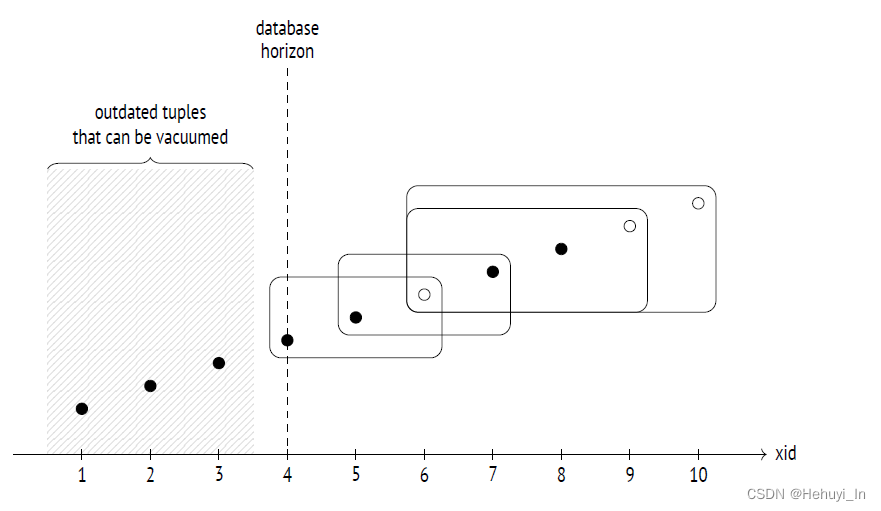
长事务会hold database horizon,导致大量旧数据无法vacuum。这里说的长事务即包括打开事务后不提交/回滚,也包括慢SQL导致事务不能关闭。
三、 快照相关
1. 系统表与快照
系统表不可以通过快照去访问,它必须获取最新的数据,避免在sql操作时用到旧的表定义或约束。
例如下面的例子,虽然可重复读在事务开启时获取快照,但还是能查到新增后的字段
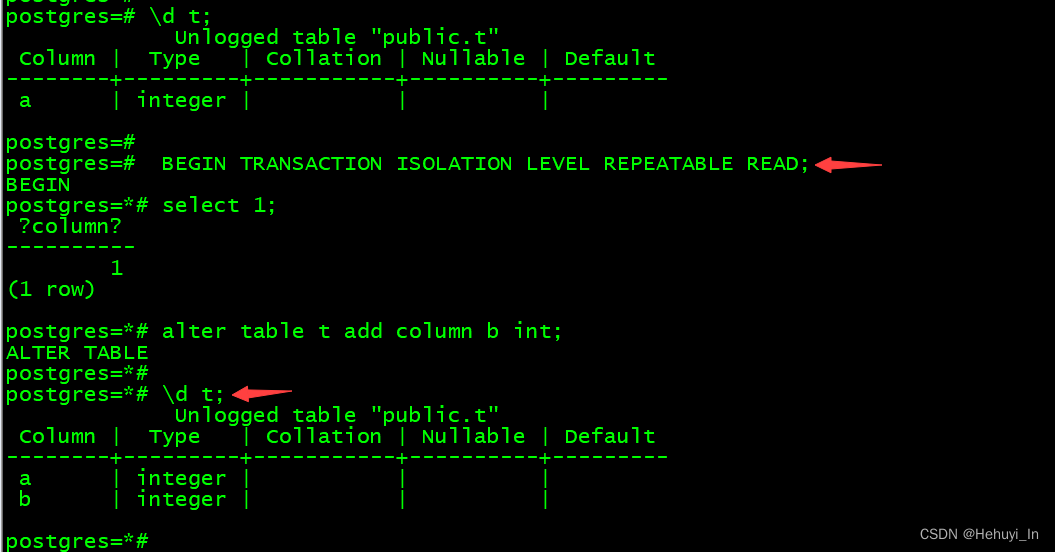
2. 数据导出与快照
如果pg_dump使用并行模式导出数据,所有进程必须读取相同快照的数据。
为确保所有事务读取到相同数据,必须制定快照导出机制。
pg_export_snapshot函数可以返回快照id,这个id可以被传送到其他事务
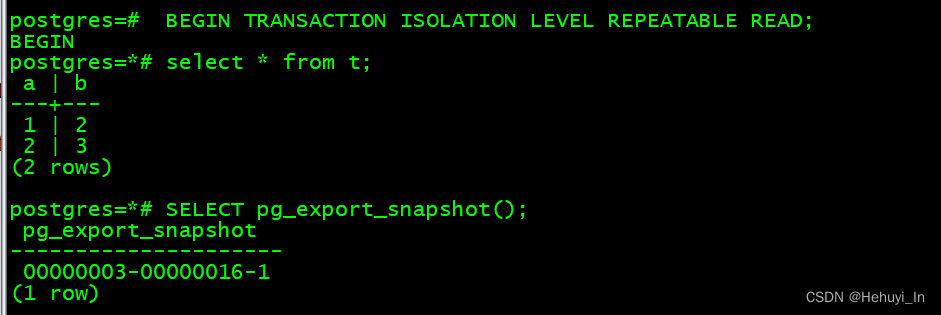
在执行第一个语句之前,其他事务会用set transaction snapshot命令导入该快照
测试导入命令
delete from t;
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
select * from t;
set transaction snapshot '00000003-00000016-1';
select * from t;可以看到快照导入后,之前删除的数据恢复了

注意隔离级别不能低于可重复读(因为已提交读级别会用自己的快照)
四、 Page pruning 与 HOT update
1. Page pruning
当一个页在被读取或更新时,在某些场景下,pg可以进行快速页清理和剪枝(cleanup and pruning)。
- 前面的update操作没能在该页找到足够空间存放新元组
- 该页存放的数据大于fillfactor参数的值(类似oracle pctfree)
