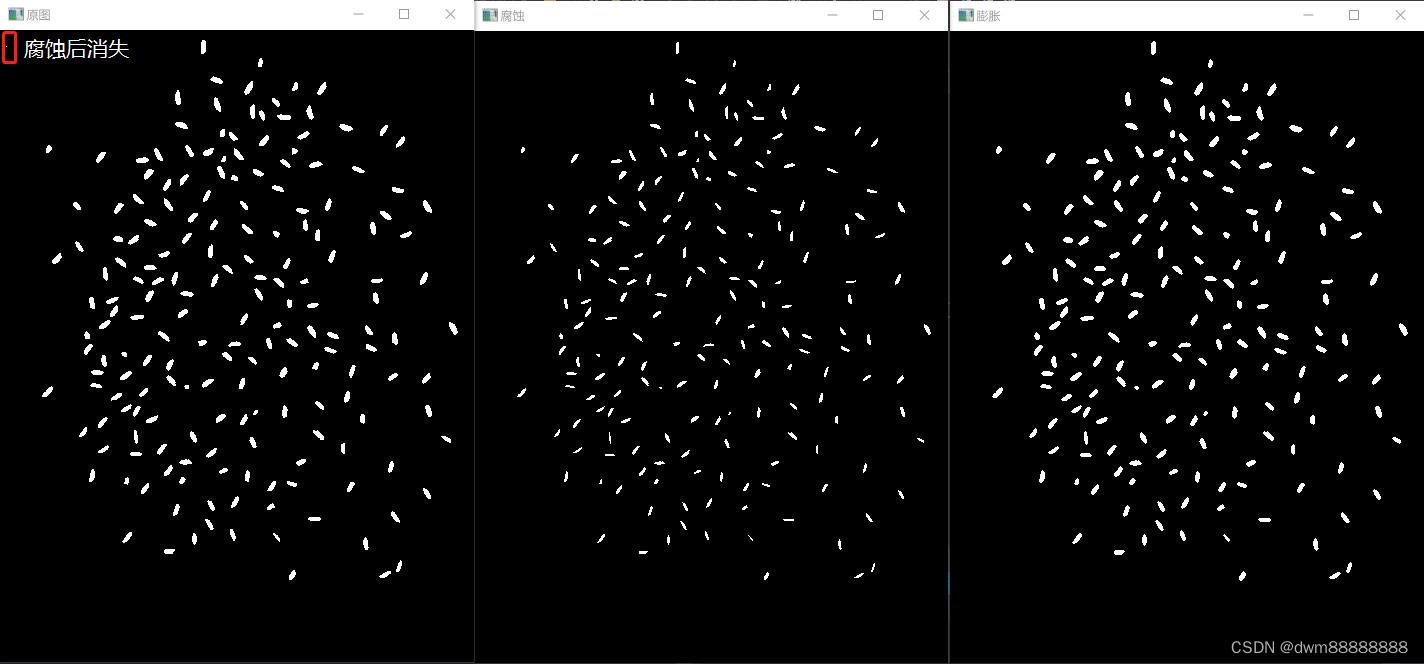
1 简介
DB2是IBM的一款优秀的关系型数据库,简单学习一下。
2 Docker安装DB2
为了快速启动,直接使用Docker来安装DB2。先下载镜像如下:
docker pull ibmcom/db2
# or
docker pull ibmcom/db2:11.5.0.0启动数据库如下:
docker run -itd \
--name mydb2 \
--privileged=true \
-p 50000:50000 \
-e LICENSE=accept \
-e DB2INST1_PASSWORD=pkslow \
-e DBNAME=testdb \
ibmcom/db2:11.5.0.0
# or
docker run -itd \
--name mydb2 \
--privileged=true \
-p 50000:50000 \
-e LICENSE=accept \
-e DB2INST1_PASSWORD=<choose an instance password> \
-e DBNAME=testdb \
-v <db storage dir>:/database ibmcom/db2这样获得的数据库,具体信息如下:
- 连接URL:
jdbc:db2://localhost:50000/testdb- 用户名:
db2inst1- 密码:
pkslow
在IDEA上连接如下:

默认的Schema为DB2INST1,测试SQL如下:
创建表:
# 创建自增主键数据库表
# 建表SQL
CREATE TABLE TEST_SCHEMA.mytest_increment_key_table(id BIGINT NOT NULL GENERATED ALWAYS AS IDENTITY(START WITH 1,INCREMENT BY 1,NO CACHE)
PRIMARY KEY, timer_wheel_id BIGINT NOT NULL, create_time TIMESTAMP NOT NULL);插入数据:
insert into TEST_SCHEMA.mytest_increment_key_table(timer_wheel_id, create_time) values (1, '2022-03-06 23:12:21.333')查询:
SELECT * FROM TEST_SCHEMA.mytest_increment_key_table;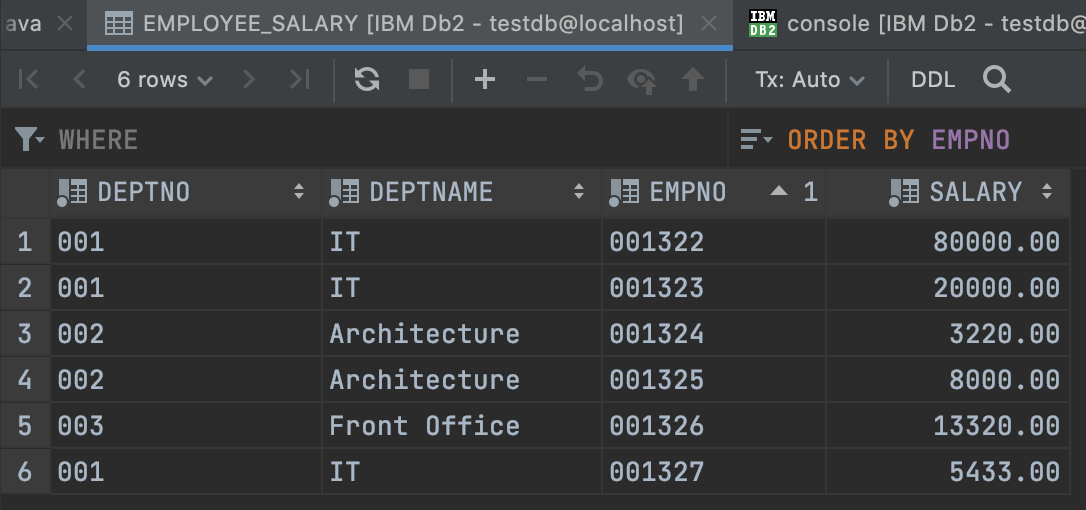
Spring Boot整合DB2
添加相关依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!-- 定义公共资源版本 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.12</version>
<relativePath/>
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>11</java.version>
<project-name>druid-hibernate-db2</project-name>
</properties>
<groupId>org.find</groupId>
<artifactId>${project-name}</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>${project-name}</name>
<description>${project-name}</description>
<dependencies>
<!-- ============= db2 数据库 start ============== -->
<!--阿里druid数据库链接依赖-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.16</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- 引入jpa -->
<!--依赖下面的spring-boot-starter-jdbc-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!--事务管理:原子性,一致性,隔离性,持久性-->
