Redis—分布式系统
- 🔎理解分布式
- 🔎分布式—应用服务与数据库服务分离
- 引入更多的应用服务节点
- 理解负载均衡
- 引入更多的数据库服务节点
- 缓存
- 分库分表
- 微服务
- 🔎常见概念
- 应用(Application) / 系统(System)
- 模块(Module) / 组件(Component)
- 分布式(Distributed)
- 集群(Cluster)
- 主(Master) / 从(Slave)
- 中间件(Middleware)
- 可用性(Availability)
- 响应时长(Response Time RT)
- 吞吐(Throughput) / 并发(Concurrent)
🔎理解分布式
一台主机的硬件资源是有限的
包括但不限于:
- CPU
- 内存
- 硬盘
- 主板
- 网络适配器
- …
服务器每收到一个请求, 都需要消耗上述的一些资源
如果同一时刻处理的请求过多, 可能导致某个硬件资源的性能陷入瓶颈
如果遇到这种场景, 应对方式有 2 种
- 开源(针对硬件 → 增加更多的硬件资源)
- 节流(针对软件 → 对软件进行优化, 通过性能测试找到性能瓶颈)
对于开源的具体解释🍭
一台主机上所能增加的硬件资源是有限的(取决于主板的扩展能力), 当一台主机扩展到极限时, 资源还是不够, 就需要引入多台主机
引入多台主机之后, 系统就可以称为是分布式系统(此时响应的代码也需要做出调整)
题外话🍭
引入分布式, 相对于程序员, 并不是一件好事
这是因为分布式的引入, 所带来的复杂程度大大提高 → 从而导致出 BUG 的概率提高 → 年终奖丢失的概率与加班的概率大大提高
🔎分布式—应用服务与数据库服务分离
单机服务器 → 应用服务与数据库服务未分离
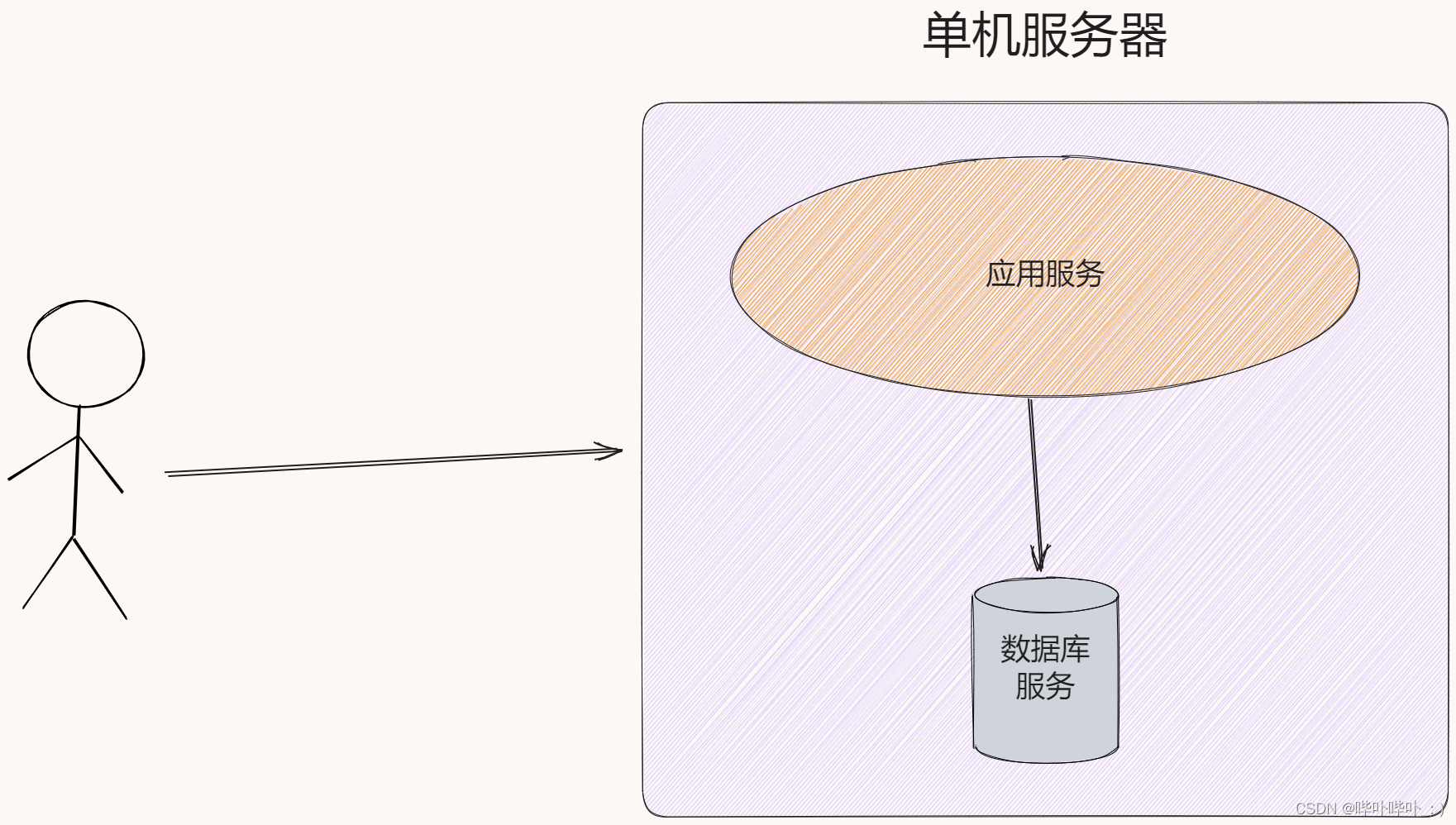
应用服务器 + 数据库服务器 → 应用服务与数据库服务分离(分布式)
针对不同服务器涉及的不同场景, 分配不同但更合理的硬件资源
对于应用服务器, 可能包含更多的业务操作. CPU, 内存的利用率更高 → 于是选择较好的 CPU, 内存