Page pruning删除在所有快照中均已不可见的元组(超出database horizon),删除的范围不会超过该页,执行速度非常快。指向被清理元组的指针依旧保留,因为它们可能会被索引用到。
因此,vm和fsm文件均不会更新,被清理出来的空间仅用于update,不用于insert。
由于pruning可以在页被读取时执行,因此任何select均可能引起页修改操作,这也需要延迟设置标记位的原因之一。
CREATE TABLE hot(id integer, s char(2000)) WITH (fillfactor = 75);
CREATE INDEX hot_id ON hot(id);
CREATE INDEX hot_s ON hot(s);
INSERT INTO hot VALUES (1, 'A');
UPDATE hot SET s = 'B';
UPDATE hot SET s = 'C';
UPDATE hot SET s = 'D';
SELECT * FROM heap_page('hot',0);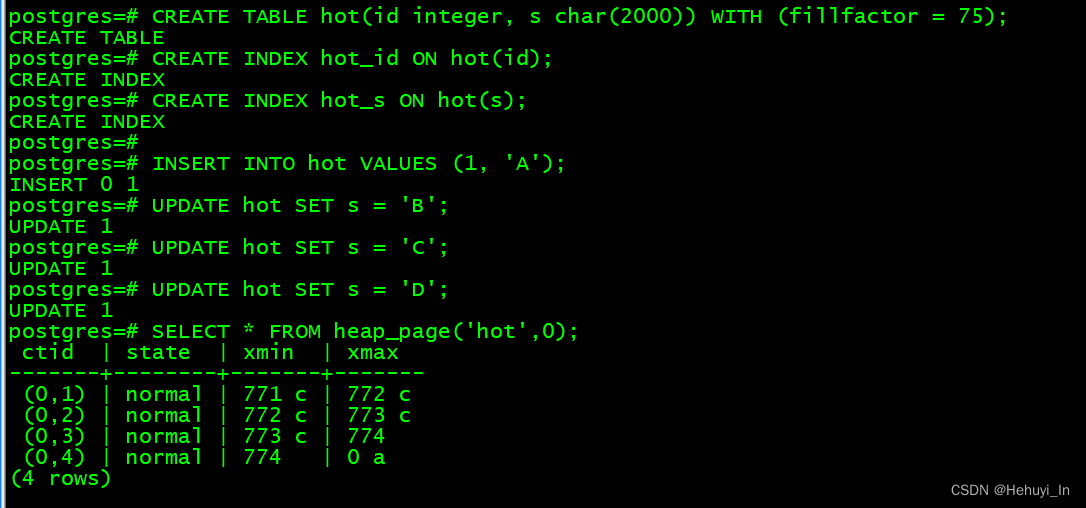
正如预期,我们恰好超过了fillfactor阈值,从pagesize和upper可以看出来(75%的pagesize是6144 bytes)。因为是反向的,upper越小,空闲空间越少。

SELECT upper, pagesize FROM page_header(get_raw_page('hot',0));
再次进行更新,当新数据写入时会触发页清理,删除过期数据,同时插入新元组(0,5)。还可以看到,upper变大,空闲空间增加,页中剩余元组移向最高地址。

指向被清理元组的指针依旧保留,因为它们可能会被索引用到。
SELECT * FROM index_page('hot_id',1);
当真正用到该索引时,其状态会被改为dead,避免后续重复访问这些页。
Explain analyze select * from hot where id=1;