<!--依赖下面的spring-jdbc-->
<!--<dependency>-->
<!-- <groupId>org.springframework.boot</groupId>-->
<!-- <artifactId>spring-boot-starter-jdbc</artifactId>-->
<!--</dependency>-->
<!--<dependency>-->
<!-- <groupId>org.springframework</groupId>-->
<!-- <artifactId>spring-jdbc</artifactId>-->
<!-- <version>4.1.0.RELEASE</version>-->
<!--</dependency>-->
<!--db2链接依赖-->
<!--<dependency>-->
<!-- <groupId>com.ibm.db2</groupId>-->
<!-- <artifactId>db2jcc4</artifactId>-->
<!-- <version>4.32.28</version>-->
<!--</dependency>-->
<dependency>
<groupId>com.ibm.db2</groupId>
<artifactId>jcc</artifactId>
</dependency>
<!-- ============= db2 数据库 end ============== -->
<!-- ================== 应用 =================== -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.1-jre</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.32</version>
</dependency>
<!-- javax api -->
<dependency>
<groupId>javax.inject</groupId>
<artifactId>javax.inject</artifactId>
<version>1</version>
</dependency>
<!-- 上边引入 parent,因此 下边无需指定版本 -->
<!-- 包含 mvc,aop 等jar资源 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 解决资源文件的编码问题 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<configuration>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<!-- maven打source包 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-source-plugin</artifactId>
<executions>
<execution>
<id>attach-sources</id>
<!--<phase>verify</phase>-->
<goals>
<!--jar, jar-no-fork-->
<goal>jar</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- spring Boot在编译的时候, 是有默认JDK版本的, 这里自定义指定JDK版本 -->
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>11</source>
<target>11</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<!--拷贝依赖jar到指定的目录-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<!-- maven-jar-plugin用于生成META-INF/MANIFEST.MF文件的部分内容, -->
<addClasspath>true</addClasspath>
<!-- 指定依赖包所在目录。 -->