对于数据库服务器, 可能需要更多的硬盘空间, 更快的访问速度 → 于是选择更大的固态硬盘
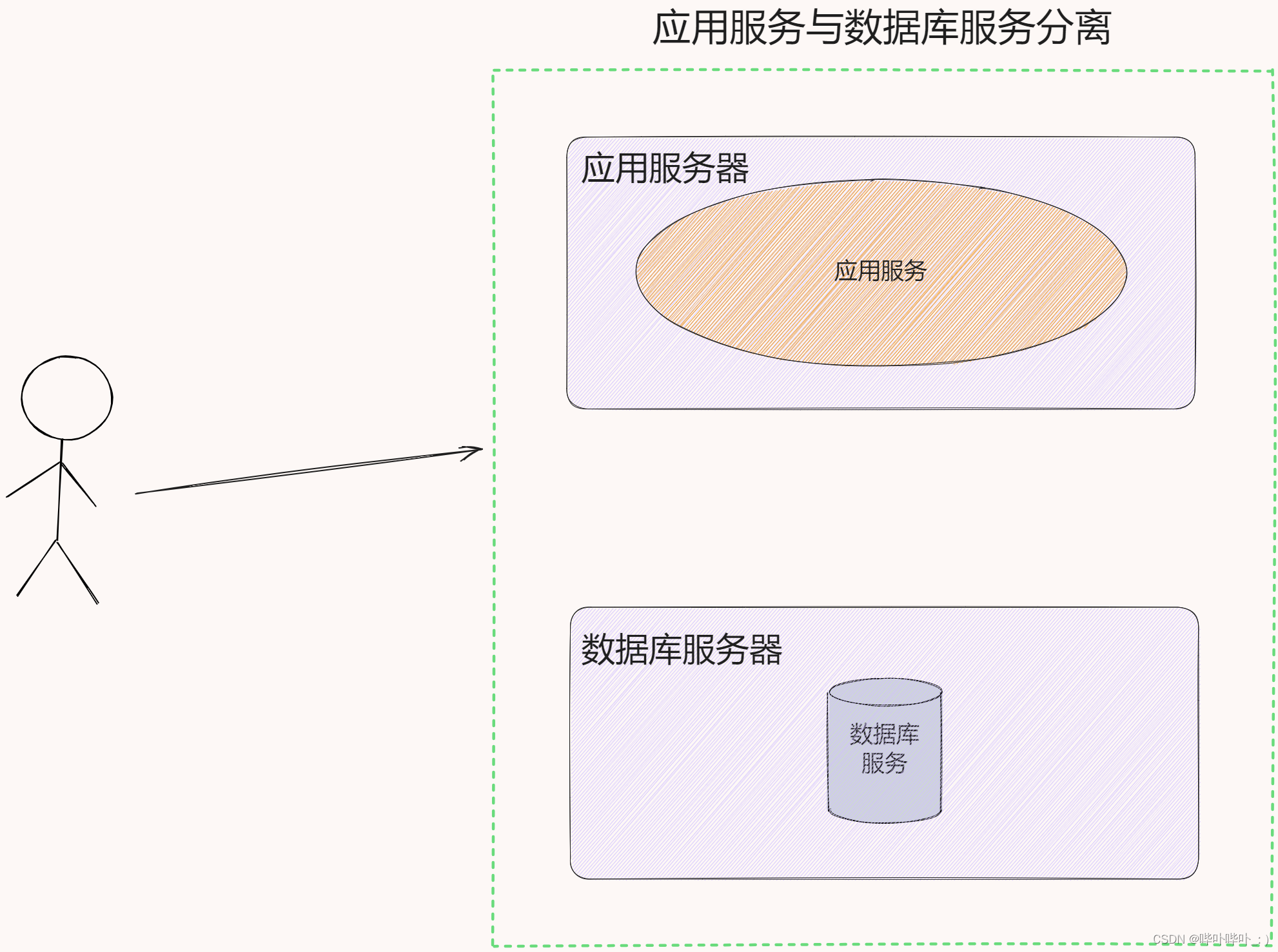
引入更多的应用服务节点
应用服务可能会消耗较多的 CPU 和内存, 如果 CPU 和内存耗光, 此时的应用服务器就会宕机
为了解决上述问题, 于是引入更多的应用服务器
通过负载均衡, 合理的分配应用服务器的工作
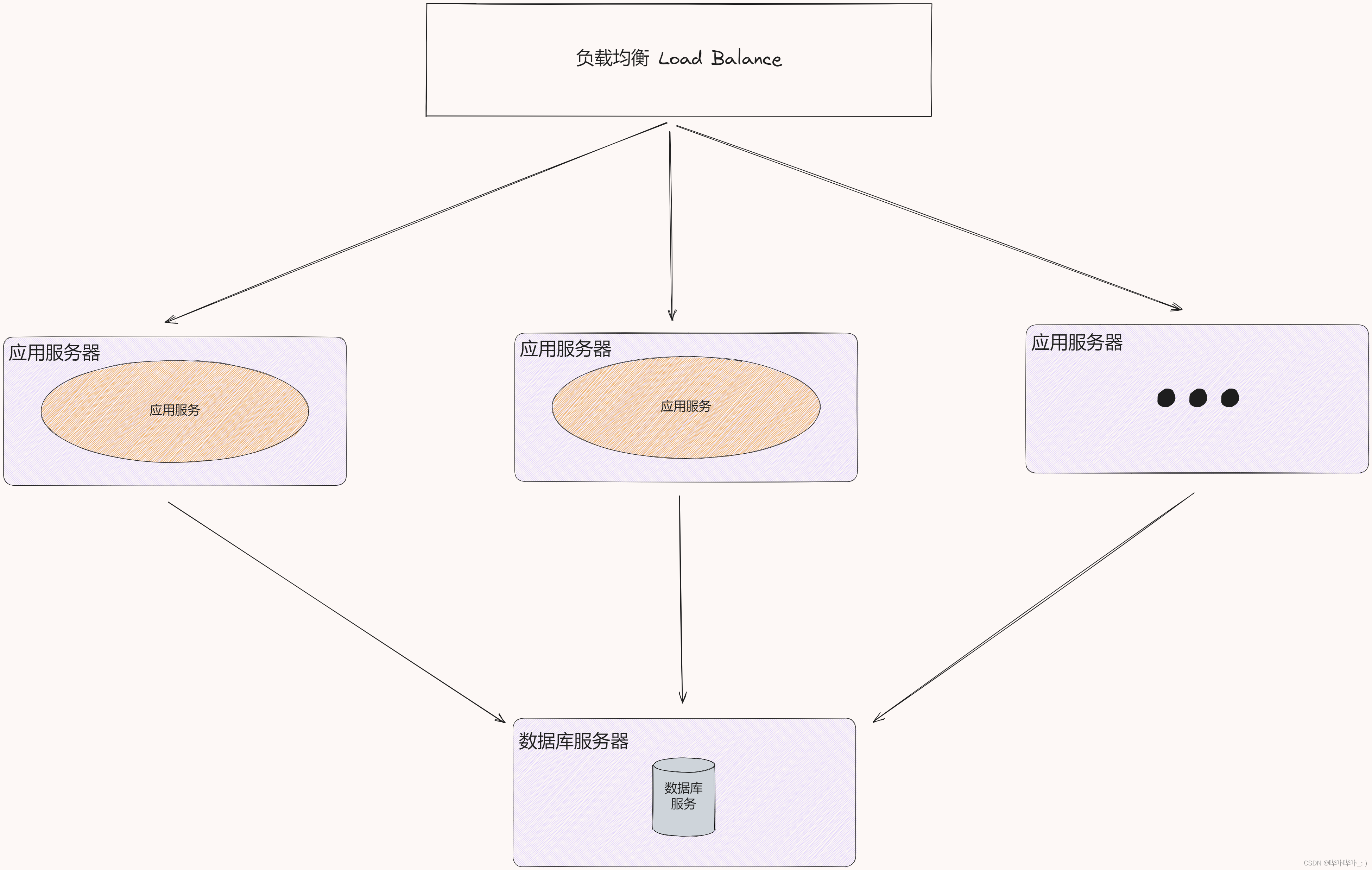
理解负载均衡
假设有 1 万个请求, 有 4 台应用服务器
此时按照负载均衡的方式, 就可以让每台服务器承担 2.5k 的访问量
举个栗子🌰
将负载均衡器看作是一个小组的领导, 应用服务器看作是小组的组员
领导(负载均衡器)分配工作, 组员(应用服务器)执行工作
其中负载均衡器的承担能力要远远大于应用服务器
你可以将其理解为领导负责分配工作, 而不是执行工作. 分配工作要比执行工作轻松
如果出现请求量过多, 从而导致负载均衡器宕机, 怎么办?
引入更多的负载均衡器