2. HOT Update
pg中更新一行时,实际上原数据行并不会被删除,只是插入了一个新行。如果表上有索引,而更新的字段不是索引的键值时,由于新行的物理位置发生了变化,仍然需要更新索引,这将导致性能下降。
如下图,表上有一个索引,其中“索引项n”指向某个数据块的第3行(图画偏了)。

使用HOT技术之后,如果更新后的行与原数据行在同一个数据块内时,原数据行会有一个指针,指向新行,这样就不必更新索引了,当从索引访问到数据行时,会根据这个指针找到新行。
更新第3行后使用HOT技术,索引项仍然指向原数据行(第3行),而第3行原数据行中有一个指针指向新数据行(第6行)
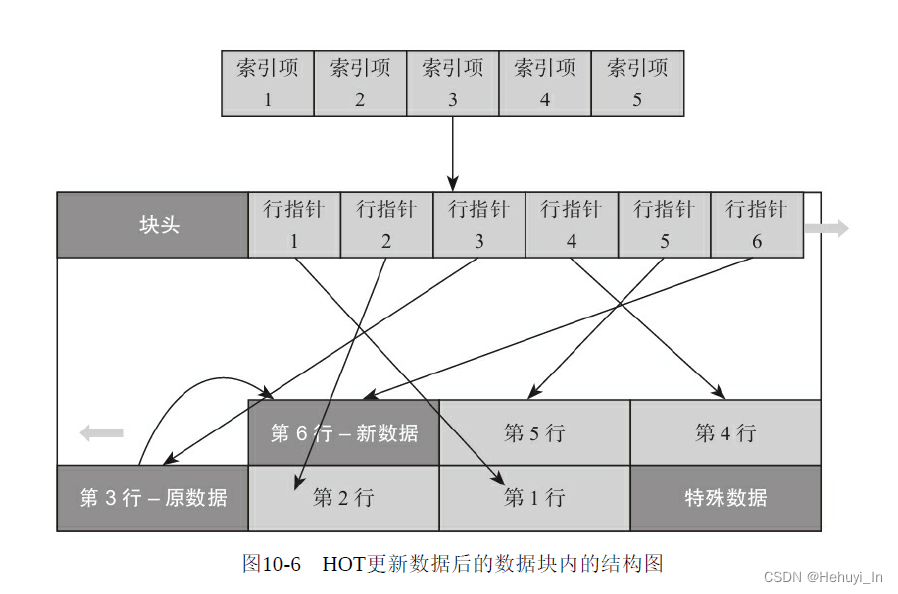
注意,如果原先的数据块中无法放下新行就不能使用HOT技术了,HOT技术中的行之间的指针只能在同一个数据块内,不能跨数据块。所以为了使用HOT技术,应该在数据块中留出较大的空闲空间,可以把表的填充因子fillfactor设置为一个较小值。
truncate前面的hot表并删掉一个索引,更新heap_page函数重新测试
DROP INDEX hot_s;
TRUNCATE TABLE hot;
DROP FUNCTION heap_page(text,integer);
CREATE FUNCTION heap_page(relname text, pageno integer)
RETURNS TABLE(
ctid tid, state text,
xmin text, xmax text,
hhu text, hot text, t_ctid tid
) AS $$
SELECT (pageno,lp)::text::tid AS ctid,
CASE lp_flags
WHEN 0 THEN 'unused'
WHEN 1 THEN 'normal'
WHEN 2 THEN 'redirect to '||lp_off
WHEN 3 THEN 'dead'
END AS state,
