HTTP的Keep-Alive
HTTP协议采用的是[请求-应答]模式,也就是客户端发起请求,服务端才会响应请求,一来一回这个样子。
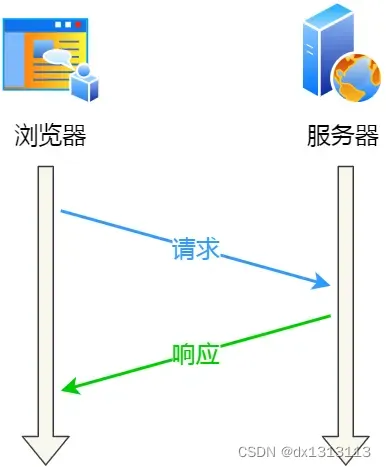
由于HTTP是基于TCP传输协议实现的,客户端与服务端需要进行HTTP通信前,需要先建立TCP连接,然后客户端发送HTTP请求,服务端收到后就返回响应,至此[请求-应答]的模式就完成了,随后就会释放TCP连接。
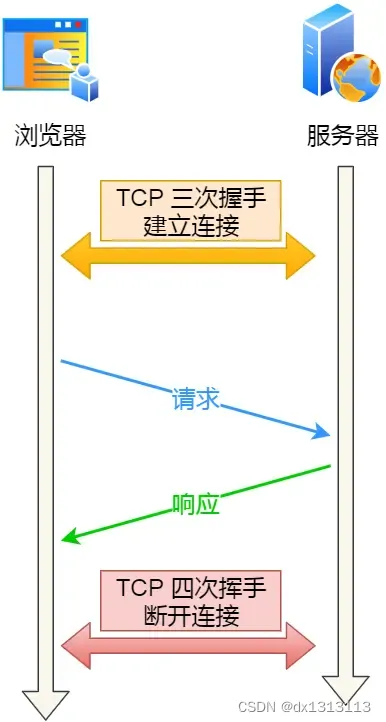
如果每次请求都要经历这样的过程:建立TCP->响应资源->释放连接,这种方式被称为HTTP短连接:
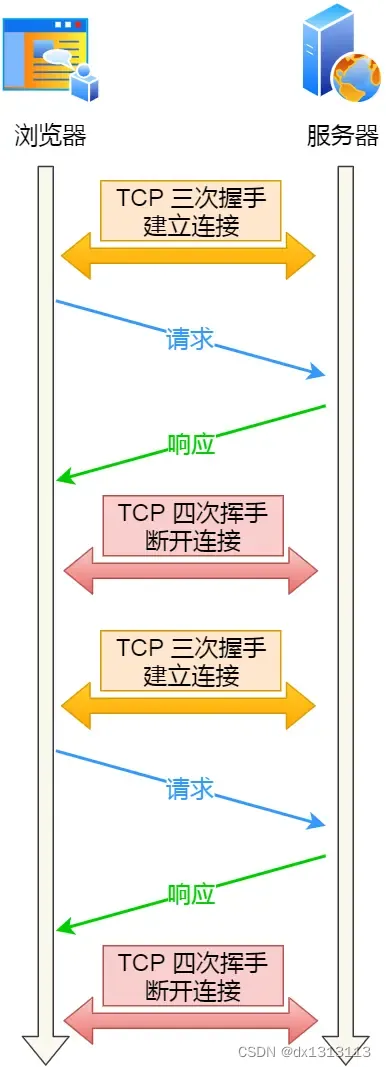
这种但是一次连接只能请求一次资源,实在是过于麻烦。所以,能不能在第一个HTTP请求后,先不断开TCP连接,让后续的HTTP请求继续使用此连接?
