文章目录
- Inception V1
- Inception Module
- native version
- Inception module with dimensionality reduction
- 1 * 1网络的降维说明
- 多个Softmax的输出
- 整体结构
GoogleLeNet主要是把深度扩充到了22层,能增加网络深度而不用担心训练精度和梯度消失问题。
总共是提出了4个版本,从V1 - V4.
Inception V1
Inception Module
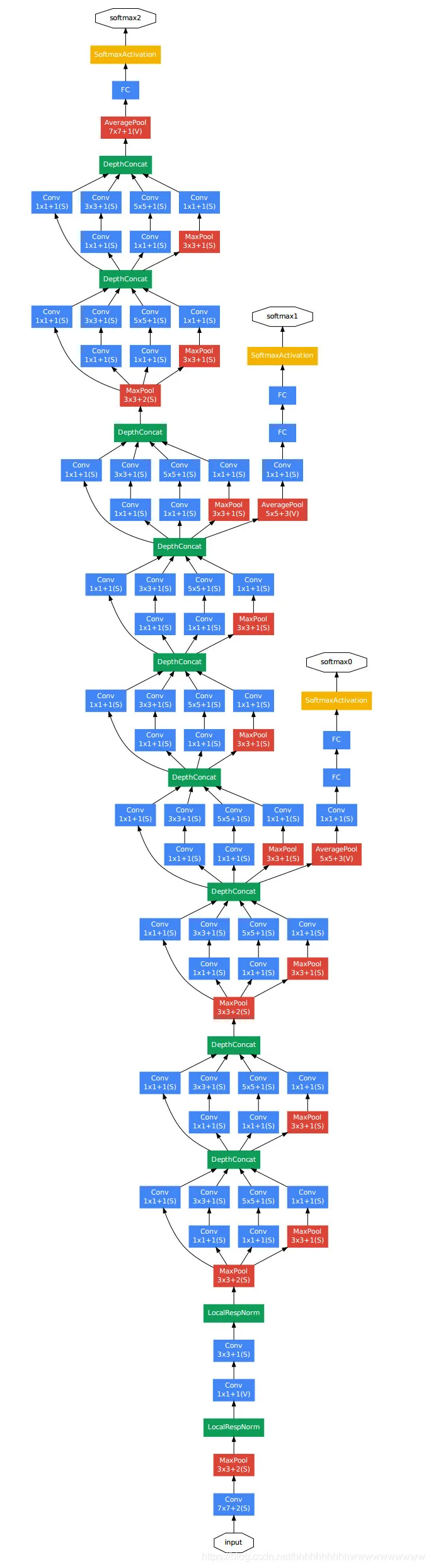
V1的版本是在论文Going deeper with Convolutions中提出的,最主要的内容就是提出了一个称作Inception的结构,这个结构在整个网络中重复出现,组成了22层网络。
这个结构如图:
总共有两个版本。
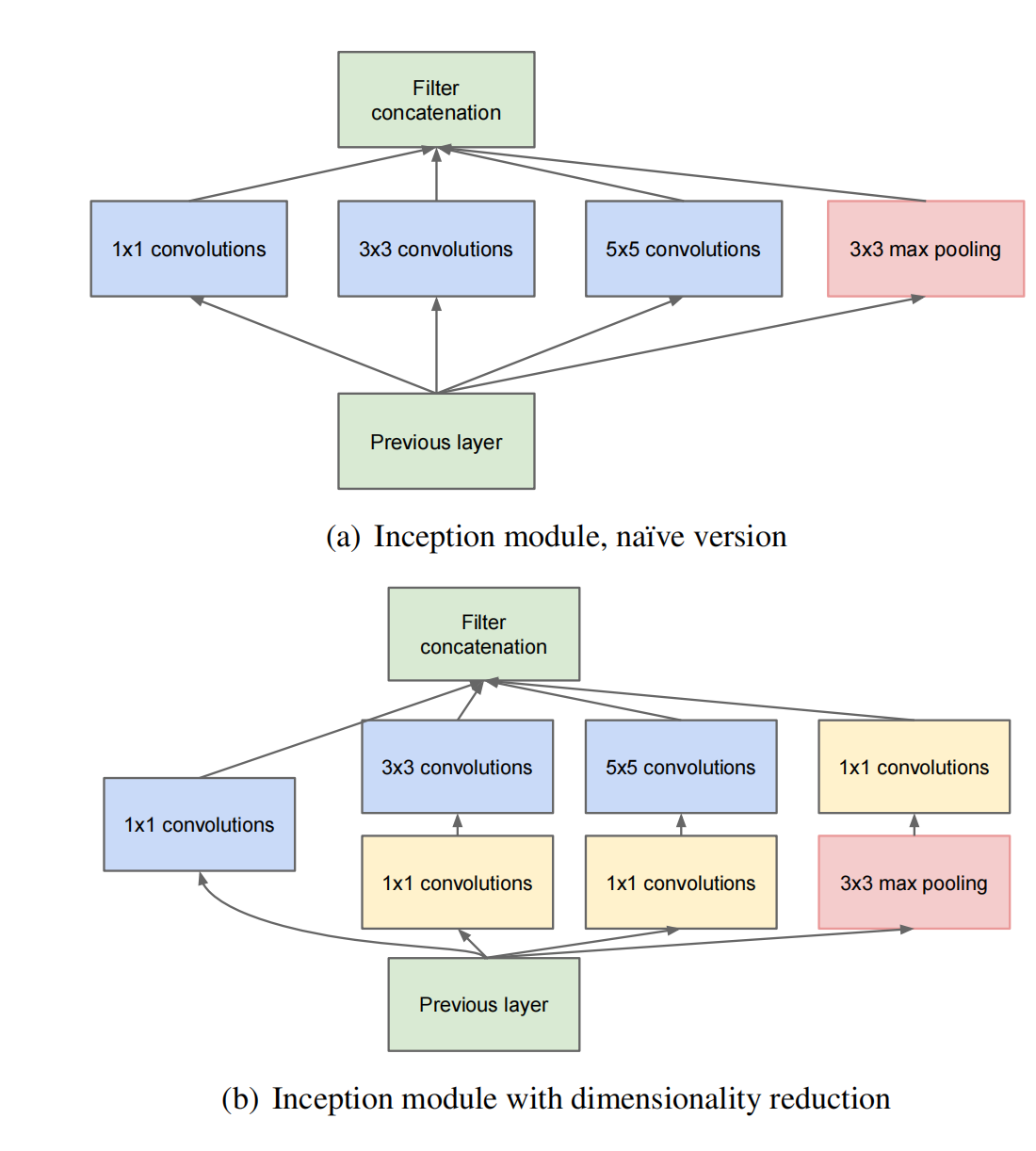
native version
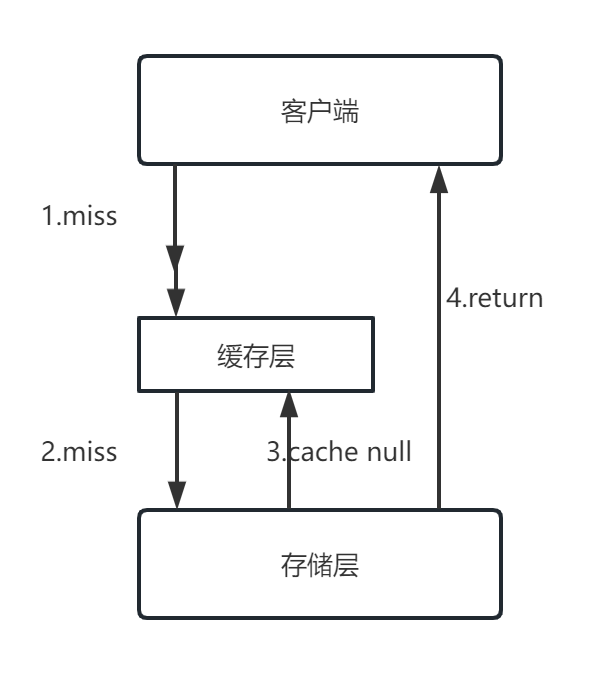
首先说说这个结构能干啥,或者说为什么要在网络中引入这个结构,对整个网络有什么帮助。
- 论文上的原话是:The main idea of the Inception architecture is to consider how an optimal local sparse structure of a convolutional vision network can be approximated and covered by readily available dense components。也就是说要把稀疏的结构去重新设计一下,去模拟和近似稠密结构的性能。因为现在的计算硬件都是针对与稠密结构来设计的。我自己对这个稀疏和稠密的理解是:因为需要多尺度数据,所以有1 * 1的,3 * 3等不同的卷积核,挨个计算的话,就会浪费计算资源。这里的dense就是把这些卷积核全部卷积一遍之后放在一起,然后再进行计算。