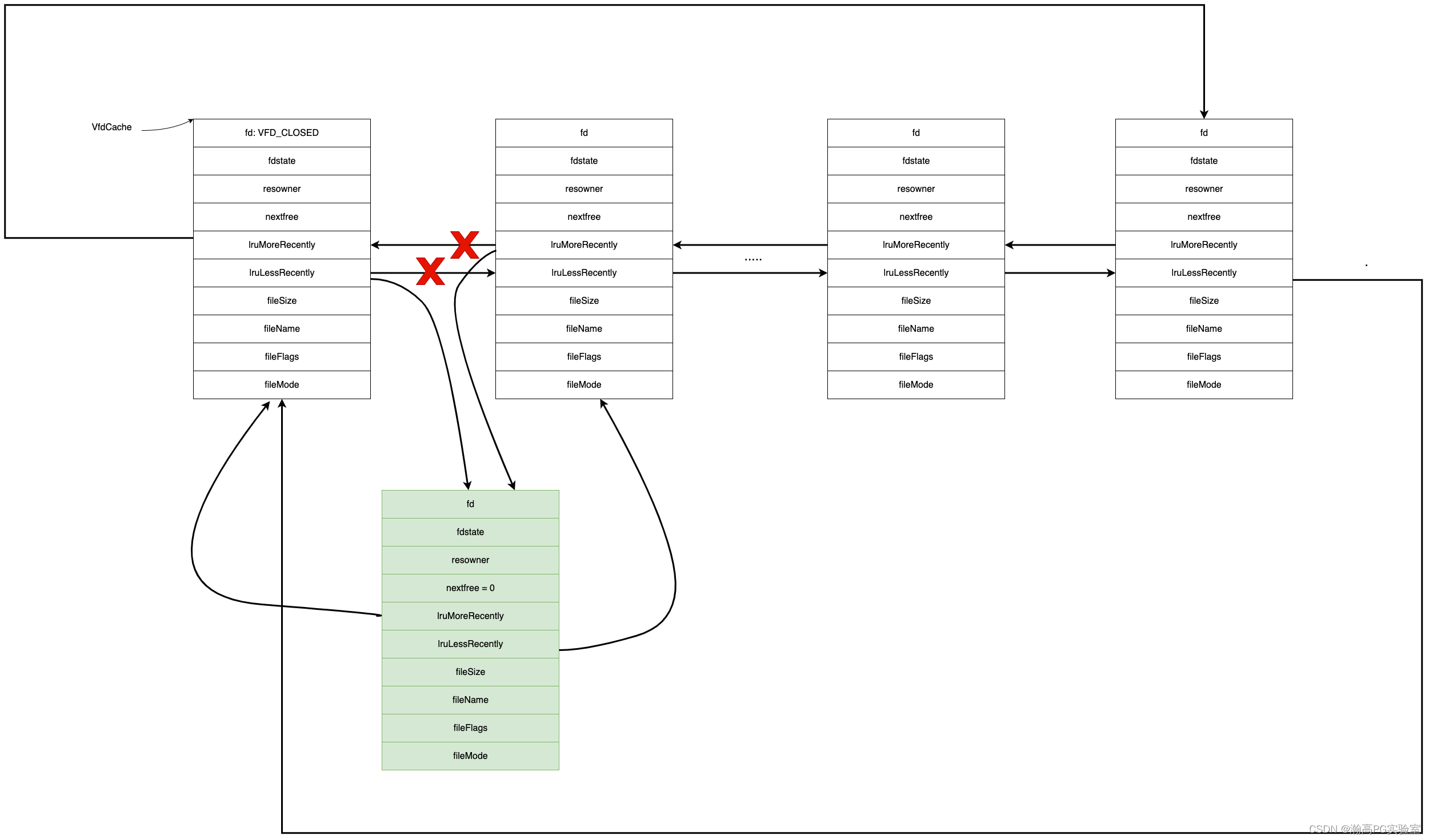
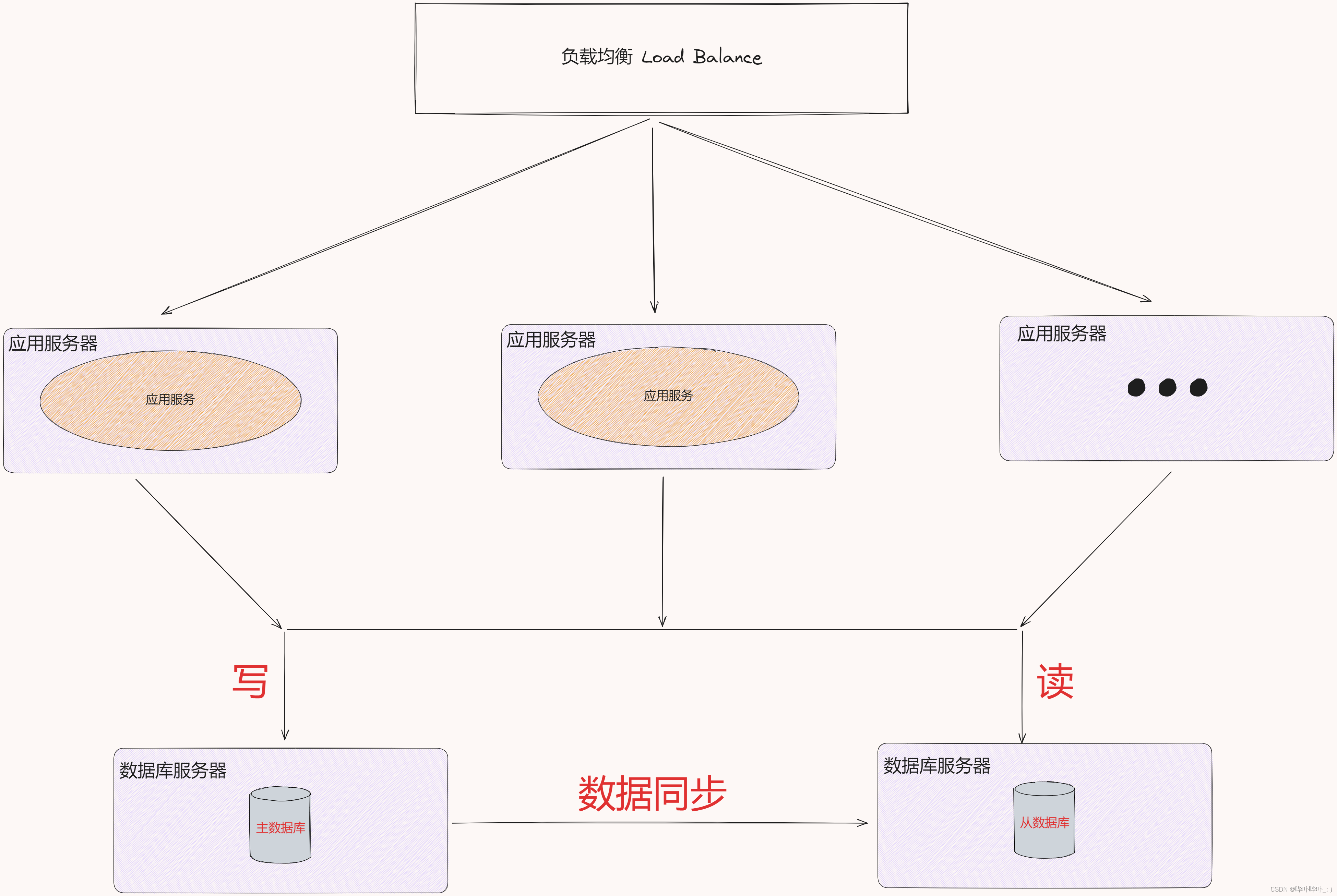
引入更多的数据库服务节点
当应用服务器过多时, 确实能够处理更高的请求量, 但是随之数据库服务器要承担的请求量也就更多了
针对上述情况, 解决办法是引入更多的数据库服务器
在实际应用场景中, 向数据库中读取数据的频率 > 向数据库中写入数据
主服务器一般是一个, 从服务器有多个(一主多从)
主(Master) / 从(Slave)
通常向主数据库中写入数据, 向从数据库中读取数据
主从数据库之间会进行周期性的数据同步
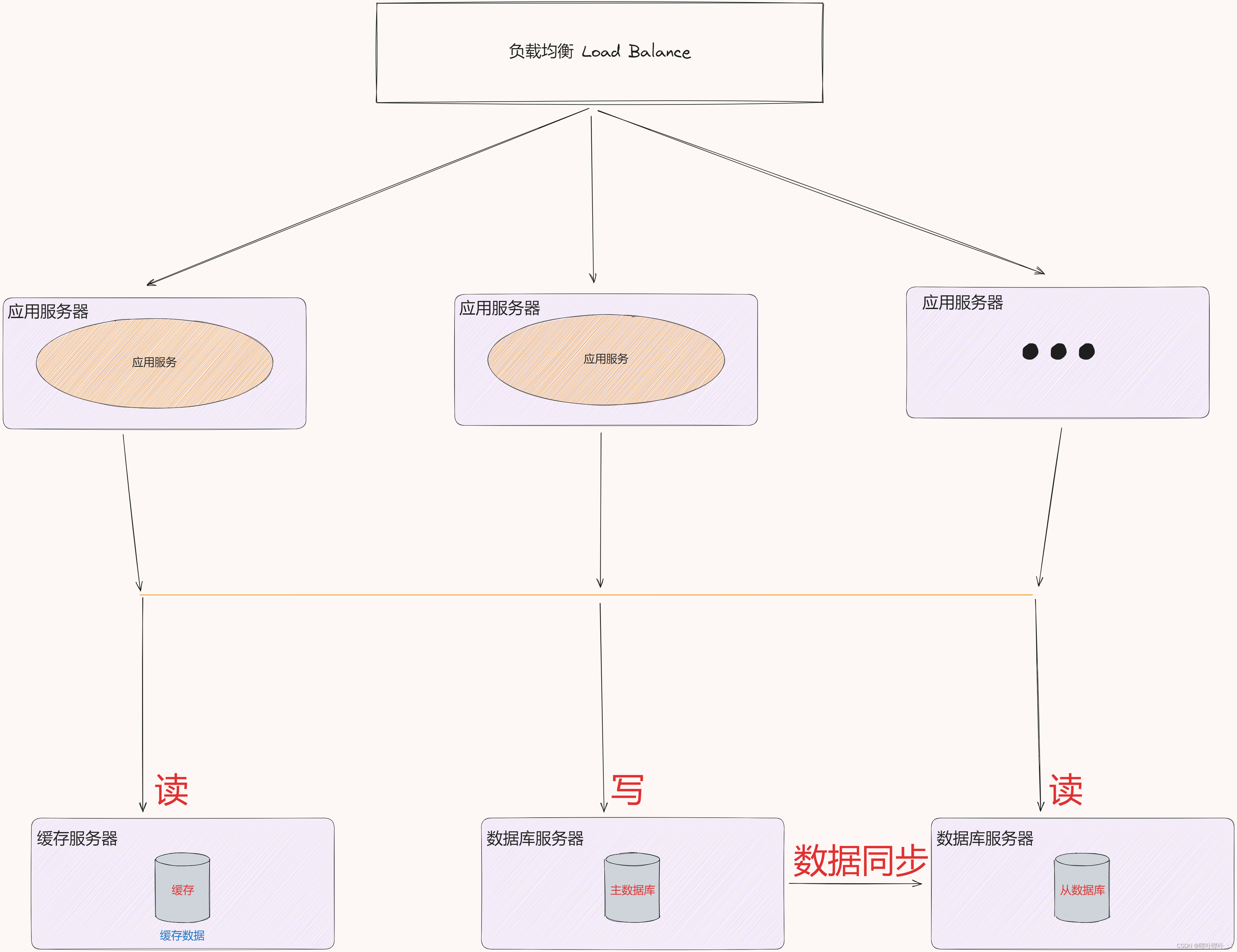
缓存
数据库的响应速度较慢(从硬盘中读取数据)
于是有了 “冷热” 数据的区别
将热点数据放入至缓存中, 缓存的响应速度 > 数据库的响应速度
根据二八原则, 20% 的数据能够支持 80% 的访问(实际场景的不同会有所差异), 即缓存中的热点数据能够支持绝大多数的访问场景
从数据库依旧存储全部数据
