【MATLAB第57期】基于MATLAB的双隐含层BP神经网络回归预测模型(无工具箱版本及工具箱版本对比)
一、无工具箱版本
1.数据设置
数据为案例数据 。103行样本,7输入1输出数据。
2.参数设置
训练函数 梯度下降
HiddenUnit1Num=10;%隐层1结点数
HiddenUnit2Num=10;%隐层2节点数
MaxEpochs=20000;%最大训练次数
TF1 = 'logsig';TF2 = 'logsig'; TF3 = 'purelin';%各层传输函数,TF3为输出层传输函数
lr=0.003;%学习率
E0=0.05;%目标误差
3.代码展示
%--------------两个隐层的BP算法-------------%
clear all;
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 导入数据
res = xlsread('数据集.xlsx');
%% 划分训练集和测试集
temp = randperm(103);
save temp temp
P_train = res(temp(1: 80), 1: 7)';
T_train = res(temp(1: 80), 8)';
M = size(P_train, 2);
P_test = res(temp(81: end), 1: 7)';
T_test = res(temp(81: end), 8)';
N = size(P_test, 2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
SamNum=size(p_train,2);%样本数
TestSamNum=size(p_test,2);%测试样本
HiddenUnit1Num=10;%隐层1结点数
HiddenUnit2Num=10;%隐层2节点数
InDim=size(p_train,1);%样本输入维数
OutDim=size(t_train,1);%样本输出维数
%根据目标函数获得样本输入输出
MaxEpochs=20000;%最大训练次数
lr=0.003;%学习率
E0=0.05;%目标误差
%产生扩展向量,及扩展样本输入%
W1Ex=[W1 B1];
W2Ex=[W2 B2];
W3Ex=[W3 B3];
SamInEx=[p_train' ones(SamNum,1)]';
for i=1:MaxEpochs
%正向传播时第一隐层,第二隐层,及网络输出值%
u=W1Ex*SamInEx;
Hidden1Out=1./(1+exp(-u));
Hidden1OutEx=[Hidden1Out' ones(SamNum,1)]'; %停止学习判断条件
Error=t_train-NetworkOut;%是一个1*M的向量
SSE=sum(Error.^2);%所有样本产生的误差之和
if SSE<E0,break,end
%计算反向传播误差
Delta3=Error;%是一个横向量,包含样本的误差
Dw3Ex=Delta3*Hidden2OutEx';
for n=1:SamNum %对每一个样本分别计算
Delta2=(W3'*Delta3(n)).*Hidden2Out(:,n).*(1-Hidden2Out(:,n));
Delta2Store(:,n)=Delta2;
Dw2Ex=Dw2Ex+Delta2*Hidden1OutEx(:,n)';
end
%更新权值
end
%% 测试集预测
v=size(p_test);
TestSamInEx=[p_test' ones(v(2),1)]';
u=W1Ex*TestSamInEx;
Hidden1Out=1./(1+exp(-u));
Hidden1OutEx=[Hidden1Out' ones(v(2),1)]';
u=W2Ex*Hidden1OutEx;
Hidden2Out=1./(1+exp(-u));
Hidden2OutEx=[Hidden2Out' ones(v(2),1)]';
TestNetworkOut=W3Ex*Hidden2OutEx; %网络输出值
T_sim2 = mapminmax('reverse', TestNetworkOut, ps_output);
%% 均方根误差
error1 = sqrt(sum((T_sim1 - T_train).^2) ./ M);
error2 = sqrt(sum((T_sim2 - T_test ).^2) ./ N);