t_xmin || CASE
WHEN (t_infomask & 256) > 0 THEN ' c'
WHEN (t_infomask & 512) > 0 THEN ' a'
ELSE ''
END AS xmin,
t_xmax || CASE
WHEN (t_infomask & 1024) > 0 THEN ' c'
WHEN (t_infomask & 2048) > 0 THEN ' a'
ELSE ''
END AS xmax,
CASE WHEN (t_infomask2 & 16384) > 0 THEN 't' END AS hhu,
CASE WHEN (t_infomask2 & 32768) > 0 THEN 't' END AS hot,
t_ctid
FROM heap_page_items(get_raw_page(relname,pageno))
ORDER BY lp;
$$ LANGUAGE sql;开始执行update
INSERT INTO hot VALUES (1, 'A');
UPDATE hot SET s = 'B';
UPDATE hot SET s = 'C';
UPDATE hot SET s = 'D';
SELECT * FROM heap_page('hot',0);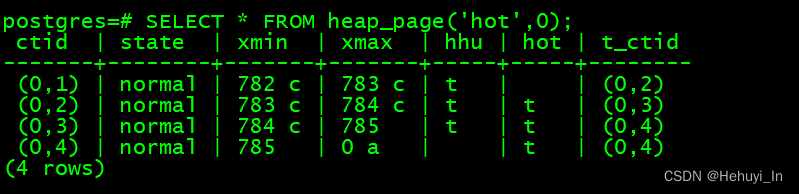
SELECT * FROM index_page('hot_id',1);
3. 两者结合
因为HOT技术不能跨页,也可以想到HOT跟上面的page pruning应该是结合使用的,它可以帮忙清理页中的过期数据。再更新可以看到,数据被清理了。
但明显这个图跟之前有所不同,因为此时页中包含HOT update链,链头必须要保留以供索引查询引用,而其他无需被索引引用的指针则可以释放。

上图中(0,1), (0,2), (0,3)元组均被pruned,(0,1)因为作为链头被保留,(0,2), (0,3)空间则被释放,状态为unused,因为它们已未被指针引用。