- 简单的来说,我理解这个结构起到了两个作用,第一是综合了多尺度或者说多视野下不同的特征图(通过不同的感受野卷积核)。第二是将sparse structure调整为dense components。增加计算的效率。
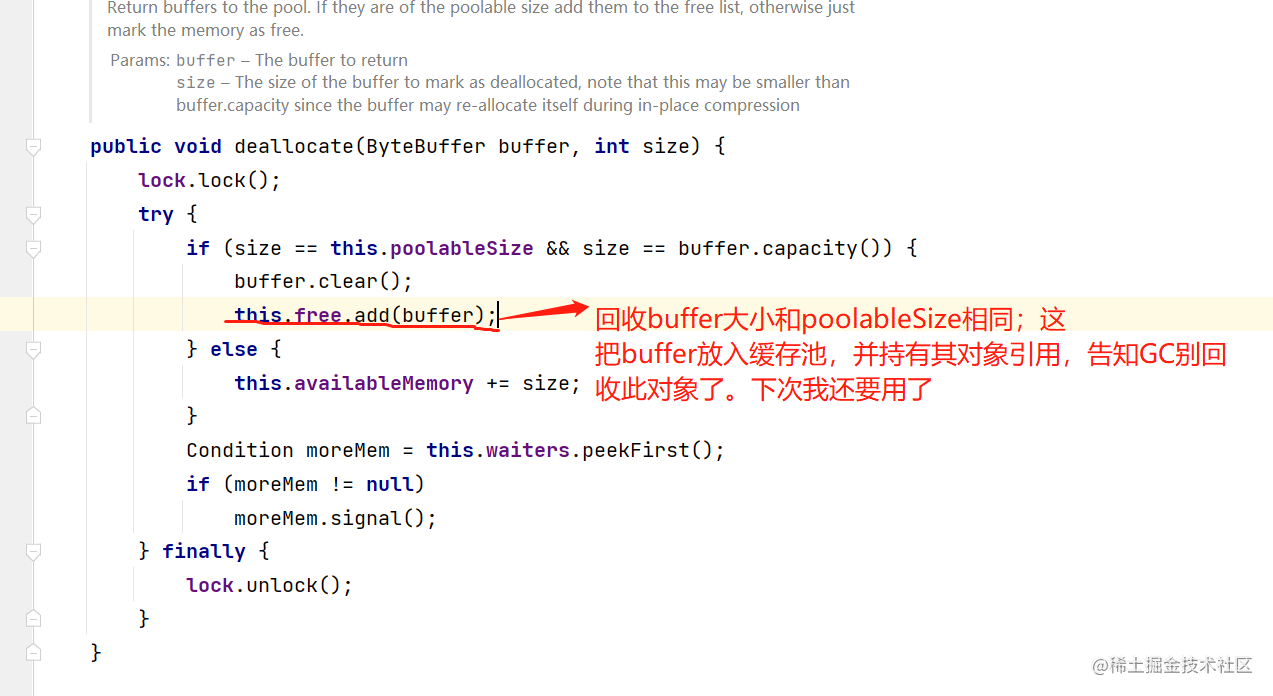
- 那么这个结构做了什么事情呢:(a)图中的各个尺寸的卷积核对前一层的输出进行计算,再加上一个合并的操作(也就是把每个卷积核的操作全部叠在一起)。我这里懒得画图了,比如说1 * 1的卷积核有32个通道,那么1 * 1处理后的通道就是32个通道,3 * 3的有64个通道,5 * 5的有128个通道,直接叠加就行,所以需要调整stride和padding使得这些不同感受野的featrue map尺寸一样,可以直接叠加。然后把这个合并后的featrue map再进入这一层的新的卷积操作(Filter concalenation)
Inception module with dimensionality reduction
这个与native version相比,增加了1 * 1的卷积核做降维的操作,减少参数量和计算量,降低训练和推理的难度。
原文中的描述为:One big problem with the above modules, at least in this native form, is that even a modest number of 5×5 convolutions can be prohibitively expensive on top of a convolutional layer with a large number of filters. This problem becomes even more pronounced once pooling units are added to the mix: the number of output filters equals to the number of filters in the previous stage。
