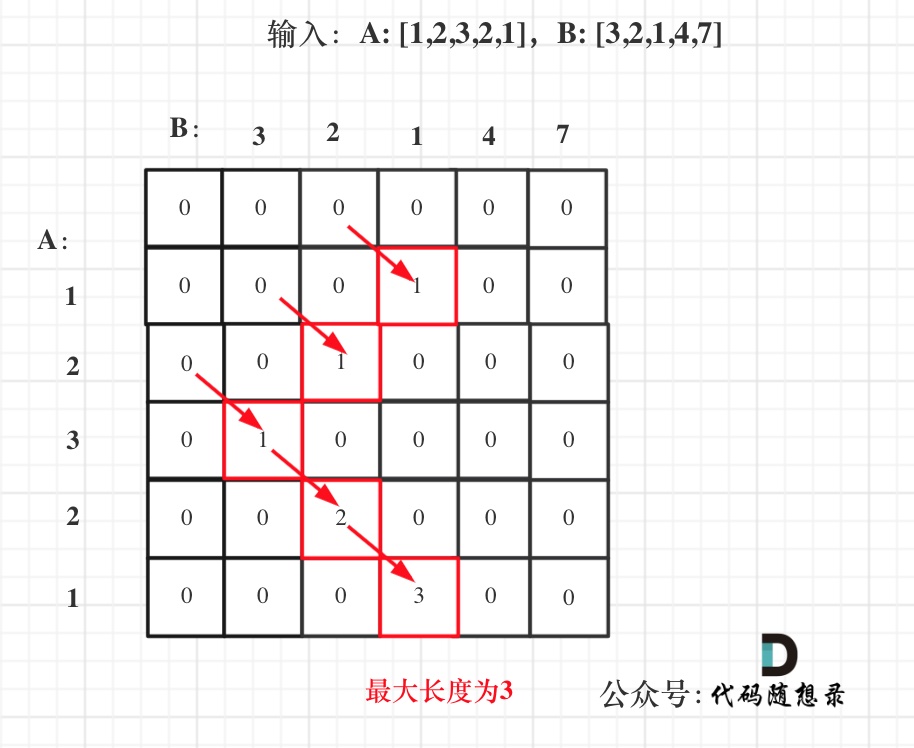
一、说明
训练深度学习模型是一个耗时的过程。您可以在训练期间和训练后保存模型进度。因此,您可以从上次中断的地方继续训练模型,并克服漫长的训练挑战。
在这篇博文中,我们将介绍如何保存模型并使用 Keras 逐步加载它。我们还将探索模型检查点回调,它通常用于模型训练。
二、加载数据集
为了演示如何保存模型,让我们使用 MNIST 数据集。此数据集由数字图像组成。

MNIST 数据集
在加载 MNIST 数据集之前,让我们先导入 TensorFlow 和 Keras。
import tensorflow as tf
from tensorflow import keras现在,让我们使用 Keras 中的方法加载训练和测试数据集。load_data
(train_images,train_labels),(test_images,test_labels)=tf.keras.datasets.mnist.load_data()训练输入和输出数据集由 60,000 个样本组成,测试输入和输出数据集由 10,000 个样本组成。
三、数据预处理
数据分析最重要的步骤之一是数据预处理。在深度学习中,一些数据预处理技术(如规范化和正则化)可以提高模型的性能。
首先,让我们从这些数据集中获取前 1000 个样本,以更快地运行代码。让我们先对输出变量执行此操作。
train_labels = train_labels[:1000]
test_labels = test_labels[:1000]我们将对训练数据执行相同的操作。数据样本由数字图像组成。这些图像是二维的。在将这些示例提供给模型之前,让我们使用该方法将它们转换为维度。此外,让我们规范化数据以提高模型的性能并使训练速度更快。reshape
train_images = train_images[:1000].reshape(-1, 28 * 28) / 255.0
test_images = test_images[:1000].reshape(-1, 28 * 28) / 255.0很好,我们的数据集已经为模型做好了准备。让我们继续前进到模型构建步骤。
四、如何构建模型
构建深度学习模型的最简单方法是 Keras 中的顺序技术。在这种技术中,层被逐个堆叠。我们现在要做的是定义一个包含模型的函数。通过这样做,我们可以更轻松地构建模型。
def create_model():
model = tf.keras.Sequential([
keras.layers.Dense(512, activation='relu',input_shape=(784,)),
keras.layers.Dropout(0.2),
keras.layers.Dense(10)
])
model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()]
)
return model让我们来看看这些代码。首先,我们定义一个使用 Keras 创建和编译顺序模型的函数。
我们构建了一个包含两个密集层的模型,第一个层具有512个神经元和一个激活函数。我们还设置了一个 dropout 层,该层随机丢弃 20% 的输入单元,以帮助防止过度拟合。之后,我们编写了一个包含 10 个没有激活函数的神经元的密集层,因为它将用于 logits。relu
接下来,我们使用优化器和损失函数编译模型。作为指标,我们设置 .AdamSparseCategoricalCrossentropySparseCategoricalAccuracy
最后,我们使用语句返回已编译的模型。return
太棒了,我们已经定义了一个简单的顺序模型。现在,让我们从这个函数中获取一个名为 model 的示例对象。
model = create_model()现在让我们看看使用摘要方法的模型的体系结构。
model.summary()
如您所见,我们的模型由输入层、辍学层和输出层组成。让我们继续探索回调。ModelCheckpoint
五、使用模型检查点回调保存模型权重
可以保存模型以重用已训练的模型,或从上次中断的位置继续训练。
如您所知,构建模型实际上意味着训练模型的权重,称为参数。通过回调,您可以在模型训练期间保存模型的权重。为了说明这一点,让我们从这个回调实例化一个对象。ModelCheckpoint
首先,让我们创建模型将与 os 模块一起保存的目录。
import os
checkpoint_path = "training_1/my_checkpoints"
checkpoint_dir = os.path.dirname(checkpoint_path)很好,我们已经创建了目录。现在让我们创建一个回调来保存模型的权重。
checkpoint_cb = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_path,
# Let's save only the weights of the model
save_weights_only=True) 太好了,我们已经创建了回调。现在,让我们调用该方法和对此方法的回调。fitpass
model.fit(train_images,
train_labels,
epochs=10,