<classpathPrefix>lib/</classpathPrefix>
<!-- 指定MANIFEST.MF中的Main-Class, -->
<mainClass>org.fiend.MySpringbootApp</mainClass>
<useUniqueVersions>false</useUniqueVersions>
</manifest>
</archive>
<excludes>
<!--<exclude>*.properties</exclude>-->
<!--<exclude>*.yml</exclude>-->
<!--<exclude>*.xml</exclude>-->
<!--<exclude>org/fiend/controller/HomeController.class</exclude>-->
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>配置相关属性:
# tidb 环境配置
server:
port: 8100
max-http-header-size: 8192
tomcat:
max-connections: 10000 # 最大连接数, 默认为10000
accept-count: 500 # 最大连接等待数, 默认100
threads:
max: 475 # 最大工作线程数, 默认200
min-spare: 400 #最小工作线程数, 默认10
servlet:
encoding:
charset: UTF-8
force: true
enabled: true
logging:
level:
root: info
spring:
application:
name: druid-hibernate-db2
main:
allow-bean-definition-overriding: true
datasource:
url: jdbc:db2://192.168.1.22:50000/MYTEST:currentSchema=TEST_SCHEMA;
username: username
password: 123123
driver-class-name: com.ibm.db2.jcc.DB2Driver
# type: com.alibaba.druid.pool.DruidDataSource
type: com.alibaba.druid.pool.DruidDataSource
# 连接池配置
initial-size: 5
max-active: 20
max-idle: 10
min-idle: 5
# # ============================== druid ============================== #
druid:
# 最大活跃数
maxActive: 20
# 初始化数量
initialSize: 1
# 最大连接等待超时时间
maxWait: 60000
# 打开PSCache, 并且指定每个连接PSCache的大小
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
#通过connectionProperties属性来打开mergeSql功能;慢SQL记录
#connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
minIdle: 1
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
# validationQuery: select 1 from dual
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
#配置监控统计拦截的filters, 去掉后监控界面sql将无法统计,'wall'用于防火墙
filters: stat, wall, log4j
# ============================= spring jpa 配置 ============================= #
jpa:
# 禁止 hibernate sql 输出
show-sql: false
database-platform: org.hibernate.dialect.DB2Dialect
hibernate:
# create, create-drop, update, none 和 validate 五个属性
# create : Create the schema and destroy previous data. 会根据model类来生成表,但是每次运行都会删除上一次的表,重新生成表,哪怕2次没有任何改变
# create-drop : Create and then destroy the schema at the end of the session.
# 根据model类生成表,但是sessionFactory一关闭,表就自动删除
# update : Update the schema if necessary. 最常用的属性, 也根据model类生成表,即使表结构改变了,表中的行仍然存在,不会删除以前的行
# validate : Validate the schema, make no changes to the database.
# 只会和数据库中的表进行比较,不会创建新表, 但是会插入新值
# none : Disable DDL handling.
# 这里优先级较低(相对hbm2ddl.auto),不会生效
ddl-auto: none
properties:
hibernate:
dialect: org.hibernate.dialect.DB2Dialect
# 用于配置自动创建、更新或验证数据库表结构的行为
# 1. create:每次应用程序启动时,Hibernate 会删除现有的数据库表并重新创建它们。这是最简单的选项,但也是最危险的选项,因为它会丢失所有现有数据。
# 2. update:每次应用程序启动时,Hibernate 会检查数据库表结构与映射文件(或实体类)的差异,并根据需要更新表结构。如果表不存在,Hibernate将创建新表;如果表已经存在,它将添加缺少的列或索引。但是,它不会删除或修改现有的列或约束。这是在开发和测试环境中常用的选项。
# 3. validate:Hibernate 会在应用程序启动时验证数据库表结构与映射文件(或实体类)是否匹配,但不会对其进行任何更改。如果存在结构不匹配的情况,Hibernate会抛出异常并停止应用程序启动。
# 4. none:Hibernate 不会自动创建、更新或验证数据库表结构。这意味着您需要手动管理数据库表结构的创建和更新。
# 请注意,虽然 hbm2ddl.auto 属性在开发和测试环境中可能很方便,但在生产环境中慎重使用。
# 在生产环境中,建议手动管理数据库表结构,并使用数据库迁移工具(如Flyway或Liquibase)来进行版本控制和演化
hbm2ddl.auto: none
jdbc.lob.non_contextual_creation: true
format_sql: true
temp:
# 兼容SpringBoot2.X, 关闭 Hibernate尝试验证Mysql的CLOB特性
use_jdbc_metadata_defaults: false
创建Entity:
package org.fiend.entity;
import com.fasterxml.jackson.annotation.JsonFormat;
import com.fasterxml.jackson.annotation.JsonProperty;
import org.springframework.format.annotation.DateTimeFormat;
import javax.persistence.*;
import javax.validation.constraints.NotNull;
import java.io.Serializable;
import java.sql.Timestamp;
/**
* @author langpf 2023/06/10
*/
@Entity
@Table(catalog = "TEST_SCHEMA", name = "mytest_increment_key_table")
public class IncrementKeyEntity implements Serializable {
@Id
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "timer_wheel_id", nullable = false)
private Long timerWheelId;
@NotNull(message = "create_time 不可为空!")
@JsonProperty("create_time")
@Column(name = "create_time", nullable = false, columnDefinition = "timestamp")
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss.SSS")
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss.SSS")
private Timestamp createTime;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public Long getTimerWheelId() {
return timerWheelId;
}
public void setTimerWheelId(Long timerWheelId) {
this.timerWheelId = timerWheelId;
}
public Timestamp getCreateTime() {
return createTime;
}
public void setCreateTime(Timestamp createTime) {
this.createTime = createTime;
}
}创建Repository类用于操作数据库:
package org.fiend.repository;
import org.fiend.entity.IncrementKeyEntity;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
/**
* @author langpf 2018/12/10
*/
@Repository
public interface IncrementKeyRepo extends JpaRepository<IncrementKeyEntity, Long> {
}测试方法
IncrementKeyController.java
package org.fiend.c.web.controller;
import com.alibaba.fastjson.JSONObject;
import org.fiend.c.web.service.IncrementKeyTestService;
import org.fiend.entity.IncrementKeyEntity;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
/**
* @author 86133 2023-07-11 15:43:00
*/
@RestController
public class IncrementKeyController {
Logger log = LoggerFactory.getLogger(getClass());
@Autowired
IncrementKeyTestService incrementKeyTestService;
@RequestMapping(value = "getData")
public List<IncrementKeyEntity> getData() {