%% 绘图
figure
plot(1: M, T_train, 'r-*', 1: M, T_sim1, 'b-o', 'LineWidth', 1)
legend('真实值','预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'训练集预测结果对比'; ['RMSE=' num2str(error1)]};
title(string)
xlim([1, M])
grid
figure
plot(1: N, T_test, 'r-*', 1: N, T_sim2, 'b-o', 'LineWidth', 1)
legend('真实值','预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'测试集预测结果对比';['RMSE=' num2str(error2)]};
title(string)
xlim([1, N])
grid
%% 相关指标计算
% 决定系数 R2
R1 = 1 - norm(T_train - T_sim1)^2 / norm(T_train - mean(T_train))^2;
R2 = 1 - norm(T_test - T_sim2)^2 / norm(T_test - mean(T_test ))^2;
disp(['训练集数据的R2为:', num2str(R1)])
disp(['测试集数据的R2为:', num2str(R2)])
% 平均绝对误差 MAE
mae1 = sum(abs(T_sim1 - T_train)) ./ M ;
mae2 = sum(abs(T_sim2 - T_test )) ./ N ;
disp(['训练集数据的MAE为:', num2str(mae1)])
disp(['测试集数据的MAE为:', num2str(mae2)])
% 平均相对误差 MBE
mbe1 = sum(T_sim1 - T_train) ./ M ;
mbe2 = sum(T_sim2 - T_test ) ./ N ;
disp(['训练集数据的MBE为:', num2str(mbe1)])
disp(['测试集数据的MBE为:', num2str(mbe2)])
4.效果展示
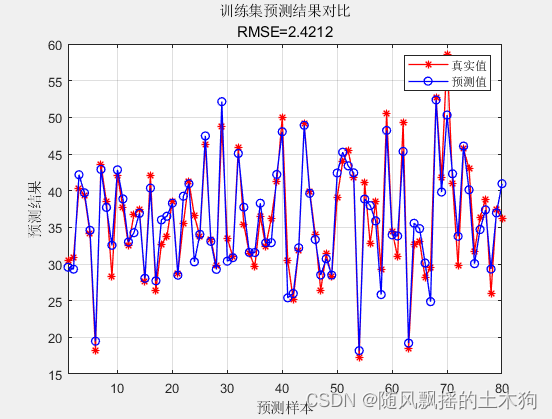
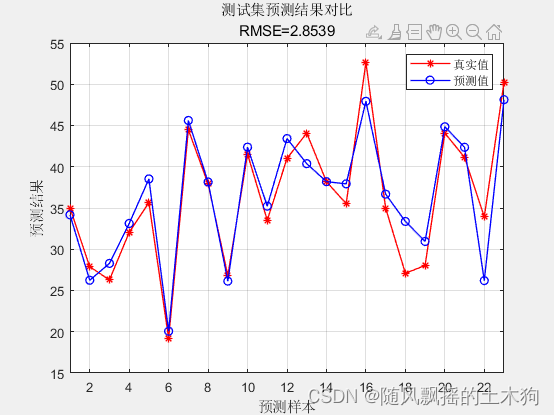
训练集数据的R2为:0.9022
测试集数据的R2为:0.87266
训练集数据的MAE为:1.8189
测试集数据的MAE为:2.1658
训练集数据的MBE为:-0.00088469
测试集数据的MBE为:0.3059
二、有工具箱版本
1.数据设置
数据与无工具版本相同,数据顺序也相同。
2.参数设置
训练函数 trainlm
NodeNum1 = 10; % 隐层第一层节点数
NodeNum2=10; % 隐层第二层节点数
net.trainParam.epochs=20000;%训练次数设置
net.trainParam.goal=0.05;%训练目标设置
net.trainParam.lr=0.003;%学习率设置,应设置为较少值,太大虽然会在开始加快收敛速度,但临近最佳点时,会产生动荡,而致使无法收敛
TF1 = 'logsig';TF2 = 'logsig'; TF3 = 'purelin';%各层传输函数,TF3为输出层传输函数
%如果训练结果不理想,可以尝试更改传输函数,以下这些是各类传输函数
3.代码展示
%--------------两个隐层的BP算法-------------%
% BP 神经网络用于预测
%网络为7输入,1输出
% 103组数据,其中80组为正常训练数据,23组为测试数据
clear all;
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 导入数据
res = xlsread('数据集.xlsx');
%% 划分训练集和测试集
temp = randperm(103);
load temp
P_train = res(temp(1: 80), 1: 7)';
T_train = res(temp(1: 80), 8)';
M = size(P_train, 2);
P_test = res(temp(81: end), 1: 7)';