Update的最新元组写入原来(0,2)的位置,由t_ctid也可以看出这个元组是最新的,而(0,4)指向(0,2)。所以最终指向顺序是(0,1) -> (0,4) -> (0,2)。
随着更新越来越多,指向也会更复杂,最终又被清理。
UPDATE hot SET s = 'F';
UPDATE hot SET s = 'G';
SELECT * FROM heap_page('hot',0);
指向顺序是(0,1) -> (0,4) -> (0,2) -> (0,3) -> (0,5)
UPDATE hot SET s = 'H';
SELECT * FROM heap_page('hot',0);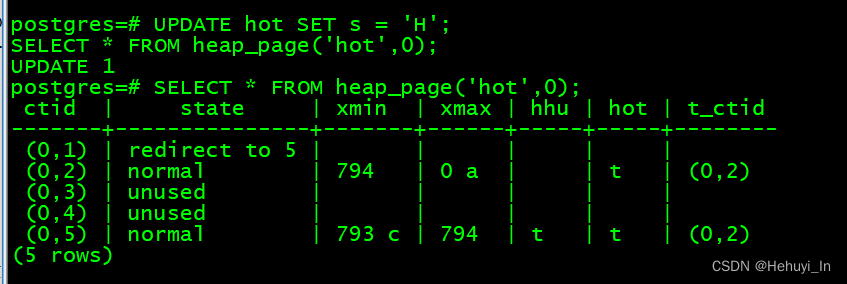
(0,2),(0,3),(0,4)被清理,最新数据插入(0,2),最终指向顺序是(0,1) -> (0,5) -> (0,2) -> (0,3) -> (0,5)。
4. HOT链分裂
如果页已经没有足够空间放新元组,HOT Chain将会分裂,pg必须加一个独立索引项指向新页的元组。
下面使用可重复读隔离级别设置,这样页中的元组就不能被pruned。
BEGIN ISOLATION LEVEL REPEATABLE READ;
SELECT 1;
UPDATE hot SET s = 'I';
UPDATE hot SET s = 'J';
UPDATE hot SET s = 'K';
SELECT * FROM heap_page('hot',0);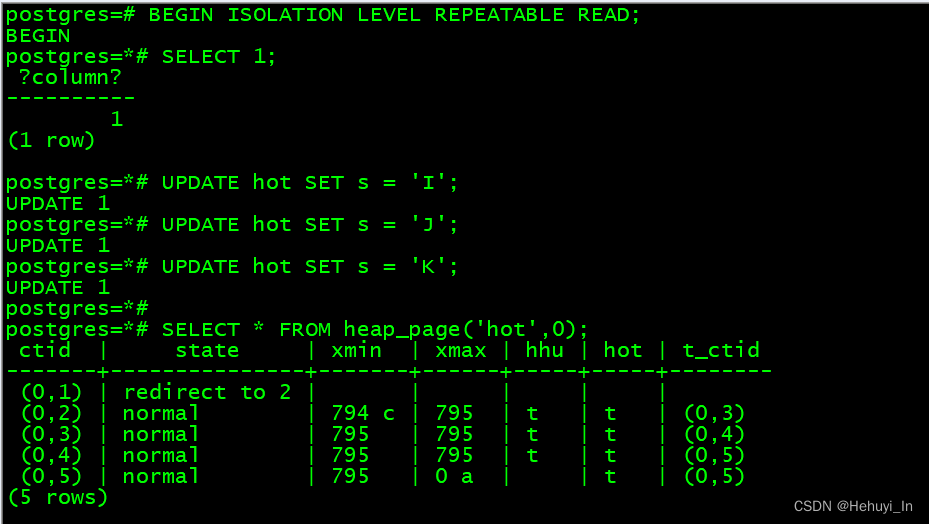
UPDATE hot SET s = 'L';
SELECT * FROM heap_page('hot',0);从最后一条记录指向(1,1)可以看出,它已经用上了下一个数据页。
SELECT * FROM heap_page('hot',1);
