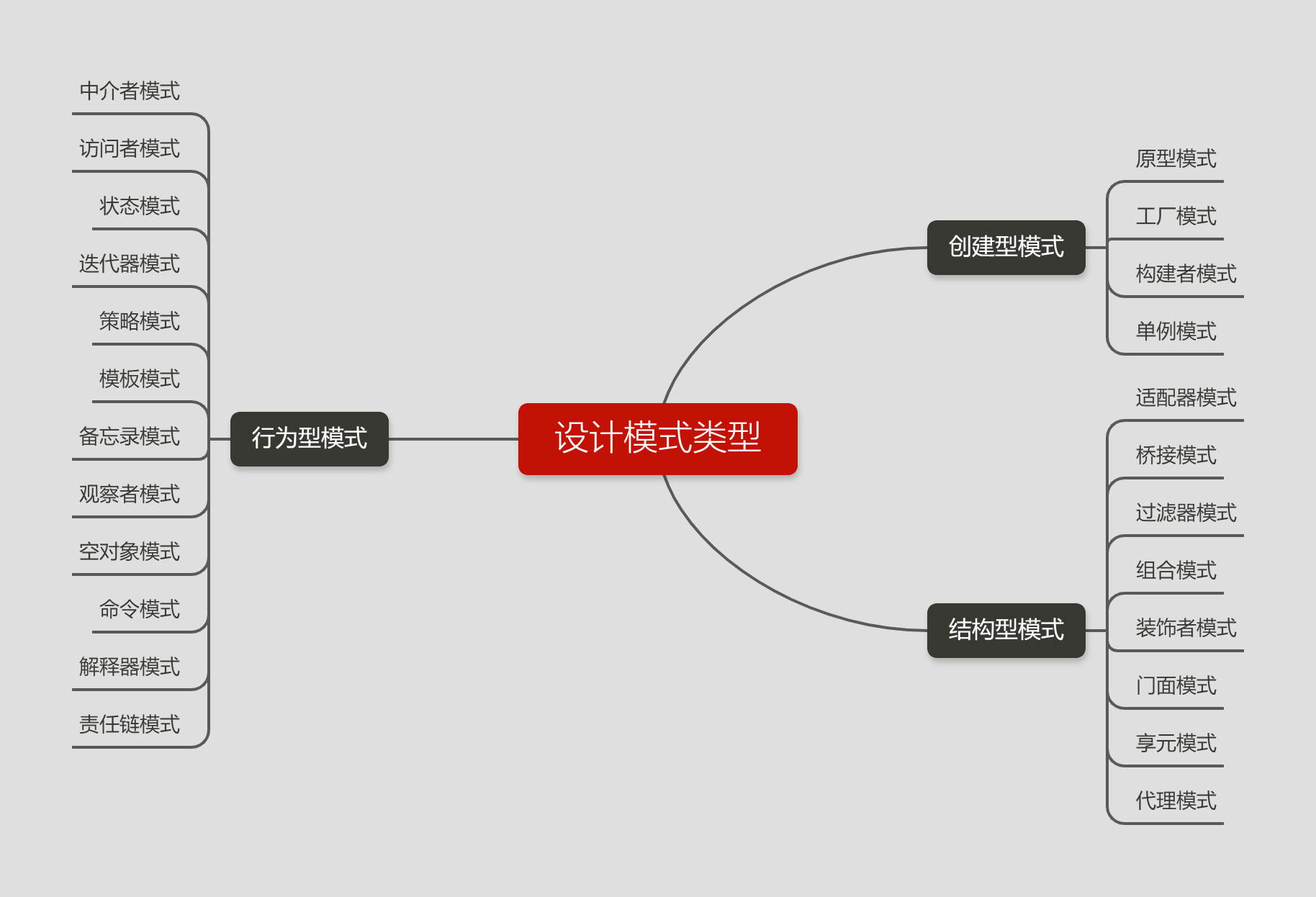
在深度学习领域中,数据的标注方式和对应的数据格式确实五花八门。下面是一些常见的标注方式和对应的数据格式:
-
- 目标检测标注方式:对于图像目标检测任务,常见的标注方式包括Bounding Box、Mask、Keypoint等。其中,
- Bounding Box指的是在图像中用矩形框标记出目标的位置和大小,通常用左上角和右下角的坐标表示;
- Mask指的是将目标的轮廓用像素点进行标记,通常用二值图像表示;
- Keypoint指的是在目标上标记出关键点的位置,通常用关键点坐标表示。
- 这些标注方式通常用XML、JSON、CSV等格式进行存储。
-
- 分割标注方式:对于图像分割任务,常见的标注方式包括Semantic Segmentation、Instance Segmentation等。其中,
- Semantic Segmentation指的是将图像中的每个像素都进行分类,以实现对图像的整体理解;
- Instance Segmentation指的是将图像中的每个目标都进行分割,以实现对目标的精细理解。
- 这些标注方式通常用PNG、JPEG、TIFF等格式进行存储。
在公开数据中,有一些特色代表性的标注文件存储格式,例如:
-
- COCO:这是一个广泛使用的图像目标检测和分割数据集,其标注文件采用JSON格式进行存储。
-
- Pascal VOC:这是一个经典的图像目标检测和分割数据集,其标注文件采用XML格式进行存储。
-
- ImageNet:这是一个包含超过1400万张图像的数据集,其标注文件采用TXT格式进行存储,每张图像对应一个TXT文件。
-
- Open Images:这是一个由Google发布的大规模图像数据集,其标注文件采用CSV格式进行存储。
本文主要记录在yolo系列目标检测和分割算法中,尝尝会将json文件,转为yolo所需要的txt文件。分别包括了目标检测和分割的数据转换形式。
一、yolov5的bbox另存为txt
yolov5的bbox目标检测中,数据形式是(x-center,y_center, width, height)。都是图像的相对大小
import numpy as np
import os
from PIL import Image
import json
import pandas as pd
label_list = ['a', 'b']
class LabelJson(object):
def __init__(self, abs_path=None, mode='saveTXT') -> None:
super().__init__()
self.abs_path = abs_path
self.mode = mode
self.read()
def read(self):
with open(self.abs_path,'r', encoding='utf-8') as f:
lj = json.load(f)
self.wh = [lj.get('imageWidth'), lj.get('imageHeight')]
shapes = lj.get('shapes')
if self.mode=='saveTXT':
self.cls = [i.get('label') for i in shapes]
points = [i.get('points') for i in shapes]
points = [np.array(i, dtype=np.int32).reshape((-1, 2)) for i in points]
self.loc = points
self.box = [[j[:, 0].min(), j[:, 1].min(), j[:, 0].max(), j[:, 1].max()] for j in points]
self.img_name=lj.get('imagePath')
self.is_pos = bool(self.cls)
return self
def saveTXT_bbox(json_info, save_path, imp):
box = np.array(json_info.box)
w, h = json_info.wh
cls = json_info.cls
if w is None:
img = Image.open(imp)
w, h = img.size
print(cls)
with open(save_path, 'w', encoding='utf-8') as ff:
for idx, (xmin, ymin, xmax, ymax) in enumerate(box):
label = cls[idx].split('-')[0]
ff.write(f'{label_list.index(label)} {(xmin+xmax)/(2*w)} {(ymin+ymax)/(2*h)} {(xmax-xmin)/w} {(ymax-ymin)/h}\n')