HTTP的Keep-Alive就是实现此功能的,可以使用同一个TCP连接来发送和接收多个HTTP请求/应答,避免了连接建立和释放的开销,这个方法称为HTTP长连接
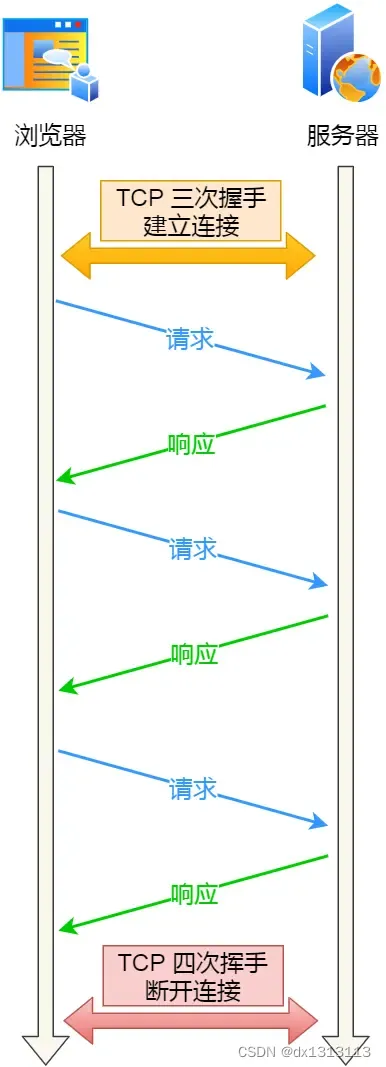
HTTP长连接的特点是:只要任意一端没有明确提出断开连接,则保持TCP连接状态。
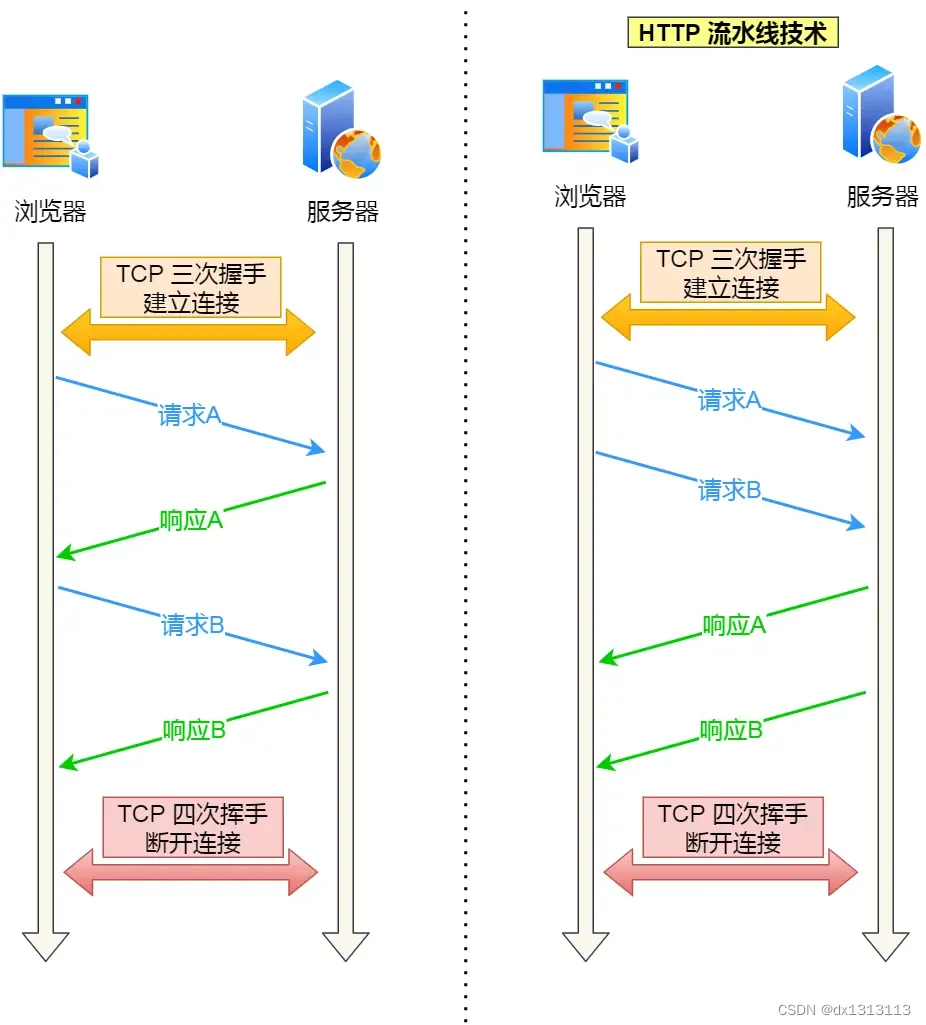
HTTP长连接不仅仅减少了TCP连接资源的开销,而且这给HTTP流水线技术提供了可实现的基础。
HTTP流水线:客户端可以先一次性发送多个请求,而在发送过程中不需先等待服务器的回应,可以减少整体的响应时间。
举例:客户端需要请求两个资源,以前的做法是,在同一个TCP连接里,先发送A请求,然后等待服务器做出回应,收到后在发送B请求。HTTP流水线机制则允许客户端同时发出A请求和B请求。
但是服务器还是按照顺序响应,先回应A请求,完成后再回应B请求。
而且要等待服务器响应完客户端第一批发送的请求后,客户端才能发出下一批请求,也就是说服务器响应的过程发生了阻塞,那么客户端就无法发出下一批请求,此时就造成了[对头阻塞]的问题。
