数据架构设计模式
数据架构主要有三种模式:
Shared Everything、Shared Disk、Shared Nothing。
Shared Disk
各处理单元使用本地的私有CPU和Memory,共享磁盘系统,分布式数据库。
典型的代表是Oracle RAC、DB2 PureScale。
例如:Oracle RAC用的是共享存储,做到了数据共享,可通过增加节点来提高并行处理的能力,扩展能力较好,使用Storage Area Network (SAN),光纤通道连接到多个服务器的磁盘阵列,降低网络消耗,提高数据读取的效率,常用于并发量较高的OLTP应用。
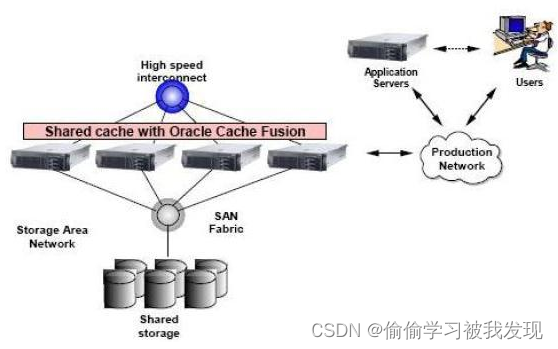
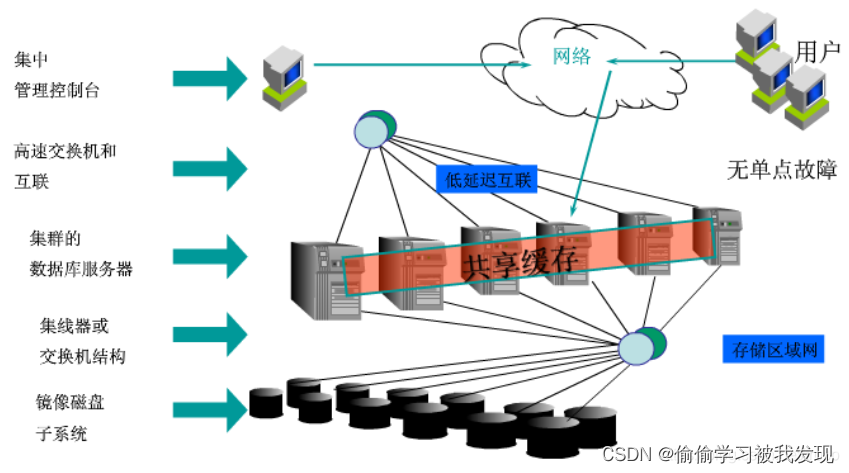
其类似于SMP(对称多处理)模式,但是当存储器接口达到饱和的时候,增加节点并不能获得更高的性能,同时更多的节点,则增加了运维的成本。
Data Shared Cluster 数据共享集群,简称DSC,是并行集群,位于不同服务器系统的DM实例同时访问同一个数据库,节点之间通过私有网络进行通信,所有的控制文件、联机日志和数据文件存放在共享的设备上,能够被集群中的所有节点同时访问。
DSC的优点主要在于高可用和负载均衡,一台机器宕机不影响应用访问数据库。
Shared Everything
一般指的是单个主机的环境,完全透明共享的CPU/内存/硬盘,并行处理能力是最差的,一般不考虑大规模的并发需求,架构比较简单,一般的应用需求基本都能满足。
典型代表就是SQL Server、单机版Oracle和MySQL。
Shared Nothing
Shared noting(SN)是一种分布式计算架构。这种架构中,每一个节点都是独立的,自给的,在系统中不存在单点竞争。更明确地说,没有节点共享存储和硬盘。人们通常将SN和大量保存中央存储状态信息的系统进行对比,无论是在数据库,应用服务器或者是其他相似的单点竞争。
SN相对中央控制架构有很大的优点。SN可以避免单点故障,拥有自我恢复能力,并且在不破坏原有系统的情况下进行升级。
各处理单元都有自己私有的CPU/内存/硬盘等,Nothing,顾名思义,不存在共享资源,类似于MPP(大规模并行处理)模式,各处理单元之间通过协议通信,并行处理和扩展能力更好。
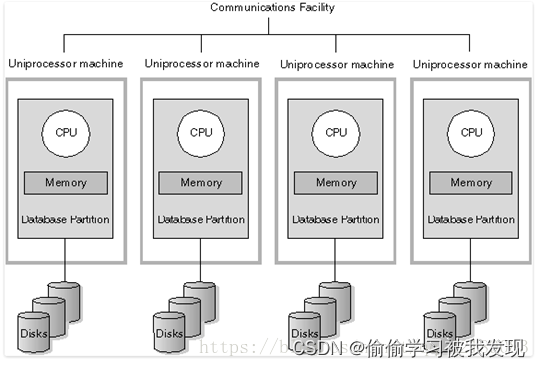
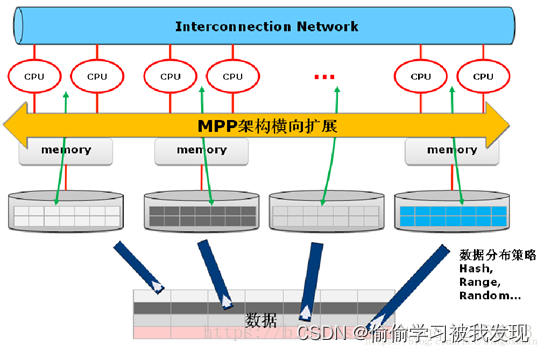
典型代表DB2 DPF、带分库分表的MySQL Cluster,各节点相互独立,各自处理自己的数据,处理后的结果可能向上层汇总或在节点间流转。
实际上Shared Nothing架构细化又可以分为两种:
- 一种是分布式架构,将数据库中的数据按照某一标准分布到多台机器中,查询或插入时按照条件查询或插入对应的分区。
- Sharding其实就是Shared Nothing,他是将某个表从物理存储上被水平分割,并分配给多台服务器(或多个实例),每台服务器可以独立工作,具备共同的schema,
- 例如MySQL Proxy和Google的各种架构,只需增加服务器数就可以增加处理能力和容量。
- 一种是每一个节点完全独立,节点之间通过网络连接,通常是通过光纤等专用网络。
- MPP,指的是大规模并行分析数据库(Analytical Massively Parallel Processing (MPP) Databases),他是针对分析工作负载进行了优化的数据库,一般需要聚合和处理大型数据集。MPP数据库往往是列式的,因此MPP数据库通常将每一列存储为一个对象,而不是将表中的每一行存储为一个对象。这种体系结构使复杂的分析查询可以更快,更有效地处理。
- 例如TeraData、Greenplum,GaussDB100、TBase。