def json2txtBbox_main(img_dir, json_dir, save_dir):
for imgfile in os.listdir(img_dir):
print(imgfile)
name, suffix = os.path.splitext(imgfile)
json_path = os.path.join(json_dir, name + '.json')
if os.path.exists(json_path):
img_path = os.path.join(img_dir, imgfile)
json_info = LabelJson(json_path, mode='saveTXT')
saveTXT_bbox(json_info, os.path.join(save_dir, name + '.txt'), img_path)
if __name__=="__main__":
img_dir = r'./image'
json_dir = r'./label'
save_dir = r'./txt'
json2txtBbox_main(img_dir, json_dir, save_dir)
保存后的txt文件,存储内容为:

二、yolov8的mask另存为txt
在yolov8中,可以实现对目标的分割,其中分割数据集文件中单行的格式如下:
<class-index> <x1> <y1> <x2> <y2> ... <xn> <yn>
- class-index: is the index of the class for the object,
- x1 y1 x2 y2 … xn yn: are the bounding coordinates of the object’s segmentation mask.
例如:
0 0.6812 0.48541 0.67 0.4875 0.67656 0.487 0.675 0.489 0.66
1 0.5046 0.0 0.5015 0.004 0.4984 0.00416 0.4937 0.010 0.492 0.0104
数据整理定义参考链接:Ultralytics YOLOv8 Docs
Instance Segmentation Datasets Overview
实现代码如下所示:
def saveTXT_mask(json_info, save_path, imp):
points = json_info.loc
w, h = json_info.wh
cls = json_info.cls
if w is None:
img = Image.open(imp)
w, h = img.size
with open(save_path, 'w', encoding='utf-8') as ff:
for idx, point in enumerate(points):
label = cls[idx]
coor_str = ''
for (x, y) in point:
coor_str += str(round(x/w, 4))+' '+str(round(y/h, 4))+' '
print("coor_str:", coor_str)
ff.write(f'{label_list.index(label)} {coor_str}\n')
def json2txtMask_main(img_dir, json_dir, save_dir):
for imgfile in os.listdir(img_dir):
print(imgfile)
name, suffix = os.path.splitext(imgfile)
json_path = os.path.join(json_dir, name + '.json')
if os.path.exists(json_path):
img_path = os.path.join(img_dir, imgfile)
json_info = LabelJson(json_path, mode='saveTXT')
saveTXT_mask(json_info, os.path.join(save_dir, name + '.txt'), img_path)
if __name__ == "__main__":
img_dir = r'./image'
json_dir = r'./label'
save_dir = r'./txt'
json2txtMask_main(img_dir, json_dir, save_dir)
保存后的txt文件,存储内容为:

三、总结
整个过程大致就分为以下几步:
- 读取原数据存储文件,拿到需要转储的对应的数字
- 转化为新的数组形式
- 另存为新的文件格式
最后,记得检查下转储后的文件是否正确。这个可以在训练阶段,查看训练过程中生成的图片,记录了标签和图像合并到一起之后的结果。帮助我们检验下制作的标注文件,是否有问题,并做出及时的调整。