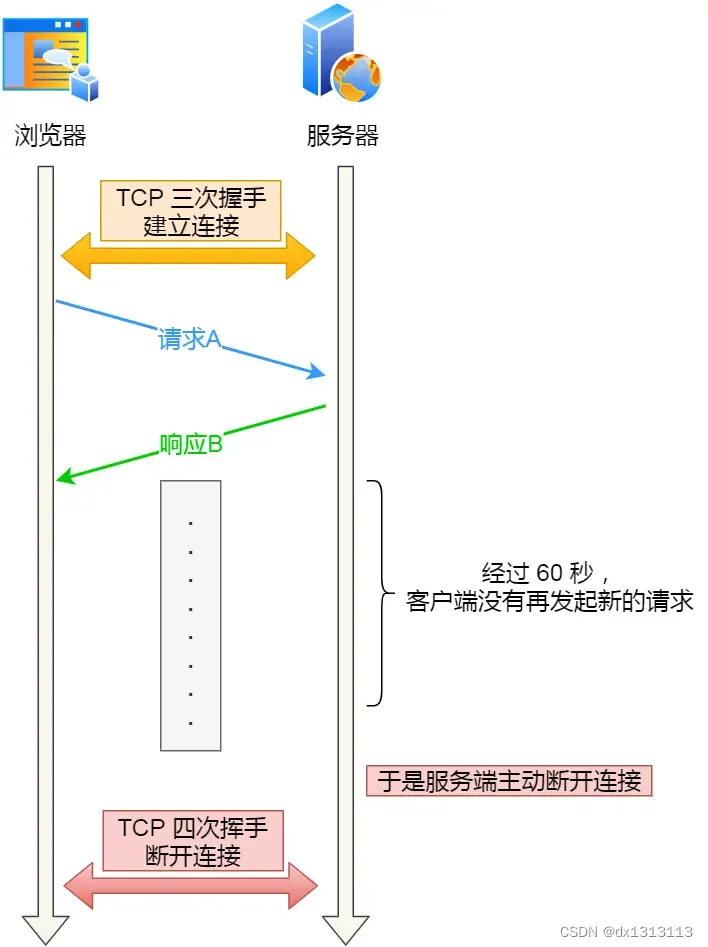
如果使用了HTTP长连接后,客户端完成了一个HTTP请求就不再发起新的请求,此时这个TCP连接一直占用着会浪费资源。
为了避免资源浪费的情况,web服务器一般会提供keepalive_timeout参数,用来指定HTTP长连接的超时时间。在完成最后一个HTTP请求后,web服务软件会启动一个定时器,如果在改keepalive_timeout时间内没有再发起新的请求,*定时器的时间一到,就会触发回调函数来释放该连接。
TCP的Keep-Alive
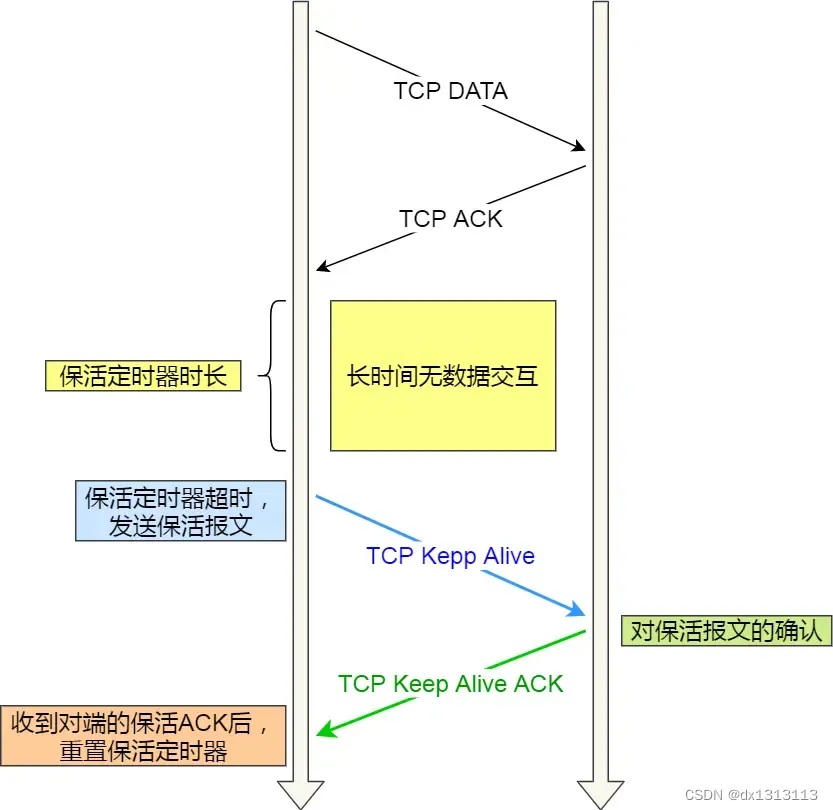
TCP的KeepAlive其实就是TCP的保活机制:
如果两端的TCP连接一直没有数据交互,达到了触发TCP保活机制的条件,那么内核的TCP协议栈就会发送探测报文.。
- 如果对端程序是正常工作的。当TCP保活的探测报文发送给对端,对端会正常响应,这样TCP保活会被重置,等待下一个TCP保活时间的到来。