validation_data=(test_images, test_labels),
callbacks=[checkpoint_cb])
因此,我们将模型权重保存在目录中。我们使用的回调在每个纪元结束时更新检查点文件。让我们使用 os 模块查看目录中的文件。
os.listdir(checkpoint_dir)
# Output
['my_checkpoints.index', 'my_checkpoints.data-00000-of-00001', 'checkpoint']如您所见,权重是在最后一个纪元之后保存的。让我们继续看看如何加载重量。
六、装载权重
保存权重后,可以将其加载到模型中。请注意,您只能将保存的权重用于具有相同体系结构的模型。
让我们实例化一个对象来演示这一点。
model = create_model() 请注意,我们尚未训练此模型的权重。这些权重是随机生成的。现在让我们看看这个未经训练的模型在测试数据上的准确性分数。evaluate
loss, acc = model.evaluate(test_images, test_labels, verbose=2)
print(f"Untrained model, accuracy: {100 * acc:5.2f}%")
# Output:
Untrained model, accuracy: 10.70%如您所见,未经训练的模型在测试数据上的准确率约为 10%。这是一个相当糟糕的分数,对吧?
现在,让我们加载之前使用该方法保存的权重,然后查看此模型在测试数据上的准确性得分。load_weights
model.load_weights(checkpoint_path)太棒了,我们加载了重量。现在,让我们检查此模型在测试集上的性能。
loss, acc = model.evaluate(test_images, test_labels, verbose=2)
print(f"Untrained model, accuracy: {100 * acc:5.2f}%")
#Output:
Untrained model, accuracy: 87.40%如您所见,事实证明该模型的准确率约为90%。
在本节中,我们已经了解了如何保存模型权重以及如何加载它们。现在让我们继续探索如何保存整个模型。
七、保存整个模型
q 训练模型后,可能需要部署该模型。若要将模型的体系结构、权重和训练配置保存在单个文件中,可以使用该方法。save
您可以将模型保存为两种不同的格式,以及 .请记住,在 Keras 中,默认情况下使用该格式。让我们保存最终模型。让我们为它创建一个目录。SaveModelHDF5SavedModel
mkdir saved_model现在让我们将模型保存在此文件中。
model.save('saved_model/my_model')太好了,我们保存了我们的模型。让我们看一下此目录中的文件。
ls saved_model/my_model
# Output:
assets fingerprint.pb keras_metadata.pb saved_model.pb variables 在这里,您可以看到文件和子目录。不需要模型的源代码即可将模型投入生产。 足以进行部署。让我们仔细看看这些文件。SavedModel
该文件包含模型的体系结构和计算图形。saved_model.pd
该文件包含 Keras 所需的额外信息。keras_metadata.pb
子目录包含权重和偏差等参数值。variables
子目录包含额外的文件,例如属性和类的名称。assets
很好,我们看到了如何保存整个模型。现在让我们看看如何加载模型。
八、加载模型
您可以使用该方法加载保存的模型。为此,让我们首先创建模型体系结构,然后加载模型。load_model
new_model = create_model()
new_model = tf.keras.models.load_model('saved_model/my_model')太棒了,我们已经加载了模型。让我们看一下这个模型的架构。
new_model.summary()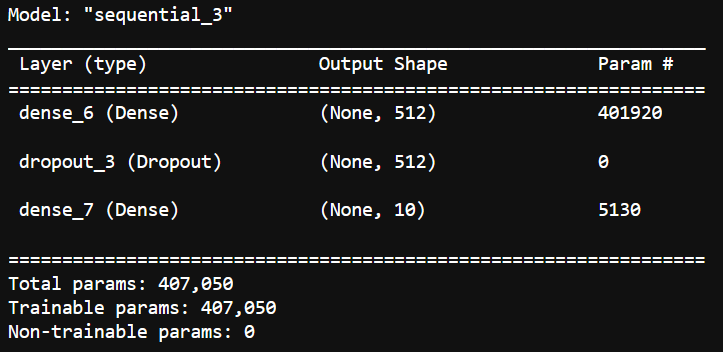
请注意,此模型是使用与原始模型相同的参数编译的。让我们看看这个模型在测试数据上的准确性。
loss, acc = new_model.evaluate(test_images, test_labels, verbose=2)
print(f'Restored model, accuracy: {100 * acc:5.2f}%')
# Output:
Restored model, accuracy: 87.40%如您所见,我们保存在测试数据上的模型的准确性得分为 87%。
您还可以以格式保存模型。但是大多数TensorFlow部署工具都需要这种格式。h5SavedModel
九、总结
训练模型时,可以保存模型以从上次中断的地方继续。通过保存模型,您还可以共享您的模型并允许其他人重新创建您的工作。
在这篇博文中,我们介绍了如何保存和加载深度学习模型。首先,我们学习了如何使用回调保存模型权重。接下来,我们看到了保存和加载整个模型以部署模型。ModelCheckpoint
感谢您的阅读。您可以在此处找到笔记的链接。
参考资料:
如何使用 Keras 保存和加载深度学习模型? |迈向人工智能 (towardsai.net)