return incrementKeyTestService.getData();
}
@RequestMapping(value = "insertByJdbc")
public String insertByJdbc() {
return incrementKeyTestService.insertByJdbc();
}
@RequestMapping(value = "insertByHibernate")
public String insertByHibernate() {
return incrementKeyTestService.insertByHibernate();
}
@RequestMapping(value = "batchInsertByJdbc")
public JSONObject batchInsertByJdbc(int count) {
incrementKeyTestService.batchInsertByJdbc(count);
return incrementKeyTestService.getIncrementSpendTime();
}
@RequestMapping(value = "batchInsertByHibernate")
public JSONObject batchInsertByHibernate(int count) {
incrementKeyTestService.batchInsertByHibernate(count);
return incrementKeyTestService.getIncrementSpendTime();
}
@RequestMapping(value = "clearSpendTime")
public String clearSpendTime() {
return incrementKeyTestService.clearSpendTime();
}
@RequestMapping(value = "getIncrementSpendTime")
public JSONObject getIncrementSpendTime() {
return incrementKeyTestService.getIncrementSpendTime();
}
}
IncrementKeyTestService.java
package org.fiend.c.web.service;
import com.alibaba.fastjson.JSONObject;
import com.google.common.collect.Lists;
import org.fiend.entity.IncrementKeyEntity;
import org.fiend.repository.IncrementKeyRepo;
import org.fiend.util.DateUtil;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/**
* @author Administrator
*/
@Service
public class IncrementKeyTestService {
Logger log = LoggerFactory.getLogger(getClass());
@Autowired
JdbcTemplate jdbcTemplate;
@Autowired
IncrementKeyRepo incrementKeyRepo;
AtomicLong maxSpendTime = new AtomicLong(0);
AtomicLong totalSpendTime = new AtomicLong(0);
AtomicInteger totalCount = new AtomicInteger(0);
private final ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private final ReentrantReadWriteLock.WriteLock writeLock = readWriteLock.writeLock();
@Transactional
public List<IncrementKeyEntity> getData() {
return incrementKeyRepo.findAll();
}
public String insertByJdbc() {
long start = System.currentTimeMillis();
String msg = "insert user failed!";
String sql2 = "insert into TEST_SCHEMA.mytest_increment_key_table(timer_wheel_id, create_time) values (?, ?)";
int result = jdbcTemplate.update(sql2, 2, DateUtil.getTimestamp());
if (result < 1) {
log.error(msg);
throw new RuntimeException(msg);
}
long spendTime = System.currentTimeMillis() - start;
calcSpendTime(spendTime);
log.info("spend time: {}ms", spendTime);
return "ok";
}
public String insertByHibernate() {
IncrementKeyEntity incrementKeyEntity;
incrementKeyEntity = new IncrementKeyEntity();
incrementKeyEntity.setTimerWheelId((long) 2);
incrementKeyEntity.setCreateTime(DateUtil.getTimestamp());
long start = System.currentTimeMillis();
incrementKeyRepo.save(incrementKeyEntity);
long spendTime = System.currentTimeMillis() - start;
calcSpendTime(spendTime);
log.info("spend time: {}ms", spendTime);
return "ok";
}
public void batchInsertByJdbc(int count) {
clearSpendTime();
int loopTimes = 10;
int i = loopTimes;
while (i > 0) {
List<Object[]> batchArgs = Lists.newArrayList();
int j = count;
while (j > 0) {
batchArgs.add(new Object[]{j, DateUtil.getTimestamp()});
j--;
}
String sql2 = "insert into mytest_increment_key_table(timer_wheel_id, create_time) values (?, ?)";
long start = System.currentTimeMillis();
int[] result = jdbcTemplate.batchUpdate(sql2, batchArgs);
long spendTime = System.currentTimeMillis() - start;