(读取数据时先去访问缓存, 如果缓存中不存在, 再去访问从数据库 → 提升了响应速度)
Redis 在分布式系统中通常作为缓存
分库分表
分布式系统的引入, 不仅要求能够处理更高的请求量, 还要求能应对更大的数据量
虽然一台服务器存储的数据可以达到几十个 TB, 但即便如此也可能会出现存不下的情况
当一台服务器存不下时, 就需要多台服务器进行存储, 即针对数据库进行拆分(分库)
分库, 将一台数据库服务器上的多个数据库拆分. 变成多台数据库服务器存储一个或一部分数据库
如果数据库中的某个表特别大, 一台主机存不下, 也可以针对数据表进行拆分(分表)
微服务
一个应用服务器程序可能包含很多的业务, 从而导致服务器的代码变的越来越复杂
为了便于代码的维护, 就将这样的复杂服务器拆分成更多的, 功能更单一, 但是更小的服务器(微服务)
微服务 → 增加了服务器的种类和数量
微服务的本质是解决 “人” 的问题🍂
当应用服务器变的复杂, 就需要更多的人来进行维护. 当人变的多了, 就需要增加配套的管理, 将这些人组织好
按照功能拆分成多组微服务, 有利于人员的组织结构划分
引入微服务的代价🍂
- 系统的性能下降
拆分出更多的服务, 多个功能之间依靠网络进行通信, 网络通信的速度较慢
(想要保证性能下降不至于太多, 解决办法是引入更多的硬件资源) - 系统的复杂程度增加了, 可用性受到影响
服务器更多, 也就意味着出现问题的概率更大
引入微服务的优势🍂
- 解决了 “人” 的问题
- 使用微服务的方式, 更方便功能的复用
- 可以针对不同的服务进行不同的部署
(针对访问量, 功能配置不同的硬件资源)

🔎常见概念
应用(Application) / 系统(System)
一个应用 / 系统, 就是一个 / 一组服务器程序
模块(Module) / 组件(Component)
一个应用中有很多的功能, 每个独立的功能就是一个模块 / 组件
分布式(Distributed)
引入多台主机 / 服务器, 协同配合完成一系列的工作(物理上的多台主机)
集群(Cluster)
引入多台主机 / 服务器, 协同配合完成一系列的工作(逻辑上的多台主机)
主(Master) / 从(Slave)
分布式系统中的一种典型结构
多台服务器节点, 其中一个是主, 另外的是从. 从节点的数据依据主节点的数据进行同步
中间件(Middleware)
功能更通用的服务, 包括:
- 数据库
- 缓存
- 消息队列
- …
可用性(Availability)
系统整体的可用时间 / 总时间
例如整体可用时间为 360 天, 总时间为 365 天
则可用性为 360 / 365
响应时长(Response Time RT)
衡量服务器的性能指标
响应时长: 处理请求到完成响应的时间
吞吐(Throughput) / 并发(Concurrent)
衡量系统处理请求的能力. 衡量性能的一种方式
🌸🌸🌸完结撒花🌸🌸🌸

![nvm 安装 Node 报错:panic: runtime error: index out of range [3] with length 3](https://img-blog.csdnimg.cn/4825d19761884fce9f1187b7d8988240.png)