SELECT * FROM index_page('hot_id',1);
提交事务,提交后无用元组可以被清理
COMMIT;
UPDATE hot SET s = 'J';
SELECT * FROM heap_page('hot',0);
SELECT * FROM heap_page('hot',1);
SELECT * FROM index_page('hot_id',1);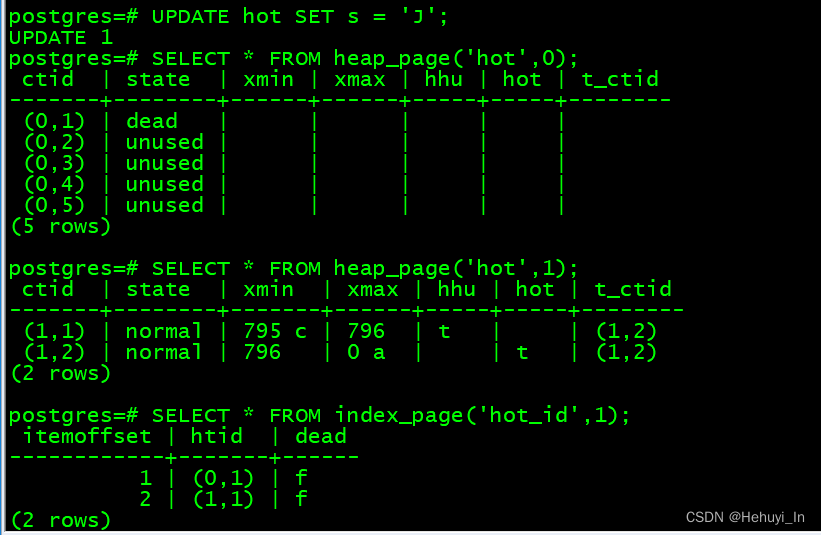
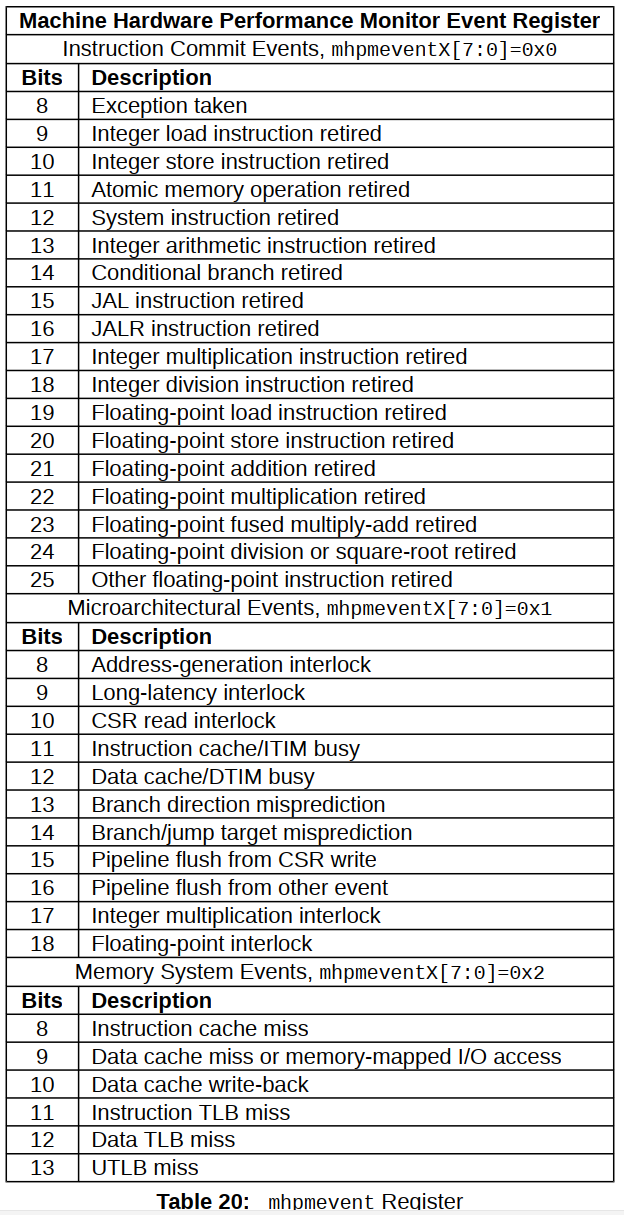
5. Index pruning
前面提到过,page pruning作用范围是单个页,并且不影响索引。不过,索引也有自己的清理机制 Index pruning,作用范围同样是单个页。
Index pruning 发生在插入索引数据到B树时。如果索引页数据过多,单页无法存放,它也会分裂为两个页。索引页分裂后,即使后来它对应的数据项已经都被删除,索引页也无法再合并成一个,长此以往会导致索引的膨胀。因此,在索引页分裂前,及时清理其中的数据也是必要的。
pg会对引用两类元组的索引进行检查和清理:
- 指向死元组的索引项
- 引用相同表、不同版本数据的索引项
下一篇见~
![[附源码]Python计算机毕业设计SSM基于框架的毕业生就业管理系统(程序+LW)](https://img-blog.csdnimg.cn/82c2cc0290f24ab4aa12e4ec864aaef0.png)

![[附源码]计算机毕业设计基于web的建设科技项目申报管理系统Springboot程序](https://img-blog.csdnimg.cn/dc00dcc661e14098bbf71efa71c0f3cf.png)
![[附源码]计算机毕业设计家庭教育appSpringboot程序](https://img-blog.csdnimg.cn/7af6d1215fab41539acff129576f759f.png)