log.info("spendTime: {}ms, result: {}", spendTime, result);
calcSpendTime(spendTime);
i--;
}
log.info("batch size: {}, maxSpendTime: {}ms, avg spend time: {}ms", count,
maxSpendTime.get(), totalSpendTime.get() / loopTimes);
}
public void batchInsertByHibernate(int count) {
clearSpendTime();
int loopTimes = 10;
int i = loopTimes;
while (i > 0) {
List<IncrementKeyEntity> list = Lists.newArrayList();
int j = count;
IncrementKeyEntity incrementKeyEntity;
while (j > 0) {
incrementKeyEntity = new IncrementKeyEntity();
incrementKeyEntity.setTimerWheelId((long) 2);
incrementKeyEntity.setCreateTime(DateUtil.getTimestamp());
list.add(incrementKeyEntity);
j--;
}
long start = System.currentTimeMillis();
incrementKeyRepo.saveAll(list);
long spendTime = System.currentTimeMillis() - start;
log.info("spend time: {}ms", spendTime);
calcSpendTime(spendTime);
i--;
}
log.info("batch size: {}, maxSpendTime: {}ms, avg spend time: {}ms", count,
maxSpendTime.get(), totalSpendTime.get() / loopTimes);
}
public String clearSpendTime() {
maxSpendTime.set(0);
totalSpendTime.set(0);
totalCount.set(0);
log.info("max spend time: {}ms, avg spend time: {}ms",
maxSpendTime.get(), totalCount.get() == 0 ? 0 : totalSpendTime.get() / totalCount.get());
return "ok";
}
public JSONObject getIncrementSpendTime() {
JSONObject json = new JSONObject();
json.put("maxSpendTime", maxSpendTime.get() + "ms");
json.put("avgSpendTime", totalCount.get() == 0 ? 0 + "ms" : totalSpendTime.get() / totalCount.get() + "ms");
log.info(JSONObject.toJSONString(json));
return json;
}
private void calcSpendTime(long spendTime) {
writeLock.lock();
if (spendTime > maxSpendTime.get()) {
maxSpendTime.set(spendTime);
}
writeLock.unlock();
totalCount.incrementAndGet();
totalSpendTime.addAndGet(spendTime);
}
}
表数据如下:
Hibernate与Jdbc测试结果
# 建表SQL
CREATE TABLE TEST_SCHEMA.mytest_increment_key_table(id BIGINT NOT NULL GENERATED ALWAYS AS IDENTITY(START WITH 1,INCREMENT BY 1,NO CACHE)
PRIMARY KEY, timer_wheel_id BIGINT NOT NULL, create_time TIMESTAMP NOT NULL);
## insert sql
insert into TEST_SCHEMA.mytest_increment_key_table(timer_wheel_id, create_time) values (1, '2022-03-06 23:12:21.333')
# ---------------- IncrementKey测试 ---------------- #
### springboot 启动
测试机器: (2核1G)
启动参数: java -jar -Xms868m -Xmx868m druid-hibernate-db2-1.0.jar
## 单条数据写入效率测试
### 测试参数
jmeter 线程数:90, 常数吞吐量: 21000.0/min, 持续时间90s
### 测试数据
#### 调用 insertByJdbc 方法
"avgSpendTime": "9ms", "maxSpendTime": "277ms", 吞吐量: 333/sec
#### 调用 insertByHibernate 方法
"avgSpendTime": "11ms", "maxSpendTime": "351ms", 吞吐量: 329/sec
### 结论
采用jdbc写入, 吞吐量和平均耗时均略优于Hibernate方式,因此推荐, 采用jdbc的方式写入数据
## 批量写入效率测试
### 测试数据
调用 batchInsertByJdbc 方法
batch size: 10, "avgSpendTime":"16ms","maxSpendTime":"44ms"
batch size: 20, "avgSpendTime":"22ms","maxSpendTime":"28ms"
batch size: 30, "avgSpendTime":"34ms","maxSpendTime":"41ms"
batch size: 40, "avgSpendTime":"43ms","maxSpendTime":"69ms"
batch size: 50, "avgSpendTime":"53ms","maxSpendTime":"63ms"
调用 batchInsertByHibernate 方法
batch size: 10, "avgSpendTime":"79ms", "maxSpendTime":"381ms"
batch size: 20, "avgSpendTime":"88ms", "maxSpendTime":"143ms"
batch size: 30, "avgSpendTime":"118ms", "maxSpendTime":"126ms"
batch size: 40, "avgSpendTime":"147ms", "maxSpendTime":"161ms"
batch size: 50, "avgSpendTime":"192ms", "maxSpendTime":"253ms"
### 结论
在相同batch size下, 批量写入, 无论是平均耗时, 还是最大耗时, Jdbc均远远优于Hibernate.
References:
Docker Image
Statements Insert