T_test = res(temp(81: end), 8)';
N = size(P_test, 2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%---------------------------------------------------
%数据归一化处理
%mapminmax函数默认将数据归一化到[0,1],调用形式如下
%[y,ps] =%mapminmax(x,ymin,ymax)
%x需归化的数据输入
%ymin,ymax为需归化到的范围,不填默认为归化到[-1,1]
%y归一化后的样本数据
%ps处理设置,ps主要在结果反归一化中需要调用,或者使用同样的settings归一化另外一组数据
%---------------------------------------------------
%---------------------------------------------------
% 设置网络参数
%---------------------------------------------------
NodeNum1 = 10; % 隐层第一层节点数
NodeNum2=10; % 隐层第二层节点数
TypeNum = 1; % 输出维数
TF1 = 'logsig';TF2 = 'logsig'; TF3 = 'purelin';%各层传输函数,TF3为输出层传输函数
%如果训练结果不理想,可以尝试更改传输函数,以下这些是各类传输函数
%TF1 = 'tansig';TF2 = 'logsig';
%TF1 = 'logsig';TF2 = 'purelin';
%TF1 = 'tansig';TF2 = 'tansig';
%TF1 = 'logsig';TF2 = 'logsig';
%TF1 = 'purelin';TF2 = 'purelin';
%注意创建BP网络函数newff()的参数调用
%---------------------------------------------------
% 设置训练参数
%---------------------------------------------------
net.trainParam.epochs=20000;%训练次数设置
net.trainParam.goal=0.05;%训练目标设置
net.trainParam.lr=0.003;%学习率设置,应设置为较少值,太大虽然会在开始加快收敛速度,但临近最佳点时,会产生动荡,而致使无法收敛
%---------------------------------------------------
% 指定训练函数
%---------------------------------------------------
% net.trainFcn = 'traingd'; % 梯度下降算法
% net.trainFcn = 'traingdm'; % 动量梯度下降算法
%
% net.trainFcn = 'traingda'; % 变学习率梯度下降算法
% net.trainFcn = 'traingdx'; % 变学习率动量梯度下降算法
%
% (大型网络的首选算法)
% net.trainFcn = 'trainrp'; % RPROP(弹性BP)算法,内存需求最小
%
% (共轭梯度算法)
% net.trainFcn = 'traincgf'; % Fletcher-Reeves修正算法
% net.trainFcn = 'traincgp'; % Polak-Ribiere修正算法,内存需求比Fletcher-Reeves修正算法略大
% net.trainFcn = 'traincgb'; % Powell-Beal复位算法,内存需求比Polak-Ribiere修正算法略大
%
% (大型网络的首选算法)
%net.trainFcn = 'trainscg'; % Scaled Conjugate Gradient算法,内存需求与Fletcher-Reeves修正算法相同,计算量比上面三种算法都小很多
% net.trainFcn = 'trainbfg'; % Quasi-Newton Algorithms - BFGS Algorithm,计算量和内存需求均比共轭梯度算法大,但收敛比较快