我理解就是说计算量大,所以升级版本的就是用了几个1 * 1来做降维。卷积是先降维再卷积,pooling是先池化再做降维。
1 * 1网络的降维说明
1 * 1的卷积层称作Network in Network,可以用于模型的降维,比如一个输出为100 * 100 * 128的featrue map,如果下一层的通道数为256的话,也就是尺寸就是 100 * 100 * 256的话,如果中间的卷积层使用 5 * 5感受野的卷积核,那么参数个数是 128 * 5 * 5 * 256个参数。
上面这个过程可以通过一个1 * 1来进行降维,比如先降低到32个通道数,也就是先通过一个 1 * 1 * 32的卷积核把100 * 100 * 128降低到 100 * 100 * 32,然后再通过一个100 * 100 * 256的卷积核计算上去,那么这里的大小是:32 * 100 * 100 * 256。总参数就是128 * 1 * 1 * 32 + 100 * 100 * 256,比上面的要少一些。
至于为什么不用一个3 * 3 * 32来降维,我理解是这里不需要再次提取特征,所以直接用1 * 1的是比较好的。
多个Softmax的输出
在整个GoogleLeNet中,网络结构设计了3个输出项,这是为了在训练过程中可以在不同的网络深度的时候计算损失值和做反向权重计算。因为如果太深了,很有可能就会出现梯度消失的现象。
辅助分类器:为了避免梯度消失,网络额外增加2个辅助的softmax用于向前传导梯度(辅助分类器)。辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样就相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个网络的训练很有裨益,实际测试时会去掉这两个额外的softmax
论文原文:The strong performance of shallower networks on this task suggests that the features produced by the layers in the middle of the network should be very discriminative. By adding auxiliary classifiers connected to these intermediate layers, discrimination in the lower stages in the classifier was expected.This was thought to combat the vanishing gradient problem while providing regularization。These classifiers take the form of smaller convolutional networks put on top of the output of the Inception (4a) and (4d) modules. During training, their loss gets added to the total loss of the network with a discount weight (the losses of the auxiliary classifiers were weighted by 0.3),在4(a)和4(d)的两个位置增加了两个输出,在训练的时候计算了0.3的权重(反向传播的过程中的权重计算),在推理的时候就不用,起到了0.5个百分点的作用。
我的理解是担心如果网络太深,在训练的时候反向传播会出现梯度弥散,也就是梯度变成0的情况,参数无法收敛,在低层次的网络就计算损失和开始梯度计算和传播,就会减少这种情况的发生。
整体结构
除了前面和后面加了一些必要的层进行预处理,基本上就是由Inception module组成。