- 如果对端主机宕机(注意不是进程崩溃,进程崩溃后操作系统在回收进程资源的时候,会发送FIN报文,而主机宕机则是无法感知的,所以需要TCP保活机制来探测对方是不是发生了主机宕机),或对端由于其他原因导致报文不可达。当TCP保活的探测报文发送给对端后,没有响应,连续几次,达到保活探测次数后,TCP会报告该TCP连接已经死亡。
所以,TCP保活机制可以在双方没有数据交互的情况下,通过探测报文来确定对方的TCP连接是否存活,这个工作是在内核中完成的。
注意,应用程序如果想用TCP的保活机制,需要通过socket接口设置SO_KEEPALIVE选项才能够生效,如果没有设置,那么就无法使用TCP保活机制。
总结
- HTTP的Keep-Alive 也叫HTTP长连接,该功能是由[应用程序]实现的,可以使得同一个TCP来发送和接收多个HTTP请求/应答,减少了HTTP短连接带来的多次TCP连接建立和释放的开销。
- TCP的Keep-Alive也叫TCP的保活机制,该功能是由[内核]实现的,当客户端和服务端长达一定时间没有进行数据交互的时候,内核为了确保该连接是否还有效,就会发送探测报文,来检测对方是否在线,然后来决定是否要关闭该连接。