% net.trainFcn = 'trainoss'; % One Step Secant Algorithm,计算量和内存需求均比BFGS算法小,比共轭梯度算法略大
%
% (中型网络的首选算法)
%net.trainFcn = 'trainlm'; % Levenberg-Marquardt算法,内存需求最大,收敛速度最快
% net.trainFcn = 'trainbr'; % 贝叶斯正则化算法
%
% 有代表性的五种算法为:'traingdx','trainrp','trainscg','trainoss', 'trainlm'
%% 训练网络
net = train(net, p_train, t_train);
%% 仿真测试
t_sim1 = sim(net, p_train);
t_sim2 = sim(net, p_test);
%% 数据反归一化
T_sim1 = mapminmax('reverse', t_sim1, ps_output);
T_sim2 = mapminmax('reverse', t_sim2, ps_output);
%% 均方根误差
error1 = sqrt(sum((T_sim1 - T_train).^2) ./ M);
error2 = sqrt(sum((T_sim2 - T_test ).^2) ./ N);
%% 绘图
figure
plot(1: M, T_train, 'r-*', 1: M, T_sim1, 'b-o', 'LineWidth', 1)
legend('真实值','预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'训练集预测结果对比'; ['RMSE=' num2str(error1)]};
title(string)
xlim([1, M])
grid
figure
plot(1: N, T_test, 'r-*', 1: N, T_sim2, 'b-o', 'LineWidth', 1)
legend('真实值','预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'测试集预测结果对比';['RMSE=' num2str(error2)]};
title(string)
xlim([1, N])
grid
%% 相关指标计算
% 决定系数 R2
R1 = 1 - norm(T_train - T_sim1)^2 / norm(T_train - mean(T_train))^2;
R2 = 1 - norm(T_test - T_sim2)^2 / norm(T_test - mean(T_test ))^2;
disp(['训练集数据的R2为:', num2str(R1)])
disp(['测试集数据的R2为:', num2str(R2)])
% 平均绝对误差 MAE
mae1 = sum(abs(T_sim1 - T_train)) ./ M ;
mae2 = sum(abs(T_sim2 - T_test )) ./ N ;
disp(['训练集数据的MAE为:', num2str(mae1)])
disp(['测试集数据的MAE为:', num2str(mae2)])
% 平均相对误差 MBE
mbe1 = sum(T_sim1 - T_train) ./ M ;
mbe2 = sum(T_sim2 - T_test ) ./ N ;
disp(['训练集数据的MBE为:', num2str(mbe1)])
disp(['测试集数据的MBE为:', num2str(mbe2)])
4.效果展示
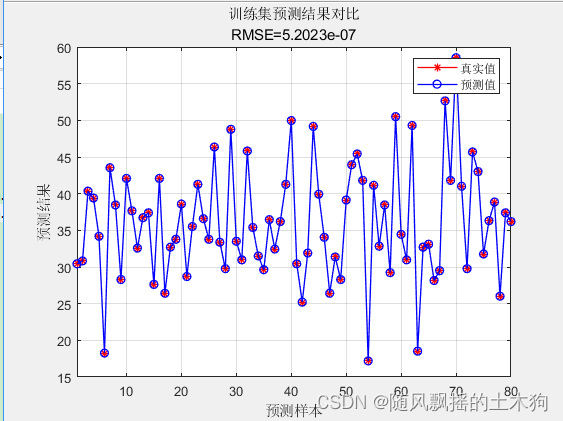
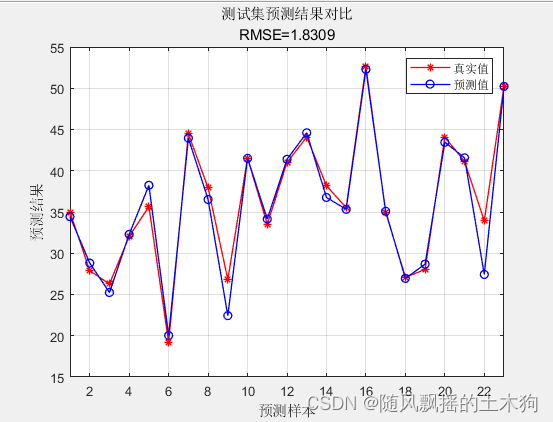
训练集数据的R2为:1
测试集数据的R2为:0.94759
训练集数据的MAE为:3.6159e-07
测试集数据的MAE为:1.0637
训练集数据的MBE为:-2.0744e-07
测试集数据的MBE为:-0.43051
三、总结
因工具箱版本和无工具箱版本训练方法不同,以及有工具箱版本内置默认参数较为丰富 ,如连续验证最大失败数量、训练集再划分样本等等参数 ,且trainlm函数功能强大,用代码编写比较复杂 。故有工具版计算结果较好,收敛速度较快,使用方便,而无工具箱版本则更能直观的观察数据变化以及能够更直观体现BP神经网络计算原理。
四、代码获取
私信回复“57期”即可获取下载链接。